初识Apache Flink - 数据流上的有状态计算
Posted 王小雷-多面手
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初识Apache Flink - 数据流上的有状态计算相关的知识,希望对你有一定的参考价值。
初识Apache Flink - 数据流上的有状态计算
| 做大数据实时(流)计算就应该学习Flink。
初识Flink
 https://www.bilibili.com/video/av66770569/
https://www.bilibili.com/video/av66770569/
点击播放视频
| 什么是Flink?
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
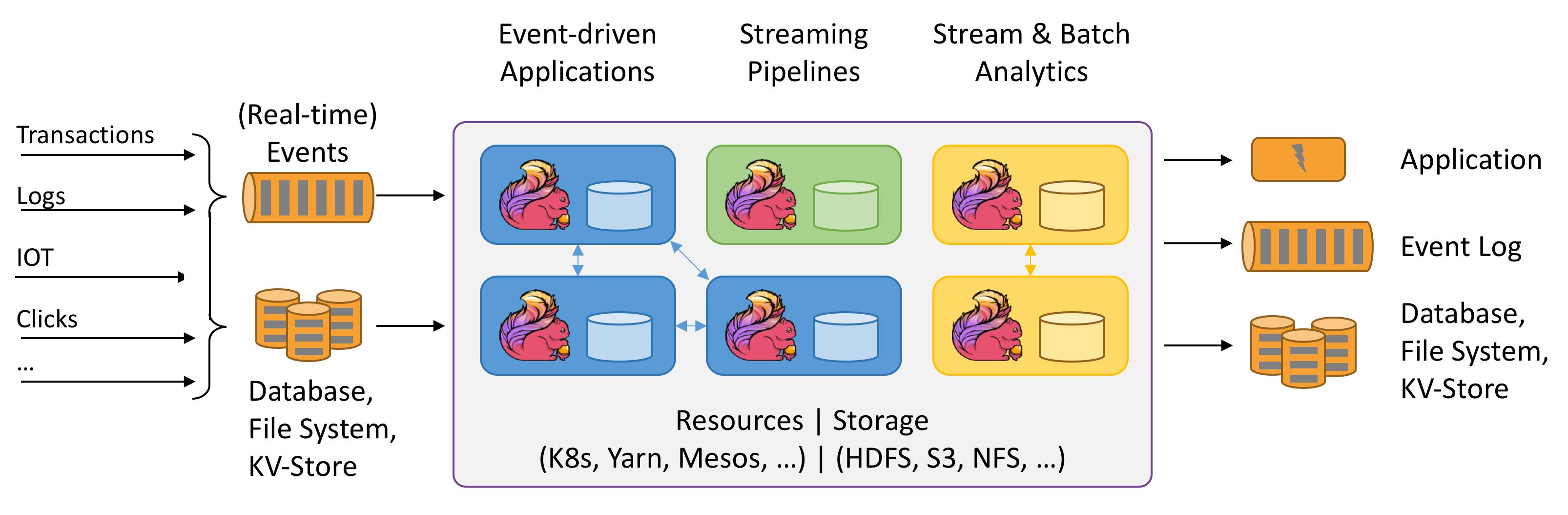
| 所有流式场景
- 事件驱动应用
- 流批分析
- 数据管道 & ETL
| 正确性保证
- Exactly-once 状态一致性
- 事件时间处理
- 成熟的迟到数据处理
| 分层 API
- SQL on Stream & Batch Data
- DataStream API & DataSet API
- ProcessFunction (Time & State)
| 聚焦运维
- 灵活部署
- 高可用
- 保存点
| 大规模计算
- 水平扩展架构
- 支持超大状态
- 增量检查点机制
| 性能卓越
- 低延迟
- 高吞吐
- 内存计算
扫码关注
【从入门到精通】系列

(微信扫一扫,关注该公众号)
以上是关于初识Apache Flink - 数据流上的有状态计算的主要内容,如果未能解决你的问题,请参考以下文章