LinuxBPF学习笔记 - 性能分析方法论[5]
Posted 宣之于口
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LinuxBPF学习笔记 - 性能分析方法论[5]相关的知识,希望对你有一定的参考价值。
本学习笔记来自于阅读 Brendan Gregg的《BPF Performance Tools》
一、工作负载
建议执行工作负载特征的步骤:
- 谁造成了负载: PID,进程名称,UID,IP地址…
- 为什么称负载: 代码路径,堆栈跟踪,火焰图
- 负载是多少: IOPS,吞吐量,类型
- 负载如何随时间变化: 每个时间间隔的摘要
示例: 这表明在跟踪时,名为"Web Content" 的进程执行了1,725个vfs_read()
bpftrace -e 'kprobe:vfs_read @[comm] = count(); '
# output
“@[rtkit-daemon]: 1
[...]
@[gdbus]: 819
@[Web Content]: 1725
二、深入分析
这种方法包括检查一个指标,然后找到将其分解成其组成部分,将最大的组成部分分解成其自己的组成部分的方法,依此类推,直到找到根本原因为止。
类推可能有助于解释这一点。 想象一下,您发现自己的信用卡账单非常大。 要对其进行分析,您登录到银行并查看交易。 在那里,您发现向在线书店收取的一笔大笔费用。 然后,您登录到该书店,查看导致该数量的书,并发现您不小心购买了该书的一千本。 这是深入分析:找到线索,然后在更多线索的带领下进行更深入的钻探,直到问题解决。
步骤: 这通常需要定制工具, bpftrace更适合使用
- 从最高级别开始
- 检查下一级的详细信息
- 选择最有趣的故障或线索
- 如果问题仍然存在,请返回步骤2
示例1: 将延迟分解为其组件的贡献, 您在这里的结论可能是存储设备是问题所在,这就是答案之一
- 请求等待时间为100毫秒
- 在CPU上运行10毫秒, 阻塞90毫秒
- 在文件系统上,关闭CPU的时间为89毫秒
- 文件系统在锁定上花费了3毫秒,在存储设备上花费了86毫秒
示例2: 深入分析也可以用来增强上下文. 现在的结论是,文件系统访问时间戳是延迟的来源,可以被禁用(这是安装选项)。 与得出更快的磁盘速度是必要的结论相比,这也是更好的结果
- 应用程序在文件系统上花费了89毫秒
- 文件系统在写入文件系统时花费了78毫秒,在读取时阻塞了11毫秒
- 文件系统写入在访问时间戳记更新上花费了77毫秒
三、使用方法
以资源分析开发为例, 对于每种资源,请检查:1) 利用率; 2) 饱和度; 3) 错误
您的第一个任务是查找或绘制软件和硬件资源图。 然后,您可以遍历它们,以寻求这三个指标, 下图显示了通用系统的硬件目标示例,包括可以检查的组件和总线
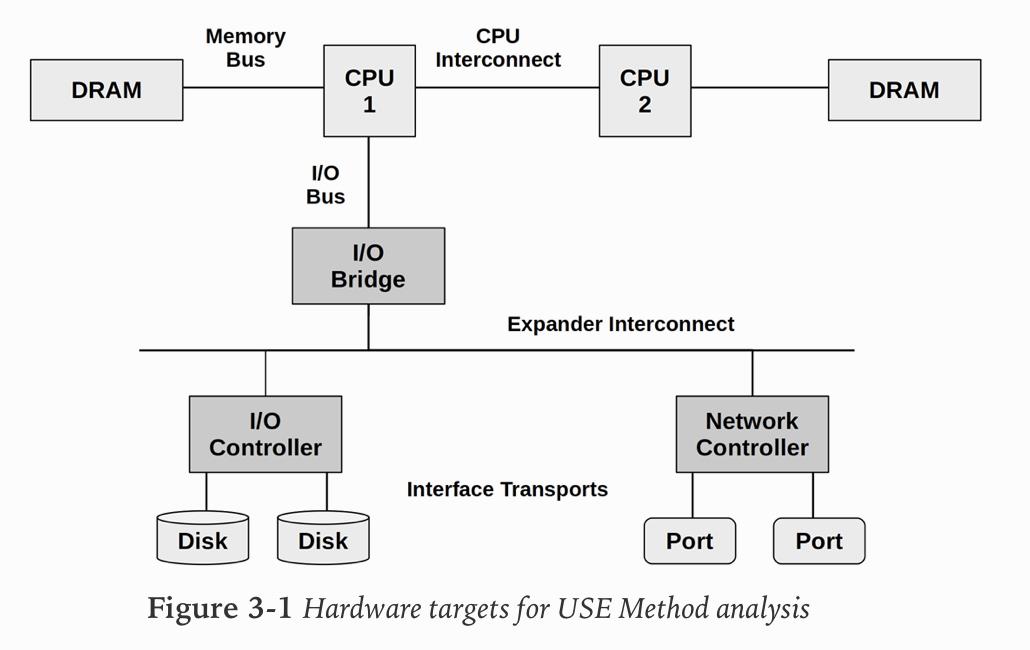
考虑一下您当前的监视工具及其显示上图中每个项目的利用率,饱和度和错误的能力:您当前有多少个盲点?
