论文导读2Causal Machine Learning:A Survey and Open Problems
Posted ViviranZ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文导读2Causal Machine Learning:A Survey and Open Problems相关的知识,希望对你有一定的参考价值。
目录
3.1 不变特征学习(Invariant Feature Learning,IFL)
3.1.1.1 Deconfounding data(数据去混杂)
3.1.2.3 Style and Content as Latent Variables
7.15 开始第三章:因果监督学习Causal Supervised Learning
这一章和我前段时间追的崔鹏教授的内容相一致,主要针对ML中“我们感兴趣的数据都是独立同分布的”这个实际上并不准确的假设。
我们可以假设我们的数据是由 SCM 管理的干预分布生成的。 对于across一组环境 ,
, 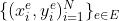 生成的给定数据集,我们将每个环境 e ∈ E 视为从单独的干预分布中采样的。 参考图 3.1 中的示例,我们将测试数据集视为通过对背景特征的潜在变量进行干预而生成的。
生成的给定数据集,我们将每个环境 e ∈ E 视为从单独的干预分布中采样的。 参考图 3.1 中的示例,我们将测试数据集视为通过对背景特征的潜在变量进行干预而生成的。

我们如何以有原则的方式估计 p(y | x)? 在不变特征学习中,我们学习 Y 的因果父母的内容表示 C,pa(Y),使得在所有环境中 Y ∼ p(y | c) 。 在不变机制学习中,我们确定了一组映射 F,它允许我们在一系列介入分布中从 X 预测 Y。
3.1 不变特征学习(Invariant Feature Learning,IFL)
IFL部分的整体架构如下:
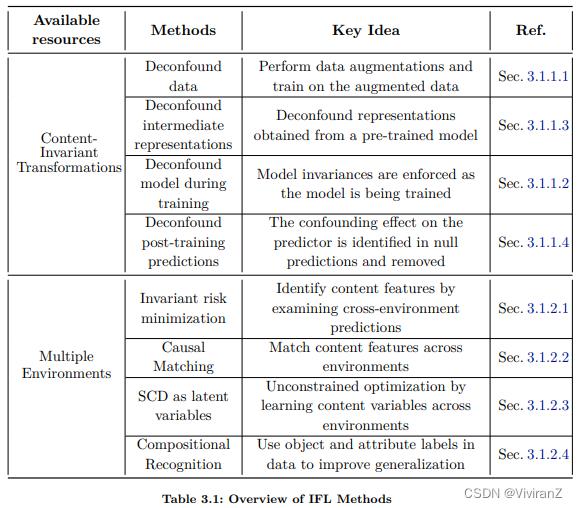
不变特征学习旨在找到稳定的特征,因果上我们认为是去找因果父节点(Causal parent) ,理论基础如下:(C2的定义) 
3.1.1.1 Deconfounding data(数据去混杂)
通常,我们需要针对问题对因果模型进行简化:把目标变量的父节点看成一个整体(表示成向量?),而把其它的混杂变量看作另一部分,例子如下:
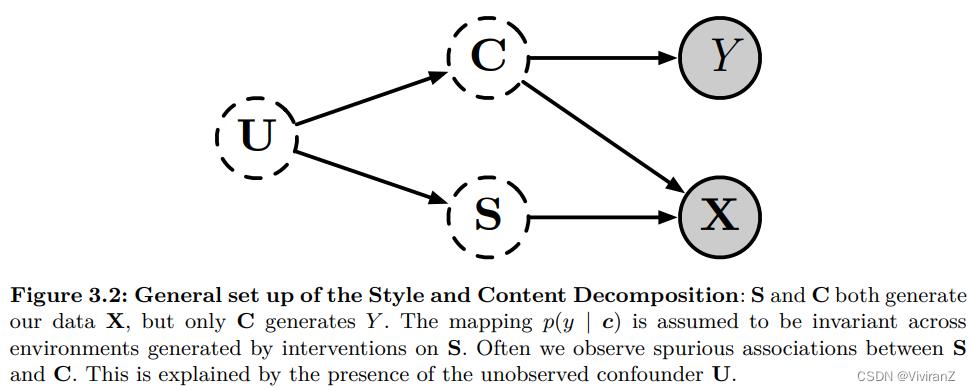 我们知道,对于真正的目标变量Y,我们想研究的都放在C里了,那么C就是我们想要的稳定变量,但是由于有X这个C和S的共果,在数据上会表现出S和C的相关性、进而错误把S也作为了Y的特征,一般地,我们将这种错误关系(spurious relation)认为是有一个共因U(即使实际上是因为共果产生的)。将以上分解方式总结为:
我们知道,对于真正的目标变量Y,我们想研究的都放在C里了,那么C就是我们想要的稳定变量,但是由于有X这个C和S的共果,在数据上会表现出S和C的相关性、进而错误把S也作为了Y的特征,一般地,我们将这种错误关系(spurious relation)认为是有一个共因U(即使实际上是因为共果产生的)。将以上分解方式总结为:

当我们假设以上分解方式是合理的时候,我们可以有如下定义:

并进一步有了以下的数据增强定义:
 挺有意思的,类似于我看到的这篇论文:Zhang X., Zhou L., Xu R., Cui P.,et al. Towards Unsupervised Domain Generalization. CVPR, 2022.,变换特征-找到不变的特征-认为是稳定的因果特征(这里被称为content variable)。在UDG问题里被称为用于寻找稳定变量的加入负样本的过程,在这里从数据增强的角度看待。
