TiFlash 源码阅读TiFlash 中常用算子的设计与实现
Posted TiDB_PingCAP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TiFlash 源码阅读TiFlash 中常用算子的设计与实现相关的知识,希望对你有一定的参考价值。
本文主要介绍了数据库系统中常用的算子 Join 和 Aggregation 在 TiFlash 中的执行情况,包括查询计划生成、编译阶段与执行阶段,以期望读者对 TiFlash 的算子有初步的了解。
视频
https://www.bilibili.com/video/BV1tt4y1875T
算子概要
在阅读本文之前,推荐阅读本系列的前作:计算层 overview,以对 TiFlash 计算层、MPP 框架有一定了解。
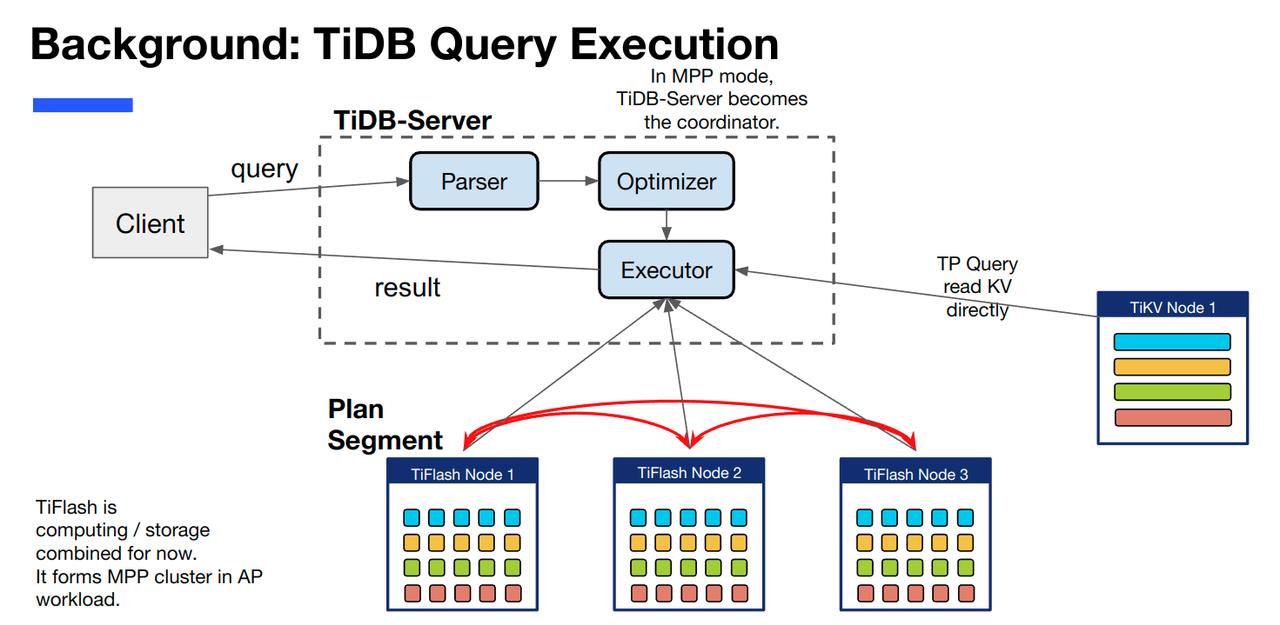
在数据库系统中,算子是执行 SQL 主要逻辑的地方。一条 SQL 会被 parser 解析为一棵算子树(查询计划),然后经过 optimizer 的优化,再交给对应的 executor 执行,如下图所示。
本文的主要内容包括
- TiDB 如何生成与优化 MPP 算子与查询计划
- Join 算子在 TiFlash 中的编译(编译指的是将 TiDB-server 下发的执行计划片段生成可执行结构的过程,下同)与执行
- Aggregation 算子在 TiFlash 中的编译与执行
构建查询计划
一些背景知识:
- 逻辑计划与物理计划:可以简单理解为逻辑计划是指算子要做什么,物理计划是指算子怎样去做这件事。比如,“将数据从表 a 和表 b 中读取出来,然后做 join”描述的是逻辑计划;而“在 TiFlash 中做 shuffle hash join” 描述的是物理计划。更多信息可以参阅:TiDB 源码阅读系列文章
- MPP:大规模并行计算,一般用来描述节点间可以交换数据的并行计算,在当前版本(6.1.0,下同)的 TiDB 中,MPP 运算都发生在 TiFlash 节点上。推荐观看:源码解读 - TiFlash 计算层 overview。MPP 是物理计划级别的概念。
MPP 计划
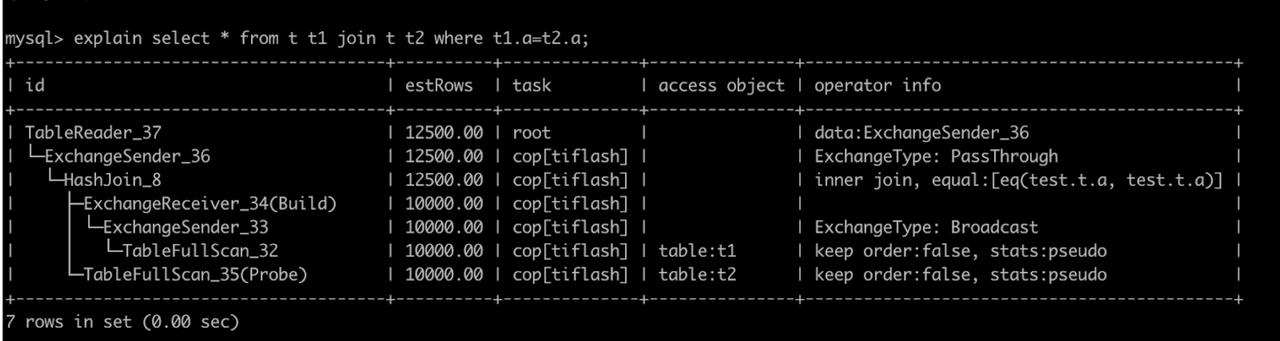
在 TiDB 中,可以在 SQL 前加上 explain 来查看这条 SQL 的查询计划,如下图所示,是一棵由物理算子组成的树,可以查看 TiDB 执行计划概览 来对其有更多的了解。

MPP 查询计划的独特之处在于查询计划中多出了用于进行数据交换的 ExchangeSender 和 ExchangeReceiver 算子。
执行计划中会有这样的 pattern,代表将会在此处进行数据传输与交换。
...
