Spark ALS recommendForAll源码解析实战之Spark1.x vs Spark2.x
Posted fansy1990
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark ALS recommendForAll源码解析实战之Spark1.x vs Spark2.x相关的知识,希望对你有一定的参考价值。
文章目录
Spark ALS recommendForAll源码解析实战
1. 软件版本:
| 软件 | 版本 |
|---|---|
| Spark | 1.6.3 、 2.2.2 |
| Hadoop | 2.6.5 |
2. 本文要解决的问题
- 分析Spark2.2.2中 ALS算法的recommendForAll函数的实现思路;
- 分析Spark1.6.3中 ALS算法的recommendForAll函数的实现思路;
- Spark2.2.2 和 Spark 1.6.3 关于 ALS的recommendForAll的实现的性能对比(参考Spark2.2.2. VS Spark1.6.3 之ALS 推荐性能对比);
3. 源码分析实战
源码分析实战采用源码分析+实例演示的方式来阐明源码的实现思路,下面分别给出Spark2.2.2以及Spark1.6.3的源码中关于ALS算法的recommendForAll的实战分析。
3.1 Spark2.2.2 ALS recommendForAll 实战分析
1. 首先给出其核心实现源码:
private def recommendForAll(
rank: Int,
srcFeatures: RDD[(Int, Array[Double])],
dstFeatures: RDD[(Int, Array[Double])],
num: Int): RDD[(Int, Array[(Int, Double)])] =
val srcBlocks = blockify(srcFeatures)
val dstBlocks = blockify(dstFeatures)
val ratings = srcBlocks.cartesian(dstBlocks).flatMap case (srcIter, dstIter) =>
val m = srcIter.size
val n = math.min(dstIter.size, num)
val output = new Array[(Int, (Int, Double))](m * n)
var i = 0
val pq = new BoundedPriorityQueue[(Int, Double)](n)(Ordering.by(_._2))
srcIter.foreach case (srcId, srcFactor) =>
dstIter.foreach case (dstId, dstFactor) =>
// We use F2jBLAS which is faster than a call to native BLAS for vector dot product
val score = BLAS.f2jBLAS.ddot(rank, srcFactor, 1, dstFactor, 1)
pq += dstId -> score
pq.foreach case (dstId, score) =>
output(i) = (srcId, (dstId, score))
i += 1
pq.clear()
output.toSeq
ratings.topByKey(num)(Ordering.by(_._2))
private def blockify(
features: RDD[(Int, Array[Double])],
blockSize: Int = 4096): RDD[Seq[(Int, Array[Double])]] =
features.mapPartitions iter =>
iter.grouped(blockSize)
核心源码包含两个部分:
- 一个是blockify子函数;
- 一个是recommendForAll的核心实现;
ALS模型中包含的userFeatures和productFeatures作为此函数的核心输入,分别代表用户向量和物品向量(关于其解释,可以参考ALS算法原理)。
2. blockify函数
blockify函数就是把原RDD进行分块处理,怎么理解分块呢?
假设有如下RDD,uf:
scala> val uf= sc.parallelize(List((1,Array(0.3,0.4,0.6,0.3,0.7)),(2,Array(0.13,0.14,0.16,0.13,0.17)),(3,Array(0.23,0.24,0.26,0.23,0.27)),(4,Array(0.83,0.84,0.86,0.83,0.87)),(5,Array(0.31,0.41,0.61,0.31,0.71)),(6,Array(0.213,0.214,0.216,0.213,0.217)),(7,Array(0.323,0.324,0.326,0.323,0.327)),(8,Array(0.283,0.284,0.286,0.283,0.287)),(9,Array(0.31,0.42,0.63,0.34,0.75)),(10,Array(0.131,0.141,0.161,0.131,0.171)),(11,Array(0.223,0.224,0.226,0.223,0.227)),(12,Array(0.813,0.814,0.816,0.813,0.817)) ))
