nlp cs224n 学习笔记1 Introduction and Word Vectors
Posted 随煜而安
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了nlp cs224n 学习笔记1 Introduction and Word Vectors相关的知识,希望对你有一定的参考价值。
注:个人笔记,价值有限,不建议逗留。
word embedding 的意义和目的?
通过一种映射,将自然语言中的单词,嵌入到n维欧式空间中,得到可以用数学语言表达并用计算机计算的“词向量”。
同时我们希望,在语言中语义相近的词汇,在映射后的空间中仍具有相似性(表现为距离相近)
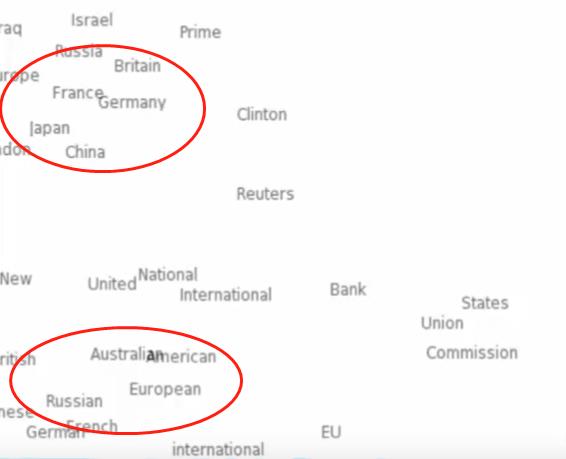
分布式语义
如何学习具有我们想要特性的word embedding呢?
一个重要的思路是分布式语义:
一个单词的含义由频繁的出现在其附近的单词所决定
有一定道理,就好像我们在学语言时,一个单词的具体含义,经常通过给出的若干例句来记住和理解。

Skip-Gram
进行word embedding的方法应该有很多,今天学习了 skip-gram
这里是一个不错的教程
模型结构:

个人感觉结构和思想都很像自编码器。
输入层:对词典进行one-hot编码
如何得到某个单词的词向量?
网络的隐层的输出就是最终的 词向量。
但实际中,并不需要进行前向推理,更像是查表,因为:
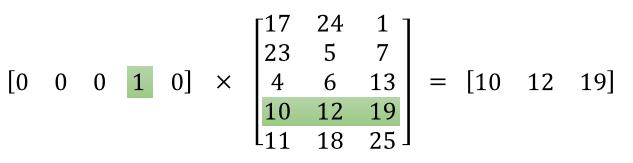
模型是如何学到有效的词向量的?
基于分布式语义的合理假设,设定输出层负责预测所有词表中的单词出现在当前输入的单词周围的概率。
以上是关于nlp cs224n 学习笔记1 Introduction and Word Vectors的主要内容,如果未能解决你的问题,请参考以下文章