大数据平台搭建及集群规划
Posted 爱是与世界平行
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据平台搭建及集群规划相关的知识,希望对你有一定的参考价值。
01 如何做大数据集群规划设计
通常,对于给定业务的大数据集群来说,应该如何规划集群才能使硬件资源不浪费?由于成本考量只有少量节点的情况下如何规划集群的主节点和从节点才合理?对于集群的副本数如何设置才比较合适?给定容量的集群到底能存储多少数据?等等,想必这些问题也应该曾经或者目前正在困惑着很多的大数据技术人员或者运维人员,本文将结合笔者在实际工作中的经验简单的对这些问题解析和分享,希望对读者能够有一定的帮助。下面笔者以构建Hadoop和HBase分布式文件系统来说明如何规划集群。
02 从集群性能和运维角度考虑
- 单机配置性能
在进行集群规划时,对于单机机器资源配置主要是从内存、CPU、硬盘、网络等方面进行考虑。通常情况下大数据集群中分为两类节点:主节点和从节点,比如Hadoop中的NameNode就是主节点,而DataNode就是从节点。下面具体说明各种资源在选择时应该考虑哪些关键因素。
对于内存的考量,通常选择比较大的内存节点。**如果是主节点通常情况下对内存的要求更高,需要配置更大的内存,而从节点就没必要像主节点那么大,可能更关注的是磁盘和CPU指标了。**对于小微集群,通常所有的节点可能配置都是一样的,所以可根据实际情形进行选择。
对于CPU的考量,不同的节点可以根据要求而不同的,**比如对于主节点可以选择2路32核或者更高性能的CPU,而从节点可以适当降低一些要求,选择2路16核的CPU。**如果集群规模比较小,所有的节点配置完全相同。
对于磁盘的考量,通常情况下会按照集群的总体规模进行规划。**对于从节点来说,安装的都是数据存储节点或者计算节点,往往都选择比较大的磁盘,比如由多块2T或者4T组成的20T或40T的磁盘。而对于主节点来说,通常安装的都是主节点需要的是内存,对磁盘的要求比较低,不过如果同时也安装了从节点磁盘也需要配置比较大的磁盘。**但有一点,为了保证负载均衡和集群性能,所有从节点的磁盘空间配置要尽量保持一致。
对于网络的考量,通常对于大数据平台往往数据量都是非常巨大的,网络的吞吐率要求也比较高,所以在条件允许的情况下都选择万兆网。
- 应用分布规划
从集群的系统性能方面考虑,希望集群的整体性能尽可能比较高,资源使用率尽可能大,而从运营维护角度考虑,当集群某个节点出现故障时希望对集群的可用性、稳定性等方面的影响尽可能小,下面我们以通常情况下按照如下分配所有的应用程序。
对于小微集群来说,集群节点个数往往比较少(有时可能只有几台服务器),这样多个节点需要进行共享。如果集群的节点个数少于5个,我们以4个节点的集群、HA模式为例,可以按照如下进行应用分布设计:
Node01: NN、RM、HM
Node02: NN、RM、HM、JN、ZK
Node03: DN、NM、RS、JN、ZK
Node04: DN、NM、RS、JN、ZK
对于如上的集群配置,这样的集群抗风险和容错能力比较差,集群的扩展能力也方便,当有节点发生故障需要机器下线操作起来也不方便,所以仅适合于做开发环境或者实时性要求比较低的批处理集群。
对于节点数大于等于5个节点时,集群就可以按照如下进行分布设计:
Node01: NN、RM、HM
Node02: NN、RM、HM
Node03: JN、ZK、DN、NM、RS
Node04: JN、ZK、DN、NM、RS
Node05: JN、ZK、DN、NM、RS
Node06: DN、NM、RS
Node07: DN、NM、RS
…
NodeNN: DN、NM、RS
对于这样的集群随着业务规模的扩展,我们随时可以很方便的将Node03、Node04、Node05上的DN、NM、RS都下线,使集群的分布变更为:
Node01: NN、RM、HM
Node02: NN、RM、HM
Node03: JN、ZK
Node04: JN、ZK
Node05: JN、ZK
Node06: DN、NM、RS
Node07: DN、NM、RS
…
NodeNN: DN、NM、RS
上述中的简写名称分别代表:NN代表NameNode,RM代表ResourceManager,HM代表HMaster,DN代表DataNode,JN代表JournalNode,ZK代表Zookeeper,NM代表NodeManager,RS代表RegionServer。
03 从存储容量角度规划考虑
在进行集群规划时同时还需要从存储容量角度考虑,可以按照如下四个方面进行规划:
- 数据范围
在实际业务中,对于任何一个企业其业务条线都会有其自己的业务增长趋势,这样随着业务规模的增长企业数据量也会不断增长,所以我们在规划集群时可以按照短期业务(1~2年)、中长期(3~5年)业务增长进行规划,而不是在集群初始化时一次性导入的初始数据量。
比如:我们假设企业的客户量x,所有客户产生的所有业务数据量为y,在构建集群时的初始数据量为c,那么可能的一种企业数据量增长模型为
y = af(x) + bg(x) + c
其中,在大部分企业中如果客户量增加一个量级dx,那么其所对应的日志和订单业务数据量可能是客户量的线性模型f(x),而对于交易类业务的数据量可能是客户量的非线性增长模型g(x),比如笛卡尔积模型。
所以不能通过简单的节点动态增加来调整集群规模和存储计算能力,最好还是通过构建短期业务和中长期业务增长趋势模型来规划集群。
- 数据分级
在现实企业中,对于不同业务条线的数据具有不同的安全等级,比如对于金融企业交易数据具有较高的安全等级,对于电商企业订单数据可能具有较高的安全等级。同时廉价的商用服务器出现故障也更容易,这样可以通过多副本策略进行存储,保障数据的安全。所以在实际业务中我们可以按照业务数据的安全等级进行数据分级划分,这样在进行数据存储时高安全等级数据可以存储更多副本的数据,而低安全等级数据可以少存储一些副本,这样就可以根据数据的安全等级划分,一来保障数据的安全,二来可以节约大量的存储空间。
- 数据格式
数据格式也是会影响存储空间和性能的一个考量指标。对于实际的企业数据,通常会有JSon、CSV、Parquet、ORC、DAT等格式的数据,我们以实际使用中对Json、Csv、Parquet三种类型的业务数据进行分析测试,得出如下的结论:
1)对于相同的数据集使用三种格式进行存储,对空间的使用比例接近2:1:0.3左右;
2)我们以一个2亿条记录的二维表、HDFS文件系统中3个副本结构为例,如果使用Json格式存储该数据集会占用200G空间,那么使用Csv格式存储大约会占用100G空间,而使用Parquet格式存储大约会占用30G空间;
3)其中的Parquet格式占用会有部分偏差,因为Parquet底层使用的数据压缩算法,对于不同数据分布列会有不同的压缩比,比如对于均匀分布列、枚举值列、长尾分布列等压缩比例会有不同,但对于实际的业务数据,总体上Parquet的压缩还是比较不错的。
所以在对集群进行使用时建议尽量使用Parquet等这类压缩性能比较高的格式进行存储,这样会节省大量的空间。
- 数据功能
对于集群中产生的数据可以按照业务中间数据、临时数据、集群的系统日志、集群的预留空间安全系数等来进行规划。业务中间数据和临时数据会分配一定的空间比例,对于集群的预留空间安全系数可以按照当集群的总体规模使用达到80%就需要进行横向扩容,等等。
笔者曾经在实践中遇到过如下情形,原始的业务数据大概有15T左右,通过多副本存储策略、数据处理过程中产生的大量中间和临时数据、再加上集群需要有预留空间的安全系数等,当时整个集群120T的总空间尽然都不够用,也就是说现实中的业务数据在使用中总体上可能会膨胀好多倍。