挺有意思的,类似于我看到的这篇论文:Zhang X., Zhou L., Xu R., Cui P.,et al. Towards Unsupervised Domain Generalization. CVPR, 2022.,变换特征-找到不变的特征-认为是稳定的因果特征(这里被称为content variable)。在UDG问题里被称为用于寻找稳定变量的加入负样本的过程,在这里从数据增强的角度看待。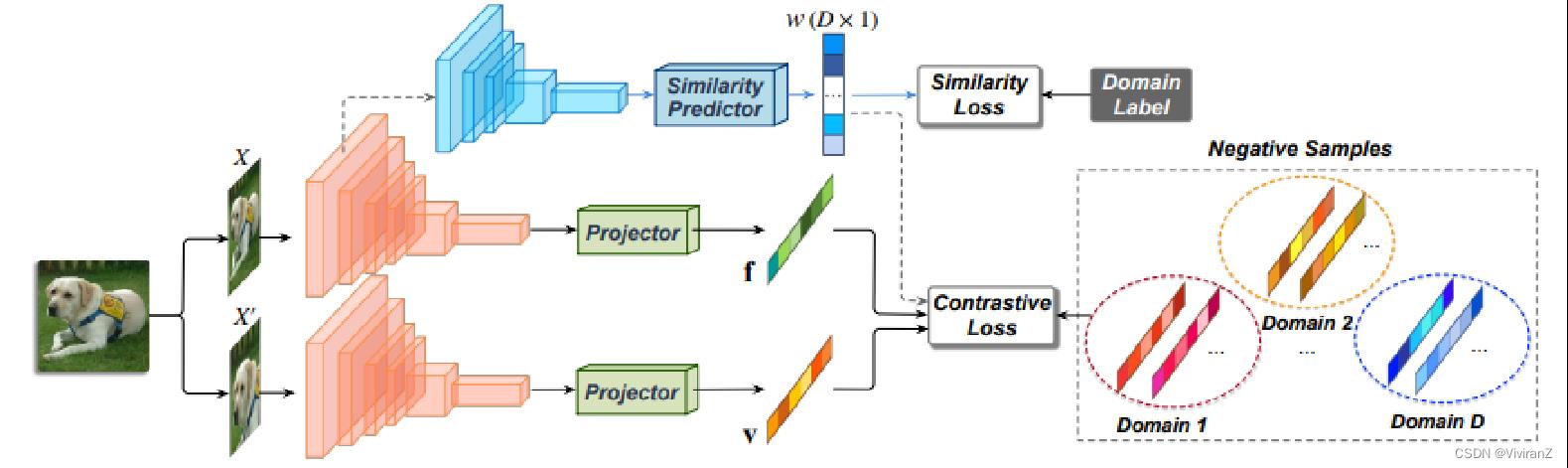
本节中的增强是手工制作的。在第 4 章后面,我们将回顾如何使用因果生成模型生成反事实数据增强。
伊尔斯等人。 [31] 解释说,DA 削弱了观察到的域和任务标签之间的虚假关联。为了证明这一点,他们引入了干预增强方差的概念,将数据增强和对领域引起的特征的干预之间的关系形式化。如果干预-增强方差成立,则可以使用数据增强仅使用观察数据来模拟新环境 e 。这消除了由隐藏的混杂 U 引起的虚假关联 E ← U → Y,它允许 E 通过后门影响 Y。基于这种洞察力,他们推导出了一种算法,该算法能够从转换列表中选择数据增强技术,从而实现更好的域泛化。
【论文导读】Selecting Data Augmentation for Simulating Interventions_ViviranZ的博客-CSDN博客
考希克等人。 [33] 提出了一种通过人在循环过程中进行数据增强的方法,在该过程中,给定一些文档及其(初始)标签,人类必须通过足以翻转标签的编辑来修改文本,从而生成反事实样本。重要的是,禁止进行不足以翻转适用标签的编辑。因此,它们生成负样本和正样本,允许对比学习作为表示学习的一种方法
Explaining The Efficacy of Counterfactually-Augmented Data - TABball - 博客园
特尼等人。 [34] 通过合并具有对比标签但语义信息相似(即相似的内容变量)的样本(即反事实样本)进一步发展了这一想法,作为改进模型 f(·) 训练的一种手段(进一步评论见第 4 章)。他们提出了一个新的正则化项,它强制局部梯度 ∇xf(xi) 和 ground truth 梯度之间的对齐。在两个对比样本及其对应的标签之间,ground truth 梯度模拟了切换模型输出所需的输入空间中的转换。
具体来说,对于 yi != yj 的两个反事实样本 (xi , yi),(xj , yj ),定义 gi = ∇xf (xi) 和 g^i = xj - xi 。然后他们提出的正则化项强制 g^i 和 gi 之间的相似性。该方法可以应用于从业者可以访问反事实样本的任何地方。作者展示了视觉和语言任务(例如视觉问答)的泛化能力的改进
毛等人。 [35] 使用数据增强来模拟因果干预,得出一种最佳干预策略,并提出了一个损失函数 GenInt,它结合了 GAN 生成的数据增强。他们建议根据 GANSpace [36] 中提出的方法,凭经验识别一组不会干扰对象标签的数据增强。它们直接干预原始数据中的潜在因素,例如背景和视角,如图 3.3 所示。与竞争对手的数据增强策略相比,大量实验证明了使用 AlexNet [37] 架构在 ImageNet-C 上的 OOD 分类精度更高。
下面这篇挺详细了 不再赘述
 https://blog.csdn.net/qq_37614597/article/details/116130485
https://blog.csdn.net/qq_37614597/article/details/1161304853.1.1.2 去混淆中间表示
Deconfounding intermediate representations
在这种情况下,我们可以访问 X 的样本和预训练的表示。R. Mao 等人。 [38] 提出了一种方法(参见算法 1),该方法改进了通过自监督学习或其他方式学习的预训练表示,并将其用于分类模型。 他们假设数据是由图 3.4 所示的因果结构生成的,其中 X ∼ p(x | c, s) 由样式和内容特征生成,R 是我们由预训练模型给出的 X 的表示 . 重要的是,他们假设 S 和 Y 之间存在未观察到的混杂 US,Y,这自然地解释了任何训练数据集中 X 和 Y 之间虚假关联的原因。

