spark.mllib源码阅读-分类算法4-DecisionTree
Posted 大愚若智_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark.mllib源码阅读-分类算法4-DecisionTree相关的知识,希望对你有一定的参考价值。
本篇博文主要围绕Spark上的决策树来讲解,我将分为2部分来阐述这一块的知识。第一部分会介绍一些决策树的基本概念、Spark下决策树的表示与存储、结点分类信息的存储、结点的特征选择与分类;第二部分通过一个Spark自带的示例来看看Spark的决策树的训练算法。另外,将本篇与上一篇博文"spark.mllib源码阅读bagging方法"的bagging子样本集抽样方法结合,也就理解了Spark下的决策森林树的实现过程。
第一部分:
决策树模型
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点和有向边组成。结点有两种类型:内部节点和叶节点,内部节点表示一个特征或属性,叶节点表示一个类。分类的时候,从根节点开始,当前节点设为根节点,当前节点必定是一种特征,根据实例的该特征的取值,向下移动,直到到达叶节点,将实例分到叶节点对应的类中。

图 1 是一棵结构简单的决策树,用于预测贷款用户是否具有偿还贷款的能力。贷款用户主要具备三个属性:是否拥有房产,是否结婚,平均月收入。每一个内部节点都表示一个属性条件判断,叶子节点表示贷款用户是否具有偿还能力。例如:用户甲没有房产,没有结婚,月收入 5K。通过决策树的根节点判断,用户甲符合右边分支 (拥有房产为“否”);再判断是否结婚,用户甲符合左边分支 (是否结婚为否);然后判断月收入是否大于 4k,用户甲符合左边分支 (月收入大于 4K),该用户落在“可以偿还”的叶子节点上。所以预测用户甲具备偿还贷款能力。(示例摘自IBM博客)
决策树的存储与表示:
决策树是一类特殊的树,每个结点存储了结点的分裂信息(非叶子结点)或者分类信息(叶子结点),既然是树结构,那么就可以用我们熟悉的树数据结构来表示和存储了。

Spark在Node.scala文件中实现了决策树结点的存储与通过"遍历"结点来进行预测,其基本的形态是一颗二叉树,并实现了三类不同的结点:
LeafNode:叶子结点使用LeafNode存储,关键参数有prediction,impurity。
InternalNode:内部结点(包含叶子结点)InternalNode,关键参数有prediction,impurity,gain,leftChild,rightChild,split。
LearningNode:决策树训练时结点的表示类LearningNode,在训练完成后通过LearningNode.toNode方法,将其转变为InternalNode或者LeafNode。
说一下几个参数的意思:
prediction:预测类别或者回归值
impurity:不纯度,Spark实现了三种不纯度度量方式:熵、信息增益、残差(适用于回归)。
leftChild、rightChild:左右子节点
split:Node在进行预测时,需要用到split存储的结点信息,由split来决定选择左结点还是右结点。
结点分裂信息类Split:
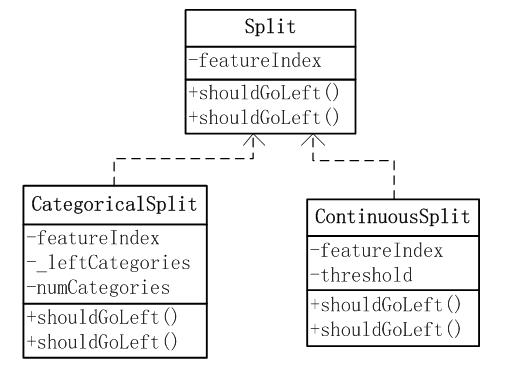
Spark实现了2个结点选取类CategoricalSplit和ContinuousSplit,分别完成分类特征和连续特征下的子结点选取问题。
CategoricalSplit:将分类特征的属性值集分成2个集合(左集合)和右集合,判断属性值属于哪个集合来决定选取哪个子节点。
ContinuousSplit:针对连续型特征的子节点选取类,输入的特征值与设定的阀值threshold比较大小,来决定是选取左子节点还是右子结点。
决策树特征选择与分裂:
选择一个合适的特征作为判断节点,可以快速的分类,减少决策树的深度。决策树的目标就是把数据集按对应的类标签进行分类。最理想的情况是,通过特征的选择能把不同类别的数据集贴上对应类标签。特征选择的目标使得分类后的数据集比较纯。
Spark实现了3类数据不纯度度量算法:Giniimpurity、Entropy、Variance,都继承自Impurity类并覆写了不纯度计算方法calculate。
Gini impurity:
采用基尼指数来度量数据的不纯度,计算公式如下:

计算代码如下:
override def calculate(counts: Array[Double], totalCount: Double): Double = if (totalCount == 0) return 0 val numClasses = counts.length //∑Ci=1fi(1−fi) = ∑Ci=1fi + ∑Ci=1fi*fi, 其中前半部分为1 实际只需要计算后半部分。 var impurity = 1.0 var classIndex = 0 while (classIndex < numClasses) val freq = counts(classIndex) / totalCount //fi impurity -= freq freq classIndex += 1 impurityEntropy impurity:
采用熵来度量数据的不纯度,计算公式如下:

计算代码如下:
override def calculate(counts: Array[Double], totalCount: Double): Double = if (totalCount == 0) return 0 val numClasses = counts.length //∑Ci=1−filog(fi) var impurity = 0.0 var classIndex = 0 while (classIndex < numClasses) val classCount = counts(classIndex) if (classCount != 0) val freq = classCount / totalCount impurity -= freq log2(freq) classIndex += 1 impurityVariance impurity:
使用残差度量数据不纯度,使用决策树回归问题,计算公式如下:

实现代码:
override def calculate(count: Double, sum: Double, sumSquares: Double): Double = if (count == 0) return 0 val squaredLoss = sumSquares - (sum * sum) / count squaredLoss / count
特征选取的方式是子结点的总数据不纯度小于当前结点的数据不纯度,并且其差值越大越好,即结点的分裂总是朝着数据纯度提高的方向进行:
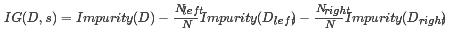
分裂候选集:
上面提到,Spark的决策树的基本形态是一颗二叉树,那么在每个非叶子结点上,都需要选择特征并将特征值一分为二,并根据样本的特征值的归属来决定样本分配至哪一个子节点。分裂候选集即是来完成特征值一分为二的过程,和切西瓜那样一刀切下去会有很多种不同的切分类似,分裂候选集也会产生很多种对特征值集不同的切分方法,之后在模型训练时选择一种最优的切法。
分裂候选集是将当前的输入特征的属性值集分成两大属性值集合或者两个区间,如例子中婚姻状态有已婚、未婚、不知,那么可以构造多个两两互斥的属性值集<<已婚>。<未婚、不知>>、<<已婚、不知>。<未婚>>等等。
对于分类型特征,如果特征值有M个可能取值,则可以构造 个分裂候选。如果特征有100个可能值,那么可能的分裂选项就非常的多,搜索起来也很昂贵。因此有必要减少可能的分裂候选数量,基本方法是将特征值按分裂后的纯度或者与目标类的相关性进行排序,以上为例,假设已婚、未婚、不知分别与目标因变量lable=1的相关性为0.6、0.4、0.2,那么可能的划分是<<已婚>。<未婚、不知>>、<<已婚、未婚>。<不知>>两种。因此M个可能取值的特征,其进行排序后可能存在的切分点为M-1个。
对于连续特征,需要先对所有的取值进行排序才能寻找可能的切分点。由于大数据下的值排序是比较昂贵的,因此采用了抽样的方式获得一个特征值子集来构造分裂候选集。
看看该部分的实现代码,分类候选集代码在org.apache.spark.ml.tree.impl.RandomForest中
protected[tree] def findSplits(
input: RDD[LabeledPoint],//输入数据
metadata: DecisionTreeMetadata,//元信息
seed: Long): Array[Array[Split]] =
logDebug("isMulticlass = " + metadata.isMulticlass)
val numFeatures = metadata.numFeatures//特征数量
val continuousFeatures = Range(0, numFeatures).filter(metadata.isContinuous)//得到连续特征的index
//对连续特征分裂构建所需的子样本集,参看该篇"分裂候选集"章节
val sampledInput = if (continuousFeatures.nonEmpty)
val requiredSamples = math.max(metadata.maxBins * metadata.maxBins, 10000)//估算抽样数量
val fraction = if (requiredSamples < metadata.numExamples) 计算抽样率
requiredSamples.toDouble / metadata.numExamples
else
1.0
logDebug("fraction of data used for calculating quantiles = " + fraction)
//进行无放回抽样 该抽样的实现方式可参考http://blog.csdn.net/zbc1090549839/article/details/69329584
input.sample(withReplacement = false, fraction, new XORShiftRandom(seed).nextInt())
else
input.sparkContext.emptyRDD[LabeledPoint]
findSplitsBySorting(sampledInput, metadata, continuousFeatures)//找到分裂点
private def findSplitsBySorting(
input: RDD[LabeledPoint], //无放回抽样后的子样本集
metadata: DecisionTreeMetadata, //元信息
continuousFeatures: IndexedSeq[Int] //连续特征的index
): Array[Array[Split]] =
//这一步是找到连续特征的多个可能分裂点
val continuousSplits: scala.collection.Map[Int, Array[Split]] =
val numPartitions = math.min(continuousFeatures.length, input.partitions.length)
input
.flatMap(point => continuousFeatures.map(idx => (idx, point.features(idx))))//得到的RDD是RDD<features_idx, features_value>
.groupByKey(numPartitions) // <features_idx, list<features_value>>
.map case (idx, samples) =>
val thresholds = findSplitsForContinuousFeature(samples, metadata, idx) //连续特征分裂候选的排序、分裂函数
val splits: Array[Split] = thresholds.map(thresh => new ContinuousSplit(idx, thresh))
logDebug(s"featureIndex = $idx, numSplits = $splits.length")
