Flink Runtime 1.0 Notes: Task Execution
Posted 张包峰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink Runtime 1.0 Notes: Task Execution相关的知识,希望对你有一定的参考价值。
About
I will try to give the mainline of how does Flink task works.
Main classes and methods are mentioned.
Format explaination
this is
Classthis is method()
this is constant
Task Execution
Task Components
Through DataSourceTask, we see some basic components inside a Task
Taskis an invokable.gets the use of
InputSplitProviderinRuntimeEnvironmentto read dataCollector, a list ofChainedDriver, a list ofRecordWriter. They do the computation and forward the result records to the next task(I do not claim that it is a push-style or just write somewhere to wait for fetching).BatckTaskinits them together.ChainedDriveris also aCollector, and contains theFunction.It closes when no more input splits got, first
OutputCollector.close(), thenRecordWriter.flush(), all things(buffers, resources and so on) cleared. ForDataSourceTask, its invocation is done.
Task Coordination
Go back to Task, after the invokable finishes invoke(), ResultPartition.finish() invoked. We will see how tasks coordinate with each other under Flink Runtime.
ResultPartition is a result partition for data produced by a single task.
Before a consuming task can request the result, it has to be deployed. The time of deployment depends on the PIPELINED vs. BLOCKING characteristic of the result partition(see
ResultPartitionType). With PIPELINED results, receivers are deployed as soon as the first buffer is added to the result partition. With BLOCKING results on the other hand, receivers are deployed after the partition is finished.
Inside ResultPartition. finish(), if it finishes successfully, it will then notifyPipelinedConsumers(), else, for BLOCKING results, this will trigger the deployment of consuming tasks.
ResultPartitionConsumableNotifier does the notification by sending a ScheduleOrUpdateConsumers msg to JobManager. On the master side, ExecutionGraph.scheduleOrUpdateConsumers() gets the Execution by theResultPartitionID from msg, then continues to invoke ExecutionVertex.scheduleOrUpdateConsumers(), where all consumers are finally scheduled or updated by Execution.
The consumer may be not deployed before due to some deployment race, so that it will now do the scheduleForExecution(). Else if the consumer is RUNNING, a ResultPartitionLocation will be created, both locally or remotely, it is a perspective of the consuming task on the location of a result partition, then a msg of UpdatePartitionInfo is sent to the consumer slot. Else if the consumer is in other status, the UpdatePartitionInfo will be sent to it anyway, just omit that.
Here goes the reader side action.
TaskManager handles the UpdatePartitionInfo msg, both single partition info or multi partitions info, happens in updateTaskInputPartitions(). The target task is found according to executionId, a SingleInputGate is found by the IntermediateDataSetID, which acts like a reader, consuming one or more partitions of a single produced intermediate result. SingleInputGate updates the input channel in updateInputChannel(), it maintains a map of IntermediateResultPartitionID to InputChannel.
Actually, InputGate is a common abstraction for down-stream consumers to read the up-stream produsers result, like in a map-reduce program. It is created during the construction of Task.
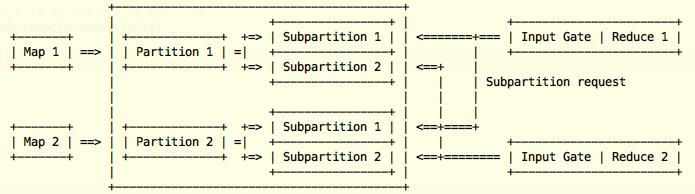
Now we need to know how reader is used in Task.
Through DataSinkTask, we see the read procedure more clearly. During initInputReaders(), a MutableRecordReader is created with a InputGate, as the input reader, then a ReaderIterator is created, having the input reader and the serde factory inside it, delegating the next() thing. MutableRecordReader.next() goes into AbstractRecordReader.getNextRecord(), InputGate.getNextBufferOrEvent() is called. If getting buffer, data will be deser and got by the DataSinkTask, else, event will be handled as follows:
EndOfPartitionEvent. This is generated byResultSubpartition.finish(), so we infer that subparitition will put an end-mark once it finishes add buffer.PipelinedSubpartitionandSpillableSubpartitionare twoResultSubpartitions, the former keeps data in-memory and can be consumed once, the latter is able to spill to disk. Basically, these two should map to PIPELINED vs. BLOCKING.EndOfSuperstepEvent. This is generated under iterative job.TaskEvent. This is also designed for iterative job to transfer control messages, dispatched byTaskEventHandlerto subscribers.
The Task
Little confused that Flink Runtime gives two kinds of task:
DataSourceTaskandDataSinkTaskBatchTask, including its iterative related subclasses:IterationHeadTask,IterationTailTask, andIterationIntermediateTask.
Inside Flink Streaming Java module, another important StreamTask is given. It is strange that Streaming module has its own extension of Runtime, whose model is pipelined, which in my opinion is ought to be included inside Flink Runtime.
Maybe it will be explained next time.
:)
以上是关于Flink Runtime 1.0 Notes: Task Execution的主要内容,如果未能解决你的问题,请参考以下文章