这种方法的优势在于,它从重要的问题开始,而不是以度量形式的答案开始,然后尝试倒退以找出它们为什么重要。 它还显示了盲点:从您要回答的问题开始,是否有方便的工具来衡量它们
四、工具
性能分析清单可以列出要运行和检查的工具和指标,
1. LINUX 60-SECOND ANALYSIS
此清单可用于任何性能问题,并反映了我通常在登录性能不佳的Linux系统后的最初60秒内执行的操作
uptime | 当前时间,系统已经运行了多久,用户连接数,系统在过去1,5,15分钟内的平均负载 |
dmesg | tail | 用于显示开机信息 |
vmstat 1 | 显示Linux系统虚拟内存状态,也可以报告关于进程、内存、I/O等系统整体运行状态 |
mpstat -P ALL 1 | 报告CPU的一些统计信息 |
pidstat 1 | 监控全部或指定进程的cpu、内存、线程、设备IO等系统资源的占用情况 |
iostat -xz 1 | 显示磁盘的IO |
free -m | 显示的当前内存的使用 |
sar -n DEV 1 | 显示网络接口信息 |
sar -n TCP,ETCP 1 | TCP统计信息, TCP错误统计信息 |
top | 显示系统上正在运行的进程 |
2. BCC TOOL CHECKLIST
这里工具可以参考: GIT
execsnoop: 通过为每个execve系统调用打印一行输出来显示新的进程执行。 检查进程是否短暂.
opensnoop: 为每个open系统调用(及其变体)打印一行输出,包括打开的路径的详细信息以及它是否成功
ext4slower: 跟踪ext4文件系统中的常见操作(读取,写入,打开和同步),并打印超出时间阈值的操作。 这可以识别或消除一种类型的性能问题:应用程序通过文件系统等待缓慢的单个磁盘I/O
biolatency: 跟踪磁盘I/O延迟,即从设备发布到完成的时间,并将其显示为直方图
biolatency -m
Tracing block device I/O... Hit Ctrl-C to end.
^C
msecs : count distribution
0 -> 1 : 16335 |****************************************|
2 -> 3 : 2272 |***** |
4 -> 7 : 3603 |******** |
[...]
512 -> 1023 : 1 | |
biosnoop: 为每个磁盘I/O打印一行输出,详细信息包括延迟。 这样一来,您可以更详细地检查磁盘I/O,并查找按时间顺序排列的模式(例如,在写入之后进行读取队列)
cachestat: 每秒(或每个自定义间隔)打印一行摘要,显示文件系统缓存中的统计信息。 使用它可以确定较低的缓存命中率和较高的未命中率
cachestat
HITS MISSES DIRTIES HITRATIO BUFFERS_MB CACHED_MB
53401 2755 20953 95.09% 14 90223
49599 4098 21460 92.37% 14 90230
[...]
tcpconnect: 为每个活动的TCP连接打印一行输出,详细信息包括源地址和目标地址。 寻找可能会导致应用程序配置效率低下的意外连接或入侵者
tcpaccept: 是tcpconnect的配套工具。 它为每个被动TCP连接(e.g. accept())打印一行输出,详细信息包括源地址和目标地址
tcpretrans: 为每个TCP重传数据包打印一行输出,详细信息包括源地址和目标地址以及TCP连接的内核状态。 TCP重传会导致延迟和吞吐量问题。 对于已建立TCP会话状态的重传,请查找外部网络是否有问题
runqlat: 线程等待打开CPU的时间,然后将此时间打印为直方图。 可以使用此工具确定等待CPU访问的时间长于预期,该等待时间可能由于CPU饱和,配置错误或调度程序问题而受到影响
profile: 是一个CPU事件探查器,它是了解哪些代码路径正在消耗CPU资源的工具。 它以一定时间间隔获取堆栈跟踪的样本,并打印出唯一堆栈跟踪的摘要以及它们的出现次数
以上是关于LinuxBPF学习笔记 - 性能分析方法论[5]的主要内容,如果未能解决你的问题,请参考以下文章