(idx, splits)
.collectAsMap() //a map that contains <idx, splits>
//将连续特征和分类特征的分裂点合并并返回
val numFeatures = metadata.numFeatures
val splits: Array[Array[Split]] = Array.tabulate(numFeatures)
case i if metadata.isContinuous(i) =>
val split = continuousSplits(i)
metadata.setNumSplits(i, split.length)
split
case i if metadata.isCategorical(i) && metadata.isUnordered(i) =>
// Unordered features
// 2^(maxFeatureValue - 1) - 1 combinations
val featureArity = metadata.featureArity(i)
Array.tabulate[Split](metadata.numSplits(i)) splitIndex =>
val categories = extractMultiClassCategories(splitIndex + 1, featureArity)
new CategoricalSplit(i, categories.toArray, featureArity)
case i if metadata.isCategorical(i) =>
// Ordered features
// Splits are constructed as needed during training.
Array.empty[Split]
splits
//这一步是找到很多可能的分裂点
private[tree] def findSplitsForContinuousFeature(
featureSamples: Iterable[Double],//特征featureIndex的值集合featureSamples
metadata: DecisionTreeMetadata,
featureIndex: Int): Array[Double] =
require(metadata.isContinuous(featureIndex),
"findSplitsForContinuousFeature can only be used to find splits for a continuous feature.")
val splits = if (featureSamples.isEmpty)
Array.empty[Double]
else
val numSplits = metadata.numSplits(featureIndex)//分裂数
// get count for each distinct value
val (valueCountMap, numSamples) = featureSamples.foldLeft((Map.empty[Double, Int], 0)) //(Map.empty[Double, Int], 0)是foldLeft函数传入的初始值
case ((m, cnt), x) => //(m, cnt)已经累加的值 ,x 为新传入的值 即featureSamples中的值
(m + ((x, m.getOrElse(x, 0) + 1)), cnt + 1)//每个特征值得数量在valueCountMap中key = numSamples中value, valueCountMap中value=该特征值的计数,,numSamples为总的计数
// sort distinct values
val valueCounts = valueCountMap.toSeq.sortBy(_._1).toArray //根据特征值的大小排序
// if possible splits is not enough or just enough, just return all possible splits
val possibleSplits = valueCounts.length - 1
if (possibleSplits <= numSplits)
valueCounts.map(_._1).init //如果特征值数目小于设定值,直接返回所有的特征值作为分裂值
else
// stride between splits
val stride: Double = numSamples.toDouble / (numSplits + 1)
logDebug("stride = " + stride)
// iterate `valueCount` to find splits
val splitsBuilder = mutable.ArrayBuilder.make[Double]
var index = 1
// currentCount: sum of counts of values that have been visited
var currentCount = valueCounts(0)._2
//这里划分成numSplits个分裂点,并使划分后每箱样本数量均衡
var targetCount = stride
while (index < valueCounts.length)
val previousCount = currentCount
currentCount += valueCounts(index)._2 //取得当前值的样本数量
val previousGap = math.abs(previousCount - targetCount)
val currentGap = math.abs(currentCount - targetCount)
// If adding count of current value to currentCount
// makes the gap between currentCount and targetCount smaller,
// previous value is a split threshold.
