SpringCloudAlibaba知识概括
Posted GeorgeLin98
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SpringCloudAlibaba知识概括相关的知识,希望对你有一定的参考价值。
SpringCloudAlibaba知识概括
SpringCloud Alibaba简介
why会出现SpringCloud alibaba:
- Spring Cloud Netflix项目进入维护模式。
- 将模块置于维护模式,意味着Spring Cloud团队将不会再向模块添加新功能。我们将修复block级别的bug以及安全问题,我们也会考虑并审查社区的小型pull request。
- 进入维护模式意味着Spring Cloud Netlix将不再开发新的组件,我们都知道Spring Cloud版本迭代算是比较快的,因而出现了很多重大ISSUE都还来不及Fix就又推另一个Release了. 进入维护模式意思就是目前一直以后一段时间Spring Cloud Netflix提供的服务和功能就这么多了,不在开发新的组件和功能了。以后将以维护和Merge分支Full Request为主,新组件功能将以其他替代平代替的方式实现。
SpringCloud alibaba带来了什么?
-
是什么?
①Spring Cloud for Alibaba,它是由一些阿里巴巴的开源组件和云产品组成的。 这个项目的目的是为了让大家所熟知的Spring框架,其优秀的设计模式和抽象理念,以给使用阿里巴巴产品的Java开发者带来使用Spring Boot和Spring Cloud的更多便利。 -
能干嘛?
①服务限流降级:默认支持Servlet、 Feign、 RestTemplate、 Dubbo和RocketMQ限流降级功能的接入,可以在运行时通过控制台实时修改限流降级规则,还支持查看限流降级Metrics监控。
②服务注册与发现:适配Spring Cloud服务注册与发现标准,默认集成了Ribbon的支持。
③分布式配置管理:支持分布式系统中的外部化配置,配置更改时自动刷新。
④消息驱动能力:基于Spring Cloud Stream为微服务应用构建消息驱动能力。
⑤阿里云对象存储:阿里云提供的海量、安全、低成本、高可靠的云存储服务。支持在任何应用、任何时间、任何地点存储和访问任意类型的数据。
⑥分布式任务调度:提供秒级、精准、向靠、可用的定时(基于Cron表达式)任务调度服务。同时提供分布式的任务执行模型,如网格任务。网格任务支持海量子任务均匀分配到所有Worker (schedulerx client) 上执行。 -
怎么玩?
①Sentinel:把流量作为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
②Nacos:一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
③RocketMQ:一款开源的分布式消息系统,基于高可用分布式集群技术,提供低延时的、高可靠的消息发布与订阅服务。
④Dubbo:Apache Dubbo™ 是一款高性能 Java RPC 框架。
⑤Seata:阿里巴巴开源产品,一个易于使用的高性能微服务分布式事务解决方案。
⑥Alibaba Cloud ACM:一款在分布式架构环境中对应用配置进行集中管理和推送的应用配置中心产品。
⑦Alibaba Cloud OSS: 阿里云对象存储服务(Object Storage Service,简称 OSS),是阿里云提供的海量、安全、低成本、高可靠的云存储服务。您可以在任何应用、任何时间、任何地点存储和访问任意类型的数据。
⑧Alibaba Cloud SchedulerX: 阿里中间件团队开发的一款分布式任务调度产品,提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。
⑨Alibaba Cloud SMS: 覆盖全球的短信服务,友好、高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道。 -
一句话:Spring Cloud Alibaba致力于提供微服务开发的一-站式解决方案。此项目包含开发分布式应用微服务的必需组件,便开发者通过SpringCloud编程模型轻松使用这些组件来开发分布式应用服务。依托Spring Cloud Alibaba,您只需要添加一些注解和少量配置, 就可以将Spring Cloud应用接入阿里微服务解决方案,通过阿里中间件来迅速搭建分布式应用系统。
Nacos
Nacos简介:
- 为什么叫Nacos:
①前四个字母分别为Naming和Configuration的前两个字母,最后的s为Service - 是什么:
①一个更易于构建云原生应用的动态服务发现,配置管理和服务管理中心
②Nacos:Dynamic Naming and Configuration Service
③Nacos就是注册中心+配置中心的组合:等价于Eureka+Config+Bus - 能干嘛:
①替代Eureka做服务注册中心
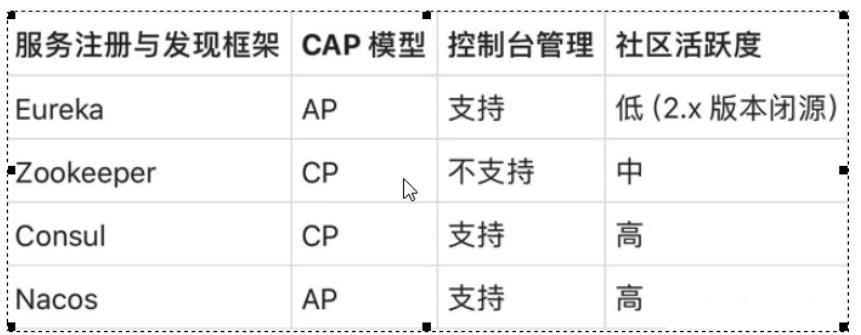
②替代Config做服务配置中心 - 各种注册中心比较:
Nacos环境搭建:
- 先从官网下载Nacos,解压安装包,直接运行bin目录下的startup.cmd。
- 命令运行成功后直接访问http://localhost:8848/nacos,默认账号密码都是nacos。
Nacos作为服务注册中心:
- pom.xml:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
- application.yml:
server:
port: 9001
spring:
application:
name: nacos-payment-provider
cloud:
nacos:
discovery:
server-addr: localhost:8848 #配置Nacos地址
management:
endpoints:
web:
exposure:
include: '*'
- 为什么nacos支持负载均衡?