uf: org.apache.spark.rdd.RDD[(Int, Array[Double])] = ParallelCollectionRDD[11] at parallelize at <console>:27
那么,使用块大小为5,来对uf进行blockify处理,如下:
scala> val blockSize = 5
blockSize: Int = 5
scala> val ufsrc = uf.mapPartitions iter =>iter.grouped(blockSize)
ufsrc: org.apache.spark.rdd.RDD[Seq[(Int, Array[Double])]] = MapPartitionsRDD[15] at mapPartitions at <console>:31
而blockify的核心就是针对RDD中的每个分区的数据执行grouped操作,grouped操作就是针对一个列表进行分组,如下:
scala> (0 to 10).grouped(5).toList
res3: List[scala.collection.immutable.IndexedSeq[Int]] = List(Vector(0, 1, 2, 3, 4), Vector(5, 6, 7, 8, 9), Vector(10))
scala> (0 to 10).grouped(6).toList
res4: List[scala.collection.immutable.IndexedSeq[Int]] = List(Vector(0, 1, 2, 3, 4, 5), Vector(6, 7, 8, 9, 10))
所以ufsrcRDD就会在每个分区中构建多条记录,而每个记录就是一个Seq数组,上面的uf数据应用blockify,其数据流如下:
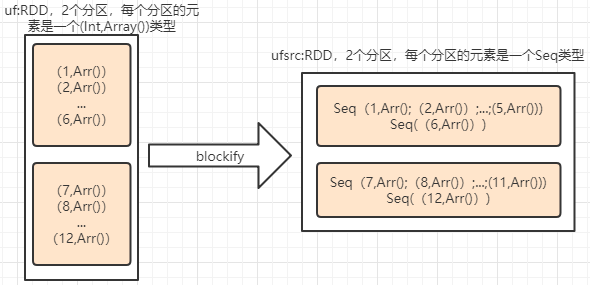
下面对此图进行验证:
1)原始uf RDD数据有2个分区,并且其数据分别为1~6 、 7~12;
scala> uf.glom().collect.foreach(x => println(x.mkString("|")))
(1,[D@673b5922)|(2,[D@5bda90af)|(3,[D@3962064d)|(4,[D@53d95e8a)|(5,[D@6e96ff9a)|(6,[D@61c6450f)
(7,[D@48bf7714)|(8,[D@518b5d87)|(9,[D@8381203)|(10,[D@5b85d036)|(11,[D@68311b85)|(12,[D@635d1461)
2)blockify后的RDD其分区数据每个元素为一个Seq数组,如下:
scala> ufsrc.glom().collect.foreach(x => println(x.mkString("|")))
List((1,[D@299c20bd), (2,[D@256d5200), (3,[D@6e81084f), (4,[D@11a6e7d4), (5,[D@59f7a495))|List((6,[D@164500f9))
List((7,[D@7060b10e), (8,[D@565e7091), (9,[D@3269a5c3), (10,[D@c1539bf), (11,[D@790801f2))|List((12,[D@5c772cba))
下面构造的pf 如下:
scala> val pf = sc.parallelize(List((101,Array(0.33,0.34,0.36,0.33,0.37)),(201,Array(0.43,0.44,0.46,0.43,0.47)),(301,Array(0.53,0.54,0.56,0.53,0.57)),(401,Array(0.303,0.304,0.306,0.303,0.307)),(501,Array(0.403,0.404,0.406,0.403,0.407)),(601,Array(0.153,0.154,0.156,0.153,0.157)),(701,Array(0.523,0.524,0.526,0.523,0.527)),(801,Array(0.553,0.554,0.556,0.553,0.557)) ) )
pf: org.apache.spark.rdd.RDD[(Int, Array[Double])] = ParallelCollectionRDD[12] at parallelize at <console>:27
scala> val pfdst = pf.mapPartitions iter =>iter.grouped(blockSize)
