分布式id 生成器实现
Posted 史上最强的弟子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式id 生成器实现相关的知识,希望对你有一定的参考价值。
随着业务的扩展的需要,分库是很多业务必不可少的操作,而分完库之后分布式id 生成缺成了一个问题,需要分布式id 服务生成。
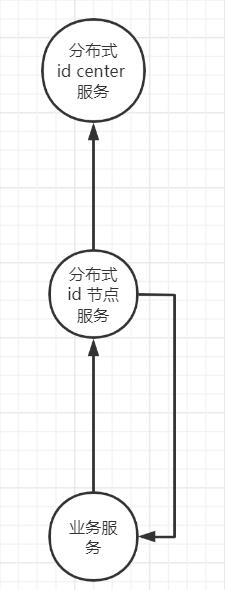
1.获取分布式id 角色会有三个角色,分为:业务服务,分布式id节点服务,分布式id 中心服务。
2. 请求流程两个流程:
业务服务 --> 分布式id节点服务获取号码(根据号码段和号码规则还有set 编号生成id)。
业务服务 --> 分布式id节点服务获取号码 ->分布式id 中心服务获取号码段及号码规则。
3.号码规则:
前缀+时间戳+唯一编号
4.数据库设计
4.1 tb_id_config id 配置
| Field name | Type | Comment | Remark |
|---|---|---|---|
| id | PK | ||
| table_name | String | 表名 | |
| service_name | String | 服务名 | |
| colum_name | String | id,number | |
| init_number | int | 初始值 | |
| add_number | int | 增值 | |
| create_time | dateTime | 创建时间 | |
| update_time | dateTime | 修改时间 |
4.2.tb_id_config_regular id 配置规则
| Field name | Type | Comment | Remark |
|---|---|---|---|
| id | PK | ||
| type | Integer | 1.前缀,2.时间戳,3.号码段 | |
| keywords | String | 关键词(前缀时) | |
| create_time | dateTime | 创建时间 | |
| update_time | dateTime | 修改时间 |
4.3.tb_id_operator_log id 操作log 日志
| Field name | Type | Comment | Remark |
|---|---|---|---|
| id | PK | ||
| config_id | FK | tb_id_config id | |
| unique_key | String | 唯一key | |
| min_number | Integer | 号段最小值 | |
| max_number | Integer | 号段最大值 | |
| config_number | Integer | 配置号(获取号段的redis 分布式节点服务号) | |
| create_time | dateTime | 创建时间 | |
| update_time | dateTime | 修改时间 | |
| version | Integer | 数据版本 |
4.4 插入log ,在通过unique_key 查询出来,这个是针对每个分布式id节点服务请求生成的唯一键
EXPLAIN
INSERT INTO `tb_id_operator_log` ( `config_id`, `unique_key`, `min_number`, `max_number`, create_time, update_time ) SELECT
1,
2,
min_number + 1000,
max_number + 1000,now(),now()
FROM
tb_id_operator_log
WHERE
config_id = 1
ORDER BY
id DESC
LIMIT 14.5分布式id节点服务,会把号段信息以及号配置信息存放到redis 计数器中,业务来一个请求redis 计数器获取后+1,注意这里当号段使用号段到60%,需要缓存下一个号端,避免使用完了,或者是等待中心发号段。
以上是关于分布式id 生成器实现的主要内容,如果未能解决你的问题,请参考以下文章