if (previousGap < currentGap)
splitsBuilder += valueCounts(index - 1)._1
targetCount += stride
index += 1
splitsBuilder.result()
splits
第二部分:
决策树的整体训练流程
上面介绍了决策树的基本概念、决策树的存储与表示、决策树特征选择算法、特征值分裂候选集等和决策树息息相关的一些概念和算法。以及在"spark.mllib源码阅读-bagging方法"介绍的随机森林的样本子集抽样算法。

决策树的训练过程在上面各个组件的基础上,通过特征值分裂候选集来对特征进行值集合分箱,再在子样本集上重复的进行特征选择算法来选取每个结点的最优特征与特征值划分来构造树的结点,直至满足结点分裂的终止规则。下面以一个实例开始,来一步步的剖析的决策树的整个训练过程。
以下实例摘自org.apache.spark.examples.mllib.JavaDecisionTreeClassificationExample。
SparkConf sparkConf = new SparkConf().setAppName("JavaDecisionTreeClassificationExample");
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
// Load and parse the data file.
String datapath = "data/mllib/sample_libsvm_data.txt";
JavaRDD<LabeledPoint> data = MLUtils.loadLibSVMFile(jsc.sc(), datapath).toJavaRDD();
// Split the data into training and test sets (30% held out for testing)
JavaRDD<LabeledPoint>[] splits = data.randomSplit(new double[]0.7, 0.3);
JavaRDD<LabeledPoint> trainingData = splits[0];
JavaRDD<LabeledPoint> testData = splits[1];
// Set parameters.
// Empty categoricalFeaturesInfo indicates all features are continuous.
Integer numClasses = 2;
Map<Integer, Integer> categoricalFeaturesInfo = new HashMap<>();
String impurity = "gini";
Integer maxDepth = 5;
Integer maxBins = 32;
// Train a DecisionTree model for classification.
final DecisionTreeModel model = DecisionTree.trainClassifier(trainingData, numClasses,
categoricalFeaturesInfo, impurity, maxDepth, maxBins);通过输入初始参数和训练样本集,调用DecisionTree的trainClassifier方法来训练并返回一个DecisionTreeModel。下面是trainClassifier的实现代码:
def run(input: RDD[LabeledPoint]): DecisionTreeModel =
val rf = new RandomForest(strategy, numTrees = 1, featureSubsetStrategy = "all", seed = seed)
val rfModel = rf.run(input)
rfModel.trees(0)
@Since("1.0.0")
def train(
input: RDD[LabeledPoint],
algo: Algo,
impurity: Impurity,
maxDepth: Int,
numClasses: Int,
maxBins: Int,
quantileCalculationStrategy: QuantileStrategy,
categoricalFeaturesInfo: Map[Int, Int]): DecisionTreeModel =
val strategy = new Strategy(algo, impurity, maxDepth, numClasses, maxBins,
quantileCalculationStrategy, categoricalFeaturesInfo)
new DecisionTree(strategy).run(input)
@Since("1.1.0")
def trainClassifier(
input: RDD[LabeledPoint],
numClasses: Int,
categoricalFeaturesInfo: Map[Int, Int], //<n,k> 分类特征n有k个可能取值
impurity: String,
maxDepth: Int,
maxBins: Int): DecisionTreeModel =
val impurityType = Impurities.fromString(impurity)
train(input, Classification, impurityType, maxDepth, numClasses, maxBins, Sort,
categoricalFeaturesInfo)
在train方法中,将决策树的配置信息封装在Strategy这个类中,Strategy维护一系列决策树的配置参数:
class Strategy @Since("1.3.0") (
@Since("1.0.0") @BeanProperty var algo: Algo,//算法的类别:分类还是回归 Classification、Regression
@Since("1.0.0") @BeanProperty var impurity: Impurity,//计算信息增益的准则 分类基尼指数、信息增益 回归impurity.Variance
@Since("1.0.0") @BeanProperty var maxDepth: Int, //树的最大深度
@Since("1.2.0") @BeanProperty var numClasses: Int = 2,//类别数