04 大数据平台的硬件规划、网络调优、架构设计、节点规划
4.1 大数据平台硬件选型
要对 Hadoop 大数据平台进行硬件选型,首先需要了解 Hadoop 的运行架构以及每个角色的功能。在一个典型的 Hadoop 架构中,通常有 5 个角色,分别是 NameNode、Standby NameNode、ResourceManager、NodeManager、DataNode 以及外围机。
其中 NameNode 负责协调集群上的数据存储,Standby NameNode 属于 NameNode 的热备份,ResourceManager 负责协调计算分析,这三者属于管理角色,一般部署在独立的服务器上。
而 NodeManager 和 DataNode 角色主要用于计算和存储,为了获得更好的性能,通常将 NodeManager 和 DataNode 部署在一起。
4.1.1 对 NameNode、ResourceManager 及其 Standby NameNode 节点硬件配置
由于角色的不同,以及部署位置的差别,对硬件的需求也不相同,推荐对 NameNode、ResourceManager 及其 Standby NameNode 节点选择统一的硬件配置,基础配置推荐如下表所示:
| 硬件 | 配置 |
|---|---|
| CPU | 推荐 2 路 8 核、2 路 10 核或 2 路 12 核等,主频至少 2~2.5GHz |
| 内存 | 推荐 64~256GB |
| 磁盘 | 分为 2 组,即系统盘和数据盘,系统盘 2T*2,做 raid1;数据盘 2-4T 左右,数据盘的数量取决于你想冗余备份元数据的份数 |
| 网卡 | 万兆网卡(光纤卡) |
| 电源 | 均配置冗余电源 |
对于 CPU,可根据资金预算,选择 8 核、10 核或者 12 核。
对于内存,常用的计算公式是集群中 100 万个块(HDFS blocks)对应 NameNode 需要 1GB 内存,如果你的集群规模在 100 台以内,NameNode 服务器的内存配置一般选择 128GB 即可。
由于 NameNode 以及 Standby NameNode 两个节点需要存储 HDFS 的元数据,所以需要配置数据盘,数据盘建议至少配置 4 块,每两块做 raid1,做两组 raid1;然后将元数据分别镜像存储到这两个 raid1 磁盘组中。而对于 ResourceManager,由于不需要存储重要数据,因而,数据盘可不配置。
网络方面,为了不让网络传输成为瓶颈,建议配备光纤接口网卡,节点之间带宽要保证在 10GB左右。
最后,主机电源推荐都是用双电源,虽然有一些费电,但可保证这些重要节点的稳定性,不至于出现电源故障直接宕机的情况。
4.1.2 对 NodeManager、DataNode 节点服务器硬件配置
下面再说下企业通用和主流的 NodeManager、DataNode 节点服务器硬件配置,如下表所示:
| 硬件 | 配置 |
|---|---|
| CPU | 推荐 2 路 10 核、2 路 12 核或 2 路 14 核等,主频至少 2~2.5GHz |
| 内存 | 推荐 64~512GB |
| 磁盘 | 分为 2 组,系统盘和数据盘,系统盘 2T*2,做 raid1;数据盘 4~8T 左右,数据盘单盘使用,无须做 raid |
| 网卡 | 万兆网卡(光纤卡),存储越多,网络吞吐就要求越高 |
| 电源 | 最好配置冗余电源,如预算不足,也可使用单电源 |
由于 NodeManager、DataNode 主要用于计算和存储,所以对 CPU 性能要求会比较高,推荐 2 路 14 核。