|_ExchangeReceiver_xx
|_ ExchangeSender_xx
…
每个 ExchangeSender 都会有一个 ExchangeType,来标识本次数据传输的类别,包括:
- HashPartition,将数据按 Hash 值进行分区之后分发到上游节点。
- Broadcast,将自身数据拷贝若干份,广播到所有上游节点中。
- PassThrough,将自己的数据全部传给一个指定节点,此时接收方可以是 TiFlash 节点(ExchangeReceiver);也可以是 TiDB-server 节点(TableReader),代表 MPP 运算完毕,向 TiDB-server 返回数据。
在上面的查询计划图中,一共有三个 ExchangeSender,id 分别是 19, 13 和 17。其中 ExchangeSender_13 和 ExchangeSender_17 都是将读入后的数据按哈希值 shuffle 到所有节点中,以便进行 join,而 ExchangeSender_19 则是将 join 完成后的数据返回到 TiDB-server 节点中。
添加 Exchange
在优化器的计划探索过程中,会有两处为查询计划树插入 Exchange 算子:
- 一个是 MPP 计划在探索完毕后,接入 TiDB 的 tableReader 时。类型为 passThrough type. 源码在函数
func (t *mppTask) convertToRootTaskImpl中 - 一个是 MPP 计划在探索过程中,发现当前算子的 property(这里主要指分区属性)不满足上层要求时。例如上层要求需要按 a 列的 hash 值分区,但是下层算子不能满足这个要求,就会插入一组 Exchange.
func (t *mppTask) enforceExchanger(prop *property.PhysicalProperty) *mppTask
if !t.needEnforceExchanger(prop)
return t
return t.copy().(*mppTask).enforceExchangerImpl(prop)
// t.partTp 表示当前算子已有的 partition type,prop 表示父算子要求的 partition type
func (t *mppTask) needEnforceExchanger(prop *property.PhysicalProperty) bool
switch prop.MPPPartitionTp
case property.AnyType:
return false
case property.BroadcastType:
return true
case property.SinglePartitionType:
return t.partTp != property.SinglePartitionType
default:
if t.partTp != property.HashType
return true
if len(prop.MPPPartitionCols) != len(t.hashCols)
return true
for i, col := range prop.MPPPartitionCols
if !col.Equal(t.hashCols[i])
return true
return false
Property 对于分区属性的要求(MPPPartitionTp)有以下几种:
- AnyType,对下层算子没有要求,所以并不需要添加 exchange;
- BroadcastType,用于 broadcast join,要求下层节点复制数据并广播到所有节点中,此时一定需要添加一个 broadcast exchange;
- SinglePartitionType,要求下层节点将数据汇总到同一台节点中,此时如果已经在同一台节点上,则不用再进行 exchange。
- HashType,要求下层节点按特定列的哈希值进行分区,如果已经按要求分好区了,则不用再进行 exchange.
在优化器的生成查询计划的探索中,每个算子都会对下层有 property 要求,同时也需要满足上层传下来的 property;当上下两层的 property 无法匹配时,就插入一个 exchange 算子交换数据。依靠这些 property,可以不重不漏的插入 exchange 算子。
MPP 算法
是否选择 MPP 算法是在 TiDB 优化器生成物理计划时决定,即 CBO(Cost-Based Optimization) 阶段。优化器会遍历所有可选择的计划路径,包括含有 MPP 算法的计划与不含有 MPP 算法的计划,估计它们的代价,并选择其中总代价最小的一个查询计划。
对于当前的 TiDB repo 代码,有四个位置可以触发 MPP 计划的生成,分别对应于 join、agg、window function、projection 四个算子:
- func (p *LogicalJoin) tryToGetMppHashJoin
- func (la *LogicalAggregation) tryToGetMppHashAggs
- func (lw *LogicalWindow) tryToGetMppWindows
- func (p *LogicalProjection) exhaustPhysicalPlans
这里只描述具有代表性的 join 和 agg 算子,其他算子同理。
Join
当前 TiDB 支持两种 MPP Join 算法,分别是:
- Shuffle Hash Join,将两张表的数据各自按 hash key 分区后 shuffle 到各个节点上,然后做 hash join,如上一节中举出的查询计划图所示。
- Broadcast Join,将小表广播到大表所在的每个节点,然后做 hash join,如下图所示。
tryToGetMppHashJoin 函数在构建 join 算子时给出了对子算子的 property 要求:
if useBCJ // broadcastJoin
…
childrenProps[buildside] = MPPPartitionTp: BroadcastType
childrenProps[1-buildside] = MPPPartitionTp: AnyType
…
else // shuffle hash join
…
childrenProps[0] = MPPPartitionTp: HashType, key: leftKeys
childrenProps[1] = MPPPartitionTp: HashType, key: rightKeys
…
如代码所示,broadcast join 要求 buildside(这里指要广播的小表)具有一个 BroadcastType 的 property,对大表侧则没有要求。而 shuffle hash join 则要求两侧都具有 HashType 的分区属性,分区列分别是 left keys 和 right keys。
Aggregation
当前 tryToGetMppHashAggs 可能生成三种 MPP Aggregation 计划:
1.“一阶段 agg”,要求数据先按 group by key 分区,然后再进行聚合。

2.“两阶段 agg”,首先在本地节点进行第一阶段聚合,然后按 group by key 分区,再进行一次聚合(用 sum 汇总结果)。
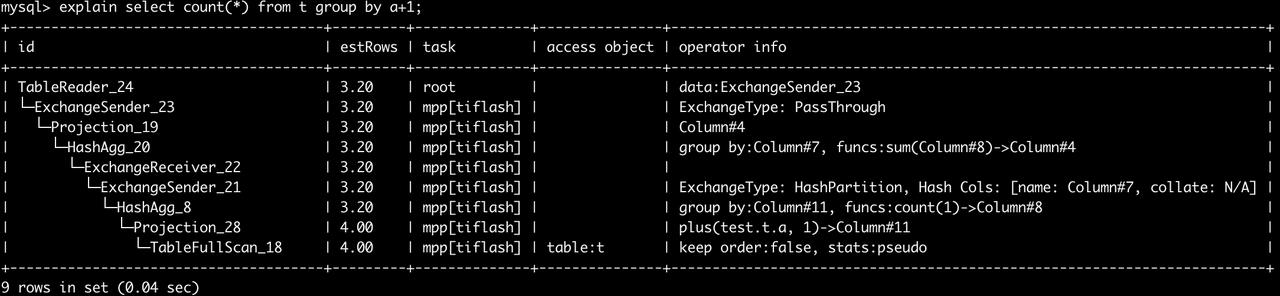
3.“scalar agg”,没有分区列的特定情况,在本地节点进行第一阶段聚合,然后汇总到同一台节点上完成第二阶段聚合。
一阶段 agg 和两阶段 agg 的区别是是否先在本地节点做一次预聚合,优化器会根据 SQL 与代价估算来选择执行哪种方式。对于重复值很多的情况,两阶段 agg 可以在网络传输前减少很多数据量,从而减少大量的网络消耗;而如果重复值很少的情况下,这次预聚合并不会减少很多数据量,反而白白增大了 cpu 与内存消耗,此时就不如使用一阶段 agg。
这里留一个小思考题,这三种 agg 各自对下方有什么 property 要求?在聚合做完之后又满足了怎样的 property?
