个推数据智能技术实践 | 教你打造数据质量心电图,智能检测数据“心跳”异常
Posted 个推技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了个推数据智能技术实践 | 教你打造数据质量心电图,智能检测数据“心跳”异常相关的知识,希望对你有一定的参考价值。
个推拥有丰富的数据资源,通过知识挖掘、机器学习等技术,提炼数据价值,为行业客户提供数据智能产品和解决方案。为更好地保障自身数据质量,为合作伙伴提供更加优质的数据智能服务,个推构建了数百个指标对数据质量进行监控,并形成“数据质量心电图”,可视化地展现日增数据量、数据总量变化趋势等情况,帮助相关人员更直观地发现数据异常点,及时感知数据质量。
每天通过人工去观察和分析庞大的指标,会占用很多人力资源。如何通过智能化的方式高效且准确地识别出数据异常点?本文将个推在数据异常点智能检测方面的实践做了总结,与大家分享个推的数据质量保障经验。

四种常见的指标异常
首先,根据个推业务场景,我们总结并定义出了四种常见的数据指标异常类型,分别是单点指标异常、周期指标异常、阶梯指标异常、连续指标异常。
第一类:单点指标异常
单点指标异常是指在大多数时间内都保持相对平稳的数据,在某一时间点突然发生较大波动。
以个推用户画像数据为例,个推将画像标签数据分为冷、温、热三种,其中“ 冷数据”指的是性别、年龄阶段等在很长一段时间内不会发生较大变化的一类数据。但是,如果相关特征数据缺失,冷数据的标签量级会骤降。这种情况下就会产生单点异常的情况。