pfdst: org.apache.spark.rdd.RDD[Seq[(Int, Array[Double])]] = MapPartitionsRDD[14] at mapPartitions at <console>:31
思考: 其pfdst RDD的数据流情况。
3. cartesian flatMap的优势
代码接下来就是执行 cartesian flatMap,此处关于cartesian flatMap的实现其实有两种方式:
-
原始数据直接cartesian;
其代码如下:
uf.cartesian(pf) -
原始数据先blockify,然后cartesian;
下面,先看下这两种方式的异同:
- cartesian的操作就是把两个RDD的元素做一个全连接配对,举个简单例子:
scala> val a = sc.parallelize(List(1,2,3,4))
a: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[23] at parallelize at <console>:27
scala> val b = sc.parallelize(List(11,22,33))
b: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[24] at parallelize at <console>:27
scala> val c = a.cartesian(b)
c: org.apache.spark.rdd.RDD[(Int, Int)] = CartesianRDD[25] at cartesian at <console>:31
scala> c.collect.foreach(println(_))
(1,11)
(2,11)
(1,22)
(1,33)
(2,22)
(2,33)
(3,11)
(4,11)
(3,22)
(3,33)
(4,22)
(4,33)
scala> c.count
res19: Long = 12
scala> a.partitions.size
res20: Int = 2
scala> b.partitions.size
res21: Int = 2
scala> c.partitions.size
res22: Int = 4
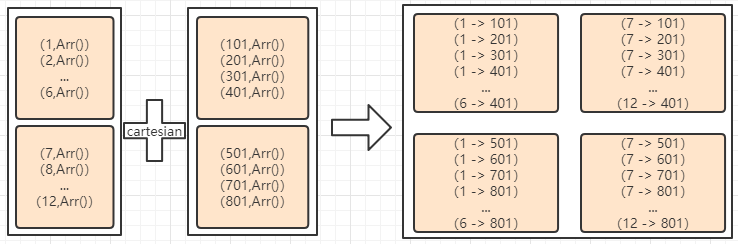
- 两种方式的cartesian的数据流对比
-
- 直接cartesian:
-
- 先blockify,然后cartesian:
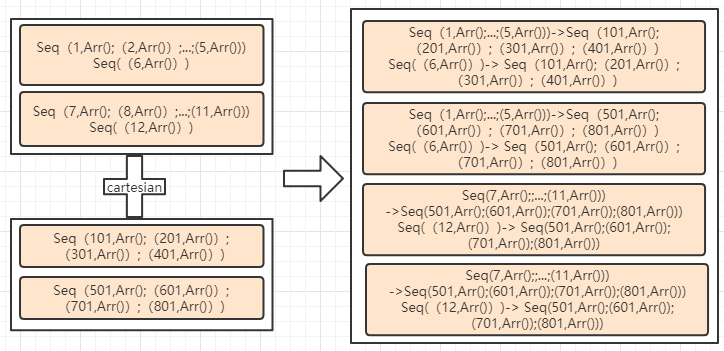
图 blockify-cartesian数据流
通过数据流其实也可以看出,直接cartesian的数据会多些(就单看产生的数据量)。
比如在i.中 用户1的数据(1,Arr())存储要8个;而在ii.中用户1的数据(1,Array())却只会出现2次。
对比其产生的数据大小,代码如下:
scala> uf.cartesian(pf).saveAsTextFile("/tmp/cartesian01")
scala> ufsrc.cartesian(pfdst).saveAsTextFile("/tmp/cartesian02")
执行后,查看其数据存储大小,分别如下图所示。
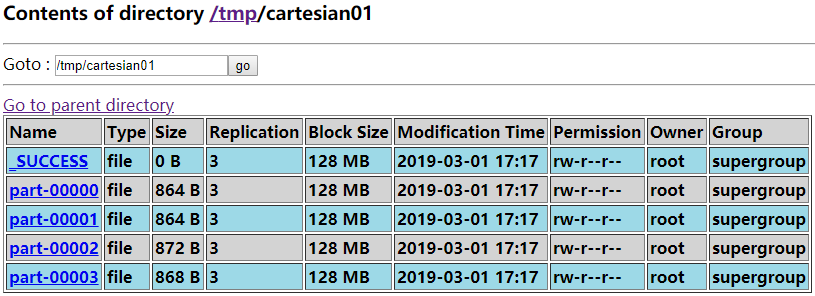

从两个图的对比也可以发现,第二种方式其数据存储会小很多。这也是为什么源码用的是第二种实现方式。
这里的BlockSize 其实对性能也有很大影响,所以源码中也会建议是否把此参数暴露出来,供用户自己设置。
4. flatMap的处理逻辑
flatMap的处理逻辑比较复杂,下面分点描述:
- case (srcIter, dstIter)代表什么数据
参考 图 blockify-cartesian数据流 中的输出数据,(srcIter,dstIter)代表的数据其实就是组对应的数据,例如:
| srcIter | dstIter |
|---|---|
| Seq( (1,Arr();…;(5,Arr())) | Seq( (101,Arr();(201,Arr());(301,Arr());(401,Arr()) ) |
| Seq( (6,Arr()) ) | Seq( (101,Arr();(201,Arr());(301,Arr());(401,Arr()) ) |
| … | … |
| Seq((12,Arr())) | Seq(501,Arr();(601,Arr());(701,Arr());(801,Arr())) |
- 规划输出数组大小
val m = srcIter.size
val n = math.min(dstIter.size, num)
val output = new Array[(Int, (Int, Double))](m * n)
output的大小为什么是srcIter.size * math.min(dstIter.size, recNum)?