答案是:
一阶段 agg 要求 hash,做完满足 hash;二阶段 agg 无要求,做完满足 hash;scalar agg 无要求,做完满足 singlePartition.
编译与执行
执行计划构建好之后,TiDB-server 会将 dag(执行计划的片段)下发给对应的 TiFlash 节点。在 TiFlash 节点中,需要首先解析这些执行计划,这个过程我们称作“编译”,编译的结果是 BlockInputStream,它是 TiFlash 中的可执行结构;而最后一步就是在 TiFlash 中执行这些 BlockInputStream.
下图是一个 BlockInputStream DAG 的例子,每个 BlockInputStream 都有三个方法:readPrefix, read 和 readSuffix;类似于其他火山模型调用 open、next 和 close。
下图的来源是 TiFlash 执行器线程模型 - 知乎专栏 (zhihu.com),关于执行模型更多的内容,可以参考这篇文章或者 TiFlash Overview,这里不再赘述。

Join 的编译与执行
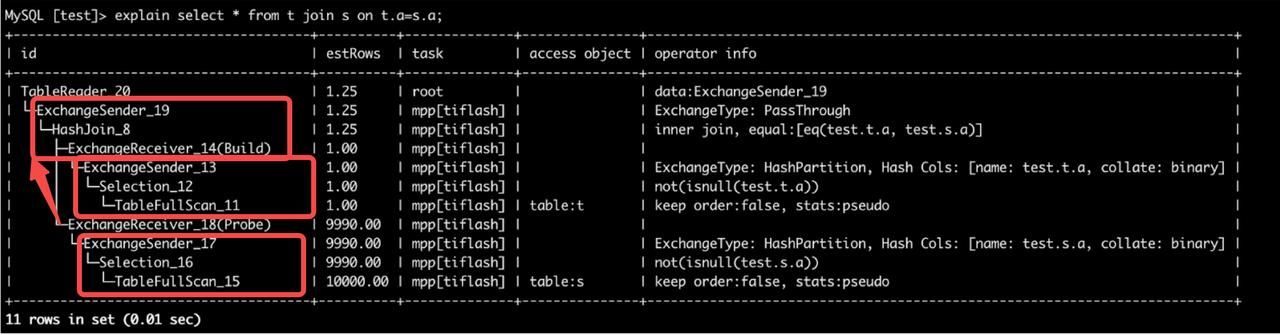
TiDB-server 节点会将查询计划按 Exchange 会作为分界,将查询切分为不同的计划片段(task),作为 dag 发给 TiFlash 节点。比如对于下图中所示的查询计划,会切分为这三个红框。
TiFlash 节点在编译完成后生成的 BlockInputStream 如下,可以在 debug 日志中看到:
task 1
ExchangeSender
Expression: <final projection>
Expression: <projection after push down filter>
Filter: <push down filter>
DeltaMergeSegmentThread
task 2
ExchangeSender
Expression: <final projection>
Expression: <projection after push down filter>
Filter: <push down filter>
DeltaMergeSegmentThread
task 3
CreatingSets
Union: <for join>