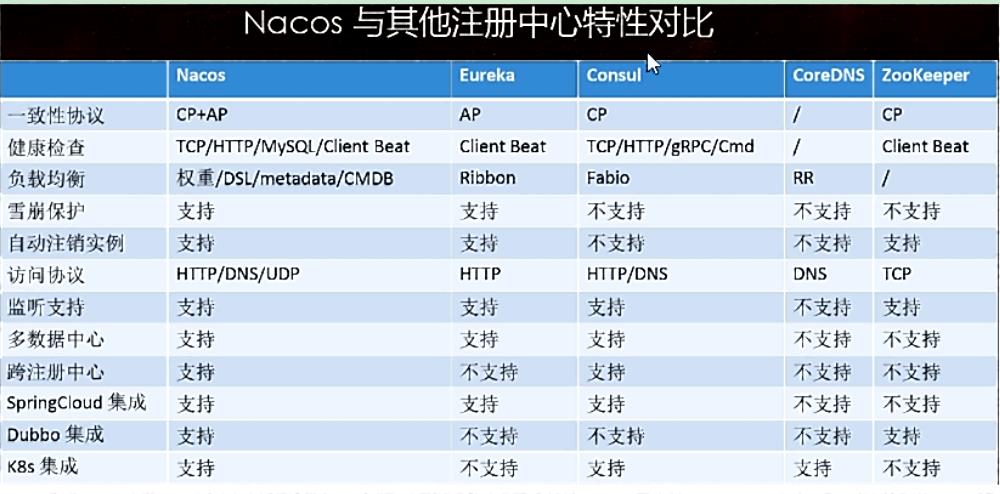
各种注册中心对比:
- Nacos和CAP:
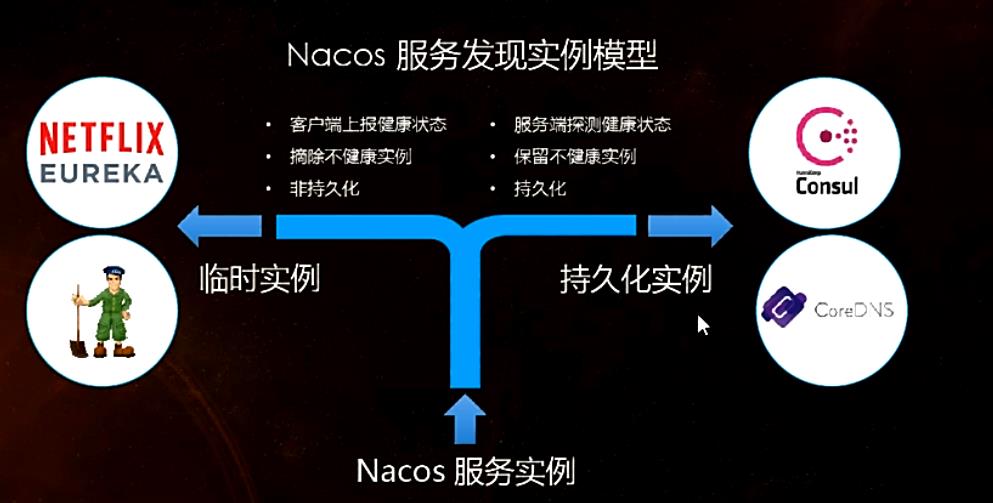
- Nacos支持AP和CP模式的切换:
①C是所有节点在同一时间看到的数据是一致的,而A的定义是所有的请求都会收到响应。
②一般来说,如果不要存储服务级别的信息且服务实例是通过nacos- client注册, 并能够保持心跳上报,那么就可以选择AP模式。当前主流的服务如Spring cloud和Dubbo服务,都适用于AP模式,AP模式为了服务的可能性而减弱了一致性,因此AP模式下只支持注册临时实例。
③如果需要在服务级别编辑或者存储配置信息,那么CP必须,K8S服务和DNS服务则适用于CP模式。
CP模式下则支持注册持久化实例,此时则是以Raft协议为集群运行模式,该模式下注册实例之前必须先注册服务,如果服务不存在,则会返回错误。
④切换:curl -X PUT '$NACOS_ SERVER:8848/nacos/v1/ns/operator/switches?entry= serverMode&value=CP'
Nacos作为服务配置中心:
- pom.xml:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!--nacos-discovery-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
- bootstrap.yml:
server:
port: 3377
spring:
application:
name: nacos-config-client
cloud:
nacos:
discovery:
server-addr: localhost:8848 #服务注册中心地址
config:
server-addr: localhost:8848 #配置中心地址
file-extension: yaml #指定yaml格式的配置
- application.yml:
spring:
profiles:
active: dev
- 业务类:
①通过Spring Cloud原生注解@RefreshScope 实现配置自动更新,即Nacos自带动态刷新。
@RestController
@RefreshScope
public class ConfigClientController
@Value("$config.info")
private String configInfo;
@GetMapping("/config/info")
public String getConfigInfo()
return configInfo;
-
Nacos中的匹配规则:
①之所以需要配置spring. application.name, 是因为它是构成Nacos配置管理dataId 字段的一 部分。在Nacos Spring Cloud中,dataId 的完整格式如下:$prefix-$spring . profile. active.$file- extension。
<1>prefix默认为spring. application.name的值, 也可以通过配置项spring. cloud . nacos . config. prefix来配置。
<2>spring. profile. active即为当前环境对应的profile, 详情可以参考Spring Boot文档。注意:当spring. profile.active为空时,对应的连接符一也将不存在, datald 的拼接格式变成$prefix. $file . extension
<3>file-exetension为配置内容的数据格式,可以通过配置项spring. cloud .nacos . config. file-extension来配置。目前只支持properties和yaml 类型。
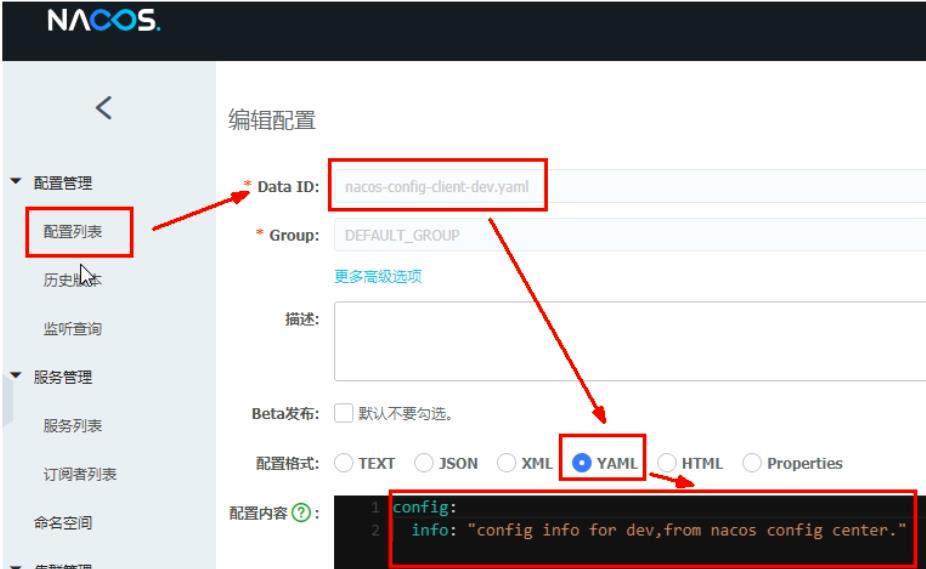
-
Namespace+Group+Data ID三者关系?为什么这么设计?
