《BEV LaneDet:Fast Lane Detection on BEV Ground》论文笔记
Posted m_buddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《BEV LaneDet:Fast Lane Detection on BEV Ground》论文笔记相关的知识,希望对你有一定的参考价值。
参考代码:bev_lane_det(截止2022.11.01未开源)
1. 概述
介绍:这篇文章是毫末科技在单目场景下在bev视图下实现车道线检测的方法,其车道线检测的基础方法是源自于bev视图下车道线分割,再通过预测几个附加预测头用于辅助后处理。具体来讲这篇文章的工作可以划分为3点。1)这篇文章将图像坐标下的特征转换为bev坐标下使用的是全连接的形式,也就是直接通过学习的方式得到一个固定相机参数下的转换关系(这是出于实际部署与计算性能的考量),这样就可以不同显式去编码相机参数。同时为了增强特征表达使用了多个尺度的特征。2)由于使用全连接的方式学习相机坐标到bev坐标的映射关系,因较难同时编码相机参数等几何信息,所以文章将所涉及到的图像依据相机参数统一变换到virtual camera下,从而实现感知视角统一。3)文中对于车道线的感知基础是车道线语义分割(confidence),同时还会预测车道线偏移量(offset)、车道线实例辅助信息(embedding,可参考LaneDet方法实现)、车道线高度信息(height)。此外文中还是用一个小trick,便是在图像坐标添加了车道线语义分割和实例信息头,用于优化图像特征提取。
2. 方法设计
2.1 整体pipeline
这篇文章的算法整体流程见下图所示:
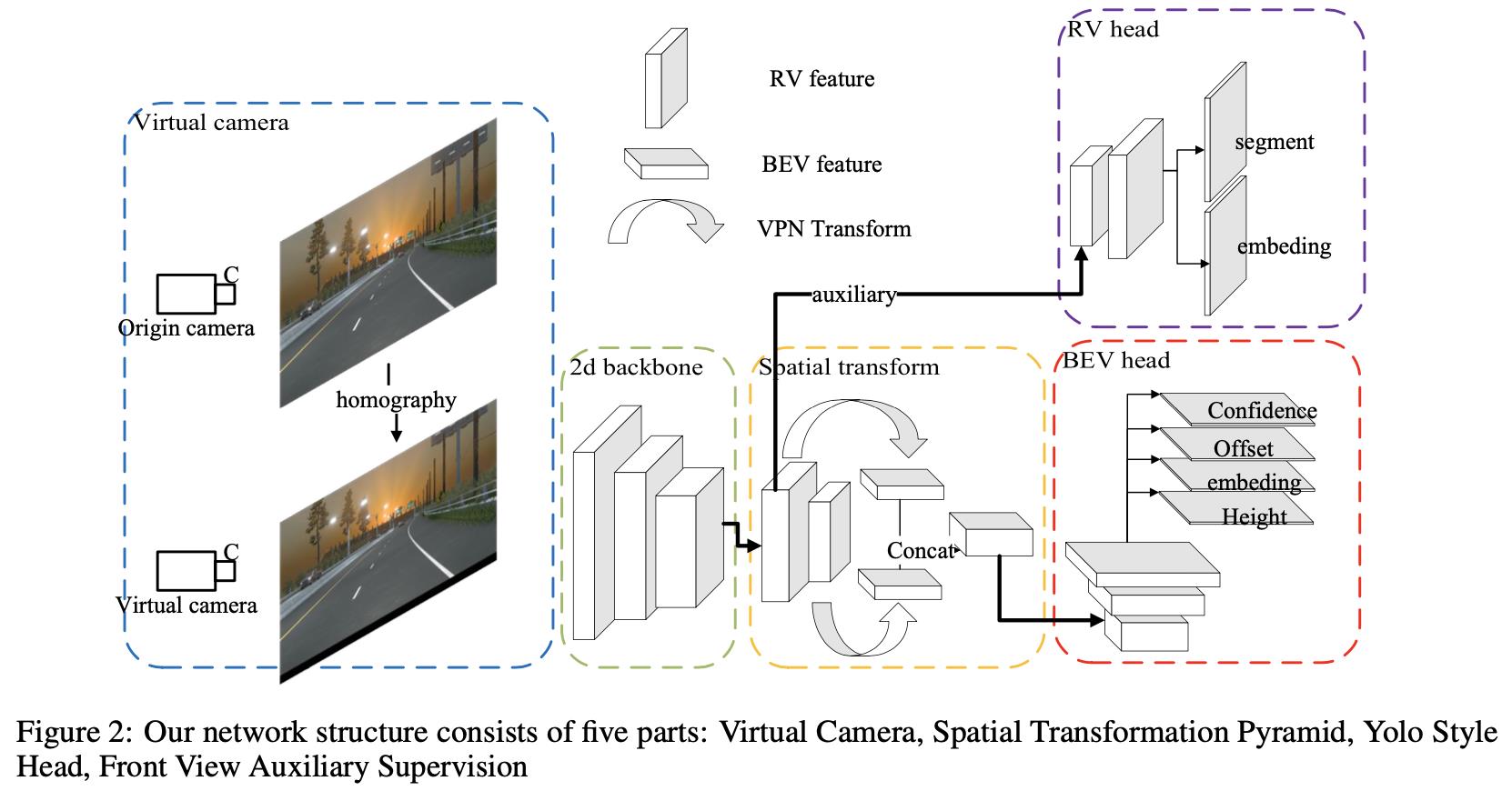
按照上图中的箭头朝向可以将整体流程划分为如下几个步骤:
- 1)图像往virtual camera下转换:在文中由于没有显式编码相机参数信息,直接是采用全连接层拟合的,这就需要保证输入的相机内外参数是一致的,使得整体网络不是那么难学习。因而在数据处理阶段会将图像往virtual camera下映射,这里做的过程是乘上一个单应矩阵。
- 2)2D特征到BEV特征转换:这里使用了两个stage的特征作为输入构建多尺度特征金字塔(用的都是大stride的特征图,因为语义信息更多更好学习),之后经过全连接层实现2D特征到bev特征的转换。
- 3)网络预测:这里的预测包含2个部分:bev特征下的预测和2D特征下的预测。bev下借鉴YOLO检测算法中的回归机制实现车道线预测,也就是分别预测confidence、offset、embedding、height。2D特征下是作为辅助损失形式添加到网络中用于提供更好特征表达,其预测车道线语义分割和实例embedding信息。
2.2 virtual camera
在文中设与车形式方向垂直的是
y
y
y方向,车行进方向为
x
x
x,则这里需要感知的范围是
x
∈
[
3
m
,
100
m
]
,
y
∈
[
−
10
m
,
10
m
]
x\\in[3m,100m],y\\in[-10m,10m]
x∈[3m,100m],y∈[−10m,10m],bev下最小的网格单元为
0.5
∗
0.5
m
2
0.5*0.5m^2
0.5∗0.5m2,也就是bev网格的大小为
(
s
1
=
200
,
s
2
=
40
)
(s_1=200,s_2=40)
