spark.mllib源码阅读-分类算法2-NaiveBayes
Posted 大愚若智_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark.mllib源码阅读-分类算法2-NaiveBayes相关的知识,希望对你有一定的参考价值。
朴素贝叶斯模型简述:
贝叶斯模型通过使用后验概率和类的概率分布来估计先验概率,具体的以公式表达为
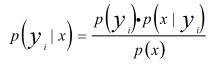
P(Y)可以使用训练样本的类分布进行估计。如果X是单特征也很好估计,但如果X=x1,x2,..,xn等n个特征构成,那估计n个特征的联合概率分布P(X)=P(x1,x2,...,xn)将变得非常困难。由于贝叶斯模型的参数难于估计,限制了其的应用。
朴素贝叶斯模型是贝叶斯模型的简化版本,通过假设特征之间独立不相关,那么
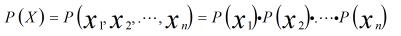

通过求解每个特征的分布和每个特征的后验概率来近似特征的联合概率分布和特征的后验概率。当然,通常情况下,特征相互独立的假设不会成立,这里只是模型复杂度和模型精度的一个权衡。这样样本x属于第i类和第k类的概率分别为:

由于P(X)联合概率分布对每个类都是相同的,可以不求。
Spark下朴素贝叶斯的具体实现:
NaiveBayesModel

NaiveBayesModel保存了朴素贝叶斯模型的参数,继承自ClassificationModel,并重写了predict方法。
先看看NaiveBayesModel的贝叶斯模型参数,
labels:类别编号
pi: 类的先验概率P(Y)的对数值
theta: 条件概率P(X|Y)的对数值
modelType:Multinomial,Bernoulli:实际上依据特征的分布不同,朴素贝叶斯又划分为多个子类别,这实际上又是对特征的一种假设来简化建模。
如果特征近似服从多项式分布,即特征只能取N个值,取到每个值的概率为pi,则p1+p2+..+pn=1。基于此假设构建的贝叶斯分类称为Multinomial NaiveBayesModel,典型的例子是基于词频向量的文本分类。
如果特征服从伯努利分布,基于此假设构建的贝叶斯分类称为 Bernoulli NaiveBayesModel,典型的例子是基于one-hot构建的文本分类。
不同的特征分布假设,将调用不同的概率计算函数:
private val (thetaMinusNegTheta, negThetaSum) = modelType match
case Multinomial => (None, None)
case Bernoulli =>
val negTheta = thetaMatrix.map(value => math.log(1.0 - math.exp(value)))//事件失败的概率
val ones = new DenseVector(Array.fill(thetaMatrix.numCols) 1.0)
//事件不失败的概率
val thetaMinusNegTheta = thetaMatrix.map value =>
value - math.log(1.0 - math.exp(value))
(Option(thetaMinusNegTheta), Option(negTheta.multiply(ones)))
case _ =>
// This should never happen.
throw new UnknownError(s"Invalid modelType: $modelType.")
//特征的分布不一样,其估计也不一样
@Since("1.0.0")
override def predict(testData: Vector): Double =
modelType match
case Multinomial =>
labels(multinomialCalculation(testData).argmax)
case Bernoulli =>
labels(bernoulliCalculation(testData).argmax)
另外为方便计算和避免小数值,根据对数运算法则,可将乘积运算转换为加法运算,后验概率的估计值为