HashJoinBuildBlockInputStream x 20: <join build, build_side_root_executor_id = ExchangeReceiver_15>, join_kind = Inner
Expression: <append join key and join filters for build side>
Expression: <final projection>
Squashing: <squashing after exchange receiver>
TiRemoteBlockInputStream(ExchangeReceiver): schema: <exchange_receiver_0, Nullable(Int32)>, <exchange_receiver_1, Nullable(Int32)>
Union: <for mpp>
ExchangeSender x 20
Expression: <final projection>
Expression: <remove useless column after join>
HashJoinProbe: <join probe, join_executor_id = HashJoin_34>
Expression: <final projection>
Squashing: <squashing after exchange receiver>
TiRemoteBlockInputStream(ExchangeReceiver): schema: <exchange_receiver_0, Nullable(Int32)>, <exchange_receiver_1, Nullable(Int32)>
其中 task1 和 task2 是将数据从存储层读出,经过简单的处理之后,发给 ExchangeSender. 在 task3 中,有三个 BlockInpuStream 值得关注,分别是:CreatingSets, HashJoinBuild, HashJoinProbe.
CreatingSetsBlockInputStream
接受一个数据 BlockInputStream 表示 joinProbe,还有若干个代表 JoinBuild 的 Subquery。CreatingSets 会并发启动这些 Subquery, 等待他们执行结束后在开始启动数据 InputStream. 下面两张图分别是 CreatingSets 的 readPrefix 和 read 函数的调用栈。