(s1=200,s2=40)。在
z
=
0
z=0
z=0的平面
P
r
o
a
d
P_road
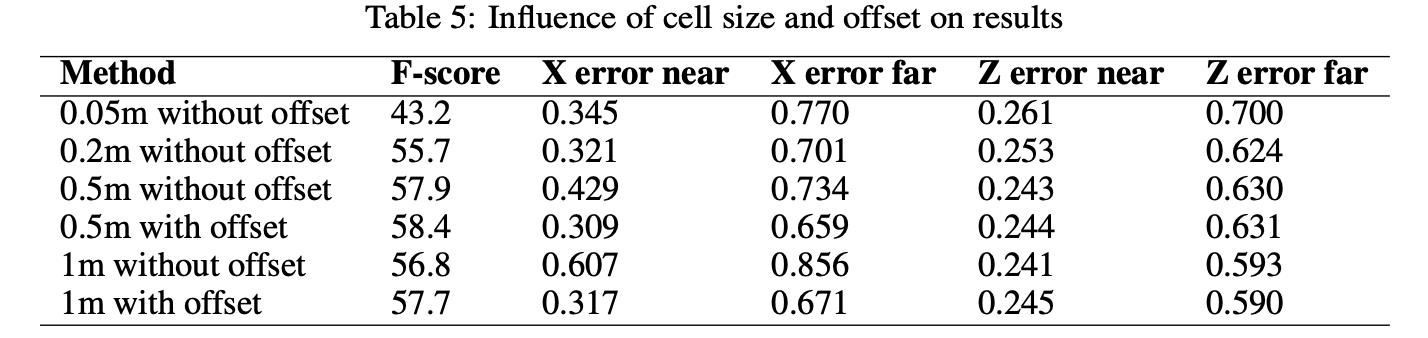
Proad为当前车点处相对道路平面的切面,高度的计算便是基于此为标准计算得到的。这里补充网格单元大小对向能带来的影响:
在数据集中或是在实际算法部署中相机的参数是各式各样的,为了降低网络学习2D到bev空间转换的难度这里添加了virtual preprocess的处理过程。首先对于virtual camera是通过统计手段对数据集中的相机内参和外参计算均值作为其相机参数,从而得到
K
i
,
[
R
i
∣
T
i
]
K_i,[R_i|T_i]
Ki,[Ri∣Ti]。由于是以
P
r
o
a
d
P_road
Proad作为基准,因而这里在该平面上采样几个点
k
i
=
(
x
i
,
y
i
,
0
)
,
k
=
1
,
2
,
3
,
4
k_i=(x_i,y_i,0),k=1,2,3,4
ki=(xi,yi,0),k=1,2,3,4,分别通过相机内外参数映射得到对应成像平面的坐标,之后将这些坐标值带入计算出两个camera中图像坐标的变换关系(这里使用单应个人理解为在深度未知情况下实现稠密对齐):
H
i
,
j
u
i
k
=
u
j
k
H_i,ju_i^k=u_j^k
Hi,juik=ujk
2.3 2D特征到BEV特征
2D特征到BEV实际是坐标的转换,在这篇文章中使用全连接的形式实现坐标转换,同时还使用了多个尺度的特征作为信息来源。其过程见下图所示:
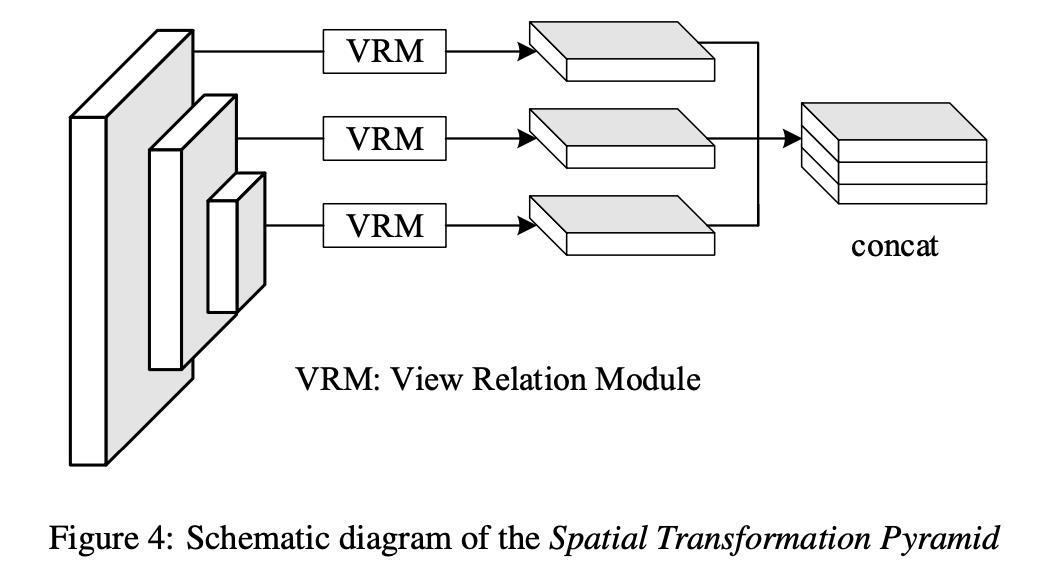