①类似Java里面的package名和类名,最外层的namespace是可以用于区分部署环境的,Group和DatalD逻辑上区分两个目标对象。
②默认情况:Namespace=public,Group=DEFAULT _GROUP,默认Cluster是DEFAULT。Nacos默认的命名空间是public,,Namespace主要用来实现隔离。比方说我们现在有三个环境:开发、测试、生产环境,我们就可以创建三个Namespace,不同的Namespace之间是隔离的。
③Group默认是DEFAULT_ GROUP,Group可以把不同的微服务划分到同一个分组里面去。
④Service就是微服务,一个Service可以包含多个Cluster (集群),Nacos默认Cluster是DEFAULT,Cluster是对指定微服务的一个虚拟划分。比方说为了容灾,将Service微服务分别部署在了杭州机房和广州机房,这时就可以给杭州机房的Service微服务起一个集群名称 (HZ) ,给广州机房的Service微服务起一个集群名称(GZ) ,还可以尽量让同一个机房的微服务互相调用,以提升性能。
⑤最后是Instance,就是微服务的实例。

-
Nacos的分类配置:
①DataID方案:
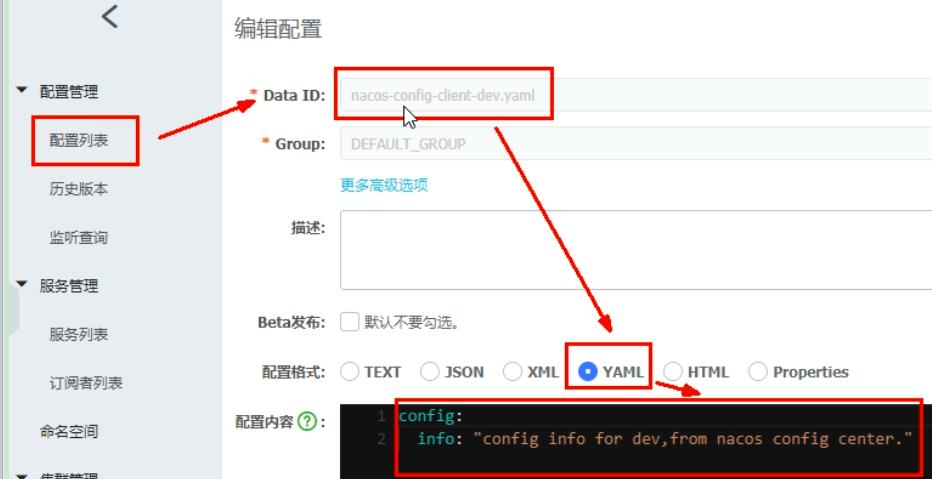
②Group方案:

③Namespace方案:

spring:
application:
name: nacos-config-client
cloud:
nacos:
discovery:
server-addr: localhost:8848 #服务注册中心地址
config:
server-addr: localhost:8848 #配置中心地址
file-extension: yaml #指定yaml格式的配置
namespace: bdc9002e-6312-4d10-acb8-04798ea4d72c
group: DEV_GROUP
Nacos持久化:
- Nacos默认自带的是嵌入式数据库derby。
- derby到mysql切换配置步骤:
①nacos-server-1.1.4\\nacos\\conf目录下找到sql脚本(nacos-mysql.sql)并执行。
②nacos-server-1.1.4\\nacos\\conf目录下找到application.properties,加入以下配置。
spring.datasource.platform=mysql
db.num=1
db.url.0=jdbc:mysql://11.162.196.16:3306/nacos_devtest?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true
db.user=nacos_devtest
db.password=youdontknow
- 重新启动Nacos后也可以看到之前的配置。
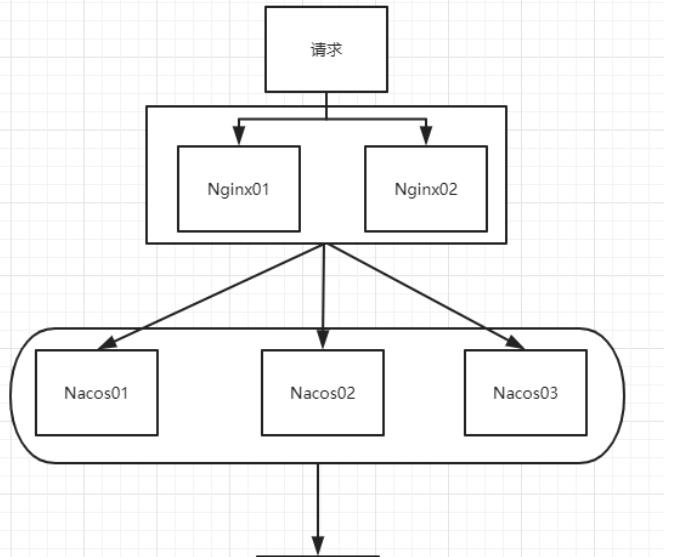
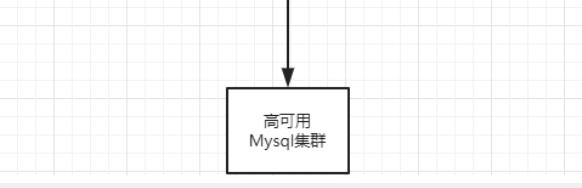
Nacos集群:
- Nacos集群架构:
- Nacos支持三种部署模式:
①单机模式-用于测试和单机试用。
②集群模式-用于生产环境,确保高可用。
③多集群模式-用于多数据中心场景。 按照上述我们需要mysql数据库,单机模式支持mysqI:在0.7版本之前,在单机模式时nacos使用嵌入式数据库实现数据的存储,仿便观察数据存储的基本情况。0.7版本增加了支持mysq|数据源能力,具体的操作步骤:
①安装数据库,版本要求: 5.6.5+
②初始化mysq|数据库,数据库初始化文件:nacos-mysql.sql
③修改conf/application.properties文件, 增加支持mysq|数据源配置(目前只支持mysq|) , 添加mysq|数
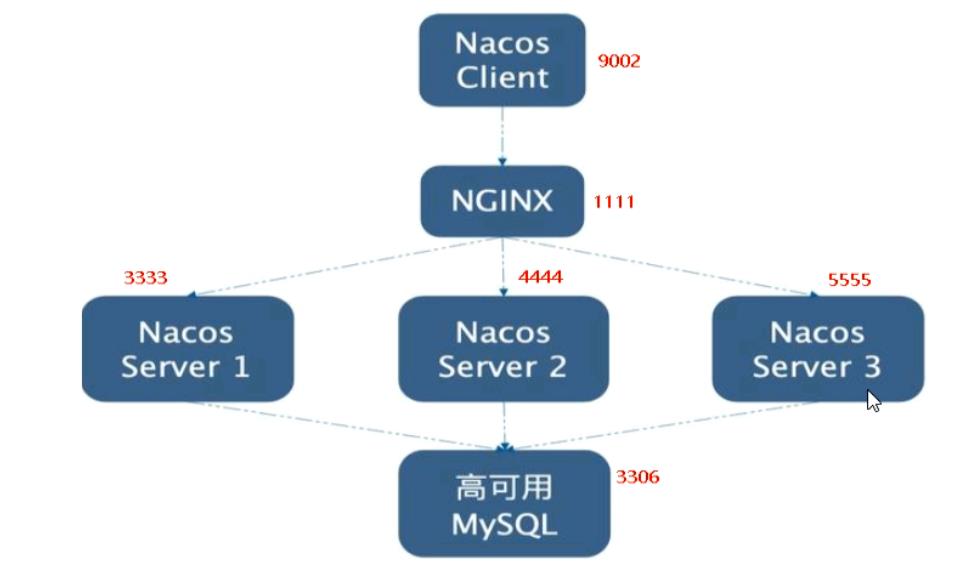
据源的url、用户名和密码。- 集群配置:
①配置集群Nacos机器的Mysql持久化,以便再次重启时能访问拿到同一数据。
②修改conf目录下的cluster.conf文件:填写集群Nacos机器的IP地址加端口号。
③配置nginx,由它作为负载均衡器。
upstream cluster
#Nacos集群机器地址
server 127.0.0.1:3333;
server 127.0.0.1:4444;
server 127.0.0.1:5555;
server
listen 1111;
server_name localhost;
location /
#反向代理域名地址
proxy_pass http://cluster;
....省略
- 集群访问地址:https://Nginx部署IP地址:Nginx部署端口号/nacos/。
- 集群架构:
Sentinel
Sentinel概述:
- 是什么:轻量级的流量控制、熔断降级Java库。
- 能干嘛:
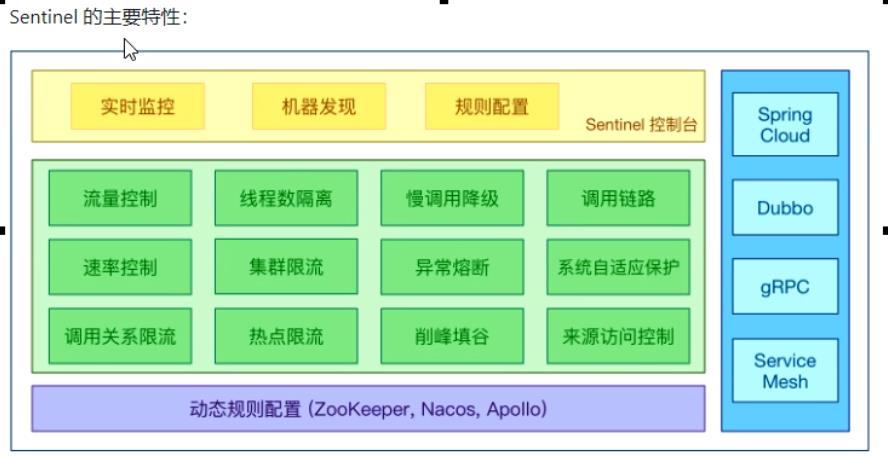
- 怎么玩:
①服务雪崩
②服务降级
③服务熔断
④服务限流
Sentinel分为两个部分:
- 核心库(Java客户端)不依赖任何框架/库,能够运行于所有Java运行时环境,同时对Dubbo / Spring
Cloud等框架也有较好的支持。 - 控制台(Dashboard) 基于Spring Boot开发,打包后可以直接运行,不需要额外的Tomcat等应用 容器。
Sentinel控制台:
- 前提:
①8080端口不能被占用
②java8环境OK - 下载sentinel-dashboard-1.7.0.jar包到本地后执行命令:java -jar sentinel-dashboard-1.7.0.jar 。
- 访问sentinel管理界面:http://localhost:8080。登录账号密码均为sentinel。
Sentinel核心库客户端:
- POM.xml:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
- application.yml:
spring:
application:
name: cloudalibaba-sentinel-service
cloud:
nacos:
discovery:
server-addr: localhost:8848
sentinel:
transport:
dashboard: localhost:8080
port: 8719 #默认8719,假如被占用了会自动从8719开始依次+1扫描。直至找到未被占用的端口
Sentinel采用的懒加载说明:执行一次访问后即可在控制台看到相关接口。
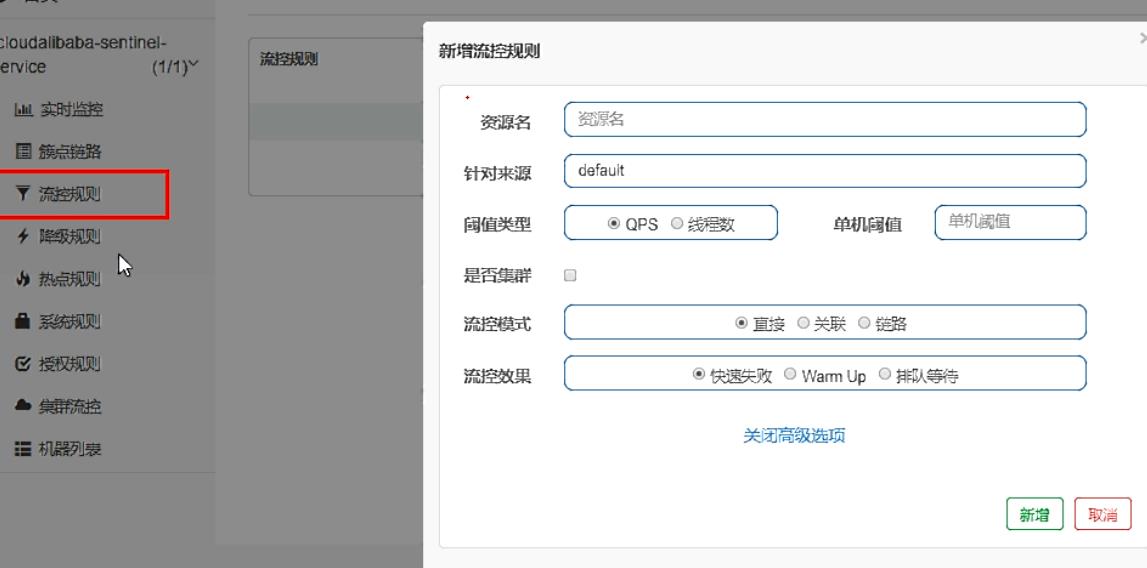
流控规则:
- 资源名:唯一名称,默认请求路径
- 针对来源: Sentine可以针对调用者进行限流,填写微服务名,默认default (不区分来源)
- 阈值类型/单机阈值:
①QPS (每秒钟的请求数量) :当调用该ap的QPS达到阈值的时候,进行限流
②线程数:当调用该api的线程数达到阈值的时候,进行限流 - 是否集群:不需要集群
- 流控模式:
①直接: api达到限流条件时,直接限流
②关联:当关联的资源达到阈值时,就限流自己
③链路:只记录指定链路上的流量(指定资源从入口资源进来的流量,如果达到阈值,就进行限流) [api级