由于异常点的值会极大地偏离整体数据区间,所以这一类指标异常点比较容易判别。
第二类:周期指标异常
周期异常是指数据整体具有周期特性,在数据曲线上能明显看出周期性起伏,异常点数值虽然处于正常的数据区间,但是不符合一贯的周期波动规律。
比如,办公类App的日活数据就具有典型的周期特性,一般来讲办公类App周一至周五的日活较高,周末的日活较低。如果办公类App在周末或假期期间,日活突然升高,甚至超过工作日,那么我们就可以认为出现了周期数据异常点。
第三类:阶梯指标异常
这一类的异常其实并非都是问题数据。例如系统接入外部的广告流量后,数据曲线骤升,然后在高点保持正常波动。一段时间后,外部流量接入暂停,数据曲线骤降,然后在骤降点附近维持正常波动。类似场景下,数据曲线整体呈阶梯化走势。
一般来讲,有外部流量接入是正向反馈,但底层数据量突然增加,还是需要及时关注,以便更好地分析业务发展。
第四类:连续指标异常
连续异常是指在一段时间内连续发生的异常。例如我们在进行新老系统版本切换的过程中,老版本的日活数据会连续下降,直到切换完成后趋于稳定。那么,在切换过程中连续下降的所有点都应视为异常点。
此类数据异常对业务影响较大,我们需要挖掘异常原因并积极解决。
异常指标智能检测实践
针对以上四种数据指标异常,我们通过算法和统计学的方法进行智能检测。目前常用的几种异常值检测方法,在之前的文章中详细介绍过,大家可以点击阅读 >> 大数据科学家需要掌握的几种异常值检测方法。