由于S和Y被U_S,Y所混淆,而且在假设的因果图中S→C(图3.4),因此p(y | c)也被混淆。然而,p (y | c, do (s))和p (y | do (c), s)都是不混淆的(即p (y | do (x))是不混淆的)。因此,Mao等人[38]认为p (y | c, do (s))是一个不变的预测因子。为了模拟这种对给定样本x的干预,他们通过p(r | x)获得表示,以及一批从数据集中随机抽出的腐败图像(corrupted images)。图像的损坏是为了破坏高水平的信息,从而模拟对S特征的干预。
Mao等人[38]提出了一个训练算法(第3.1.1.2节),通过最小化分类损失L_class来学习p(y | x, r),以及一个单独的评估算法来估计因果量p(y | do(x))。分类算法的输出读作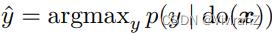
在实验中,作者利用预训练方法,如SimCLR[39]和SWAV[40]来产生R,然后与ERM损失进行比较,在OOD基准,如ImageNet9[41]上进行分类,显示出明显的改进。他们的最佳结果是在彩色MNIST[27]上取得的,在那里他们比IRM(第3.1.2.1节)、RSC[42]和GenInt[35](第3.1.1.1节)有了很大的改进。

3.1.1.3 训练过程中的去中心化模型
Deconfounding models during training
反事实不变性
反事实不变性是一个构建预测器的框架,其预测对X上的某些扰动是不变的[43],使用实践者的规格。为了定义不变性,我们指定了一个额外的变量A,它捕捉了不应该影响预测的信息。然而,A可能会因果地影响协变量X。
作为一个激励性的例子,考虑图3.1中的图像数据集的采样。我们发现,当背景从山脉变成海滩时,我们的分类器似乎无法识别奶牛。在这个例子中,我们将背景识别为A,因为改变背景不应该影响模型的预测,但它确实对协变量X有因果影响。
让Xa(\\epsilon)表示如果A被设定为a,我们会看到的反事实X,其他都固定不变,其中(\\epsilon)捕捉到关于背景因素的信息,如噪音。

这个框架要求从业者确定:i)因果方向X→Y或X←Y,ii)敏感属性A,以及iii)A和Y之间的关联是否是由于数据收集中的混杂或选择偏差。见图3.5的说明。有了这些信息,实践者可以适当地在两个正则器中选择一个,强制执行反事实不变性特征(一个必要但不充分的条件)。在Veitch等人[43]的实施中,这种方法仅限于二进制A,但从概念上讲,这种想法可以通过对A进行适当的调节而扩展到更高维度。 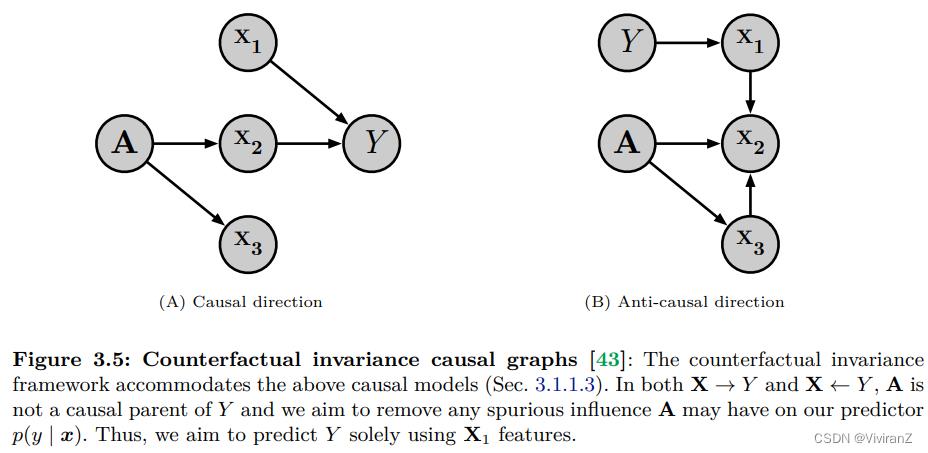
如果A是一个受保护的属性(如性别或种族),我们希望预测者在这方面是公平的,这个定义与定义6.2.1中介绍的反事实公平有关。
不对称性学习
与反事实不变性框架类似,Mouli和Ribeiro[44]提出了不对称学习,用于学习对某些分布转移设置具有反事实不变性的分类器。实践者在数据生成过程中指定了一组模型应具有不变性的等价关系。Mouli和Ribeiro[44]介绍了一种新颖的分布外泛化理论范式,该范式对数据生成过程进行建模,并规定了我们可以泛化到的测试分布类型。不对称性学习将X,Y,所提供的等价关系集合作为输入。
作为一个激励性的例子,考虑[44]中包含的钟摆实验。两个全局属性ρ1(.), ρ2(.)被确定为任何摆锤摆动x,其中一个是系统的初始势能ρ1(.)。然后,他们定义了一个等价关系∼1,这样对于任何两个具有相同初始势能的样本x (1) , x (2) ,ρ1(x (1)) = ρ1(x (2)),我们说x (1) ∼1 x (2)。