别的针对来源] - 流控效果:
①快速失败:直接失败,抛异常
②Warm Up:根据codeFactor (冷加载因子,默认3)的值,从阈值/codeFactor, 经过预热时长,才达到设置的QPS阈值。
<1>应用场景:秒杀系统在开启的瞬间,会有很多流量上来,很有可能把系统打死,预热方式就是把为了保护系统,可慢慢的把流量放进来,慢慢的把阀值增长到设置的阀值。
③排队等待:匀速排队,让请求以匀速的速度通过,阈值类型必须设置为QPS,否则无效。
<1>这种方式主要用于处理间隔性突发的流量,例如消息队列。想象一下这样的场景, 在某一秒有大量的请求到来,而接来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求。
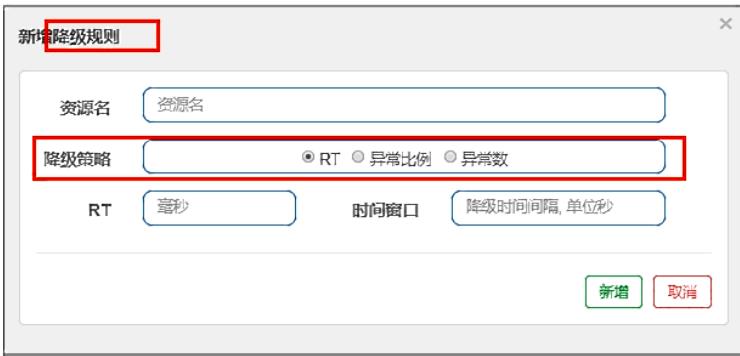
熔断(降级)规则:
- 解释:
Sentinel熔断降级会在调用链路中某个资源出现不稳定状态时(例如调用超时或异常比例升高), 对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联错误。当资源被降级后,在接下来的降级时间窗口之内,对该资源的调用都自动熔断(默认行为是抛出DegradeException)。 - RT (平均响应时间,秒级):平均响应时间超出阈值且在时间窗口内通过的请求>=5,两个条件同时满足后触发降级,窗口期过后关闭断路器。
①RT最大4900 (更大的需要通过Dcsp.sentinel.statistic.max.rt= XXXX才能生效) - 异常比列(秒级):QPS>= 5且异常比例(秒级统计)超过阈值时,触发降级。时间窗门结束后,关闭降级。
- 异常数(分钟级):异常数(分钟统计)超过阈值时,触发降级。时间窗口结束后,关闭降级。
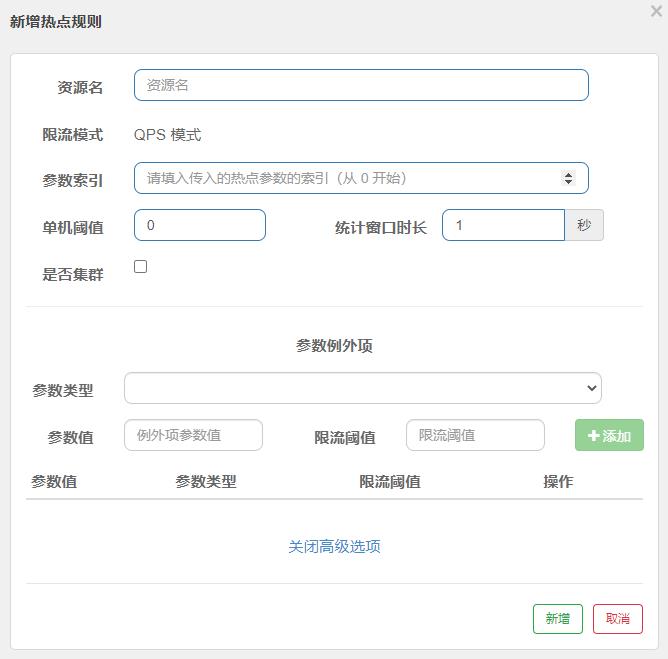
热点key限流规则:
- 参数索引:针对限流接口方法的参数,若访问接口有带上对应索引的参数,则对其限流。
- 参数例外项:添加例外项的对应值后,若访问接口与例外项匹配则放行。
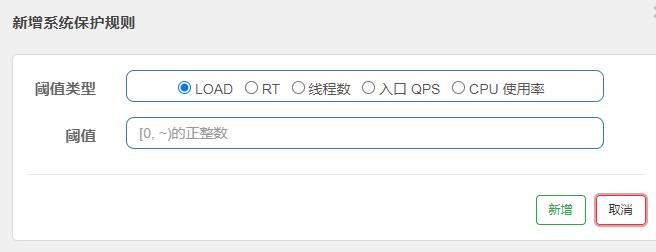
系统规则:
- 系统保护规则是从应用级别的入口流量进行控制,从单台机器的load、CPU 使用率、平均RT、入口
QPS和并发线程数等几个维度监控应用指标,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳 定性。 - 系统保护规则是应用整体维度的,而不是资源维度的,并且仅对入口流量生效。入口流量指的是进入 应用的流量(EntryType.IN),比如Web服务或Dubbo服务端接收的请求,都属于入口流星。 系统规则支持以下的模式:
①Load 自适应(仅对Linux/Unix-like机器生效) : 系统的load1作为启发指标,进行自适应系统保护。当系统load1超过设定的启发值,且系统当前的并发线程数超过估算的系统容量时才会触发系统保护(BBR 阶段)。系统容量由系统的maxQps * minRt 估算得出。设定参考值一般是CPU cores * 2.5。
②CPU usage (1.5.0+版本) :当系统CPU使用率超过阈值即触发系统保护(取值范围0.0-1.0) ,比较灵敏。
③平均RT:当单台机器上所有入口流量的平均RT达到阈值即触发系统保护,单位是毫秒。
④并发线程数:当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护。
⑤入口QPS:当单台机器上所有入口流量的QPS达到阈值即触发系统保护。
@SentinelResource概述:
- 按资源名称限流+后续处理:
①限流后会返回blockHandler方法所返回的信息。
@GetMapping("/byResource")
@SentinelResource(value = "byResource",blockHandler = "handleException")//规则填写此value 信息
public CommonResult byResource()
return new CommonResult(200,"按资源名称限流测试OK",new Payment(2020L,"serial001"));
public CommonResult handleException(BlockException exception)
return new CommonResult(444,exception.getClass().getCanonicalName()+"\\t 服务不可用");
- 按照Url地址限流+后续处理:
①限流后会返回系统自带的限流结果。
@GetMapping("/rateLimit/byUrl")//规则填写此信息
@SentinelResource(value = "byUrl")
public CommonResult byUrl()
return new CommonResult(200,"按url限流测试OK",new Payment(2020L,"serial002"));
- 上面兜底方法面临的问题:
①系统默认的,没有体现我们自己的业务要求。
②依照现有条件,我们自定义的处理方法又和业务代码耦合在一块,不直观。
③每个业务方法都添加一个兜底的,那代码膨胀加剧。
④全局统-的处理方法没有体现。 - 自定义限流处理逻辑:
①创建一个类用于自定义限流处理逻辑
-------------------于自定义限流处理逻辑类----------------------
public class CustomerBlockHandler
public static CommonResult handleException(BlockException exception)
return new CommonResult(2020, ”自定义的限流处理信息.....ustomerBlockHandler");
-------------------Controller类----------------------
@GetMapping("/rateLimit/customerBlockHandler")
@SentinelResource(value = "customerBlockHandler",
blockHandlerClass = CustomerBlockHandler.class,
blockHandler = "handlerException")
public CommonResult customerBlockHandler()
return new CommonResult(200,"按客戶自定义",new Payment(2020L,"serial003"));
- @SentinelResource详解:
①fallback 用于异常后返回结果,
②blockHandler 用于限流规则命中后返回结果,
③exceptionsToIgnore 用于忽略的异常。
④以下代码为对fallback的支持:
----------------客户端配置(Ribbon系列):----------------
@SentinelResource(value = "fallback",fallback = "handlerFallback",blockHandler = "blockHandler",
exceptionsToIgnore = IllegalArgumentException.class)