这些异常值检测方法在个推的实际应用效果如何?四种数据指标异常的智能检测思路有哪些不同?接下来为大家一一介绍。
1. 单点指标及连续指标异常(有一定规律)检测
以个推部分SDK的日活数据为例,某App在集成个推SDK过程中遇到问题,导致日活数据曲线出现一个连续骤降点A;后续一次系统故障又导致了SDK日活数据曲线再次骤降(产生骤降点B),并出现极小值点C。那么在骤降点A、骤降点B和极小值点C之间的数值就是我们要检测找出的异常点。
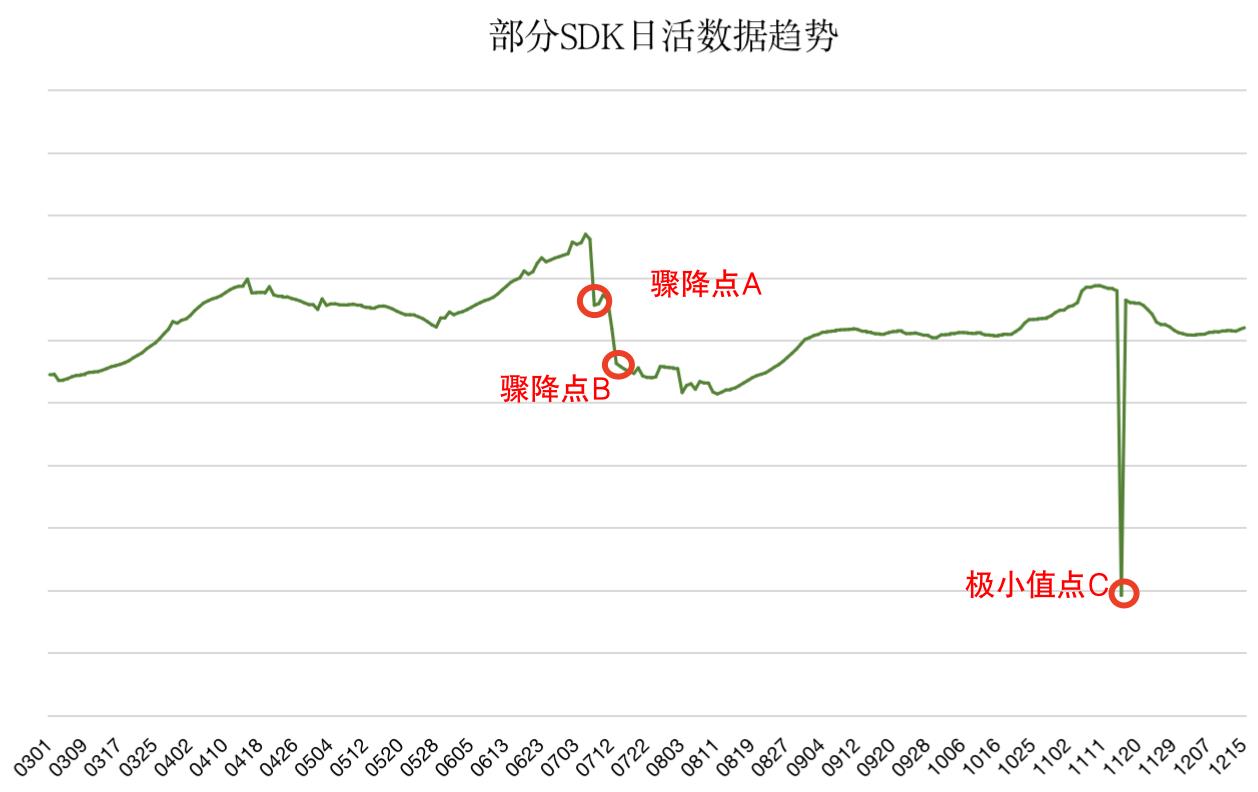
通常来说,使用统计模型或机器学习模型就可以将系统故障产生的极度明显的单点异常识别出来。如下图,使用3σ统计方法和孤立森林模型均可感知到系统故障产生的极小值点C。
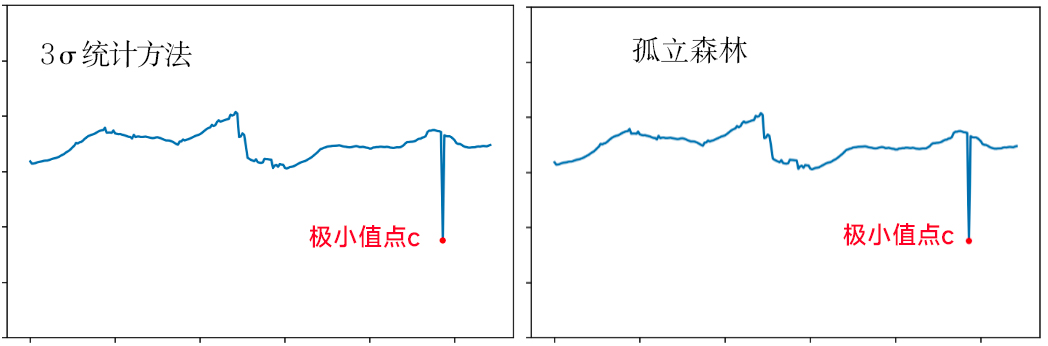
然而,因为集成问题所产生的骤降点A和骤降点B并未能被识别出来。这些骤降点背后的原因对我们迭代产品设计有非常重要的参考价值,所以我们要优化检测方法,使模型能准确识别到骤降点A和骤降点B。
分析之前的检测方案,我们发现骤降点A和B的数值都在正常的数据波动区间内,所以统计方法没有将骤降点A和B分到3σ外,孤立森林模型也无法将它们视为离群点(即异常点)。
针对此问题,我们对输入模型的特征进行了调整,将单一的数据值替换为数据值+波动值的二维特征,对指标的波动率也赋予权重,使其参与模型计算;并保证在模型参数完全一致的情况下,利用二维特征的孤立森林进行对 比。
