Hive Distinct 的实现原理
Posted <一蓑烟雨任平生>
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive Distinct 的实现原理相关的知识,希望对你有一定的参考价值。
Hive Distinct 的实现原理
select dealid, count(distinct uid) num from order group by dealid;
当只有一个distinct字段时,如果不考虑Map阶段的Hash GroupBy,只需要将GroupBy字段和Distinct字段组合为map输出key,利用mapreduce的排序,同时将GroupBy字段作 为reduce的key,在reduce阶段保存LastKey即可完成去重。
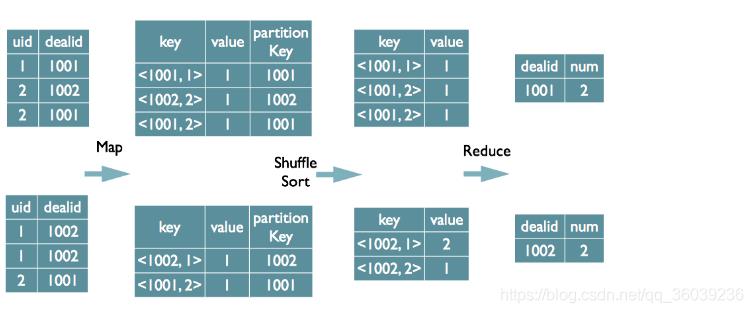
如果有多个distinct字段呢,如下面的SQL:
select dealid, count(distinct uid), count(distinct date) from order group by dealid;
实现方式有两种:
(1)如果仍然按照上面一个distinct字段的方法,即下图这种实现方式,无法跟据uid和date分别排序,也就无法通过LastKey去重,仍然需要在reduce阶段在内存中通过Hash去重

(2)第二种实现方式,可以对所有的distinct字段编号,每行数据生成n行数据,那么相同字段就会分别排序,这时只需要在reduce阶段记录LastKey即可去重。这种实现方式很好的利用了MapReduce的排序,节省了reduce阶段去重的内存消耗,但是缺点是增加了shuffle的数据量。需要注意的是,在生成reduce value时,除第一个distinct字段所在行需要保留value值,其余distinct数据行value字段均可为空。

以上内容仅供参考学习,如有侵权请联系我删除!
如果这篇文章对您有帮助,左下角的大拇指就是对博主最大的鼓励。
您的鼓励就是博主最大的动力!
以上是关于Hive Distinct 的实现原理的主要内容,如果未能解决你的问题,请参考以下文章