public CommonResult<Payment> fallback(@PathVariable Long id)
CommonResult<Payment> result = restTemplate.getForObject(SERVICE_URL + "/paymentSQL/"+id, CommonResult.class,id);
if (id == 4)
throw new IllegalArgumentException ("IllegalArgumentException,非法参数异常....");
else if (result.getData() == null)
throw new NullPointerException ("NullPointerException,该ID没有对应记录,空指针异常");
return result;
//fallback
public CommonResult handlerFallback(@PathVariable Long id,Throwable e)
Payment payment = new Payment(id,"null");
return new CommonResult<>(444,"兜底异常handlerFallback,exception内容 "+e.getMessage(),payment);
//blockHandler
public CommonResult blockHandler(@PathVariable Long id,BlockException blockException)
Payment payment = new Payment(id,"null");
return new CommonResult<>(445,"blockHandler-sentinel限流,无此流水: blockException "+blockException.getMessage(),payment);
----------------客户端配置(Feign系列):----------------
@FeignClient(value = "nacos-payment-provider",fallback = PaymentFallbackService.class)
public interface PaymentService
@GetMapping(value = "/paymentSQL/id")
public CommonResult<Payment> paymentSQL(@PathVariable("id") Long id);
其中application.yml需要加上以下配置:
#对Feign的支持
feign:
sentinel:
enabled: true
- 更多注解属性说明:
①Sentinel主要有三个核心API:
<1>SphU定义资源
<2>Tracer定义统计
<3>ContextUtil定义了上下文
规则持久化:
- pom.xml:
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
- application.yml:
spring:
application:
name: cloudalibaba-sentinel-service
cloud:
nacos:
discovery:
server-addr: localhost:8848 #Nacos服务注册中心地址
sentinel:
transport:
dashboard: localhost:8080 #配置Sentinel dashboard地址
port: 8719
datasource:
ds1:
nacos:
server-addr: localhost:8848
dataId: cloudalibaba-sentinel-service
groupId: DEFAULT_GROUP
data-type: json
rule-type: flow
- 添加Nacos业务规则配置:
①resource:资源名称;
②limitApp:来源应用;
③grade:阈值类型,0表示线程数,1表示QPS;
④count:单机阈值;
⑤strategy:流控模式,0表示直接, 1表示关联,2表示链路;
⑥controlBehavior:流控效果,0表示快速失败,1表示Warm Up, 2表示排队等待;
⑦clusterMode:是否集群。
[
"resource": "/retaLimit/byUrl",
"limitApp": "default",
"grade": 1,
"count": 1,
"strategy": 0,
"controlBehavior": 0,
"clusterMode": false
]
熔断框架比较:
| - | Sentinel | Hystrix | resilience4j |
|---|---|---|---|
| 隔离策略 | 信号量隔高(并发线程数限流) | 线程池隔离/信号量隔 | 信号量隔离 |
| 熔断降级策略 | 基于响应时间、异常比率、异常数 | 基于异常比率 | 基于异常比率、响应时间 |
| 实时统计实现 | 滑动窗口(LeapArray) | 滑动窗口(基于RxJava) | Ring Bit Buffer |
| 动态规则配置 | 支持多种数据源 | 支持多种数据源 | 有限支持 |
| 扩展性 | 多个扩展点 | 插件的形式 | 接口的形式 |
| 基于注解的支持 | 支持 | 支持 | 支持 |
| 限流 | 基于QPS.支持基于调用关系的限流 | 有限的支持 | Rate Limiter |
| 流量整形 | 支持预热模式、匀速器模式、预热排队模式 | 不支持 | 简单的Rate Limiter |
| 系统自适应保护 | 支持 | 不支持 | 不支持 |
| 控制台 | 提供开箱即用的控制台,可配置规则、查看秒级监控、机器发现等 | 简单的监控查看 | 不提供控制台,可对接其它监控系统 |
Seata
分布式事务问题:
- 分布式前:单机单库从1:1 -> 1:N -> N: N都没这个问题。
- 分布式之后:单体应用被拆分成微服务应用,原来的三个模块被拆分成三个独立的应用,分别使用三个独立的数据源,业务操作需要调用三个服务来完成。此时每个服务内部的数据一 致性由本地事务来保证,但是全局的数据一 致性问题没法保证。
- 一句话:一次业务操作需要跨多个数据源或需要跨多个系统进行远程调用,就会产生分布式事务问题。
Seata简介:
- 是什么:
①Seata是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。
②2019年1月份蚂蚁金服和阿里巴巴共同开源的分布式事务解决方案,Simple Extensible Autonomous Transaction Architecture意为简单可扩展自治事务框架。 - 能干嘛:
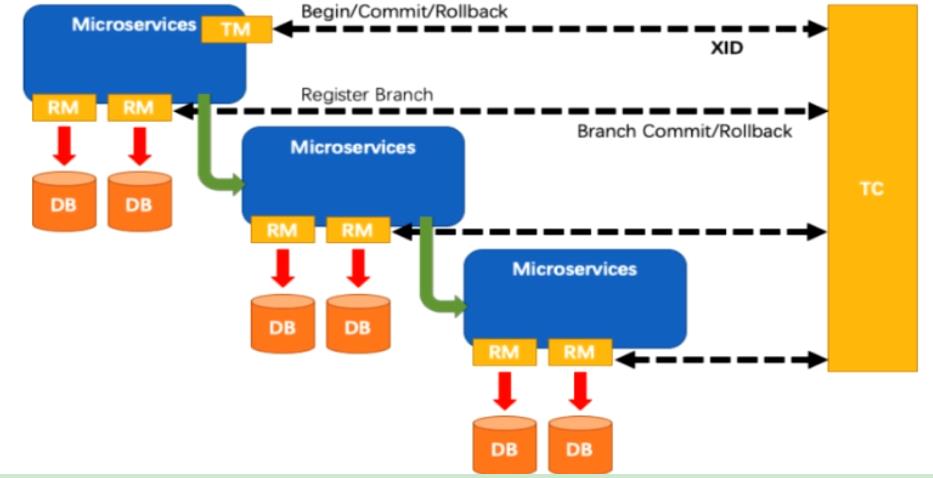
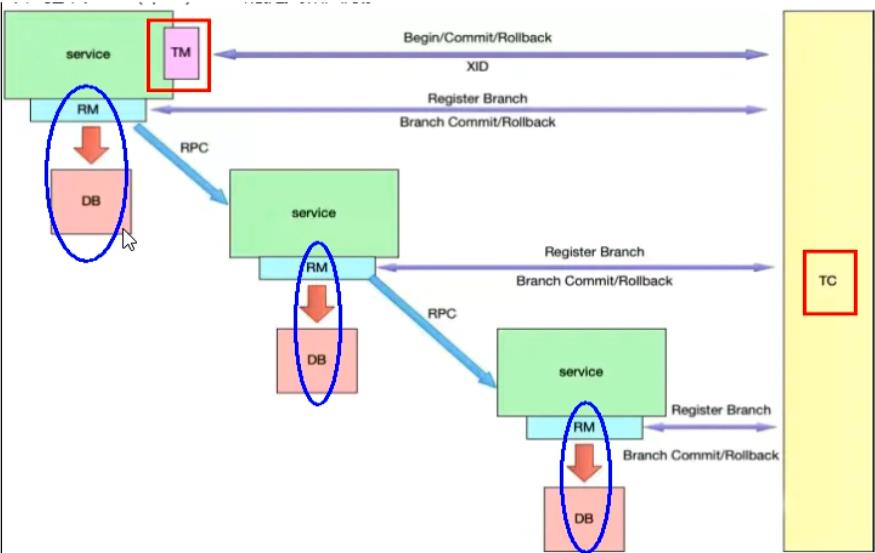
①分布式事务处理过程的一ID+三组件模型:
<1>Transaction ID XID:全局唯一的事务ID
<2>Transaction Coordinator(TC) :事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚。