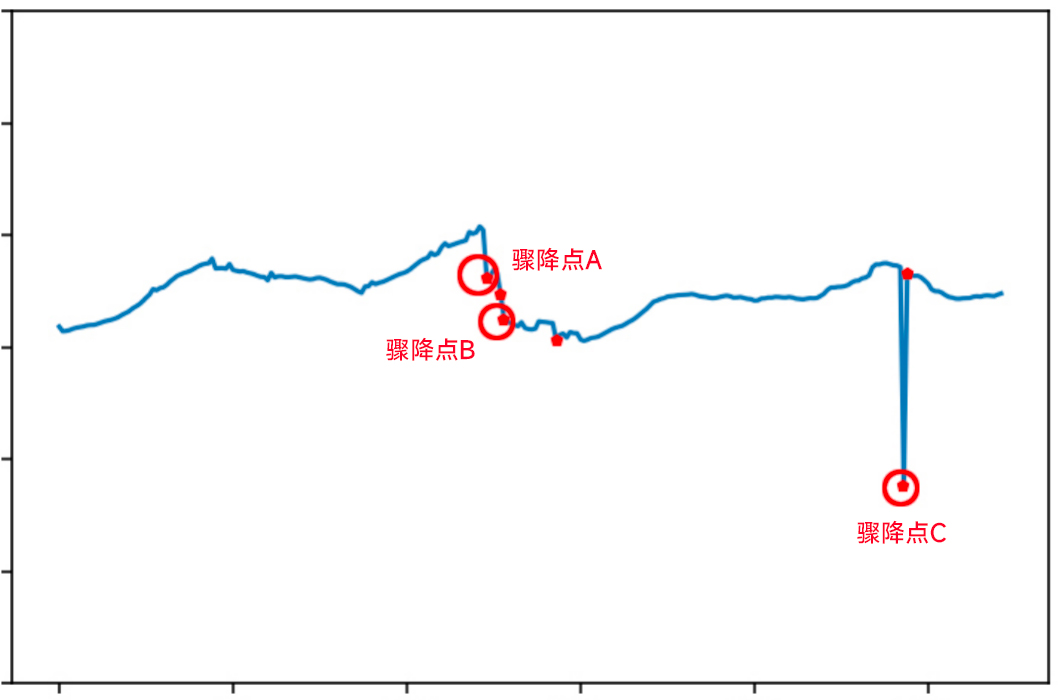
上图展示了模型优化后的检测效果。可以明显看出,在模型参数一致的情况下,连续下降的那些异常值能够被准确地识别出来,由于系统故障产生的极小值点也可以成功地被检测。优化后的模型识别效果比较符合指标检测要求。
经验总结
单点指标异常:针对此类明显偏离正常数据区间的单点异常值(其他时间段的数据保持稳定),使用统计类模型就能识别和检测出来。
连续指标异常:因为数据值在正常区间内,所以这类异常值较为隐藏,需要将波动率融入特征,参与孤立森林模型计算才能识别。
2. 连续指标异常(无明显规律)检测
刚才提到的连续指标异常,是在数据曲线整体比较有规律的情况下发生的,所以较容易被识别;但是在数据整体曲线无明显规律的情况下,数据波动较大,连续指标异常的识别就相对困难一些。
比如,个推某汇总层(DWS层)的上游数据源头众多,逻辑复杂。任何一个上游数据的变化都会对汇总层产生直接影响,所以整体数据曲线起伏较大且无明显规律,直观上看存在比较多的异常点。但是数据源改动或上线优化等造成的波动都远大于日常波动,所以我们需要智能识别出这些由于底层原因导致的较大波动,及时评估影响,做好应对方案。
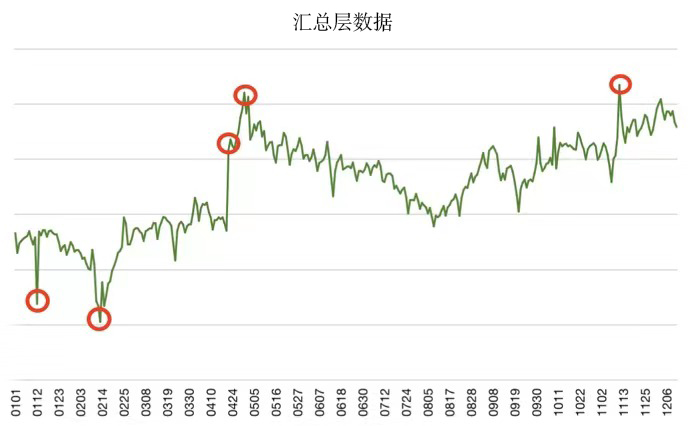
由于汇总层数据整体无明显的规律性,异常点数值跨度比较大且异常点较多,极易使数据的正常区间发生偏移,从而导致异常指标被误判为合理指标。对于这类数据,我们使用局部异常因子算法(LOF),依靠模型计算局部密度的特性,通过不同区域的数据密度找出异常点。