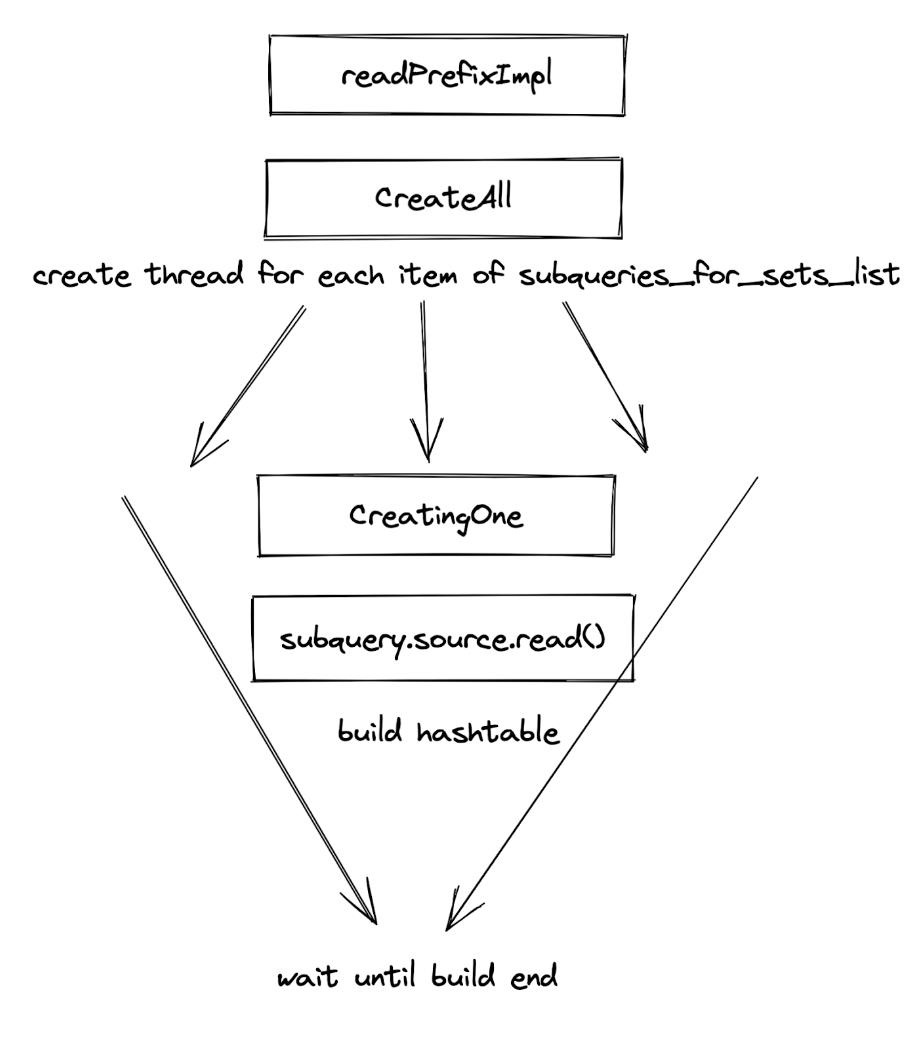
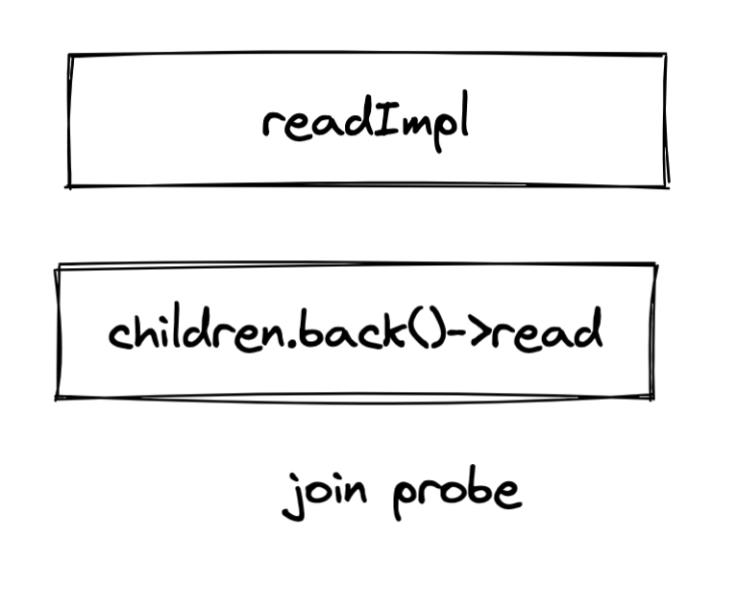
为什么 CreatingSets 可能同时创建多张哈希表?因为在一个多表 join 中,同一个计划片段可能紧接着做多次 join porbe,如下图所示:
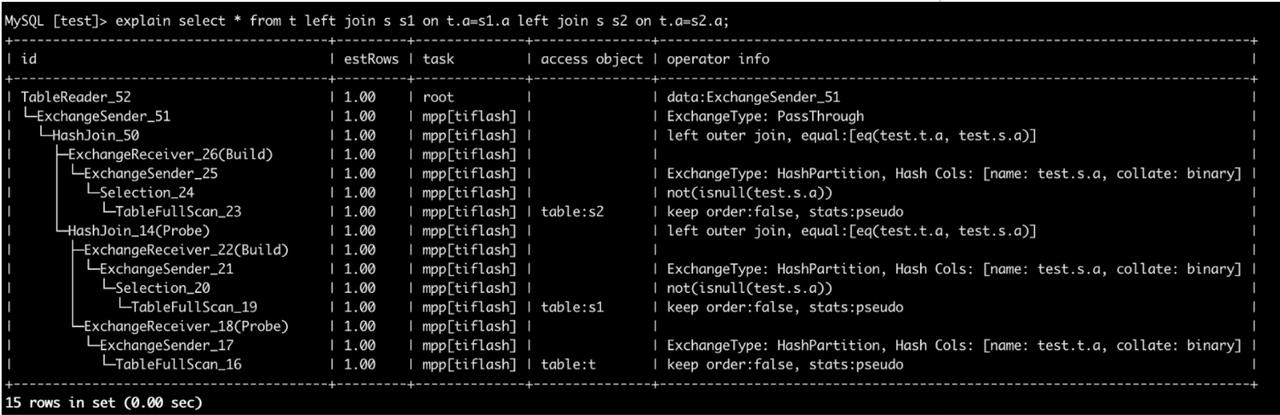
task:4
CreatingSets
Union x 2: <for join>
HashJoinBuildBlockInputStream x 20: <join build, build_side_root_executor_id = ExchangeReceiver_22>, join_kind = Left
Expression: <append join key and join filters for build side>
Expression: <final projection>
Squashing: <squashing after exchange receiver>
TiRemoteBlockInputStream(ExchangeReceiver): schema: <exchange_receiver_0, Nullable(Int32)>, <exchange_receiver_1, Nullable(Int32)>
Union: <for mpp>
ExchangeSender x 20
Expression: <final projection>
Expression: <remove useless column after join>
HashJoinProbe: <join probe, join_executor_id = HashJoin_50>
Expression: <final projection>
Expression: <remove useless column after join>
HashJoinProbe: <join probe, join_executor_id = HashJoin_14>
Expression: <final projection>