1) output只代表当前块(block)的用户的推荐内容,所以行个数就应该是当前用户的个数,而srcIter就是用户的一个数组,所以其大小就是行个数;
2) 推荐的个数,当然和用户设置的推荐个数有关,但是其算的当前的项目的块大小如果小于设置的推荐个数,那么最多也只能推荐当前块中项目的个数,所以是math.min ;
- 每个用户块(block)和每个项目块(block)乘积并优先队列
var i = 0
val pq = new BoundedPriorityQueue[(Int, Double)](n)(Ordering.by(_._2))
srcIter.foreach case (srcId, srcFactor) =>
dstIter.foreach case (dstId, dstFactor) =>
// We use F2jBLAS which is faster than a call to native BLAS for vector dot product
val score = BLAS.f2jBLAS.ddot(rank, srcFactor, 1, dstFactor, 1)
pq += dstId -> score
pq.foreach case (dstId, score) =>
output(i) = (srcId, (dstId, score))
i += 1
pq.clear()
优先队列指的是一个用户块(比如有5个用户),那么和一个项目块(比如有4个项目),比如现在只推荐3个项目。那么,针对用户块中的每个用户,会和所有的项目进行计算,得到4个项目对应的分数,这些(项目,分数)对就会存入一个优先队列,而这个优先队列在4个(项目,分数)对存入完成后,只会有3个,并且其分数是最大的三个;
- 每个用户都会有多个优先队列
val ratings = srcBlocks.cartesian(dstBlocks).flatMap
...
output.toSeq
首先,每个用户块会对应多个项目块,而每个项目块会对应一个优先队列;接着,这些优先队列会通过flatMap进行合并,得到所有的(用户id,(项目id,分数))这样的数据,也就是RDD,也即是说ratings:RDD[(Int,(Int,Double))]。
思考一下,如果上面的例子中,blockify设置的个数为2,那么srcIter : Seq ((1,Array()), (2,Array()) ) 会对应多少个项目块,对应多少个优先队列?
- 合并取top
ratings.topByKey(num)(Ordering.by(_._2))
而这句就是针对ratings数据的每个key分组,然后按照value的第二个值(其实就是分数)排序,取其前n个键值对。
第4,5 步可以通过下图展示:
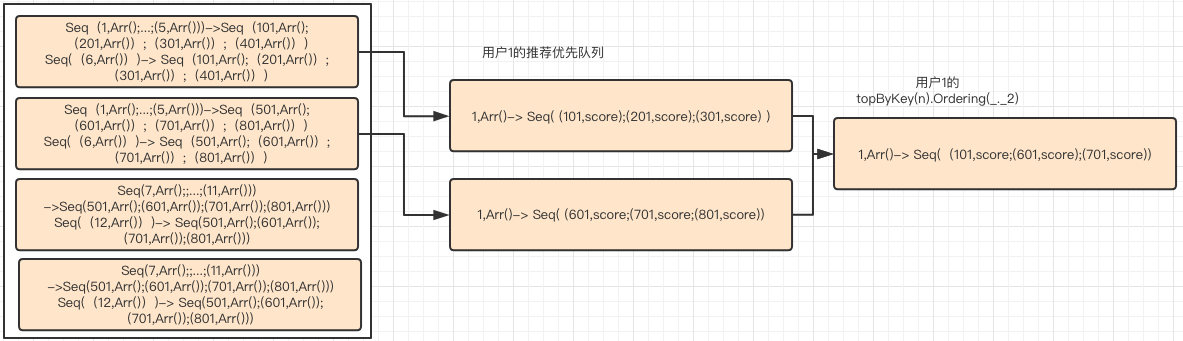
至此,分析完毕!
3.2 Spark1.6.3 ALS recommendForAll 实战分析
1. blockify函数
Spark1.6.3的blockify函数和Spark2.2.2中实现的blockify函数是不一样的,如下:
/**
* Blockifies features to use Level-3 BLAS.
