Spark算子执行流程详解之六
Posted 亮亮-AC米兰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark算子执行流程详解之六相关的知识,希望对你有一定的参考价值。
26.coalesce
coalesce顾名思义为合并,就是把多个分区的RDD合并成少量分区的RDD,这样可以减少任务调度的时间,但是请记住:合并之后不能保证结果RDD中的每个分区的记录数量是均衡的,因为合并的时候并没有考虑合并前每个分区的记录数,合并只会减少RDD的分区个数,因此并不能利用它来解决数据倾斜的问题。
| def coalesce(numPartitions: Int, shuffle: Boolean =false)(implicitord:Ordering[T] =null) //将原来的记录映射为(K,记录)对,其中K为随机数的不断叠加 //针对(k,记录)进行一次Hash分区 |
先看其shuffle参数,如果为true的话,则先生成一个ShuffleRDD,然后在这基础上产生CoalescedRDD,如果为false的话,则直接生成CoalescedRDD。因此先看下其ShuffleRDD的生成过程:
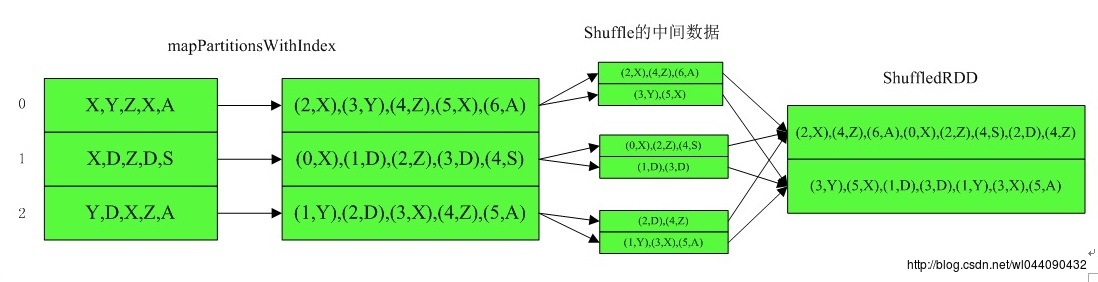
以上是将3个分区合并成2个分区,当shuffle为true的时候,其CoalescedRDD父RDD即ShuffledRDD的生成过程,如果shuffle为false的时候,则直接利用其本身取生成CoalescedRDD。
再来看CoalescedRDD的计算过程:
| private[spark] classCoalescedRDD[T: ClassTag]( /** * parentsIndices它代表了当前CoalescedRDD对应分区索引的分区是由父RDD的哪几个分区组成的 * @param preferredLocation the preferred location for this partition |
CoalescedRDD的分区结果由CoalescedRDDPartition决定,其中parentsIndices参数代表了CoalescedRDD的某个分区索引的分区来源于其父RDD的哪几个分区,然后就是利用flatMap把父RDD的多个分区串联起来。因此主要关注CoalescedRDD是如何生成CoalescedRDDPartition的,即
| override def getPartitions: Array[Partition] = |
通过PartitionCoalescer来计算生成CoalescedRDDPartition:
| /** //设置一个个group throwBalls() // assign partitions (balls) to each group (bins) |
首先生成一个个PartitionGroup,里面的arr保存了父rdd的分区索引,然后把其他父rdd没有分配的分区投放至PartitionGroup里面。先看setupGroups的过程,它首先生成targetLen个PartitionGroup,里面包含了初始默认的父rdd的分区索引,其流程如下:
/** * Initializes targetLen partition groups and assigns a preferredLocation * This uses coupon collector to estimate how many preferredLocations it must rotate through * until it has seen most of the preferred locations (2 * n log(n)) * @param targetLen */ def setupGroups(targetLen: Int) val rotIt = new LocationIterator(prev) // deal with empty case, just create targetLen partition groups with no preferred location //如果父RDD的分区没有本地性,则直接生成targetLen个PartitionGroup返回 if (!rotIt.hasNext) (1 to targetLen).foreach(x => groupArr += PartitionGroup()) return noLocality = false // number of iterations needed to be certain that we've seen most preferred locations val expectedCoupons2 = 2 * (math.log(targetLen)*targetLen + targetLen + 0.5).toInt var numCreated = 0 var tries = 0 // rotate through until either targetLen unique/distinct preferred locations have been created // OR we've rotated expectedCoupons2, in which case we have