@Since("1.0.0") @BeanProperty var maxBins: Int = 32,//连续特征离散化的分箱数
@Since("1.0.0") @BeanProperty var quantileCalculationStrategy: QuantileStrategy = Sort,//计算分裂点的算法,待定
@Since("1.0.0") @BeanProperty var categoricalFeaturesInfo: Map[Int, Int] = Map[Int, Int](),//存储每个分类特征的值数目
@Since("1.2.0") @BeanProperty var minInstancesPerNode: Int = 1,//子结点拥有的最小样本实例数,一个终止条件
@Since("1.2.0") @BeanProperty var minInfoGain: Double = 0.0,//最小的信息增益值,这个应该是用来控制迭代终止的
@Since("1.0.0") @BeanProperty var maxMemoryInMB: Int = 256,//聚合使用的内存大小。待定
@Since("1.2.0") @BeanProperty var subsamplingRate: Double = 1,//用于训练数据的抽样率
@Since("1.2.0") @BeanProperty var useNodeIdCache: Boolean = false,//待定
@Since("1.2.0") @BeanProperty var checkpointInterval: Int = 10 //checkpoint)这些配置参数在训练过程中都需要用到。在DecisionTree.run中调用了org.apache.spark.mllib.tree.RandomForest这个类的run方法,实际上在这个run方法中也没干啥事:
//org.apache.spark.mllib.tree.RandomForest下的run方法
def run(input: RDD[LabeledPoint]): RandomForestModel =
//包导入的时候将org.apache.spark.ml.tree.RandomForest重命名为NewRandomForest了。
//import org.apache.spark.ml.tree.impl.RandomForest => NewRandomForest 注意这句import,要不然不知道NewRandomForest在哪里
val trees: Array[NewDTModel] = NewRandomForest.run(input.map(_.asML), strategy, numTrees,
featureSubsetStrategy, seed.toLong, None)
new RandomForestModel(strategy.algo, trees.map(_.toOld))
不过在这里终于是找到真正的决策树训练算法实现了,其真正的实现在org.apache.spark.ml.tree包下的RandomForest。ml包是spark新开的一个轮子,基于DataFrame提供管道式机器学习方案。
来看看org.apache.spark.ml.tree包下的RandomForest对决策树的具体实现:
//代码有删减,只保留主要的关键流程
def run(
input: RDD[LabeledPoint],//输入数据
strategy: OldStrategy,//树的配置信息
numTrees: Int,//树的数量,意味着这个训练方法可以和随机森林这类一次训练多棵树的模型公用
featureSubsetStrategy: String,//是否使用全量的特征
seed: Long,
instr: Option[Instrumentation[_]],// parentUID 上一棵决策树的ID
parentUID: Option[String] = None): Array[DecisionTreeModel] =
val retaggedInput = input.retag(classOf[LabeledPoint])
//统计数据的元信息,如各个特征的分箱数,各个结点的特征数
val metadata = DecisionTreeMetadata.buildMetadata(retaggedInput, strategy, numTrees, featureSubsetStrategy)
instr match
case Some(instrumentation) =>
instrumentation.logNumFeatures(metadata.numFeatures)
instrumentation.logNumClasses(metadata.numClasses)
case None =>
logInfo("numFeatures: " + metadata.numFeatures)
logInfo("numClasses: " + metadata.numClasses)
val splits = findSplits(retaggedInput, metadata, seed) //划分得到每个特征的多个可能的分裂点,解析见本篇分裂候选章节
val treeInput = TreePoint.convertToTreeRDD(retaggedInput, splits, metadata)
val withReplacement = numTrees > 1 //多颗树时使用有放回抽样
//使用柏松分布对样本集进行抽样,见对BaggedPoint的介绍(博客"spark.mllib源码阅读-bagging方法")。
val baggedInput = BaggedPoint.convertToBaggedRDD(treeInput, strategy.subsamplingRate, numTrees, withReplacement, seed)
.persist(StorageLevel.MEMORY_AND_DISK)
val maxDepth = strategy.maxDepth //树的最大深度
// Max memory usage for aggregates TODO: Calculate memory usage more precisely.
val maxMemoryUsage: Long = strategy.maxMemoryInMB * 1024L * 1024L
// Create an RDD of node Id cache.