Squashing: <squashing after exchange receiver>
TiRemoteBlockInputStream(ExchangeReceiver): schema: <exchange_receiver_0, Nullable(Int32)>, <exchange_receiver_1, Nullable(Int32)>
Join Build
注意,join 在此处仅代表 hash join,已经与网络通信和 MPP 级别的算法无关。
关于 join 的代码都在 dbms/src/Interpreters/Join.cpp 中;我们以下面两张表进行 join 为例来说明:
left_table l join right_table r
on l.join_key=r.join_key
where l.b>=r.c

默认右表做 build 端,左表做 probe 端。哈希表的值使用链式存储:
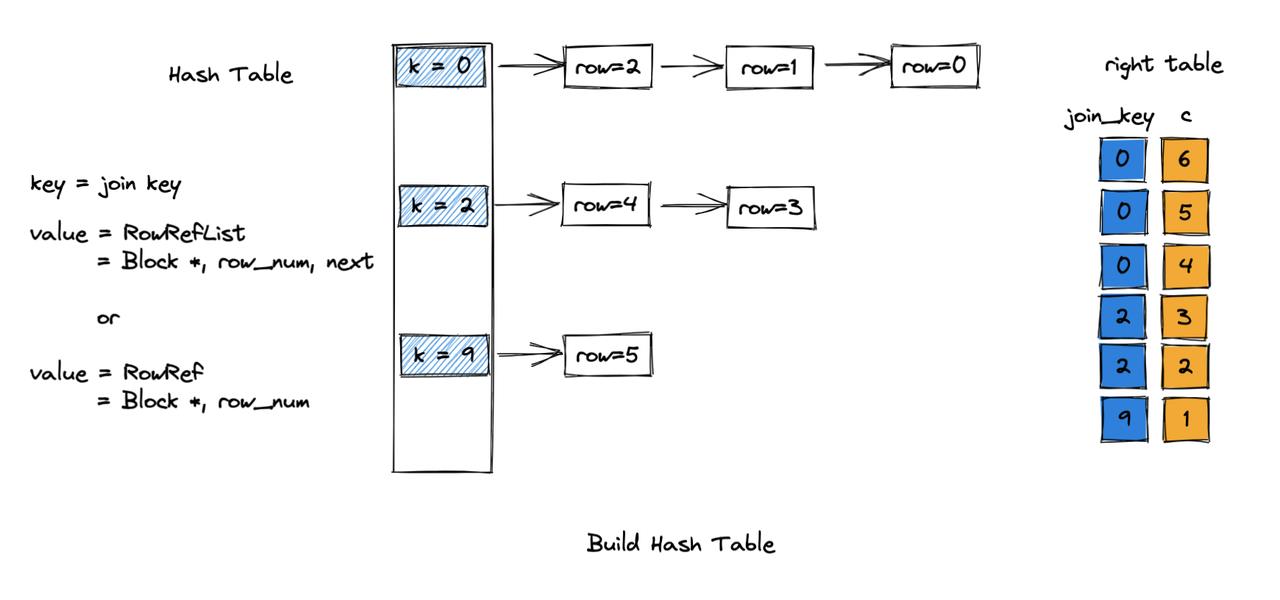
Join Probe
这里主要描述的是 JoinBlockImpl 这个函数的流程:
1.block 包含了左表的内容;创建 added_columns, 即要添加到 block 中的右表的列;然后创建相应的过滤器 replicate_offsets:表示当前共匹配了几行,之后可以用于筛选未匹配上的行,或复制匹配了多行的行。
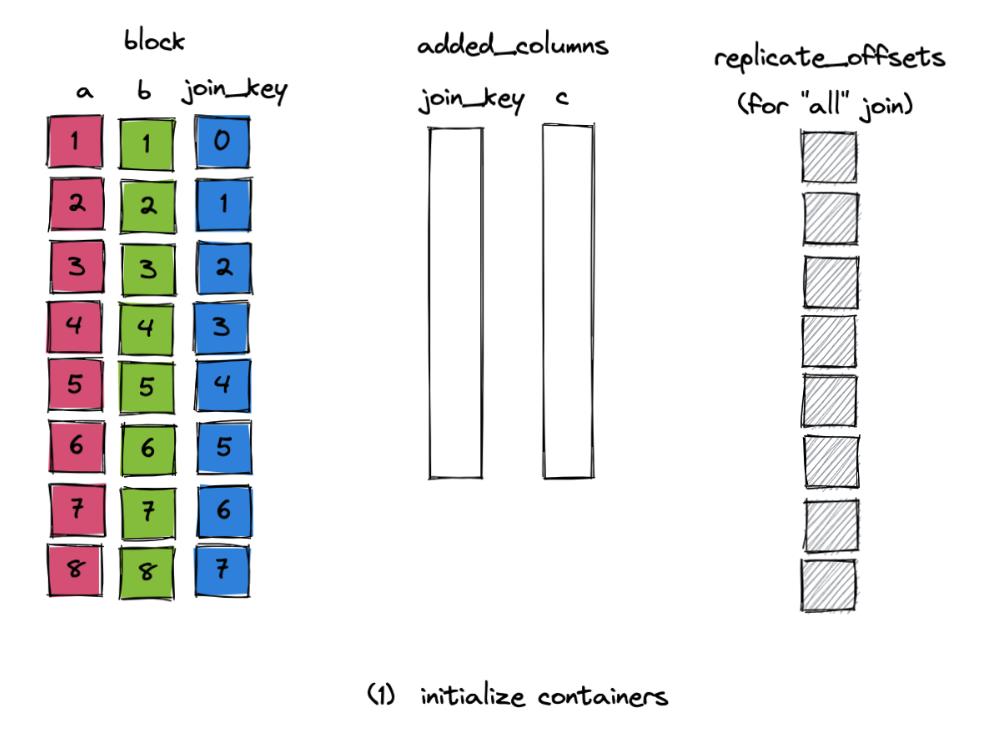
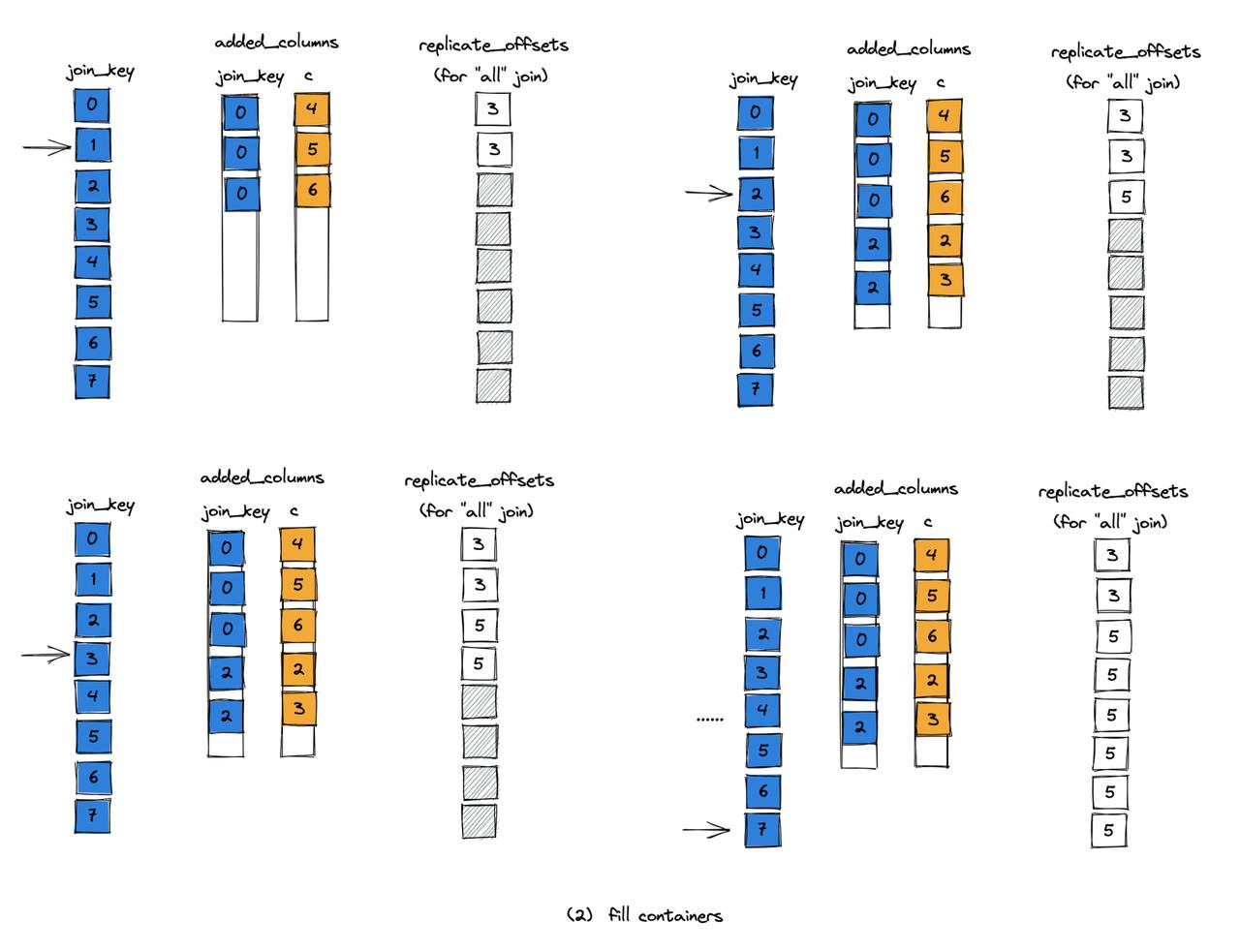
2.依次查找哈希表,根据查找结果调用相应的 addFound 或 addNotFound 函数,填充 added_columns 和过滤器。

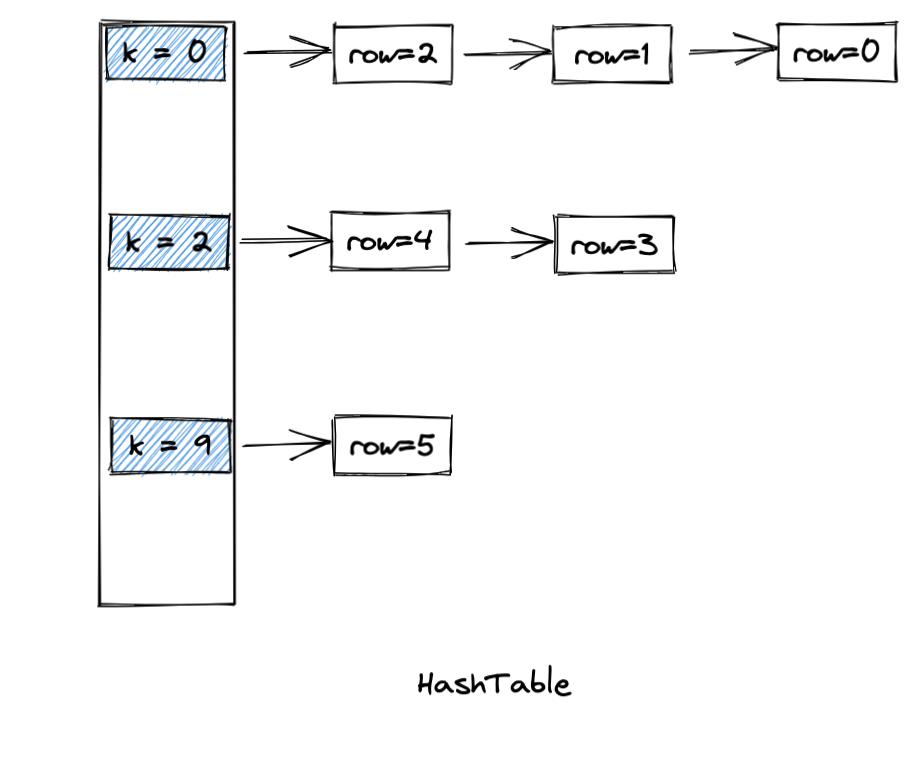
从填充的过程中也可以看到,replicate_offsets 左表表示到当前行为止,一共能匹配上的右表的行数。并且 replicate_offsets[i] - replicate_offsets[i-1] 就表示左表第 i 行匹配到的右表的行数。
3.将 added_column 直接拼接到 block 上,此时会有短暂的 block 行数不一致。
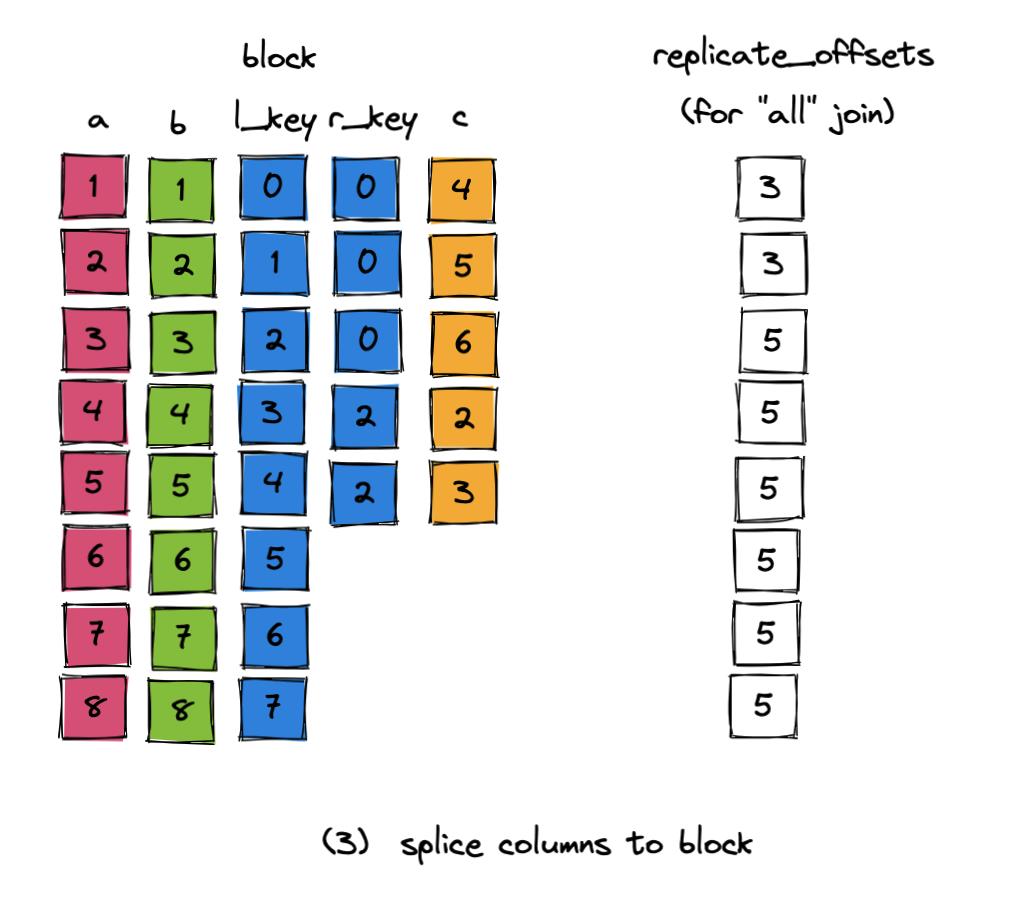
4.根据过滤器的内容,复制或过滤掉原先左表中的行。
