指定GPU使用CUDA_VISIBLE_DEVICES指定可见GPU时的一些坑
Posted SinHao22
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了指定GPU使用CUDA_VISIBLE_DEVICES指定可见GPU时的一些坑相关的知识,希望对你有一定的参考价值。
目录
1. 问题描述
记录一下今天遇到并解决的一个问题:
最近要用服务器训练模型,GPU:0一直有人在使用,所以就想着用GPU:1和GPU:2。但有一个疑惑:
假设我们要运行的代码名称为:“try3.py”,具体代码如下:
# try3.py
import torch
if __name__ == '__main__':
print(f'当前设备为:torch.cuda.current_device()')
首先在命令行:
CUDA_VISIBLE_DEVICES=1,2 python try3.py
按照我的预想,因为设置了只对GPU:1和GPU:2两个GPU可见,所以上述代码应该会输出:1,即GPU:1的id。但实际结果却为:
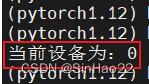
为什么设置只对GPU:1和GPU:2可见,但是代码输出的当前device id却还是0呢?
结论是:虽然这里代码输出当前device id是0,但其实指的是GPU:1,实际使用时也会使用GPU:1。由于设置CUDA_VISIBLE_DEVICES=1,2,所以只有GPU:1和GPU:2对代码可见,代码会认为可见的第一个GPU(即GPU:1)的id为0。
如果你赶时间,那么看到这里就可以了。后续是结论验证部分。
2. 验证结论
我们将try3.py设置如下:
import torch
from torchvision.models import resnet50, resnet152
if __name__ == '__main__':
# 虽然这里设置cuda:0,但实际使用的是1号gpu
device = torch.device('cuda:0' if torch.cuda.is_available else 'cpu')
print(f'当前设备为:torch.cuda.current_device()')
model = resnet152(num_classes=10)
model.to(device)
# 使用res152做1000次前向推断,batch-size设置为16
for i in range(1000):
X = torch.randn(16,3,224,224).to(device)
y = model(X)
print(f'id:i+1:3d:y')
运行命令:
CUDA_VISIBLE_DEVICES=1,2 python try3.py
看看GPU使用情况:
nvidia-smi
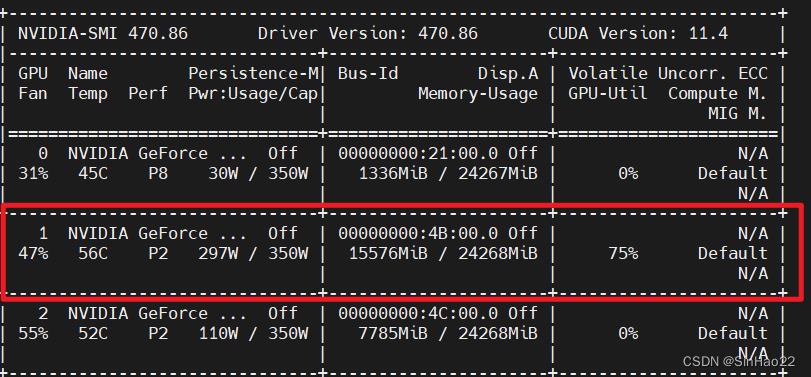
可以看到使用1号GPU在训练
如果我们将try3.py设置使用cuda:1来训练:
import torch
from torchvision.models import resnet50, resnet152
if __name__ == '__main__':
# 虽然这里设置cuda:1,但实际使用的是2号gpu
device = torch.device('cuda:1' if torch.cuda.is_available else 'cpu')
print(f'当前设备为:torch.cuda.current_device()')
model = resnet152(num_classes=10)
model.to(device)
# 使用res152做1000次前向推断,batch-size设置为16
for i in range(1000):
X = torch.randn(16,3,224,224).to(device)
y = model(X)
print(f'id:i+1:3d:y')
运行命令:
CUDA_VISIBLE_DEVICES=1,2 python try3.py
看看GPU使用情况:
nvidia-smi
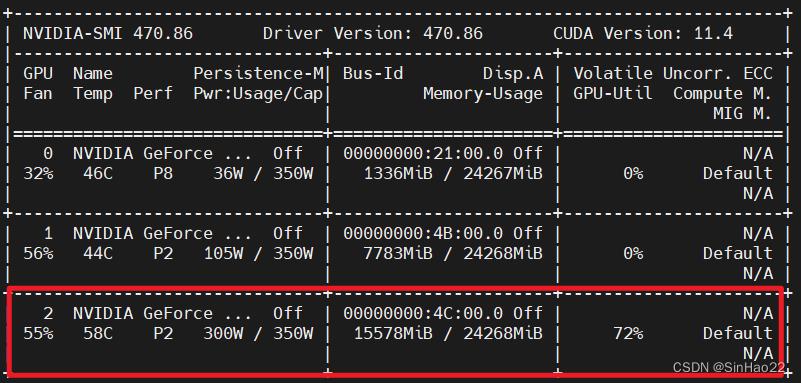
可以看到使用2号GPU在训练。
END:)
以上是关于指定GPU使用CUDA_VISIBLE_DEVICES指定可见GPU时的一些坑的主要内容,如果未能解决你的问题,请参考以下文章