// At first, all the rows belong to the root nodes (node Id == 1).
val nodeIdCache = if (strategy.useNodeIdCache)
Some(NodeIdCache.init(data = baggedInput, numTrees = numTrees, checkpointInterval = strategy.checkpointInterval, initVal = 1))
else
None
//前面都是数据的准备阶段,这里才正式开始决策树(森林)的训练
//初始化一个存储(treeIndex,rootNode)的结点栈
val nodeStack = new mutable.Stack[(Int, LearningNode)]
val rng = new Random()
rng.setSeed(seed)
//初始化每棵树的根结点
val topNodes = Array.fill[LearningNode](numTrees)(LearningNode.emptyNode(nodeIndex = 1))
//将初始化每棵树的根结点进栈
Range(0, numTrees).foreach(treeIndex => nodeStack.push((treeIndex, topNodes(treeIndex))))
//依次训练这numTrees棵树
while (nodeStack.nonEmpty)
//特征集抽样,得到每棵树的子特征集
val (nodesForGroup, treeToNodeToIndexInfo) = RandomForest.selectNodesToSplit(nodeStack, maxMemoryUsage, metadata, rng)
// Only send trees to worker if they contain nodes being split this iteration.
val topNodesForGroup: Map[Int, LearningNode] = nodesForGroup.keys.map(treeIdx => treeIdx -> topNodes(treeIdx)).toMap
//这里从特征子集中选取最优的特征及特征值划分来构建树的结点,并在新建结点不是叶子结点时,将新的结点push入nodeStack栈,来实现循环并最终将树分裂至叶子结点。
RandomForest.findBestSplits(baggedInput, metadata, topNodesForGroup, nodesForGroup, treeToNodeToIndexInfo, splits, nodeStack, timer, nodeIdCache)
baggedInput.unpersist()
// Delete any remaining checkpoints used for node Id cache.
if (nodeIdCache.nonEmpty)
try
nodeIdCache.get.deleteAllCheckpoints()
catch
case e: IOException =>
logWarning(s"delete all checkpoints failed. Error reason: $e.getMessage")
val numFeatures = metadata.numFeatures
parentUID match
case Some(uid) =>
if (strategy.algo == OldAlgo.Classification)
topNodes.map rootNode =>
new DecisionTreeClassificationModel(uid, rootNode.toNode, numFeatures,
strategy.getNumClasses)
else
topNodes.map rootNode =>
new DecisionTreeRegressionModel(uid, rootNode.toNode, numFeatures)
case None =>
if (strategy.algo == OldAlgo.Classification)
topNodes.map rootNode =>
new DecisionTreeClassificationModel(rootNode.toNode, numFeatures,
strategy.getNumClasses)
else
topNodes.map(rootNode => new DecisionTreeRegressionModel(rootNode.toNode, numFeatures))
该实现代码可以分成两部分来看:前半部分完成了训练数据的元信息的统计、特征值分裂候选集、根据树的数量抽样得到子样本集。后半部分为每棵树抽样特征子集,并选取特征及分裂点进行结点的分裂与树的生成。RandomForest.findBestSplits从特征子集中选取最优的特征及特征值划分来构建树的结点,并在新建结点不是叶子结点时,将新的结点push入nodeStack栈,来实现循环并最终将树分裂至叶子结点。
采用栈结构来存储训练时的结点是该实现比较巧妙的地方,如果栈不为空,则表示还有终端结点需要分裂,如果栈为空,表示所有的终端结点都是叶子结点,树构建完成。
以上是关于spark.mllib源码阅读-分类算法4-DecisionTree的主要内容,如果未能解决你的问题,请参考以下文章