内存方面,如果分布式计算中涉及 Spark、HBase 组件,那么建议配置大内存,每个节点 256GB 内存是个不错的配置。
磁盘方面,DataNode 节点主要用来存储数据,所以需要配置大量磁盘,磁盘单盘使用,无须做 raid,磁盘大小推荐每块 8T。不建议使用更大的单盘,当然如果有条件,也可采购 SSD 磁盘,但是 SSD 磁盘成本太高,需要根据预算来定。
每个 DataNode 建议配置 8 ~ 10 块硬盘,具体数量,需要根据总共需要的存储空间而定。例如,假设总共需要存储 800TB 的数据,HDFS 的块副本数为 3,如果每个 DataNode 配置 10 块 8T 的硬盘,那么,采购 30 台 DataNode 服务器即可。NodeManager 节点也会存储一些分析任务的中间结果以及日志等临时数据,建议这些数据的存储路径和 HDFS 的数据存储路径分开,单独规划 3~5 块 4~8T 磁盘来存储这些临时数据即可,同理,这些磁盘也无须做 raid,单盘使用即可。
在网络方面,也建议 NodeManager 和 DataNode 采购光纤接口网卡,所有 NodeManager、DataNode 节点连接到光纤交换机,保证节点之间 10GB 高速网络传输。
最后,在电源方面,可根据预算,决定是否采购双电源,在集群模式下,NodeManager 或 DataNode 某个节点故障对 Hadoop 影响不大,所以使用单电源也是可行的。
4.2 大数据平台网络架构设计
4.2.1 Hadoop 基础网络架构
普通的 Hadoop 网络一般由两层结构组成:接入交换机和汇聚交换机(或者核心交换机),在具体布线上采用 TOR 方式,在一个 42U 的标准服务器机柜的最上面安装接入交换机,每个服务器的光纤网口都接入到机柜上部的光交换机上,这个接入交换机再通过光纤,接入到网络机柜的汇聚或核心交换机上。
基本架构如下图所示:

在上图中,列出了三个机柜,在每个机柜上有两个 10GE 的 TOR 交换机,这两个交换机为主、备模式,然后这些主、被交换机在通过光纤接入到上层的 100GE 汇聚交换机上。这种部署默认可以最大限度地保证网络的传输质量和稳定性。
在每个机柜中都可部署相应的 Hadoop 服务,可以看出,机柜 1 和 2 分别部署了 NameNode 的主、被节点,这两个主、备节点分开部署到不同的机柜,可以最大限度保证 NameNode 的可靠性,不建议将主、备节点部署到同一个机柜中,因为如果某个机柜发生故障(电源故障、网络故障),那么主、备将失去存在的意义。
同理,ResourceManager 节点也部署了主、备的 HA 功能,这两个节点也不能在一个机柜中,这是一个基本常识。此外,在每个机柜中,都分布着 NodeManager 和 DataNode 节点,并且这两个服务是部署在一起的。
此外,在三个机柜中,还有 Hadoop gateway 节点,这些节点相当于用户与 Hadoop 的交互接口,通过这些节点提交任务到 Hadoop 集群中,通常这些节点也可以有多个,建议分布在多个机柜中。
4.3 大数据平台架构设计要点
在构建大数据平台之前,首先要考虑需要的存储容量、计算能力、是否有实时分析的需求、数据的存储周期等因素,然后再根据这些需求进行平台的架构设计。
同时,还要考虑平台的健壮性,例如,任意一个节点宕机都不会影响平台的正常使用,任何一个磁盘的损坏都不会导致数据丢失等。
针对 Hadoop 大数据平台的基础架构,最基本的要求是保证 NameNode、ResourceManager 这些管理节点的高可用性,因此这些节点必须要做 HA。
此外,为了保障 HDFS 数据的安全性,对 Hadoop 块存储一定要设置合适的副本数。例如,设置 3 个副本,那么集群中任意 2 个 datanode 节点故障宕机,都不会丢失数据。