<3>Transaction Manager™ :控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议。
<4>Resource Manager(RM) :控制分支事务,负责分支注册,状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚。
②处理过程:
<1>TM向TC申请开启一个全局事务,全局事务创建成功并生成一个全局唯一的XID;
<2>XID 在微服务调用链路的上下文中传播;
<3>RM向TC注册分支事务,将其纳入XID对应全局事务的管辖;
<4>TM向TC发起针对XID的全局提交或回滚决议;
<5>TC调度XID下管辖的全部分支事务完成提交或回滚请求。
- 怎么玩:
①本地@Transactional:Spring提供
②全局@GlobalTransactional:Seata提供
Seata-Server环境搭建:
- 下载seata-server-0.9.0.zip压缩包解压到指定目录。
- 修改conf目录下的file.conf配置文件:
①先备份原始file.conf文件
②主要修改:自定义事务组名称+事务日志存储模式为db+数据库连接信息:
vgroup_mapping.my_test_tx_group = "fsp_tx_group"
mode = "db"
url = "jdbc:mysql://127.0.0.1:3306/seata"
user = "root"
password = "你自己的密码"
- mysql5.7数据库新建库seata:
①建表db_store.sql在\\seata-server-0.9.0\\seata\\conf目录里面。 - 修改seata-server-0.9.0\\seata\\conf目录下的registry.conf配置文件:
①目的是:指明注册中心为nacos,及修改nacos连接信息
registry
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "nacos"
nacos
serverAddr = "localhost:8848"
namespace = ""
cluster = "default"
- 先启动Nacos,再点击softs\\seata-server-0.9.0\\seata\\bin目录下的seata-server.bat脚本启动。
seata业务:
- pom.xml:
<!--seata-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
<exclusions>
<exclusion>
<artifactId>seata-all</artifactId>
<groupId>io.seata</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-all</artifactId>
<version>0.9.0</version>
</dependency>
- application.yml:
spring:
application:
name: seata-order-service
cloud:
alibaba:
seata:
#自定义事务组名称需要与seata-server中的对应
tx-service-group: fsp_tx_group
nacos:
discovery:
server-addr: localhost:8848
每个微服务都需要建对应的回滚日志表,sql脚本在\\seata-server-0.9.0\\seata\\conf目录下的db_undo_log.sql 。- file.conf:
transport
# tcp udt unix-domain-socket
type = "TCP"
#NIO NATIVE
server = "NIO"
#enable heartbeat
heartbeat = true
#thread factory for netty
thread-factory
boss-thread-prefix = "NettyBoss"
worker-thread-prefix = "NettyServerNIOWorker"
server-executor-thread-prefix = "NettyServerBizHandler"
share-boss-worker = false
client-selector-thread-prefix = "NettyClientSelector"
client-selector-thread-size = 1
client-worker-thread-prefix = "NettyClientWorkerThread"
# netty boss thread size,will not be used for UDT
boss-thread-size = 1
#auto default pin or 8
worker-thread-size = 8
shutdown
# when destroy server, wait seconds
wait = 3
serialization = "seata"
compressor = "none"
service
vgroup_mapping.fsp_tx_group = "default"
default.grouplist = "127.0.0.1:8091"
enableDegrade = false
disable = false
max.commit.retry.timeout = "-1"
max.rollback.retry.timeout = "-1"
disableGlobalTransaction = false
client
async.commit.buffer.limit = 10000
lock
retry.internal = 10
retry.times = 30
report.retry.count = 5
tm.commit.retry.count = 1
tm.rollback.retry.count = 1
## transaction log store
store
## store mode: file、db
mode = "db"
## file store
file
dir = "sessionStore"
# branch session size , if exceeded first try compress lockkey, still exceeded throws exceptions
max-branch-session-size = 16384
# globe session size , if exceeded throws exceptions
max-global-session-size = 512
# file buffer size , if exceeded allocate new buffer
file-write-buffer-cache-size = 16384
# when recover batch read size
session.reload.read_size = 100
# async, sync
flush-disk-mode = async
## database store
db
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp) etc.