*/
private def blockify(
rank: Int,
features: RDD[(Int, Array[Double])]): RDD[(Array[Int], DenseMatrix)] =
val blockSize = 4096 // TODO: tune the block size
val blockStorage = rank * blockSize
features.mapPartitions iter =>
iter.grouped(blockSize).map grouped =>
val ids = mutable.ArrayBuilder.make[Int]
ids.sizeHint(blockSize)
val factors = mutable.ArrayBuilder.make[Double]
factors.sizeHint(blockStorage)
var i = 0
grouped.foreach case (id, factor) =>
ids += id
factors ++= factor
i += 1
(ids.result(), new DenseMatrix(rank, i, factors.result()))
在此份代码中,可以分为如下的几个部分:
- ArrayBuilder使用
val ids = mutable.ArrayBuilder.make[Int]
ids.sizeHint(blockSize)
val factors = mutable.ArrayBuilder.make[Double]
factors.sizeHint(blockStorage)
ids.result()
factors.result()
这个ArrayBuilder就是一个存储数据的数组,通过sizeHint函数来预设该数组大小,而通过result函数获取整个数组的值,如下:
scala> import scala.collection.mutable
import scala.collection.mutable
scala> val factors = mutable.ArrayBuilder.make[Double]
factors: scala.collection.mutable.ArrayBuilder[Double] = ArrayBuilder.ofDouble
scala> factors ++= Array(0.2,0.3)
res34: factors.type = ArrayBuilder.ofDouble
scala> factors.result()
res35: Array[Double] = Array(0.2, 0.3)
scala> factors ++= Array(0.2,0.3)
res36: factors.type = ArrayBuilder.ofDouble
scala> factors.result()
res37: Array[Double] = Array(0.2, 0.3, 0.2, 0.3)
- DenseMatrix使用
DenseMatrix的使用直接使用其源代码来解释,如下:
/**
* Column-major dense matrix.
* The entry values are stored in a single array of doubles with columns listed in sequence.
* For example, the following matrix
*
* 1.0 2.0
* 3.0 4.0
* 5.0 6.0
*
* is stored as `[1.0, 3.0, 5.0, 2.0, 4.0, 6.0]`.
*
* @param numRows number of rows
* @param numCols number of columns
* @param values matrix entries in column major
*/
@Since("1.0.0")
def this(numRows: Int, numCols: Int, values: Array[Double]) =
this(numRows, numCols, values, false)
这一段说的就是针对矩阵,使用一个数组来存储,同时指定其行列的个数,然后就可以针对行列的个数来对数组进行划分,进而就可以得到矩阵。
思考:factors的size为什么是 rank * blockSize,以及是否所有的factors的size都是这个?
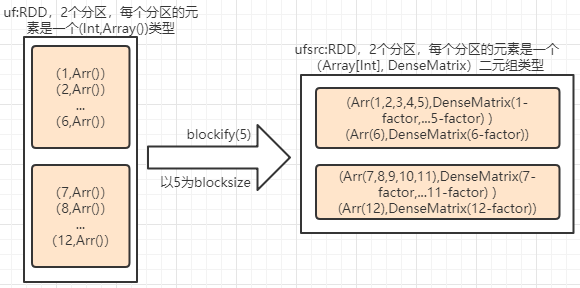
- 每个partition分组、组整合成(用户array,项目矩阵)
此处和Spark2.2.2不同的地方就是针对每个partition进行分组后的操作,此处针对每个分组的数据会把每个组整合成(用户Array,项目矩阵)的二元组数据。其流程图如下所示:
2. recommendForAll函数分析
这里只分析与Spark2.2.2不同的地方:
case ((srcIds, srcFactors), (dstIds, dstFactors)) =>
val m = srcIds.length
val n = dstIds.length
val ratings = srcFactors.transpose.multiply(dstFactors)
val output = new Array[(Int, (Int, Double))](m * n)
var k = 0
ratings.foreachActive (i, j, r) =>
output(k) = (srcIds(i), (dstIds(j), r))
k += 1
output.toSeq
- 首先,output是一个 当前组中用户数x当前组中项目数 个 (用户ID,(项目ID,分数))的三元组数组。
- ratings同样是一个DenseMatrix,其如下
srcFactor: k * m 的矩阵
dstFactor: k * n的矩阵
srcFactor' * dstFaxtor : (m * k) * (k * n) = m * n 的一个矩阵
这里是一个矩阵运算(不清楚的同学可以补充下线性代数的知识)。
- 最后两句代码,就是针对ratings中的每个值,把这个值和其对应的用户ID,项目ID的关系拼凑起来,并赋值给output。
从临时数据来看,这个数据是一个(m * n)的一个数据,远远比Spark2.2.2中 m*k (k << n)的数据量小。这也是Spark1.6.3中GC时间过长的原因,可以在后面的分析看到!