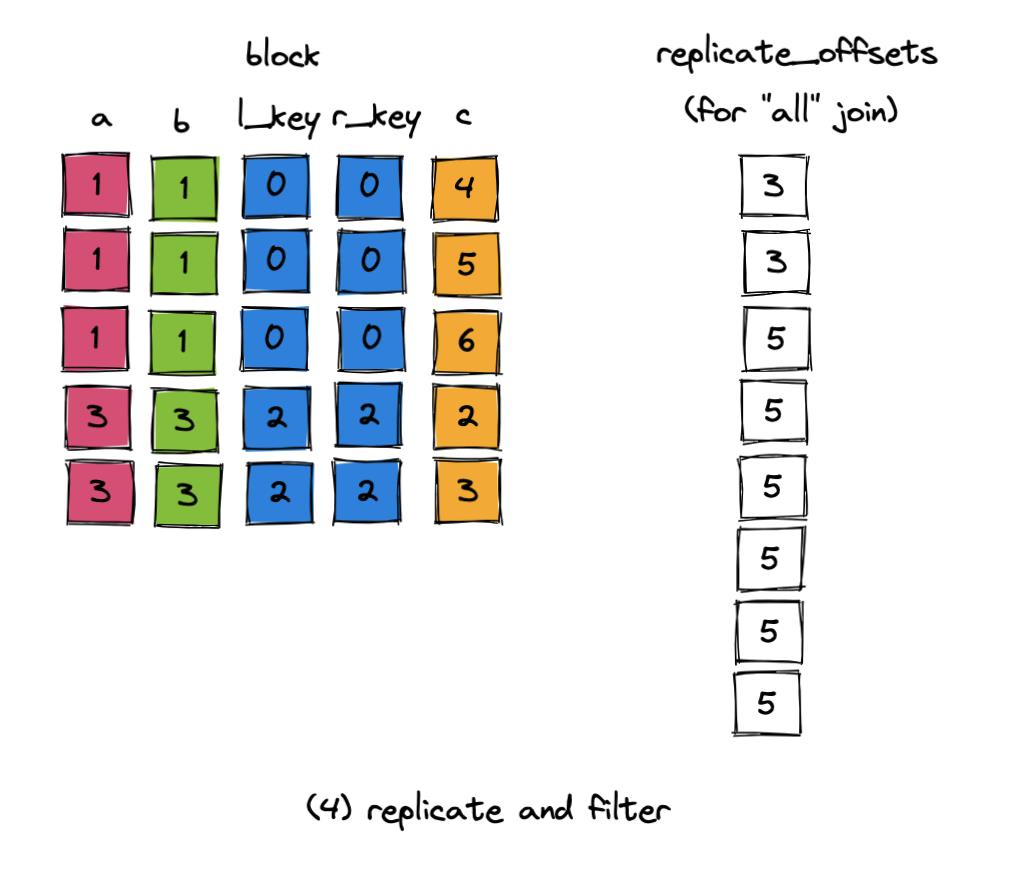
5.最后在 block 上处理 other condition,则得到了 join 的结果。

上文中描述的是对于正常的 “all” join 的情况,需要返回左右表的数据。与之相对的则是 “any” join,表示半连接,无需返回右表,只需返回左表的数据,则无需使用 replicate_offsets 这个辅助数组,读者可以自行阅读代码。 仍然在 dbms/src/intepreters/Join.cpp 中。
Aggregation 的编译与执行
还是以一个查询计划以及对应的 BlockInputStream 为例:
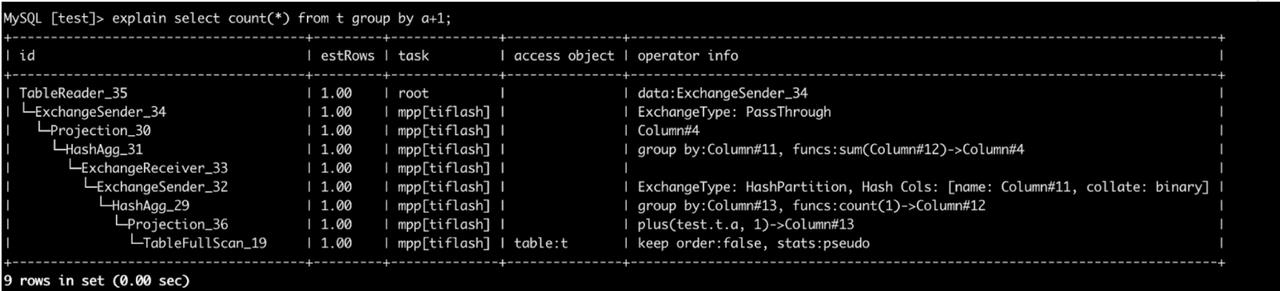
task:1
ExchangeSender
Expression: <final projection>
Expression: <before order and select>
Aggregating
Concat
Expression: <before aggregation>
Expression: <projection>
Expression: <before projection>
Expression: <final projection>
DeltaMergeSegmentThread
task:2
Union: <for mpp>
ExchangeSender x 20
Expression: <final projection>
Expression: <projection>
Expression: <before projection>
Expression: <final projection>
SharedQuery: <restore concurrency>
ParallelAggregating, max_threads: 20, final: true
Expression x 20: <before aggregation>
Squashing: <squashing after exchange receiver>
TiRemoteBlockInputStream(ExchangeReceiver): schema: <exchange_receiver_0, Int64>, <exchange_receiver_1, Nullable(Int64)>