从效果来看,人为认定的异常指标都可以被LOF模型准确识别,如下图:
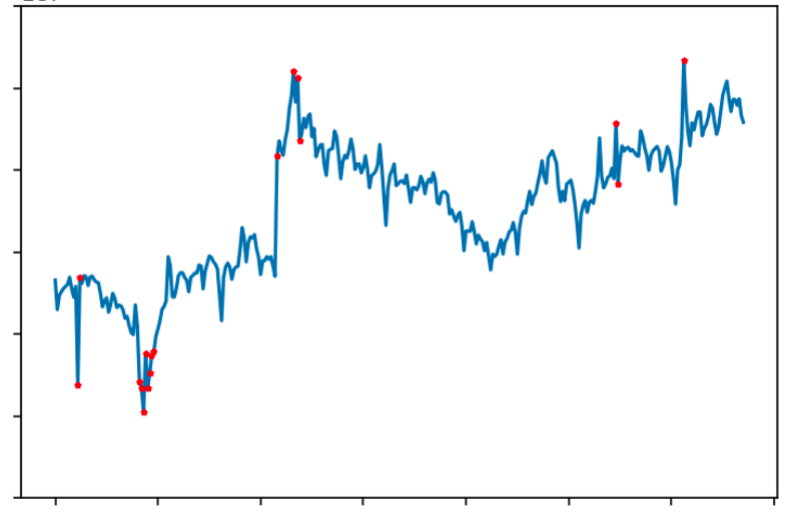
经验总结
局部异常因子算法(LOF)通过比较每个局部数据点的密度与其邻近区域数据的密度来判定异常点。局部数据点的密度越小于邻域数据密度,那么该点被判定为异常点的几率就越高。
在整体数据没有规律且比较发散的情况下,利用LOF局部密度的特性进行异常值检测的效果更好,能够满足指标检测标准。
3. 阶梯指标异常检测
外部流量的接入数据是十分典型的阶梯类指标。以个推外部流量数据为例,我们在指标检测中,应该将接入或接出后产生的波动点都作为异常值汇报。
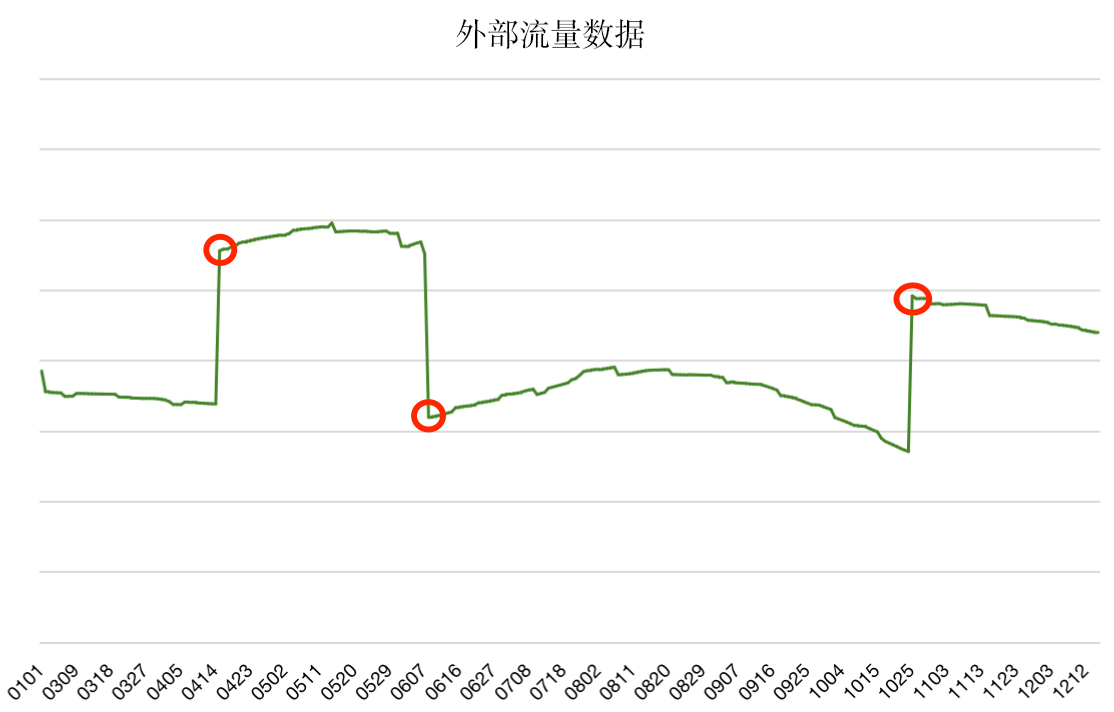
如上图,阶梯类数据异常是在瞬间发生的(数据曲线上升坡度接近90度),异常点的数值波动非常大,并且存在反复性。此外,异常值可能在正常的数值区间内,流量数据也并不符合正态分布。根据阶梯异常的特性及实践经验,我们使用二维特征的孤立森林模型来识别该类异常。
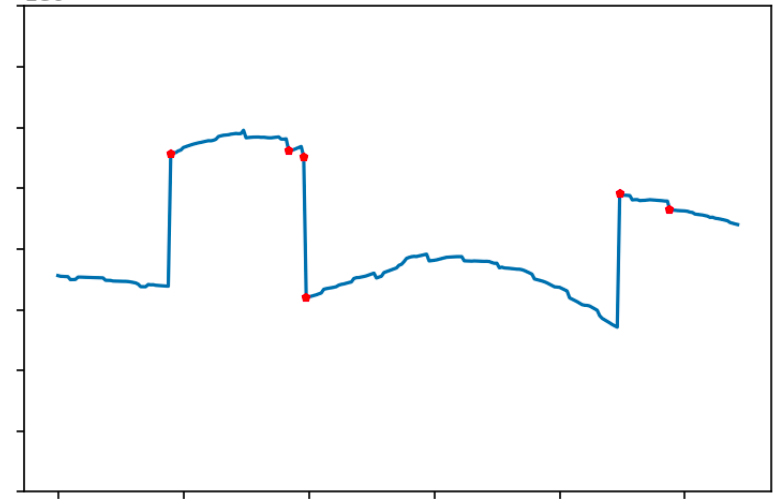
上图展示了识别效果。可以看到孤立森林模型准确识别到了流量接入和接出时的变化点,并且还识别到了两个隐蔽的变化点,将曲线放大后可以发现这两个隐蔽点的波动相对于其他点是比较大的,属于正确识别。
经验总结
阶梯异常值较为隐藏,但是波动性大。我们可以将波动值融入到特征中,采用孤立森林模型进行识别。