3.3 Spark2.2.2和Spark1.6.3 代码对比总结
| Point | Spark1.6.3 | Spark2.2.2 |
|---|---|---|
| 计算量 | 要计算每个用户ID的factor和每个项目ID的factor的乘积 | 一样 |
| 计算效率 | 使用矩阵相乘,如果不用Native BLAS,那么速度很低 | 使用向量相乘,效率高于 Native BLAS |
| 临时存储数据量 | 临时存储很大(m * n) | 临时存储较小(m*k) |
4. Spark2.2.2和Spark1.6.3性能测试对比
Note:
关于Spark2.2.2的性能测试,如使用Native BLAS等,可参考 Spark ALS应用BLAS加速
测试代码、数据等,同样参考Spark ALS应用BLAS加速
4.1 Spark1.6.3 官网安装包测试
- 注意使用Spark官网提供的安装包进行集群安装测试,官网下载地址:spark-1.6.tgz。
- 同样使用 fansy1990/als_blas 代码,进行编译打包(注意使用对应版本的pom文件)
命令如下:
spark-submit --class demo.AlsTest --deploy-mode cluster /root/als_blas-1.0-for-spark1.6.3.jar 3000
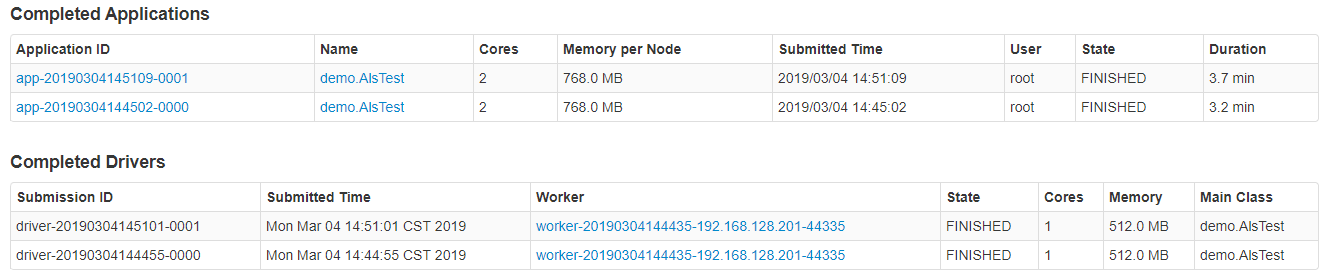
- 执行两次后,时间消耗:
时间消耗如下:
- 是否有BLAS的使用?
查看子节点是否,看是否有BLAS的使用:
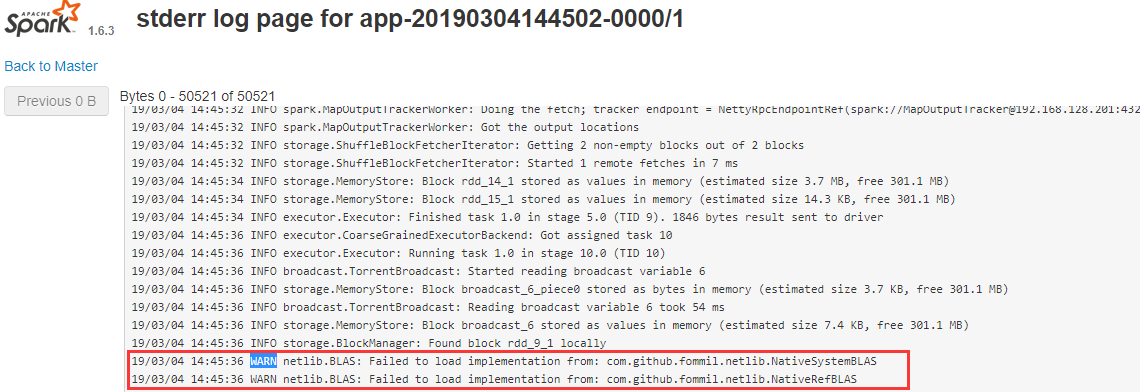
从图中可以看出,是没有使用BLAS的加速的!