likely seen all preferred locations, // i.e. likely targetLen >> number of preferred locations (more buckets than there are machines) //优先针对每台主机建立其对应的PartitionGroup,目的是为了让之后的计算更加分散 while (numCreated < targetLen && tries < expectedCoupons2) tries += 1 // rotIt.next()的返回值为(String, Partition),其中nxt_replica为主机名 nxt_part为分区索引 val (nxt_replica, nxt_part) = rotIt.next() if (!groupHash.contains(nxt_replica)) val pgroup = PartitionGroup(nxt_replica) groupArr += pgroup addPartToPGroup(nxt_part, pgroup)//将其分区索引添加进此PartitionGroup groupHash.put(nxt_replica, ArrayBuffer(pgroup)) // list in case we have multiple numCreated += 1 //如果还没有足够多的PartitionGroup,实在不行则针对同一个主机名可以创建多个PartitionGroup while (numCreated < targetLen) // if we don't have enough partition groups, create duplicates //(String, Partition) 主机名 分区索引 var (nxt_replica, nxt_part) = rotIt.next() val pgroup = PartitionGroup(nxt_replica) groupArr += pgroup // val groupHash = mutable.Map[String, ArrayBuffer[PartitionGroup]]() (主机名,PartitionGroup(主机名)),同一个主机名可能存在多个PartitionGroup groupHash.getOrElseUpdate(nxt_replica, ArrayBuffer()) += pgroup var tries = 0 //将其分区索引添加进此PartitionGroup while (!addPartToPGroup(nxt_part, pgroup) && tries < targetLen) // ensure at least one part nxt_part = rotIt.next()._2 tries += 1 numCreated += 1 |
然后将剩余没有分配的父rdd的分区分配至对应的PartitionGroup
def throwBalls() if (noLocality) // no preferredLocations in parent RDD, no randomization needed 没有本地性,少分区合并成多分区,无法合并,保持原样 if (maxPartitions > groupArr.size) // just return prev.partitions for ((p, i) <- prev.partitions.zipWithIndex) groupArr(i).arr += p else // no locality available, then simply split partitions based on positions in array for (i <- 0 until maxPartitions) //否则无本地性要求的情况下,简单的按区间进行合并 val rangeStart = ((i.toLong * prev.partitions.length) / maxPartitions).toInt val rangeEnd = (((i.toLong + 1) * prev.partitions.length) / maxPartitions).toInt (rangeStart until rangeEnd).foreach j => groupArr(i).arr += prev.partitions(j) else //遍历父rdd的分区,且之前没有被分配过,则进行分配 for (p <- prev.partitions if (!initialHash.contains(p))) // throw every partition into group //选择某个PartitionGroup,然后添加至arr pickBin(p).arr += p
|
那么pickBin是如何计算的呢?且看:
/** * Takes a parent RDD partition and decides which of the partition groups to put it in * Takes locality into account, but also uses power of 2 choices to load balance * It strikes a balance between the two use the balanceSlack variable * @param p partition (ball to be thrown) * @return partition group (bin to be put in) */ def pickBin(p: Partition): PartitionGroup = //获取父rdd的该Partition的本地性所在主机的列表,并按其包含的分区数目从少到多排序 val pref = currPrefLocs(p).map(getLeastGroupHash(_)).sortWith(compare) // least loaded pref locs //如果没有列表,则返回none,如果有,则返回最少的那个主机名的PartitionGroup val prefPart = if (pref == Nil) None else pref.head //随机选择2个PartitionGroup中包含分区数目最小的PartitionGroup val r1 = rnd.nextInt(groupArr.size) val r2 = rnd.nextInt(groupArr.size) val minPowerOfTwo = if (groupArr(r1).size < groupArr(r2).size) groupArr(r1) else groupArr(r2) if (prefPart.isEmpty) //如果无本地性要求,则返回minPowerOfTwo // if no preferred locations, just use basic power of two return minPowerOfTwo val prefPartActual = prefPart.get //否则根据平衡因子来选择 if (minPowerOfTwo.size + slack <= prefPartActual.size) // more imbalance than the slack allows minPowerOfTwo // prefer balance over locality else prefPartActual // prefer locality over balance |
因此合并的原则就是:
1.保证CoalescedRDD的每个分区个数相同
2.CoalescedRDD的每个分区,尽量跟它的Parent RDD的本地性相同。比如说CoalescedRDD的分区1对应于它的Parent RDD的1到10这10个分区,但是1到7这7个分区在节点1.1.1.1上,那么 CoalescedRDD的分区1所要执行的节点就是1.1.1.1。这么做的目的是为了减少节点间的数据通信,提升处理能力。
3.CoalescedRDD的分区尽量分配到不同的节点执行
比如说:
1)3个分区合并成2个分区,shuffle为true

ShuffleRDD的getPreferredLocations为Nil
2)2个分区合并成3个分区,shuffle为true

ShuffleRDD的getPreferredLocations为Nil
3)5个分区合并成3个分区,shuffle为 false,父RDD的每个分区都包含本地性
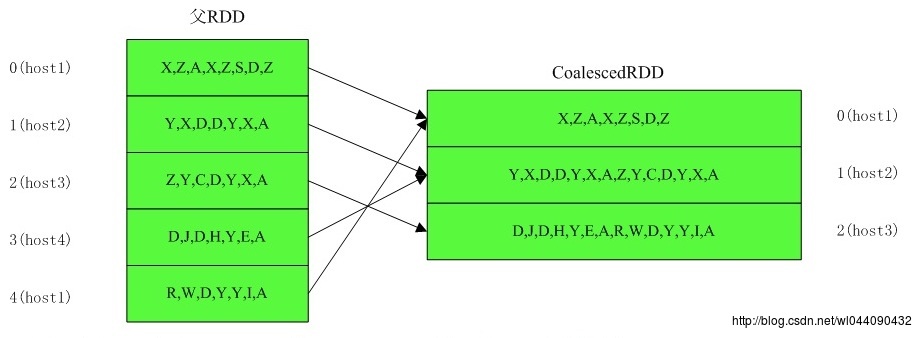
4)5个分区合并成3个分区,shuffle为 false,父RDD的每个分区不包含本地性
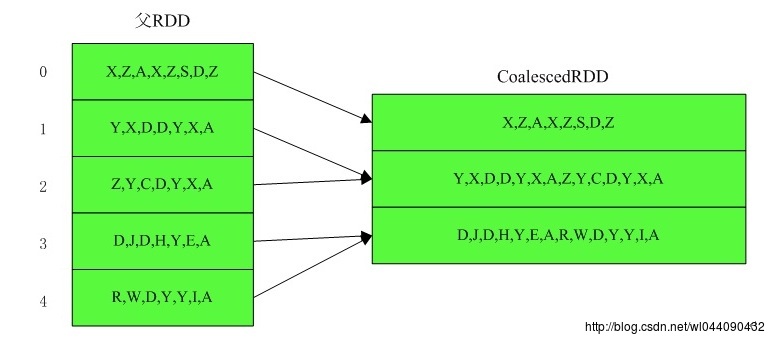
5)3个分区合并成5个分区,shuffle为 false,父RDD的每个分区都包含本地性
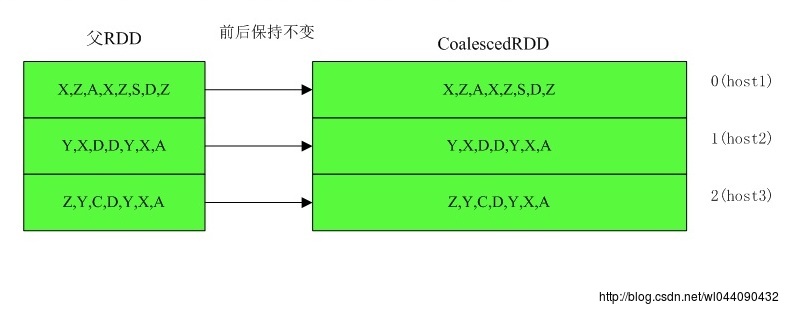
6)3个分区合并成5个分区,shuffle为 false,父RDD的每个分区不包含本地性
27.repartition
对RDD重分区,重分区之后的分区个数为numPartitions。
/** * Return a new RDD that has exactly numPartitions partitions. * * Can increase or decrease the level of parallelism in this RDD. Internally, this uses * a shuffle to redistribute data. * * If you are decreasing the number of partitions in this RDD, consider using `coalesce`, * which can avoid performing a shuffle. */ def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope coalesce(numPartitions, shuffle = true) |
可见其本质调用的还是coalesce,但是其shuffle参数为true,因为如果为false,则有可能获取不到指定分区个数的rdd
28.sample
Sample是对rdd中的数据集进行采样,并生成一个新的RDD,这个新的RDD只有原来RDD的部分数据,这个保留的数据集大小由fraction来进行控制.