在网络方面,建议每个节点的服务器采用双网卡绑定,网络设置为冗余模式,并和交换机做冗余绑定,做到单个网卡故障或者单个交换机故障,都能保证此节点网络正常运行。
下面是一个典型的 Hadoop 大数据平台部署拓扑,如下图所示:
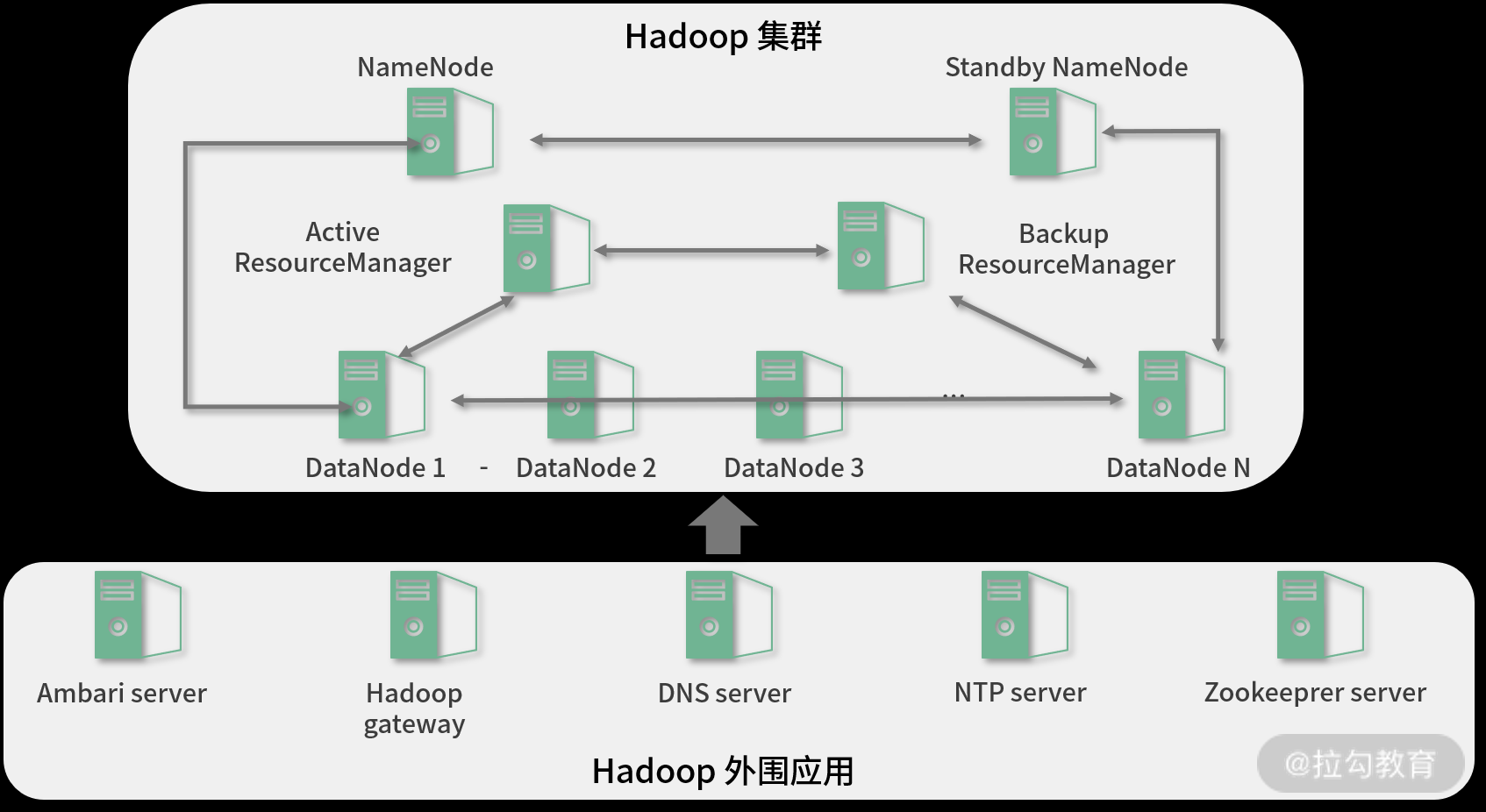
从图中可以看出,NameNode、ResourceManager 节点都部署了高可用功能,任何一个节点故障都不会影响集群的存储和计算。此外,DataNode 节点可根据存储周期、存储容量、计算任务数进行扩容和缩容,并且扩容、缩容可在线直接进行,不影响集群运行。
此外,在 Hadoop 集群之外,还要跟 Hadoop 配合的一些外围应用,例如 ambari,用来自动化运维、监控 Hadoop 集群,Hadoop gateway 用于和 Hadoop 集群的交互接口,而 DNS server 和 NTP server 主要用于 Hadoop 集群内部的主机名解析与时间同步。Zookeeper Server 用于 Hadoop 集群中的仲裁和协调调度。
4.4 大数据平台存储、计算节点规划
对大数据平台存储和计算资源的规划,需要根据实际应用需求判断,例如,现有的和日增长的数据量、数据的存储周期、每天计算任务的中间结果数据量,以及数据冗余空间,比如保持几个副本等实际应用需求。
我以一个实际案例举例说明:目前有数据量 500TB,每天数据量增长 2T 左右,数据块副本为 3,所有数据存储周期为 2 年,根据这个需求,就可以算出需要的存储节点数。
-
2 年数据量需要的存储空间:(23)(365*2)=4380TB
-
总共需要的存储空间:4380TB+(500*3)TB=5880TB
如果以一个存储节点 12 块 4T 硬盘来计算,则需要约(5880TB/48TB=147)123 个存储节点;而如果采用一个存储节点 10 块 8T 硬盘来计算,需要约(5880TB/80TB=147)74 个存储节点即可。
那么此时如何选择每个节点硬盘的大小呢?这就要看大数据平台需要的计算资源有多少了,很显然,按照 4T 硬盘 12 块来规划的话,可获得更多的计算资源(CPU、内存),但此方案需要采购 123 台服务器,成本较高;反之,如果采用 10块 8T 硬盘来规划的话,那么只需要 74 台服务器即可,此时可计算 74 台服务器是否能满足计算资源的要求,如果能满足,那么这个磁盘规划就是最合适的。
对于计算资源规划,要看都运行哪些应用,如果是 Spark、HBase、ElasticSearch 这类吃内存的大数据组件,那么建议计算节点所选的服务器的内存一定要大,最好 64GB 起,能有 128GB 更好。由于前期对计算资源需求很难评估,所以可根据上面这个原则去配置 CPU 和内存即可,如果遇到计算性能瓶颈,可以在后期进行水平扩展,非常方便。
大数据平台对硬件的规划原则: 如果能够确切地知道存储和计算的资源需要,那么就按照这个需求来配置即可;但如果无法准确地评估出存储和计算资源需求量,那么一定要留下可扩展的余地,比如留下足够的机柜位置、网络接口、磁盘接口等。在实际应用中,存储容量一般很好预估,但计算资源很难预估,因此留下足够的扩展接口,是必须要考虑的一个问题。
5 集群规划
5.1 非高可用集群规划
| 软件名 | 服务名 | hadoop100 | hadoop101 | hadoop102 |
|---|---|---|---|---|
| Hadoop(HDFS) | DataNode | 1 | 1 | 1 |
| Hadoop(HDFS) | NameNode | 1 | ||
| Hadoop(HDFS) | SecondaryNameNode | 1 | ||
| Hadoop(YARN) | ResourceManager | 1 | ||