- long GC
任务有很长的GC时间,如下(在上面已经有说明,这里只是验证):
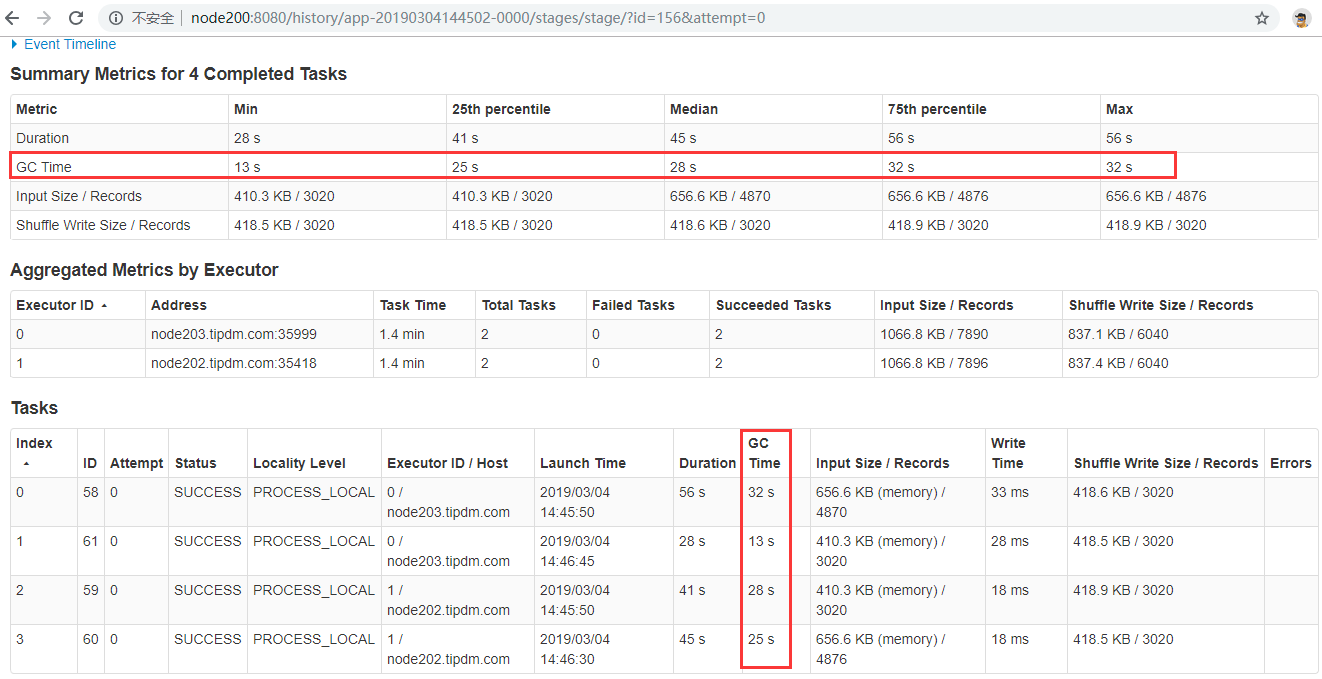
4.2 Spark1.6.3 自编译安装包测试
使用自行编译好的Spark 安装包,再次测试一遍
编译命令如下:

- 测试时间:
本次测试分为四次,前两次所有节点都没有安装open BLAS,后面两次是所有节点都安装的情况,如下:
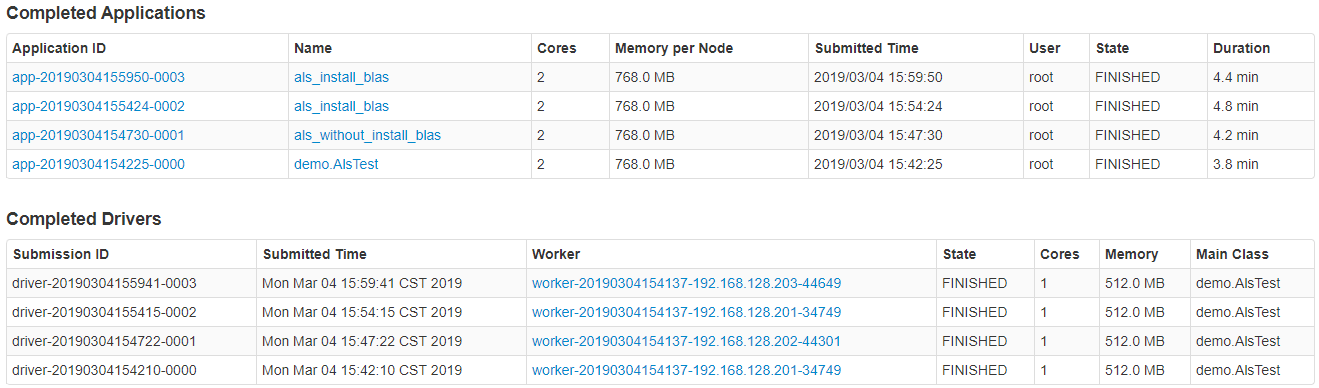
- 是否使用BLAS?
从子节点的运行日志可以看出,确实是有使用BLAS的,如下:

- 是否 Long GC?