每个等价关系∼i诱导出一组保留等价类成员的对象转换Ti。具体来说,对于任何x∈[x]i和任何t∈Ti,我们有t o x∈[x]i。这些转换被视为定义了数据的生成方式,如 。每个T被视为与给定等价关系相关的转换的串联,T = t1 ◦ ... ◦ tr (r为任意值)。T tr和T te之间的差异在转换的子集中被发现,例如我们可能有T^tr = t1 ◦ t_tr ◦ t3和T_te = t1 ◦ t_te ◦ t3。
。每个T被视为与给定等价关系相关的转换的串联,T = t1 ◦ ... ◦ tr (r为任意值)。T tr和T te之间的差异在转换的子集中被发现,例如我们可能有T^tr = t1 ◦ t_tr ◦ t3和T_te = t1 ◦ t_te ◦ t3。
然后,OOD泛化的任务是假设哪些等价关系引起的转换在测试和训练数据之间保持不变,并在预测模型的学习中强制执行不变性。训练数据需要在全局属性中包含足够的变化,以使学习程序能够识别任何不变性。
使用SCD的自监督学习
前面的方法旨在提高一个任务的预测能力,而接下来的方法则是探索如何利用IFL的原理来进行自监督学习(SSL),即通过学习表征来帮助完成一系列的下游任务。这种策略为利用大量的无标签数据铺平了道路,在这种情况下,标签数据的可用性往往是有限的,例如大规模语言建模[45]、医学图像分析[46]或分子特性预测[47]。目前流行的方法大多可以分为重建性[48]或判别性[39, 49, 50]。在鉴别性方法中,我们的目标是在类似对象的表征之间强制执行接近性。
对比性学习是鉴别性体系中的一种方法,它利用正负抽样来加强相似表征的接近性和不同表征之间的较大距离。许多对比性学习方法依赖于某种形式的数据增强,以产生正负样本,以及观察来自不同环境但具有相似标签的数据(例如,多视角对比性学习[51])。
Mitrovic等人[30]认为,对比性预训练方法隐含地假定了图3.2所示的SCD因果结构。在本文中,他们研究了我们可以利用数据增强作为提供正负样本的对比性损失的手段的情况,并提出了目标ReLIC。
传统的数据增强可以被解释为对风格变量S的干预(见因果视角3.1.1)。Mitrovic等人[30]将自我监督学习的任务定为代理任务预测,他们提出了一个代理标签Yt的列表。为了明确执行数据增强下的代理目标预测不变性,他们制定了一个标准,并建议在训练中通过在目标中添加KL-分歧项来执行。利用独立机制原理(定义2.3.4),他们得出结论:在SCD下,对S进行干预不会改变条件分布p(yt | c),即操纵S的值不会影响这个条件分布。因此,p (yt | c)在样式S的变化下是不变的,即对于所有s^ (1) , s^(2) ∈ S,

作为后续工作,Tomasev等人[52]提出ReLICv2,它与ReLIC的区别在于选择适当的正负点集以及如何在目标函数中将产生的数据观点结合起来。
3.1.1.4 训练后预测的去混杂化
3.1.1.4 Deconfounding post-training predictions
很多方法[53, 54, 55]提出在模型训练结束后,通过反事实正则化,从预测中消除未观察到的混杂因素U的影响。这涉及到估计U对预测Y˜的混杂影响,然后将其减去,从而对预测进行去混杂化。对于样本x的预测,x 0被生成,使其不携带x中的因果信息,然后,预测被使用差值去混淆。
Chen等人[53]通过将X设置为零向量(或随机噪声),对X进行干预,识别产生的Yˆ的预测,并实施公式(3.4)。作者提议将其用于轨迹预测的领域泛化。Rao等人[55]提出改善视觉分类的注意机制,Niu等人[54]提出消除视觉问题回答中的语言偏差。

3.1.2 多重环境
通常可以获得从多个环境E收集的数据集,形式为 。例如,数据可能是不同医院之间在不同协议下获得的记录,或在不同季节收集的房屋图像。作为一个更具体的例子,WILDS基准[56]提供了一个来自真实世界场景的多种环境数据的策划集合。