在上图中画了3个VRM(View Relation Module),而实际上使用了两个(分别是stride为32和64的特征),使用这么小的分辨率是因为对网络来讲更好学习。那么通过全连接形式得到的bev特征描述为:
f
t
[
i
]
=
c
o
n
c
a
t
(
R
i
s
32
(
f
s
32
[
1
]
)
,
…
,
f
s
32
[
H
W
s
32
]
)
,
R
i
s
64
(
f
s
64
[
1
]
)
,
…
,
f
s
64
[
H
W
s
64
]
)
f_t[i]=\\mathcalconcat(R_i^s32(f^s32[1]),\\dots,f^s32[HW^s32]),R_i^s64(f^s64[1]),\\dots,f^s64[HW^s64])
ft[i]=concat(Ris32(fs32[1]),…,fs32[HWs32]),Ris64(fs64[1]),…,fs64[HWs64])
2.4 BEV下车道线检测
在3D车道线预测部分采用的是类似YOLO的检测方案,其包含了预测是否为车道线 (confidence)、距离具体车道线的偏移(offset)、车道线实例信息(embedding)和车道线高度信息(height of lane)。对于其中的前三个其预测流程见下图所示: 以上是关于《BEV LaneDet:Fast Lane Detection on BEV Ground》论文笔记的主要内容,如果未能解决你的问题,请参考以下文章
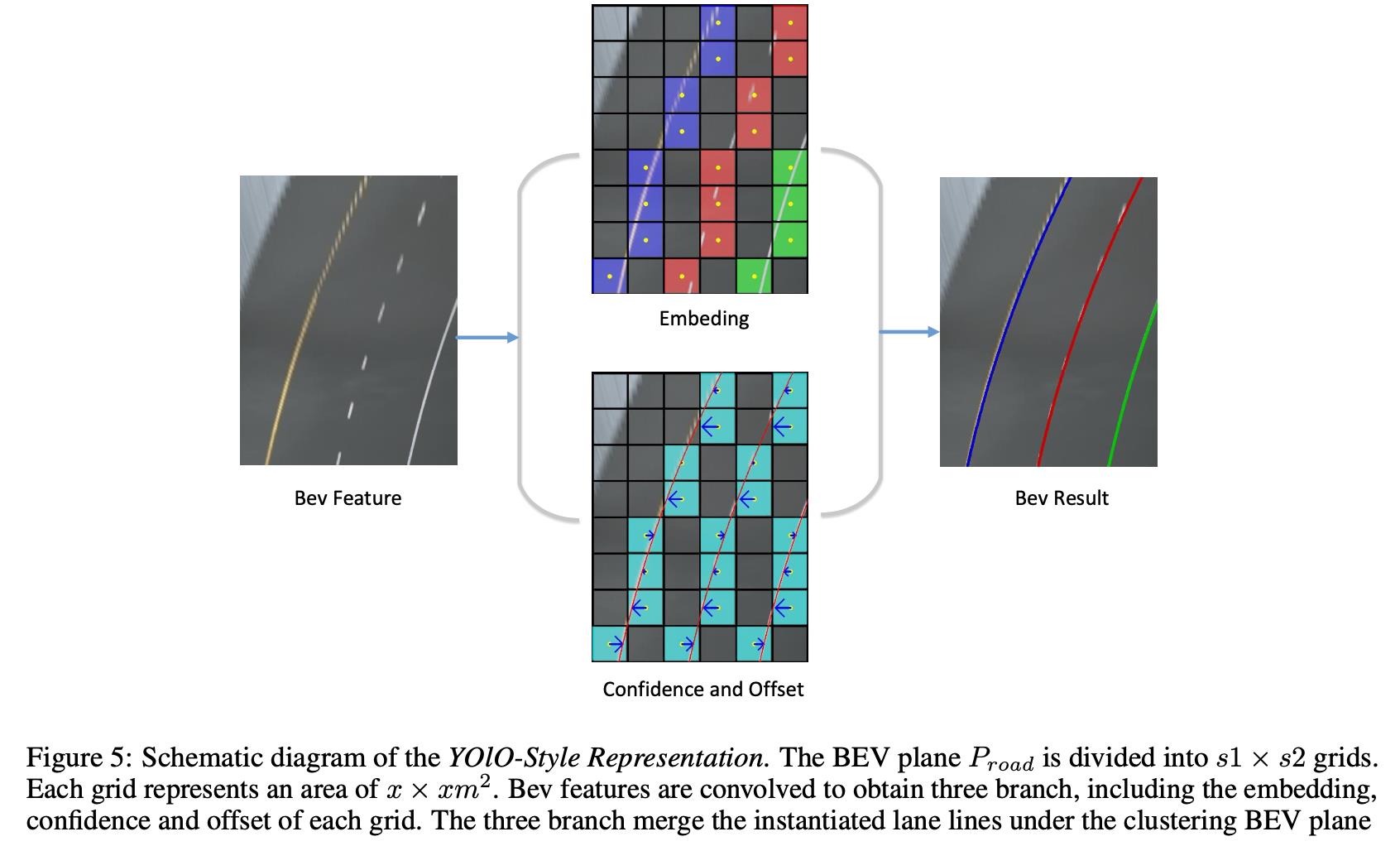
confidence:
这里使用二值分割描述对应bev grid是否为车道线上的点(bev上的某个grid),使用交叉上损失进行监督
L
c
o
n
f
3
d