4. 周期指标异常检测
以办公类App的日活数据为例,该数据在大多数时间内都呈现出震荡的周期性,但在十一假期和春节假期分别产生了一个低谷,假期结束后又重回周期性,这种假期效应带来的数据变化就是我们要找的异常值。在春节的假期效应结束后,办公类App日活数据增加,这个提升点也应该被识别出来。
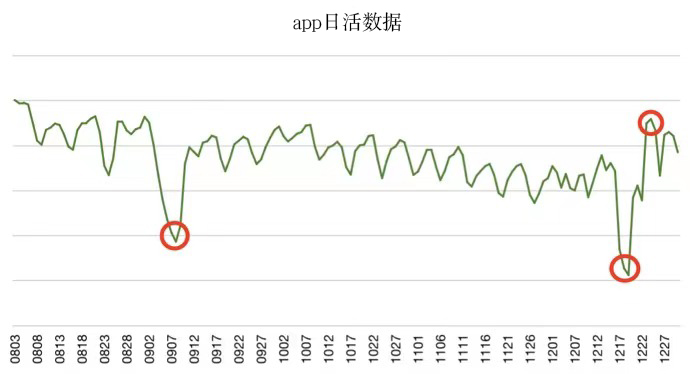
考虑到周期性,我们在识别该类异常值时增加了局部异常因子算法(LOF)。
为验证模型效果,在保证二维特征一致的前提下,我们分别通过LOF算法和孤立森林模型进行异常指标的识别,并进行了效果对比,如下图:
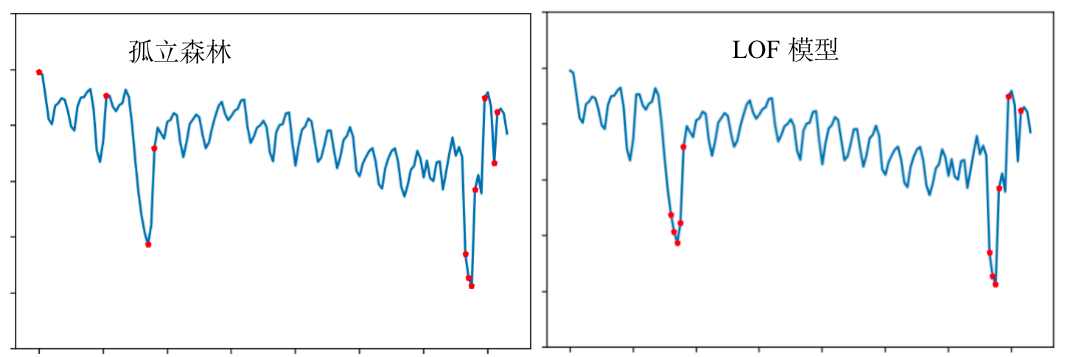
上图可以看出,二者的表现有一定差别。这两个算法都识别到了第二个周期异常点,但在第一个周期异常点的识别上,LOF利用其局部密度识别的特性,感知地更早,在不符合周期变化的初期就有所察觉;而孤立森林在第一个周期异常到达了极值点才有所感知。
在实际应用中,更早感知到数据变化,就可以更及时地采取措施以减少对业务的影响。另外,孤立森林模型明显存在误判点。所以,相比之下,LOF算法的检测效果更好。
经验总结
对周期指标异常的检测更强调及时性。从效果来看,二维特征的LOF模型通过对比每一个局部数据点的密度,能够更加准确、迅速地感知到异常。