。例如,数据可能是不同医院之间在不同协议下获得的记录,或在不同季节收集的房屋图像。作为一个更具体的例子,WILDS基准[56]提供了一个来自真实世界场景的多种环境数据的策划集合。
由于许多机器学习算法是在iid数据上操作的,从业者可以对从多种环境中收集的数据进行洗牌。Arjovsky等人[27]认为,当我们洗牌时,关于数据生成过程的信息会丢失,而且洗牌后的数据会出现虚假的关联。通过洗牌,我们失去了跨环境和环境内发生的关联之间的任何区别。例如,在图3.1中观察到草地特征和奶牛标签之间的虚假关联,但是如果一个环境是高山牧场,而另一个环境是海滩,这种关联在不同的环境中并不成立。
我们怎样才能有效地使用这些信息呢?从因果关系的角度来看,我们可以把每个环境看作是由一组对SCD中风格变量的干预产生的(图3.2)。每个环境都编码了一套特定的干预措施,而更多的环境可以揭示出更多的风格变量。
本节中的方法建议确定在所有环境中具有预测性的特征,并学习从不变特征到输出变量Y的不变映射。我们将不变特征解释为SCD中的内容特征,或Y的因果父母。
3.1.2.1 不变风险最小化 (IRM)
3.1.2.1 Invariant Risk Minimization
Peters等人[57]介绍了不变因果预测(Invariant Causal Prediction,ICP),这是一种寻找因果特征集的算法,即作为目标变量因果预测因素的最小特征集。他们利用了独立机制原理(定义2.3.4)所给出的不变性属性。
不变风险最小化(IRM)[27]是ICP的一个扩展,它不是选择变量,而是学习没有虚假关联的表示。它假定存在一个特征图Φ,使得最佳线性分类器wˆ : 对每个环境e∈E来说,将这些特征映射到输出的Φ(X)→Y是相同的。特征图和分类器组成了一个预测函数f(x)=w◦Φ(x)。优化被定义为在所有环境中最小化特定环境的经验风险Re :=  。
。
作者认为,这样的函数将只使用不变的特征,因为非不变的特征将与不同环境的标签有不同的关联。我们将此解释为风格和内容分解的一个实例,图3.2,其中Φ(X)代表我们的内容变量C,而S的可变性是在各种环境中观察到的 。

在实践中,这个二层程序是高度非凸的,很难解决。为了找到一个近似的解决方案,作者考虑了一个拉格朗日的形式,即相对于约束条件的次优性表示为每个内部优化问题的梯度的平方准则:

假设内部优化问题是凸的,实现可行性等同于惩罚项等于0。因此,如果我们设定λ=∞,公式(3.5)和公式(3.6)是等同的。
不幸的是,Rosenfeld等人[58]和Kamath等人[59]都表明,IRM的表现往往不比标准经验风险最小化(ERM)好。当潜在的因果关系是线性的,并且在训练环境中观察到足够的异质性,从而有足够的自由度被消除时,IRM达到了最佳效果[58]。然而,如果这些条件中的任何一个没有得到满足,那么IRM就会取得比ERM更差的结果。Ahuja等人[60]将IRM的目标设定为在几个环境中寻找集合博弈的纳什均衡。Ahuja等人[61]指出,虽然类似IRM的方法在线性回归任务中可以证明泛化OOD,但在线性分类任务中却不一定,因为线性分类任务需要以支持度重叠假设的形式对分布偏移进行更强的限制。他们认为,用信息瓶颈[62]约束来增强不变性原则可以解决其中的一些问题。
与IRM类似,Krueger等人[63]提出了风险外推法(REx),这是一种领域概括方法,也使用了比ICP更弱的不变性形式。然而,IRM的具体目标是不变性预测,而REx则寻求对任何形式的分布性转变的稳健性。作者证明,REx的变体可以恢复目标的因果机制,同时也对协变量转移提供一定的稳健性。Wang和Jordan[23]强制要求用于分类的表征满足必要性和充分性概率(PNS)条件。这导致了一个提高黑箱算法通用性的目标函数,他们称之为Causal-Rep。
3.1.2.2 因果匹配
3.1.2.2 Causal Matching
超越IRM的进展是更详细地分析S和C在不同环境中如何相互作用。虽然IRM假设S和C在某些环境中是虚假关联的,但Mahajan等人[64]考虑了一个数据生成过程(DGP),其中S和C被一个对象变量O所混淆,而我们的环境E只是S的因果父本。与IRM不同的是,S和C之间的依赖关系用图3.7的因果图明确地进行建模。