/** * Return a sampled subset of this RDD. * * @param withReplacement can elements be sampled multiple times (replaced when sampled out) * @param fraction expected size of the sample as a fraction of this RDD's size * without replacement: probability that each element is chosen; fraction must be [0, 1] * with replacement: expected number of times each element is chosen; fraction must be >= 0 * @param seed seed for the random number generator */ def sample( withReplacement: Boolean, fraction: Double, seed: Long = Utils.random.nextLong): RDD[T] = withScope require(fraction >= 0.0, "Negative fraction value: " + fraction) if (withReplacement) new PartitionwiseSampledRDD[T, T](this, new PoissonSampler[T](fraction), true, seed) else new PartitionwiseSampledRDD[T, T](this, new BernoulliSampler[T](fraction), true, seed) |
withReplacement:这个值如果是true时,采用PoissonSampler抽样器(Poisson分布),否则使用BernoulliSampler的抽样器.
Fraction:一个大于0,小于或等于1的小数值,用于控制要读取的数据所占整个数据集的概率.
Seed:这个值如果没有传入,默认值是一个0~Long.maxvalue之间的整数.
至于那个PoissonSampler抽样器和BernoulliSampler抽样器,数学理论比较深,大家感兴趣可以百度相关资料查看其抽样原理,这里不详细叙述其抽样的内部原理。
继续看PartitionwiseSampledRDD:
private[spark] class PartitionwiseSampledRDD[T: ClassTag, U: ClassTag]( prev: RDD[T], sampler: RandomSampler[T, U], @transient preservesPartitioning: Boolean, @transient seed: Long = Utils.random.nextLong) extends RDD[U](prev) @transient override val partitioner = if (preservesPartitioning) prev.partitioner else None override def getPartitions: Array[Partition] = val random = new Random(seed) firstParent[T].partitions.map(x => new PartitionwiseSampledRDDPartition(x, random.nextLong())) override def getPreferredLocations(split: Partition): Seq[String] = firstParent[T].preferredLocations(split.asInstanceOf[PartitionwiseSampledRDDPartition].prev) override def compute(splitIn: Partition, context: TaskContext): Iterator[U] = val split = splitIn.asInstanceOf[PartitionwiseSampledRDDPartition] val thisSampler = sampler.clone thisSampler.setSeed(split.seed) //调用不同的抽样器针对每个分区进行抽样 thisSampler.sample(firstParent[T].iterator(split.prev, context)) |
29.takeSample
takeSample函数返回一个数组,在数据集中随机采样 num 个元素组成。
/** * Return a fixed-size sampled subset of this RDD in an array * * @param withReplacement whether sampling is done with replacement * @param num size of the returned sample * @param seed seed for the random number generator * @return sample of specified size in an array */ // TODO: rewrite this without return statements so we can wrap it in a scope def takeSample( withReplacement: Boolean, num: Int, seed: Long = Utils.random.nextLong): Array[T] = val numStDev = 10.0 if (num < 0) //num为负数,直接抛异常 throw new IllegalArgumentException("Negative number of elements requested") else if (num == 0) //num为0的话,直接返回空数组 return new Array[T](0) val initialCount = this.count() if (initialCount == 0) //如果rdd为空的话,那么就直接返回空数组 return new Array[T](0) //计算最大允许的采样个数 val maxSampleSize = Int.MaxValue - (numStDev * math.sqrt(Int.MaxValue)).toInt if (num > maxSampleSize) throw new IllegalArgumentException("Cannot support a sample size > Int.MaxValue - " + s"$numStDev * math.sqrt(Int.MaxValue)") val rand = new Random(seed) //如果不支持重复采样,且采样总数大于rdd的个数,则直接把rdd的数据集混洗完返回 if (!withReplacement && num >= initialCount) return Utils.randomizeInPlace(this.collect(), rand) //为了利用sample方法,需要计算采样百分比 val fraction = SamplingUtils.computeFractionForSampleSize(num, initialCount, withReplacement) //尝试进行第一次采样 var samples = this.sample(withReplacement, fraction, rand.nextInt()).collect() // If the first sample didn't turn out large enough, keep trying to take samples; // this shouldn't happen often because we use a big multiplier for the initial size var numIters = 0 //如果采样返回的个数不满足条件,则继续利用sample进行采样 while (samples.length < num) logWarning(s"Needed to re-sample due to insufficient sample size. Repeat #$numIters") samples = this.sample(withReplacement, fraction, rand.nextInt()).collect() numIters += 1 //将结果集混洗完取前num条数据 Utils.randomizeInPlace(samples, rand).take(num) |