datasource = "dbcp"
## mysql/oracle/h2/oceanbase etc.
db-type = "mysql"
driver-class-name = "com.mysql.jdbc.Driver"
url = "jdbc:mysql://127.0.0.1:3306/seata"
user = "root"
password = "123456"
min-conn = 1
max-conn = 3
global.table = "global_table"
branch.table = "branch_table"
lock-table = "lock_table"
query-limit = 100
lock
## the lock store mode: local、remote
mode = "remote"
local
## store locks in user's database
remote
## store locks in the seata's server
recovery
#schedule committing retry period in milliseconds
committing-retry-period = 1000
#schedule asyn committing retry period in milliseconds
asyn-committing-retry-period = 1000
#schedule rollbacking retry period in milliseconds
rollbacking-retry-period = 1000
#schedule timeout retry period in milliseconds
timeout-retry-period = 1000
transaction
undo.data.validation = true
undo.log.serialization = "jackson"
undo.log.save.days = 7
#schedule delete expired undo_log in milliseconds
undo.log.delete.period = 86400000
undo.log.table = "undo_log"
## metrics settings
metrics
enabled = false
registry-type = "compact"
# multi exporters use comma divided
exporter-list = "prometheus"
exporter-prometheus-port = 9898
support
## spring
spring
# auto proxy the DataSource bean
datasource.autoproxy = false
- registry.conf:
registry
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "nacos"
nacos
serverAddr = "localhost:8848"
namespace = ""
cluster = "default"
eureka
serviceUrl = "http://localhost:8761/eureka"
application = "default"
weight = "1"
redis
serverAddr = "localhost:6379"
db = "0"
zk
cluster = "default"
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
consul
cluster = "default"
serverAddr = "127.0.0.1:8500"
etcd3
cluster = "default"
serverAddr = "http://localhost:2379"
sofa
serverAddr = "127.0.0.1:9603"
application = "default"
region = "DEFAULT_ZONE"
datacenter = "DefaultDataCenter"
cluster = "default"
group = "SEATA_GROUP"
addressWaitTime = "3000"
file
name = "file.conf"
config
# file、nacos 、apollo、zk、consul、etcd3
type = "file"
nacos
serverAddr = "localhost"