| Hadoop(YARN) | NodeManager | 1 | 1 | 1 |
| ZooKeeper | QuorumPeerMain | 1 | 1 | 1 |
| mysql | 1 | |||
| HIVE | 1 | |||
| Spark | 1 | |||
| Kafka | Kafka | 1 | 1 | 1 |
| Flume | 1 | 1 | 1 | |
| Sqoop | 1 | |||
| HBase | HMaster | 1 | ||
| HBase | HRegionServer | 1 | 1 | 1 |
| Solr | jar | 1 | 1 | 1 |
| Atlas | Atlas | 1 |
5.2 高可用集群规划
| 软件名 | 服务名 | hadoop100 | hadoop101 | hadoop102 |
|---|---|---|---|---|
| Hadoop(HDFS) | DataNode | 1 | 1 | 1 |
| Hadoop(HDFS) | NameNode | 1 | 1 | |
| Hadoop(ZKFC) | DFSZKFailoverController | 1 | 1 | |
| Hadoop(HDFS) | JournalNode | 1 | 1 | 1 |
| Hadoop(YARN) | ResourceManager | 1 | 1 | |
| Hadoop(YARN) | NodeManager | 1 | 1 | 1 |
| ZooKeeper | QuorumPeerMain | 1 | 1 | 1 |
| MySQL | 1 | |||
| HIVE | 1 | |||
| Spark | 1 | |||
| Kafka | Kafka | 1 | 1 | 1 |
| Flume | 1 | 1 | 1 | |
| Sqoop | 1 | |||
| Solr | jar | 1 | 1 | 1 |
| Atlas | Atlas | 1 |
5.3 框架版本
| 名称 | 版本 | 下载地址 |
|---|---|---|
| CentOS | 7-5 | |
| JDK | 1.8 | 同下面HIVE |
| Hadoop | 3.1.3 | 同下面HIVE |
| HIVE | 3.1.2 | https://download.csdn.net/download/Yellow_python/13782524 |
| MySQL | 5.7.32 | https://dev.mysql.com/downloads/mysql/ |
| MySQL的JDBC | 5.1.49 | https://dev.mysql.com/downloads/connector/j/ |
| ZooKeeper | 3.5.7 | http://archive.apache.org/dist/ |
| Spark | 3.0.0 | 同上ZooKeeper |
| Kafka | 2.7.0 | 同上ZooKeeper |
| Flume | 1.9 | 同上ZooKeeper |
| Sqoop | 1.4.7 | 同上ZooKeeper |
| Scala | 2.12.13 | https://www.scala-lang.org/download/ |
| HBase | 2.4.9 | |
| Atlas | 2.1.0 | https://download.csdn.net/download/Yellow_python/79106345 |
| Solr | 7.7.3 |
以上是关于大数据平台搭建及集群规划的主要内容,如果未能解决你的问题,请参考以下文章