30.randomSplit
依据所提供的权重对该RDD进行随机划分
def randomSplit( weights: Array[Double], seed: Long = Utils.random.nextLong): Array[RDD[T]] = withScope val sum = weights.sum val normalizedCumWeights = weights.map(_ / sum).scanLeft(0.0d)(_ + _) normalizedCumWeights.sliding(2).map x => randomSampleWithRange(x(0), x(1), seed) .toArray /** * Internal method exposed for Random Splits in DataFrames. Samples an RDD given a probability * range. * @param lb lower bound to use for the Bernoulli sampler * @param ub upper bound to use for the Bernoulli sampler * @param seed the seed for the Random number generator * @return A random sub-sample of the RDD without replacement. */ private[spark] def randomSampleWithRange(lb: Double, ub: Double, seed: Long): RDD[T] = this.mapPartitionsWithIndex( (index, partition) => val sampler = new BernoulliCellSampler[T](lb, ub) sampler.setSeed(seed + index) sampler.sample(partition) , preservesPartitioning = true) |
假设按照以下进行采样:
| List<Integer> data = Arrays.asList(1,2,4,3,5,6,7); JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data); double [] weights = 1,2,3,4; //依据所提供的权重对该RDD进行随机划分 JavaRDD<Integer> [] randomSplitRDDs = javaRDD.randomSplit(weights); |
先进行权重的计算,即normalizedCumWeights=[0.0,0.1,0.3,0.6,1.0],然后调用normalizedCumWeights.sliding(2)将其两两分组,即转化为[0.0,0.1],[0.1,0.3],[0.3,0.6],[0.6,0.1],接着利用伯努利采样器进行采样,即:
class BernoulliCellSampler[T](lb: Double, ub: Double, complement: Boolean = false) extends RandomSampler[T, T] /** epsilon slop to avoid failure from floating point jitter. */ require( lb <= (ub + RandomSampler.roundingEpsilon), s"Lower bound ($lb) must be <= upper bound ($ub)") require( lb >= (0.0 - RandomSampler.roundingEpsilon), s"Lower bound ($lb) must be >= 0.0") require( ub <= (1.0 + RandomSampler.roundingEpsilon), s"Upper bound ($ub) must be <= 1.0") private val rng: Random = new XORShiftRandom override def setSeed(seed: Long): Unit = rng.setSeed(seed) //利用sample进行采样 override def sample(items: Iterator[T]): Iterator[T] = if (ub - lb <= 0.0) if (complement) items else Iterator.empty else if (complement) items.filter item => val x = rng.nextDouble() (x < lb) || (x >= ub) else //正常走这个分之,其complement为false //其实就是利用rng生成随机数,然后判断其范围,是否在[lb,ub)区间范围之内,是的话就保留,否则就抛弃 items.filter item => val x = rng.nextDouble() (x >= lb) && (x < ub) /** * Return a sampler that is the complement of the range specified of the current sampler. */ def cloneComplement(): BernoulliCellSampler[T] = new BernoulliCellSampler[T](lb, ub, !complement) override def clone: BernoulliCellSampler[T] = new BernoulliCellSampler[T](lb, ub, complement) |
则以上采样的结果可能为,权重大的获取到的数据量就大,但相互之间不一定成比例,只代表一种概率
scala> randomSplitRDDs (0).collect res10: Array[Int] = Array(1, 4) scala> randomSplitRDDs (1).collect res11: Array[Int] = Array(3) scala> randomSplitRDDs (2).collect res12: Array[Int] = Array(5, 9) scala> randomSplitRDDs (3).collect res13: Array[Int] = Array(2, 6, 7, 8, 10) |
以上是关于Spark算子执行流程详解之六的主要内容,如果未能解决你的问题,请参考以下文章