=
∑
i
s
1
∗
s
2
(
p
^
i
l
o
g
p
i
+
(
1
−
p
i
^
)
l
o
g
(
1
−
p
i
)
)
L_conf^3d=\\sum_i^s_1*s_2(\\hatp_ilogp_i+(1-\\hatp_i)log(1-p_i))
Lconf3d=i∑s1∗s2(p^ilogpi+(1−pi^)log(1−pi))
offset:
这一项代表的是车道线上的点(bev上的某个grid)中心距离车道线的偏移量,这样可以更加准确预测车道线的未知,避免量化误差。
L
o
f
f
s
e
t
3
d
=
∑
i
s
1
∗
s
2
1
o
b
j
(
σ
(
Δ
y
i
)
−
Δ
y
^
i
)
2
L_offset^3d=\\sum_i^s_1*s_2\\mathcal1_obj(\\sigma(\\Delta y_i)-\\Delta\\haty_i)^2
Loffset3d=i∑s1∗s21obj(σ(Δyi)−Δy^i)2
embedding:
在得到车道线基础上还需要得到车道线的实例信息,对此这里参考LaneDet中的方法使用embedding的方式学习线的聚类信息。首先需要拉近同一根车道线的特征表达:
L
v
a
r
3
d
=
1
C
∑
c
=
1
C
1
N
c
∑
j
=
1
N
c
[
∣
∣
μ
c
−
f
j
i
n
s
t
a
n
c
e
∣
∣
−
δ
v
]
+
2
L_var^3d=\\frac1C\\sum_c=1^C\\frac1N_c\\sum_j=1^N_c[||\\mu_c-f_j^instance||-\\delta_v]_+^2
Lvar3d=C1c=1∑CNc1j=1∑Nc[∣∣μc−fjin