DUMA: Reading Comprehension with Transposition Thinking
Posted Facico
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DUMA: Reading Comprehension with Transposition Thinking相关的知识,希望对你有一定的参考价值。
DUMA: Reading Comprehension with Transposition Thinking
验证了我看完DCMN+的猜想,将复杂的DCMN+的模型换上了attention(和DCMN+一样都是上交发的。。。感觉是故意的)
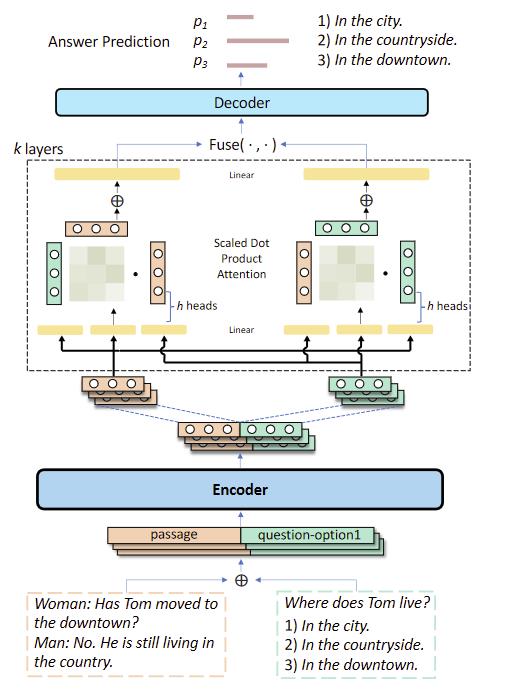
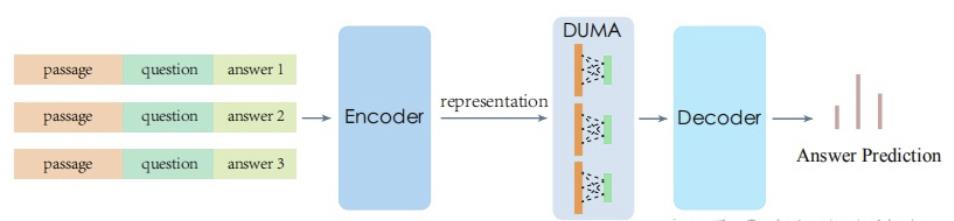
- encoder接一个预训练模型
- decoder来预测答案
- 两层之间加一个Dual Multi-head Co-Attention (DUMA) layer
Encoder
还是拼接
P
=
[
p
1
,
p
2
,
.
.
.
,
p
m
]
,
Q
=
[
q
1
,
q
2
,
.
.
.
,
q
n
]
,
A
=
[
a
1
,
a
2
,
.
.
.
,
a
k
]
E
=
E
n
c
(
P
⊕
Q
⊕
A
)
=
[
e
1
,
e
2
,
.
.
.
,
e
m
+
n
+
k
]
P=[p_1,p_2,...,p_m],Q=[q_1,q_2,...,q_n],A=[a_1,a_2,...,a_k]\\\\ E=Enc(P\\oplus Q \\oplus A)=[e_1,e_2,...,e_m+n+k]
P=[p1,p2,...,pm],Q=[q1,q2,...,qn],A=[a1,a2,...,ak]E=Enc(P⊕Q⊕A)=[e1,e2,...,em+n+k]
Dual Multi-head Co-Attention 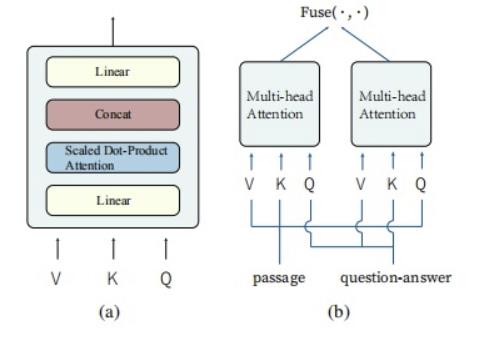
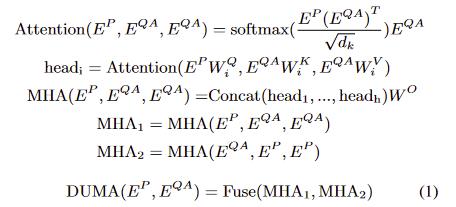
- 将encoder outputs分成P部分和QA部分,P作为Query,QA作为Key和Value
Fuse操作
MHA:Multi-head Attention
- 1、在最后的Fuse操作前,先对每个MHA进行mean pooling
- 2、然后对pooling后的output做fusing
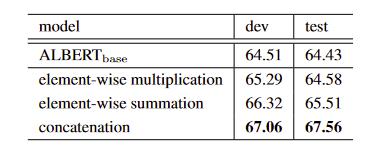
fusing作者尝试过
- element-wise multiplication
- element-wise summation
- concatenation
Decoder
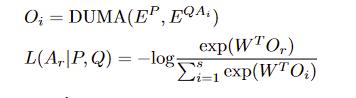 - 通过全连接再softmax得
- 通过全连接再softmax得
实验
参数量
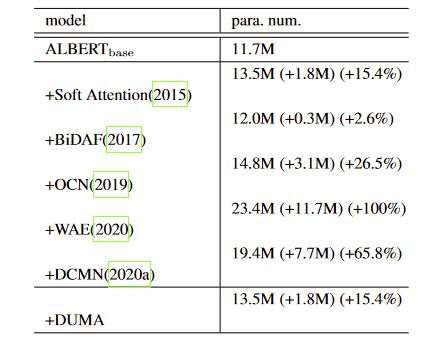
fuse的方法
DUMA的层数
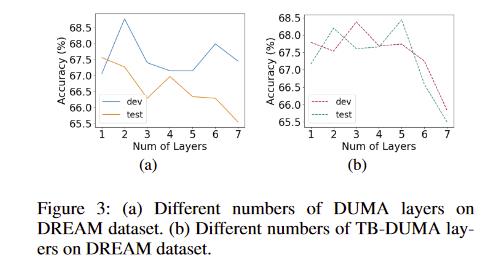
)
+DUMA的效果
在这里插入图片描述
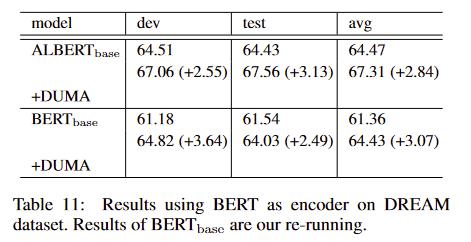
- 效果不错,比DCMN+好,参数量还少,但感觉attention的构造有点粗暴了,相信后面会有更巧妙的构造
以上是关于DUMA: Reading Comprehension with Transposition Thinking的主要内容,如果未能解决你的问题,请参考以下文章