namespace = ""
consul
serverAddr = "127.0.0.1:8500"
apollo
app.id = "seata-server"
apollo.meta = "http://192.168.1.204:8801"
zk
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
etcd3
serverAddr = "http://localhost:2379"
file
name = "file.conf"
- Service类:
@Override
@GlobalTransactional(name = "fsp-create-order",rollbackFor = Exception.class)
public void create(Order order)
log.info("----->开始新建订单");
//新建订单
orderDao.create(order);
//扣减库存
log.info("----->订单微服务开始调用库存,做扣减Count");
storageService.decrease(order.getProductId(),order.getCount());
log.info("----->订单微服务开始调用库存,做扣减end");
//扣减账户
log.info("----->订单微服务开始调用账户,做扣减Money");
accountService.decrease(order.getUserId(),order.getMoney());
log.info("----->订单微服务开始调用账户,做扣减end");
//修改订单状态,从零到1代表已经完成
log.info("----->修改订单状态开始");
orderDao.update(order.getUserId(),0);
log.info("----->修改订单状态结束");
log.info("----->下订单结束了");
Seata原理:
-
Seata是一款开源的分布式事务解决方案, 致力于提供高性能和简单易用的分布式事务服务。Seata
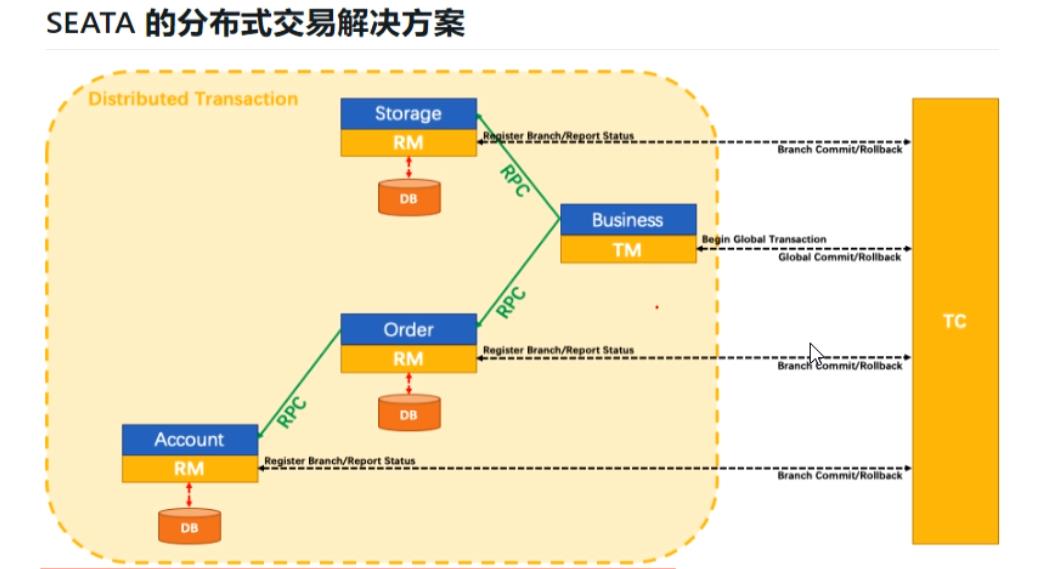
将为用户提供了AT、TCC、SAGA和XA事务模式,为用户打造一站式的分布式解决方案。 -
分布式事务的执行流程:
①TM开启分布式事务(TM向TC注册全局事务记录)。
②换业务场景,编排数据库,服务等事务内资源(RM向TC汇报资源准备状态)。
③TM结束分布式事务,事务一阶段结束(TM通知TC提交/回滚分布式事务)。
④TC汇总事务信息,决定分布式事务是提交还是回滚。
⑤TC通知所有RM提交/回滚资源,事务二阶段结束。
-
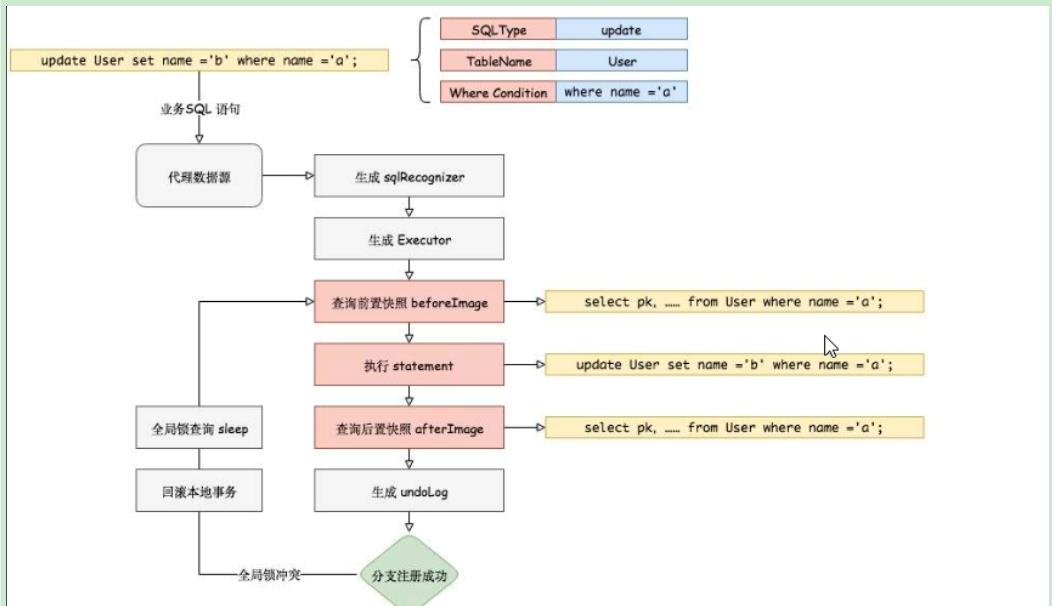
AT模式如何做到对业务的无侵入:其中AT模式的前提是一基于支持本地ACID事务的关系型数据库。二Java应用,通过JDBC访问数据库。
①整体机制为两阶段提交协议的演变:
<1>一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
<2>二阶段:
1、提交异步化,非常快速地完成。
2、回滚通过一阶段的回滚日志进行反向补偿。
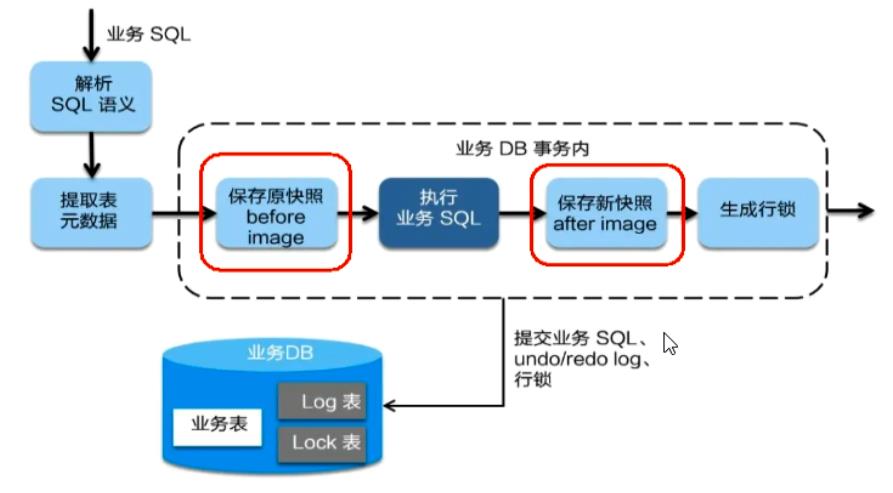
②一阶段加载:
<1>解析SQL语义,找到“业务SQL"要更新的业务数据,在业务数据被更新前,将其保存成"before image”,
<2>执行“业务SQL"更新业务数据,在业务数据更新之后,
<3>其保存成"after image" ,最后生成行锁。
<4>以上操作全部在一个数据库事务内完成,这样保证了-阶段操作的原子性。
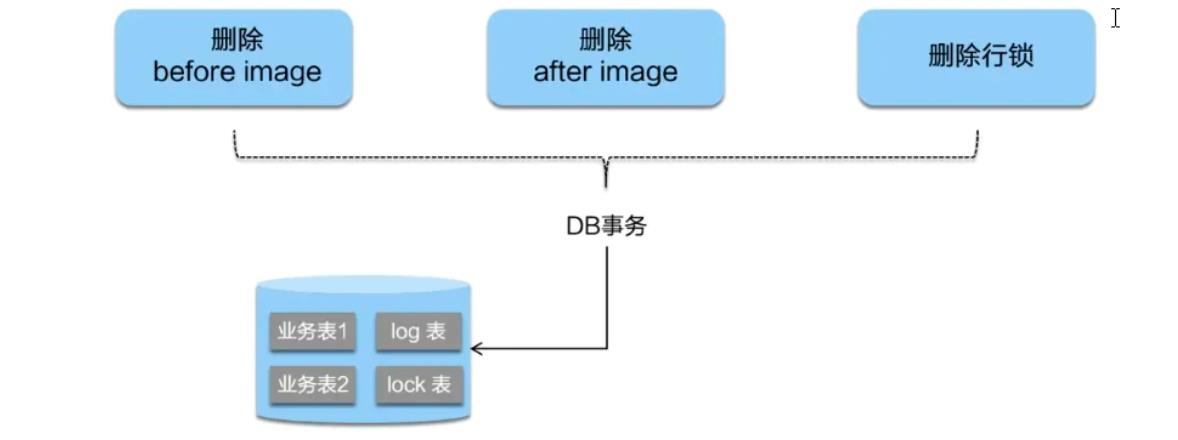
③二阶段提交:
<1>二阶段如是顺利提交的话,因为“业务SQL" 在一 阶段已经提交至数据库,所以Seata框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可。
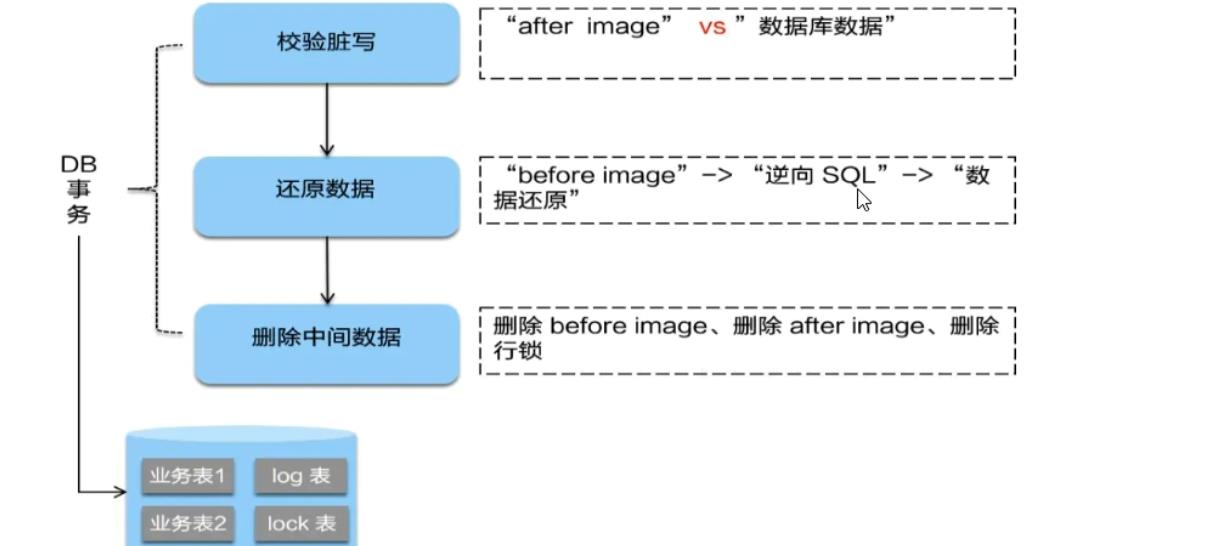
④二阶段回滚:
<1>二阶段如果是回滚的话,Seata就需要回滚一阶段已经执行的“业务SQL” ,还原业务数据。回滚方式便是用"before image"还原业务数据;但在还原前要首先要校验脏写,对比“数据库当前业务数据”和"after image” ,如果两份数据完全一 致就说明没有脏写,可以还原业务数据,如果不一 致就说明有脏写,出现脏写就需要转人工处理。
-
补充:

以上是关于SpringCloudAlibaba知识概括的主要内容,如果未能解决你的问题,请参考以下文章