从查询计划中可以看到这是一个两阶段 agg,第一阶段对应 task1,执行聚合的 BlockInputStream 是 Aggregating。第二阶段对应 task2,执行聚合的 BlockInputStream 是 ParallelAggragating。两个 task 通过 Exchange 进行网络数据传输。
在 aggregation 的编译期,会检查当前 pipeline 能够提供的并行度,如果只有 1,则使用 AggregatingBlockInputStream 单线程执行,如果大于 1 则使用 ParallelAggragating 并行执行。
DAGQueryBlockInterpreter::executeAggregation()
if (pipeline.streams.size() > 1)
ParallelAggregatingBlockInputStream
else
AggregatingBlockInputStream
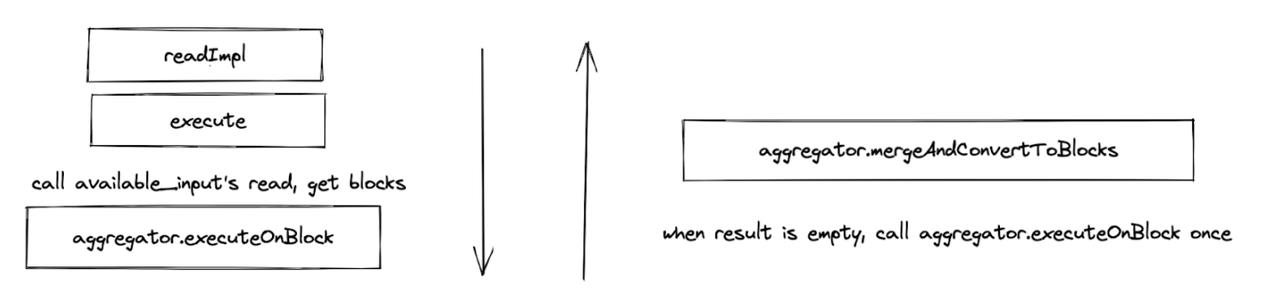
AggregatingBlockInputStream 的调用栈如下:
ParallelAggregatingBlockInputStream 内部会分两阶段操作(这里的两阶段是内部执行中的概念,发生在同一台节点上,和查询计划中的两阶段不是一个概念)。partial 阶段分别在 N 个线程构建 HashTable,merge 阶段则将 N 个 HashTable 合并起来,对外输出一个流。调用栈如下:
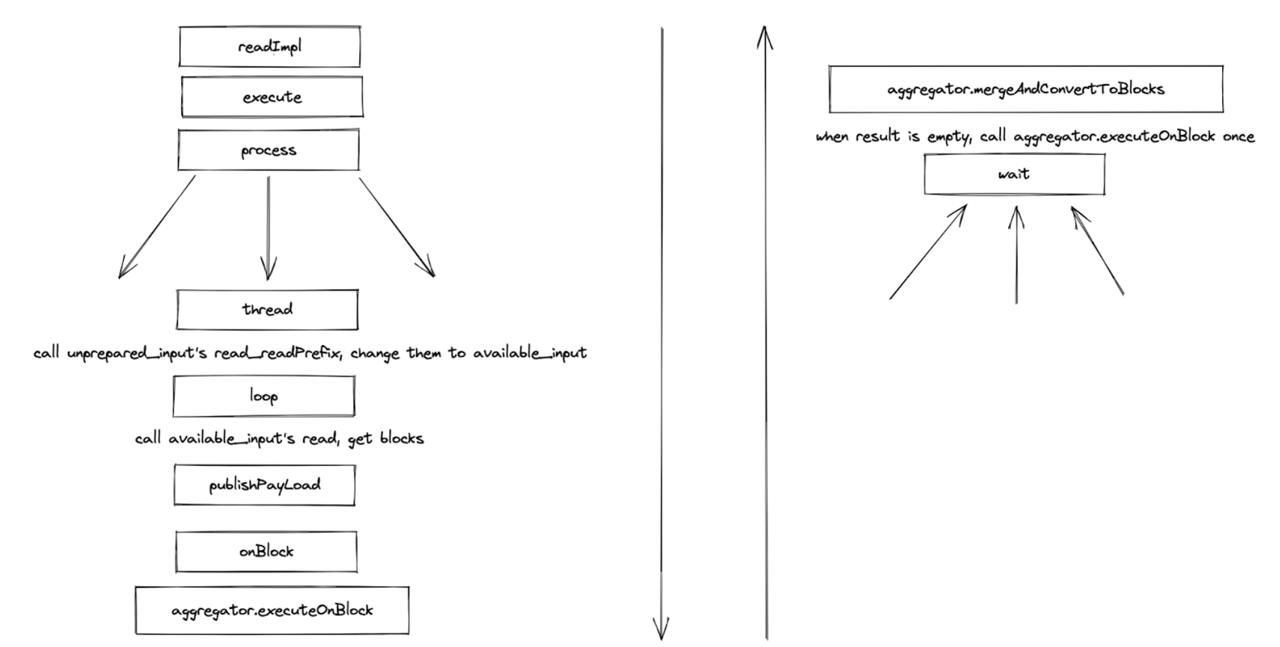
如果 result 是空,那么会单独调用一次 executeOnBlock 方法,来生成一个默认数据,类似于 count() 没有输入时,会返回一个 0.
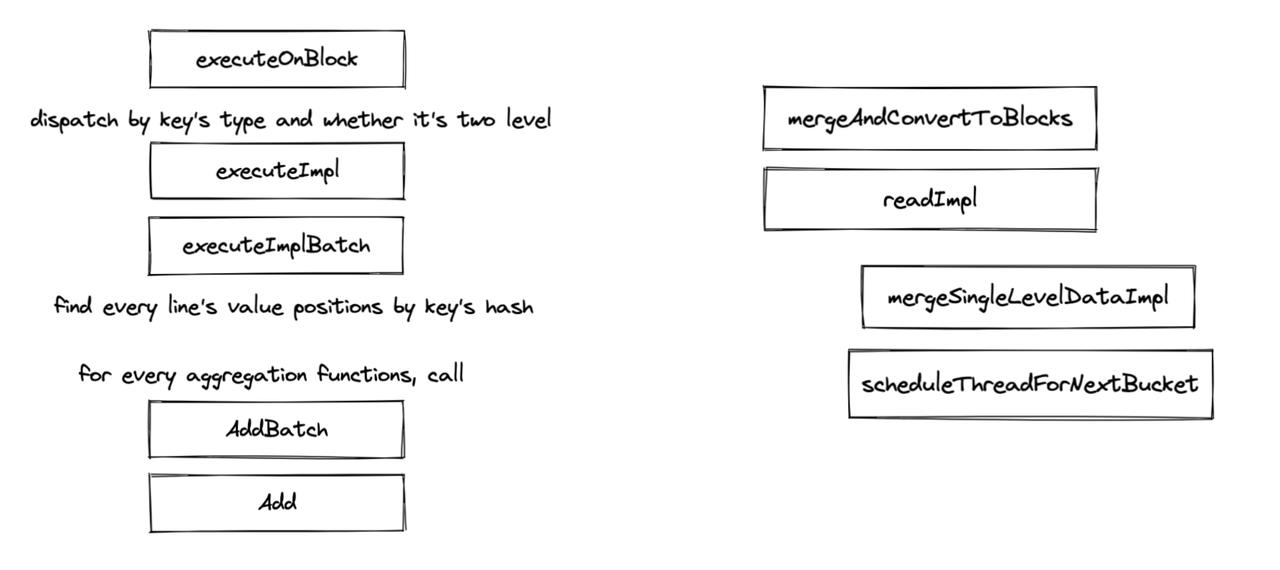
两种执行方式都用到了 Aggregator 的 executeOnBlock 方法和 mergeAndConvertToBlocks 方法,他们的调用栈如图所示。前者是实际执行聚合函数的地方,会调用聚合函数的 add 方法,将数据值加入;后者的主要目的是将 ParallelAggregating 并行生成的哈希表合并。
以上是关于TiFlash 源码阅读TiFlash 中常用算子的设计与实现的主要内容,如果未能解决你的问题,请参考以下文章