Mahajan等人[64]的贡献是双重的。首先,考虑到在数据中编码为匹配集Ω的对象位置的先验知识,他们提出了一个正则化的目标,使用Ω和一个分类器w_β:\\Phi \\to Y 学习一个表示 。其次,在不事先了解对象位置的情况下,作者提出了一种匹配算法来识别对象位置。然后,估计的匹配集Ω˜被部署到分类器目标中。
。其次,在不事先了解对象位置的情况下,作者提出了一种匹配算法来识别对象位置。然后,估计的匹配集Ω˜被部署到分类器目标中。
具体来说,他们提出,对于具有相同标签但在不同环境中产生的任何两个数据点 ,它们的基本内容特征C应该是相似的。这就促使他们的匹配算法MatchDG在 i)建立一个匹配集和 ii)学习一个表征Φ(X) 之间交替进行。
,它们的基本内容特征C应该是相似的。这就促使他们的匹配算法MatchDG在 i)建立一个匹配集和 ii)学习一个表征Φ(X) 之间交替进行。
3.1.2.3 Style and Content as Latent Variables
3.1.2.3 风格和内容作为潜变量
与学习风格和内容的表征相反,有一组方法将风格和内容建模为潜变量,并在环境e∈E中学习p^e (x, y)_e∈E。这使我们能够在SCD中产生概率风格和内容变量C和S,从而将优化目标从受限目标变为无限制目标。
这些方法通过学习分布p^e(s, c | x)从X中抽取C和S,该分布随环境e∈E的变化而变化。然后他们通过从密度Y∼p(y | c)中取样进行预测,根据独立机制原理(定义2.3.4),该分布对环境变化是不变的。
Sun等人[65]提出了LaCIM,它利用了来自多个环境的训练数据,并假设数据是根据类似的结构(图3.7)产生的,这与第3.1.2.2节中的MatchDG方法类似。然而,LaCIM解决了一个无约束的优化目标。为每个环境e学习一个先验p^e_θ (c, s),以捕捉C和S之间不同的依赖性。
先验模型p_θ(c,s | e)、推理模型p_θ(c,s | x,e)、生成模型p_θ(x | c,s)和预测模型p_θ(y | c)是为每个环境单独学习的,但关键是,p_θ(x | c,s)和p_θ(y | c)的参数是跨环境共享的。因此,因果变量C被确定为使p_θ(y | c)达到低损失。
相比之下,Liu等人[66]只利用了单一环境的训练数据,但假设C⊥S。他们的方法被称为因果语义生成模型(CSG),与LaCIM的操作类似。
Lu等人[67]提议执行与LaCIM相同的任务,但采用三阶段训练程序,而不是LaCIM和CSG的端到端方法。他们的方法被称为iCaRL。在第一阶段,他们学习Z,即X的潜在生成变量集。在第二阶段,他们使用PC算法[68]和条件独立性测试来分离出C⊂Z,即Y的因果父母。在第三阶段,分类器学习p(y | c)。iCaRL在Colored Fashion MNIST [27]OOD分类基准上优于ERM和IRM。
【看到这里感觉有点感悟:各个问题研究的数据集不同(同一环境、不同环境、不同环境混淆、不同环境带标签等),有着不同的假设(有完整模型、spurious connection的变量是独立的、条件独立等),但是有着相同目标:找到稳定的特征(符合因果关系的),细分下来,也有先验知道特征大概样子(因果效应)、直接学习生成特征(因果发现)】
3.1.2.4 组合式识别
3.1.2.4 Compositional Recognition
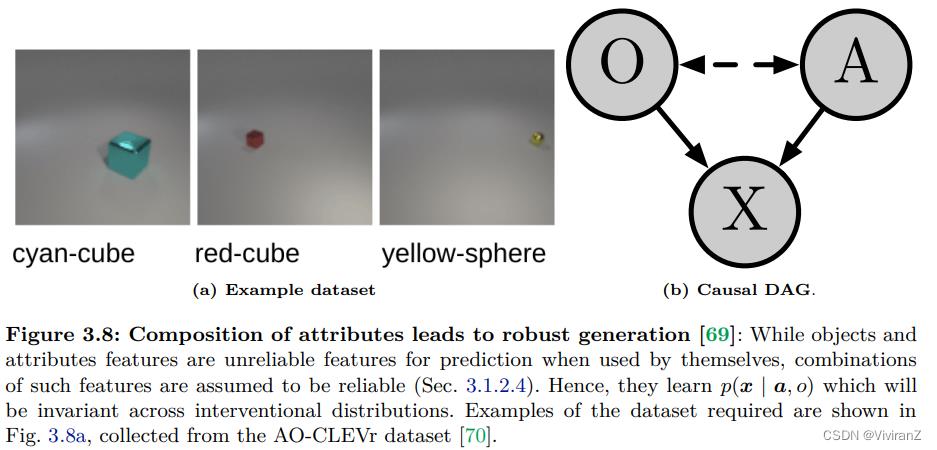