//计算每个类别的概率p(yi|X1,x2)=p(yi)*p(x1|yi)*p(x2|yi)*.../P(X) 实际计算的是log(p(yi)) + log(p(x1|yi)) +***
//全概率P(X)对每个类别一致,可以不算
private def multinomialCalculation(testData: Vector) =
val prob = thetaMatrix.multiply(testData)//求出
BLAS.axpy(1.0, piVector, prob)
prob
private def bernoulliCalculation(testData: Vector) =
testData.foreachActive((_, value) =>
if (value != 0.0 && value != 1.0) //伯努利事件的结果只有两种状态
throw new SparkException(
s"Bernoulli naive Bayes requires 0 or 1 feature values but found $testData.")
)
val prob = thetaMinusNegTheta.get.multiply(testData)
BLAS.axpy(1.0, piVector, prob)
BLAS.axpy(1.0, negThetaSum.get, prob)
prob
NaiveBayes
再来看NaiveBayesModel的参数估计,参数估计由NaiveBayes类开始。
NaiveBayes构造函数有个lambda参数,一般在估计P(Xi|Y)时,对于在训练数据中没有出现的Xi,会得到其估计P(Xij|Y)=0
在实际应用中,对于某个类别没有出现在样本集中或者某个特征没有出现在某类样本集中,这个时候就需要加入平滑因子lambda去调整,一般常用拉普拉斯平滑进行处理。
类的分布估计调整为
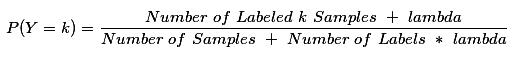
多项式模型下的参数估计调整为:
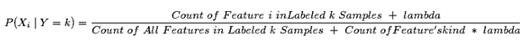
伯努力模型下参数估计调整为:
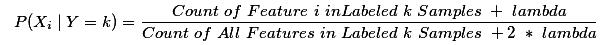
朴素贝叶斯模型的训练是在mllib.NaiveBayes中由用户调用其run来完成训练的。run方法调用了ml.NaiveBayes类的trainWithLabelCheck方法来完成参数估计的。
接下来看看trainWithLabelCheck进行参数估计的过程
private[spark] def trainWithLabelCheck(
dataset: Dataset[_],
positiveLabel: Boolean): NaiveBayesModel =
if (positiveLabel) ...
val modelTypeValue = $(modelType)
val requireValues: Vector => Unit = ...
//估算argmax p(yi)*p(X|Yi) ==> argmax log(p(yi)) + log(p(X|Yi))
//p(yi) = numDocuments in lable i / numDocuments all
//p(X|Yi) = p(X1|Yi)*p(X2|Yi)... ==> log(p(X1|Yi)) + log(p(X2|Yi))
//p(X1|Yi) = featureSum in lable i / featureSum all
//特征数量
val numFeatures = dataset.select(col($(featuresCol))).head().getAs[Vector](0).size
//特征权重
val w = if (!isDefined(weightCol) || $(weightCol).isEmpty) lit(1.0) else col($(weightCol))
// Aggregates分布式计算 进行文档和特征的统计计数
//aggregateByKey再collect等价于aggregateByKeyLocally,返回的是一个HashMap<lable id,object>
//aggregated具体形式为 [lable i, numDocuments in lable i, a vector contains <feature1Sum,feature2Sum,..>]
val aggregated = dataset.select(col($(labelCol)), w, col($(featuresCol))).rdd
.map row => (row.getDouble(0), (row.getDouble(1), row.getAs[Vector](2)))
.aggregateByKey[(Double, DenseVector)]((0.0, Vectors.zeros(numFeatures).toDense))(//分类别统计featureSum
seqOp =
case ((weightSum: Double, featureSum: DenseVector), (weight, features)) =>
requireValues(features)
BLAS.axpy(weight, features, featureSum)//常数乘以向量加另一个向量
(weightSum + weight, featureSum)
,
combOp =
case ((weightSum1, featureSum1), (weightSum2, featureSum2)) =>
BLAS.axpy(1.0, featureSum2, featureSum1)//featureSum2 + featureSum1
(weightSum1 + weightSum2, featureSum1)
).collect().sortBy(_._1)//sortBy lable index
//分类数
val numLabels = aggregated.length
//总的样本数量
val numDocuments = aggregated.map(_._2._1).sum
val labelArray = new Array[Double](numLabels)
//初始化存储p(yi)的数组
val piArray = new Array[Double](numLabels)
//用于计算p(xi|yk)的参数,类别数numLabels*特征数量numFeatures大小的数组
val thetaArray = new Array[Double](numLabels * numFeatures)
val lambda = $(smoothing)//平滑参数
val piLogDenom = math.log(numDocuments + numLabels * lambda)//这个是估计p(yi)的分母,见公式。。。
var i = 0
//迭代aggregated这个存在本地的HashMap
aggregated.foreach case (label, (n, sumTermFreqs)) =>
labelArray(i) = label
piArray(i) = math.log(n + lambda) - piLogDenom //计算log(p(yi)) , 是(numDocuments in lable i + lambda)/(numDocuments + numLabels * lambda)的对数形式
val thetaLogDenom = $(modelType) match //这个是计算公式。。。的分母部分
case Multinomial => math.log(sumTermFreqs.values.sum + numFeatures * lambda)//实际上上加了一个平滑因子的
case Bernoulli => math.log(n + 2.0 * lambda)
case _ =>
throw new UnknownError(s"Invalid modelType: $$(modelType).")
var j = 0
while (j < numFeatures)
//第i类别第j个特征的参数估计
thetaArray(i * numFeatures + j) = math.log(sumTermFreqs(j) + lambda) - thetaLogDenom //计算log(p(Xk|Yi))
j += 1
i += 1
val pi = Vectors.dense(piArray) //存储log(p(yi))的数组
val theta = new DenseMatrix(numLabels, numFeatures, thetaArray, true)
new NaiveBayesModel(uid, pi, theta).setOldLabels(labelArray)
Spark目前只实现了基于伯努利分布和二项分布的朴素贝叶斯算法,对于诸如高斯分布的朴素贝叶斯目前还没有实现,在需要时可参照上述两个模型的过程来自己实现(重写NaiveBayesModel的predict方法和NaiveBayes的参数估计方法)。
以上是关于spark.mllib源码阅读-分类算法2-NaiveBayes的主要内容,如果未能解决你的问题,请参考以下文章