总的来讲,我们可以看到,智能识别模型不仅识别到了单点指标异常、周期指标异常、阶梯指标异常、连续指标异常等四类重点关注的数据指标异常,还识别到了一些隐蔽的异常点。简单的人工目测可能会觉得这些异常指标是误判导致,但是当我们把曲线放大后就会发现,这些是除了底层数据操作影响以外波动最大的数据点。
其实在模型构建时可以选择舍去这类异常点。我们之所以保留汇报这类数据,是因为希望从这类波动偏大的数据点中总结规律,找到在未对数据做处理的情况下却产生较大数值波动的原因,进而优化数据质量,提高数据的稳定性。
指标检测系统架构
指标异常检测只是一个中间过程,将异常数据造成的影响降到最低,提高数据质量才是最终目的。为此,我们对指标检测系统架构做了如下规划:
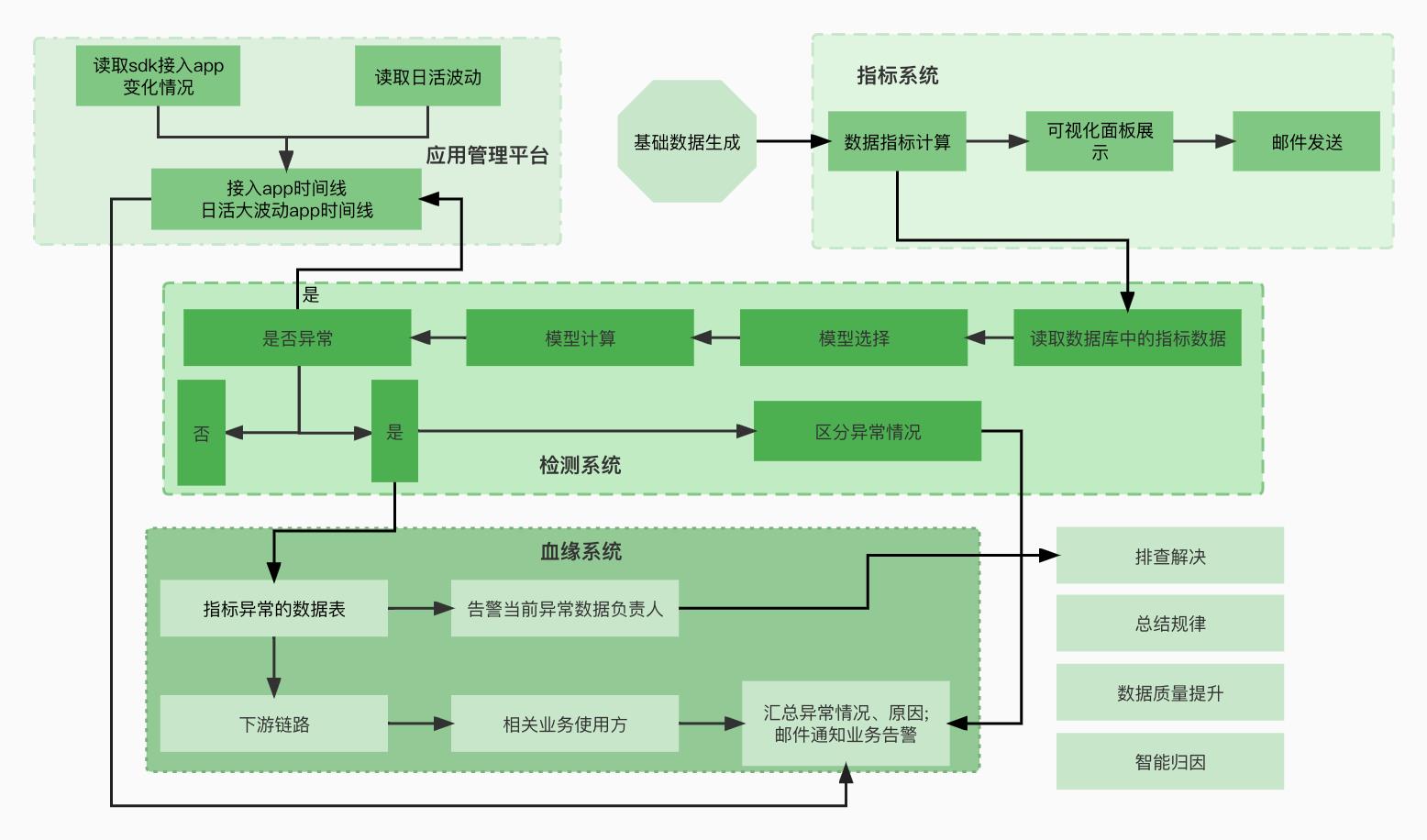
-
将应用管理平台直接与异常数据关联,匹配出异常时间线内的相关变更操作,此操作大概率为数据异常变化的直接原因,并通过邮件告知给负责人员。
-
对于非底层配置变更导致的异常,我们要结合业务和现实情况总结内在规律,比如办公类App的日活数据受假期效应影响,并分析相关特征,建立归因模型,最终实现智能化归因。
-
和数据血缘系统结合,通过数据血缘系统找到对应的数据负责人和使用数据的业务线,第一时间让业务人员知道底层数据的变动,使负面影响最小化。
-
分析不同类别指标数据的特征,构建指标数据分类模型,识别指标场景。自动化进行异常分类,并根据异常分类结果匹配对应模型,进行智能识别,减少人工调试。
以上是关于个推数据智能技术实践 | 教你打造数据质量心电图,智能检测数据“心跳”异常的主要内容,如果未能解决你的问题,请参考以下文章