组合式识别是学习识别已知成分的新组合的问题。请注意,这种方法是在具有属性A和物体O标签的数据上进行训练的,而不是前面3.1.2节中的方法所利用的额外环境标签。Atzmon等人[69]认为,深度判别模型在成分识别中失败的原因有两个:(i)分布转移和(ii)表征的纠缠。因此,他们建议构建一个基于因果图的表征,将图像建模为由属性A和物体O引起的,如图3.8所示。与对象或属性本身不同,Atzmon等人[69]认为,对象和属性的组合在训练集和测试集的图像上产生相同的分布。因此,他们建议将未见过的组合的图像视为由属性和对象标签的干预产生的;将零点推理视为寻找哪个干预导致了给定图像的问题。他们学习分布p(x | a, o),假设它在不同环境下比p(x | a)或p(x | o)更稳定。一个分类器可以用模型学到的稳健表征来学习。
3.2 不变机制学习
在上一节中,我们利用了不变特征的效用,从我们的模型中去除虚假的关联。现在我们来看一下不同种类的方法,其目标与不变特征学习有根本的不同。
考虑一下人类如何听到一个人安静地或大声地说话,但可以区分正在说什么和说得多大声。说的是什么可能对应于数据的一个特征,而说话的声音有多大则对应于将信息映射给观察者的机制。这样的观察是通过独立机制原理来解释的(定义2.3.4)。
不变机制学习的目的是确定一套代表不同干预分布的数据生成机制。对于X和Y的独立潜伏混杂因素U,我们认为每个干预分布是由对混杂因素的一个子集的干预产生的【因为我们假设因果变量(稳定变量)一定是不变的】(见图3.9)。然后,对于所学机制的集合F,我们采用映射F的一个子集,以便从X中预测Y。我们强调,没有对混杂因素U进行特征学习。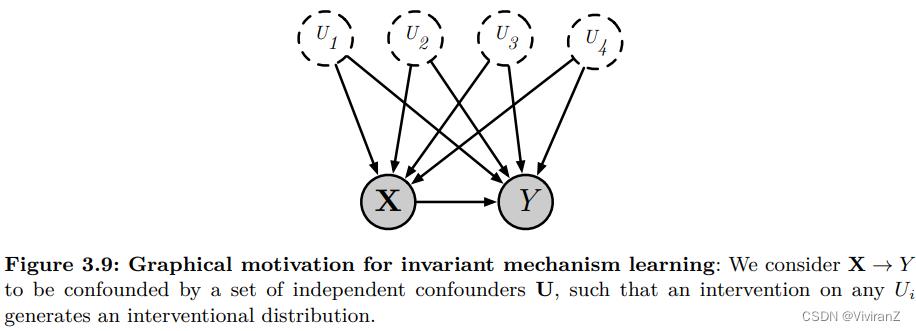

3.2.1 独立不变的机制作为独立的网络
Parascandolo等人[71]提出了一种方法,旨在识别一套相互竞争的数据转换('机制'),这些机制经过训练,在从样本中恢复不同的基本结构方面具有自己的专长。
Goyal等人[72]通过将独立机制应用于连续数据,特别是视频和文本,在之前的工作上有所发展。他们把自己提出的架构称为循环独立机制(RIMs)。在每个时间步骤,一个软注意层(a soft attention layer)从N个竞争机制中选择前k个机制来处理输入,第二个注意层允许在每个时间步骤的机制之间进行 "稀疏的交流",以帮助上下文理解。
与其他顺序结构如LSTM(Hochreiter和Schmidhuber[73])和变换器(Vaswani等[74])相比,观察到的好处是减少了输入中长期休眠的信息退化,并改善了对多个物体的轨迹预测。
Madan等人[75]然后将Goyal等人[72]提出的RIMs用于元学习算法,快速适应模块的参数,缓慢适应注意力机制参数。他们的快速和缓慢的学习动态证明了在元学习基准中比LSTM和RIMs的改进。
【感觉这一部分的意思是首先假设不需要的因素是变化的,干预会造成不同的变量一定是confounder,然后…………???不再找因素、找结论的生成机制??】
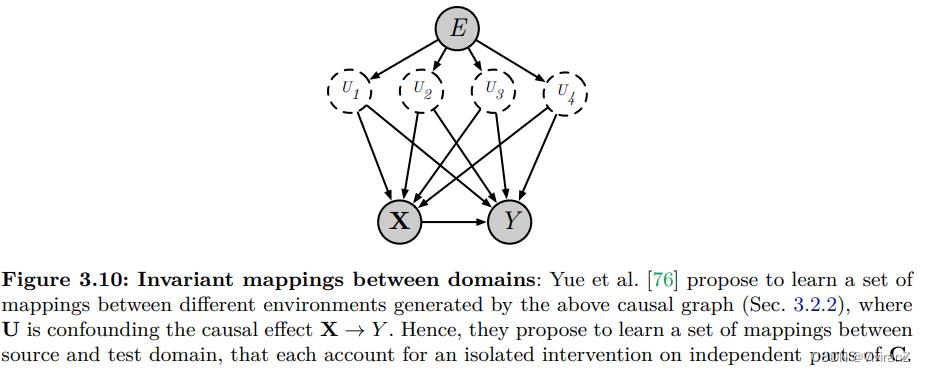
3.2.2 作为域间映射的不变机制
Yue等人[76]提议将用于分类的无监督领域适应性视为推断一组分解的因果机制的问题,这些机制产生了从源领域到测试领域的映射。
他们使用图3.10所示的因果图对数据生成过程(DGP)进行建模。E代表环境指数,U是一组关于X和Y的未观察到的领域意识混杂变量。他们利用可迁移性理论[77]的以下结果:

这一结果表明,当我们能够接触到混杂因素U时,我们可以在一个单独的领域E中确定干预do(X)对Y的影响。考虑到U是不可观察的,作者建议学习一组代理变量Uˆ,并确定领域之间的分解反事实映射,每个映射对应于对Ui的孤立干预,保持所有其他Uj6=i不变。他们以无监督的方式学习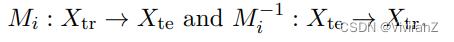
对于测试域中的一个给定输入,他们建议将测试域的输入映射到源域(即如果输入是在源域中产生的,会是什么),然后基于这个反事实的输入进行预测。
与此类似,Teshima等人[78]提议从一组不同领域的独立成分Z中找出一个生成X的不变机制。该方法接收来自多个领域的训练数据,并使用非线性ICA来识别特征Z和一个跨领域的不变映射f:Z→X。他们的估计值ˆf,确定了目标域中的Z值,并生成了模仿目标域的伪样本。一个标准的监督学习算法可以在这个生成的数据上进行训练。