不管是open BLAS安装前,还是后,都有Long GC,如下:
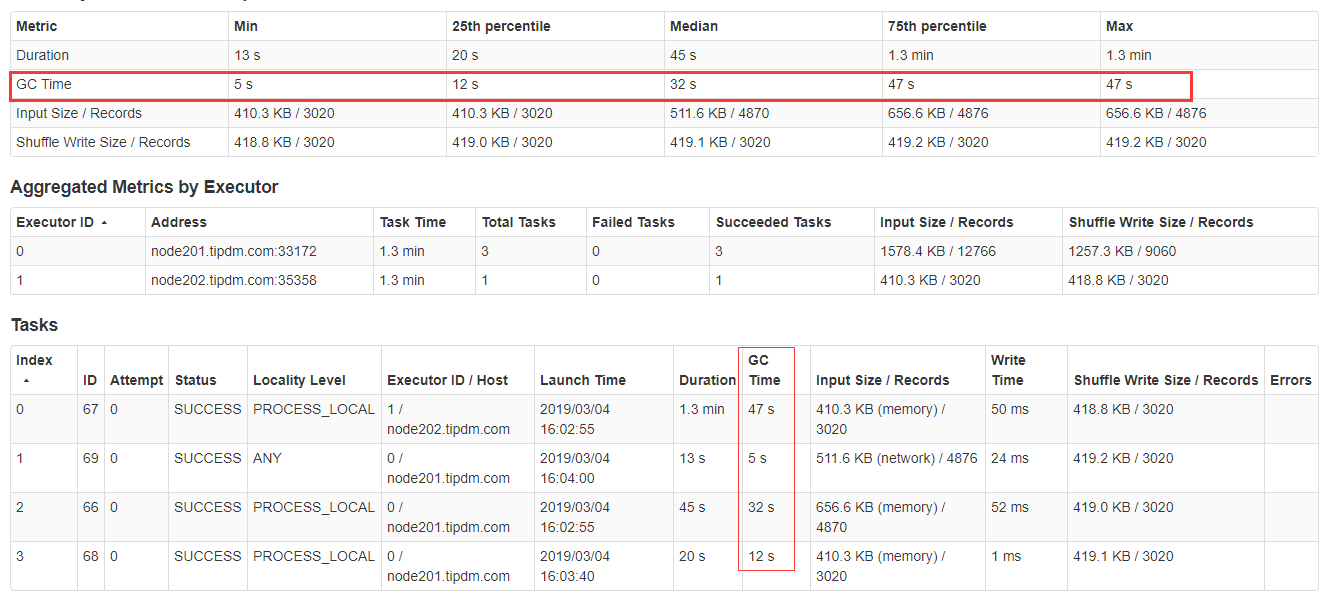
4.3 Spark2.2.2 vs Spark1.6.3 性能对比总结
部分参数来自Spark ALS应用BLAS加速
| 版本 | 平均耗时(mins) | Long GC |
|---|---|---|
| 官网Spark2 | 1.1 | 否 |
| 自编译Spark2(BLAS) | 1.2 | 否 |
| 官网Spark1 | 3.5 | 是 |
| 自编译SPark1(BLAS) | 4.3 | 是 |
Spark 2: Spark 2.2.2; Spark1:Spark 1.6.3
从表的分析结果来看:
- 如果使用Spark中ALS算法,那么尽量使用Spark2版本;
- 从当前的测试实验数据来看,针对Spark1.x版本,就算有Native BLAS,但是ALS算法也并没有加速的迹象,反而更慢了。
5. 思考解答
- pfdst RDD的分布情况:
由于pf RDD也有两个分区,每个分区4条记录,所以blockify后,pfdst RDD也有两个分区,并且每个分区只有一条记录,这个记录是一个Seq数组,同时,这个数组中有4个元素。
scala> pfdst.glom().collect.foreach(x => println(x.mkString("|")))
List((101,[D@4cd85d52), (201,[D@5669ee53), (301,[D@7cdbc04), (401,[D@4dd08e5b))
List((501,[D@43ec687e), (601,[D@5a6e1d26), (701,[D@30a9a7f3), (801,[D@794245eb))
scala> pf.glom().collect.foreach(x => println(x.mkString("|")))
(101,[D@3400f5aa)|(201,[D@1bf0208c)|(301,[D@5daf0cb0)|(401,[D@70e1a8ab)
(501,[D@43ffaeb8)|(601,[D@5991020b)|(701,[D@7c7e4f05)|(801,[D@1a714d1)
-
blockify设置的个数为2,对应多少优先队列?
-
factors的size为什么是 rank * blockSize,以及是否所有的factors的size都是这个?
以上是关于Spark ALS recommendForAll源码解析实战之Spark1.x vs Spark2.x的主要内容,如果未能解决你的问题,请参考以下文章