3.3 未解决的问题
3.3.1 缺少有针对性的不变性学习的基准
前面的方法没有以标准化的方式进行评估,因为大多数论文都设计了玩具实验来评估性能。因此,从业者不容易确定最佳方法。
评价OOD泛化的最常见的方法是在训练数据中引入虚假的关联,并在关联发生变化的测试域中评价性能。例如,Arjovsky等人[27]引入了ColoredMNIST基准,为数字添加颜色,改变了测试和训练数据之间颜色和数字标签的关联强度。Wang和Jordan[23]使用ColoredMNIST和CelebA数据集[79]评估了他们的算法,并改变了感兴趣的面部属性和虚假属性之间的关联。例如,训练数据包含了黑发和项链之间的虚假关联。此外,Wang和Jordan[23]提议比较他们模型中的表征的指定维度变化下的泛化能力。
为了提供一个考虑到因果关系的算法的最坏情况评估,Subbaswamy等人[80]提出了一个基于由可变变量指定的分布变化的评估协议。边际分布可能会发生变化,而该指标考虑了对因果后代的影响。给出了最坏情况下的性能估计,这使实践者了解任何模型在他们选择的应用中的可靠性。我们希望看到这样一个框架被更广泛地采用。
3.3.2 不变性学习可能有利于对抗性稳健性/元学习
我们注意到两个与不变性学习类似的活跃的ML研究领域:对抗性稳健性和元学习。我们提出要研究不变性学习如何有利于这些领域,因为它目前还没有被充分探索。
在对抗性鲁棒性方面,我们对学习对对抗性扰动具有鲁棒性的分类器感兴趣。对抗性扰动是一个加性随机变量∆,它使模型不能对X˜=X+∆进行分类,而模型对图像X进行正确分类。当然,我们可以从因果关系的角度来看待AR的问题,并将鲁棒模型解释为对扰动的不变性,我们将在后面的8.2.1.2节中看到。
在元学习中,我们经常寻求学习跨任务的共享结构,以及可以快速适应未见任务的特定任务参数[81, 82, 83]。在这里,我们可以把共享结构解释为跨任务的不变性。未来的工作有必要研究这些来自学习不变性的想法是否可以用来学习更好的任务不变性表征。例如,不以任务变量为条件,而是探索对它们的干预可能是有趣的。
3.3.3 可以利用额外的监督信号进行不变性学习
我们调查了不变性特征学习的方法(第3.1节),这些方法需要标签Y以外的两种不同形式的额外监督:i)内容不变的转换(第3.1.1节),或ii)环境指数(第3.1.2节)。额外的监督信号作为模拟对虚假特征进行干预的手段,这有助于模型避免对虚假关联的任何预测性依赖。在这方面,这些方法对假性特征的干预分布进行建模。
我们提出了未来研究的三个方向。首先,我们可以将这两种形式的干预模拟结合起来,利用数据生成过程的领域知识和从多种环境中收集的数据。一个简单的想法是把数据增强想象成自己产生新的环境,从而利用现有的算法来处理来自多种环境的数据,数据增强技术使可用的环境数量成倍增加。
第二,我们可以尝试利用高维环境信息,而不是环境指数e∈E。例如,为奶牛图像收集的数据集(图3.1)可以附加上每个环境拍摄照片的景观航拍图,作为环境变量,引起数据和标签。Kaddour等人[83]提出了一种元学习方法,它假设了额外的任务描述符,如每个环境一张图片。
第三,我们可以在数据上要求更多的标签,比如在第3.1.2.4节中利用的对象和属性标签。识别和利用其他形式的标签,为不变的特征学习提供信息是一个开放的问题。
这一章前后拖了一个多月终于看完了,其实划分的比较奇怪= =
不变特征学习因果上很好懂,不变机制学习其实把图像数据集认为是一个机制生成的(比如奶牛+牧场--->FIG1,奶牛+牛棚--->FIG2),基于这个假设设立学习目标:学到这个机制。。。。。
挺有意思的,机制这部分差一点 回头可以补充一下
以上是关于论文导读2Causal Machine Learning:A Survey and Open Problems的主要内容,如果未能解决你的问题,请参考以下文章