聊聊 Kafka:Kafka 消息重复的场景以及最佳实践
Posted 老周聊架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聊聊 Kafka:Kafka 消息重复的场景以及最佳实践相关的知识,希望对你有一定的参考价值。
一、前言
上一篇我们讲了 聊聊 Kafka:Kafka 消息丢失的场景以及最佳实践,这一篇我们来说一说 Kafka 消息重复的场景以及最佳实践。
我们下面会从以下两个方面来说一下 Kafka 消息重复的场景以及最佳实践。
- 生产者重复消息
- 消费者重复消息
二、Kafka 消息重复的场景
2.1 生产者重复消息
2.1.1 根本原因
生产者发送的消息没有收到 Broker 正确的响应,导致生产者重试。
生产者发出一条消息,Broker 落盘以后因为网络等种种原因,发送端得到一个发送失败的响应或者网
络中断,然后生产者收到一个可恢复的 Exception 重试消息导致消息重复。
2.1.2 重试过程

主要流程:
- new KafkaProducer() 后创建一个后台线程 KafkaThread 扫描 RecordAccumulator 中是否有消息;
- 调用 KafkaProducer.send() 发送消息,实际上只是把消息保存到 RecordAccumulator 中;
- 后台线程 KafkaThread 扫描到 RecordAccumulator 中有消息后,将消息发送到 Kafka 集群;
- 如果发送成功,那么返回成功;
- 如果发送失败,那么判断是否允许重试。如果不允许重试,那么返回失败的结果;如果允许重
试,把消息再保存到 RecordAccumulator 中,等待后台线程 KafkaThread 扫描再次发送。
具体的重试流程见下图:

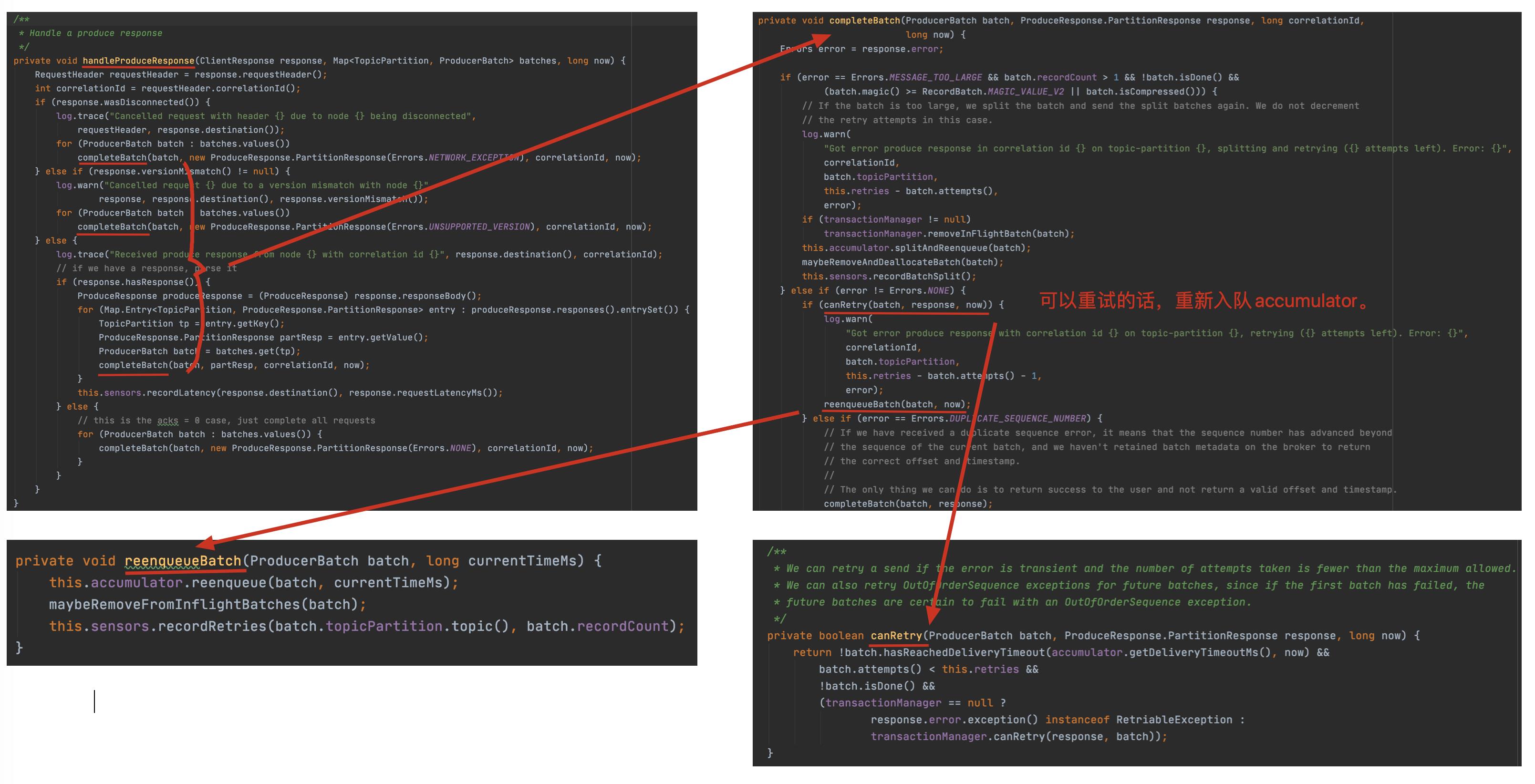
2.1.3 可恢复异常说明
从下面源码中不难发现异常是 RetriableException 类型或者消息是事务类型 TransactionManager 允许重试;
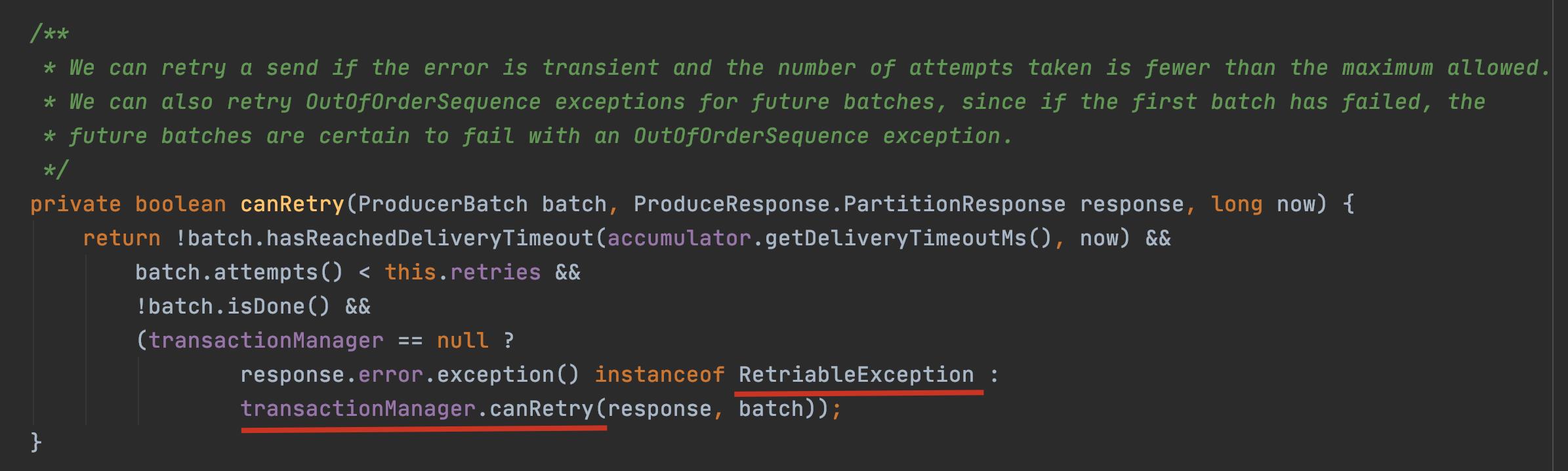
常见的 RetriableException 类继承关系如下:

2.1.4 记录顺序问题
如果设置 max.in.flight.requests.per.connection > 1(默认5,单个连接上发送的未确认请求的最大数量,表示上一个发出的请求没有确认下一个请求又发出了)。大于1可能会改变记录的顺序,因为如果将两个 batch 发送到单个分区,第一个 batch 处理失败并重试,但是第二个 batch 处理成功,那么第二个 batch 处理中的记录可能先出现被消费。
设置 max.in.flight.requests.per.connection = 1,可能会影响吞吐量,可以解决单个生产者发送顺序问题。如果多个生产者,生产者1先发送一个请求,生产者2后发送请求,此时生产者1返回可恢复异常,重试一定次数成功了。虽然生产者1先发送消息,但生产者2发送的消息会被先消费。
2.2 消费者重复消息
2.2.1 根本原因
数据消费完没有及时提交 offset 到 Broker
2.2.2 业务场景
消息消费端在消费过程中挂掉没有及时提交 offset 到 Broker,另一个消费端启动拿之前记录的 offset 开始消费,由于 offset 的滞后性可能会导致新启动的客户端有少量重复消费。
三、Kafka 的三种消息语义
上一篇我们提到 Kafka 的三种消息语义,有一种仅有一次传递语义,可以保证消息不会丢失,也不会被重复发送。
忘了的我这里再说一下:
- 最多一次(At most once):消息可能会丢失,但绝不会被重复发送。
- 至少一次(At least once):消息不会丢失,但有可能被重复发送。
- 仅有一次(Exactly once):消息不会丢失,也不会被重复发送。
那你可能就会问了,那就直接用这个 Exactly once 语义不就行了吗?
Kafka 支持的 Exactly once 和消息传递的服务质量标准 Exactly once 是不一样的。它是 Kafka 提供的另外一个特性,Kafka 中支持的事务也和我们通常意义理解的事务有一定的差异。在 Kafka 中,事务和 Excactly once 主要是为了配合流计算使用的特性。
刚开始我也以为 Kafka 像 MQTT 一样能保证消息传递的仅有一次语义,后来才发现需要自己去实现,不得不说下 Kafka 的营销手段还是不错的。
既然 Kafka 无法保证消息不重复,那就需要我们的消费代码能够接受“消息是可能会重复的”这一现状,然后,通过一些方法来消除重复消息对业务的影响。
Kafka 实际上通过两种机制来确保消息消费的精确一次:
- 幂等性(Idempotence)
- 事务(Transaction)
四、幂等性
4.1 什么是幂等性
保证在消息重发的时候,消费者不会重复处理。即使在消费者收到重复消息的时候,重复处理,也要保证最终结果的一致性。
所谓幂等性,数学概念就是: f(f(x)) = f(x) 。f函数表示对消息的处理。
比如,银行转账,如果失败,需要重试。不管重试多少次,都要保证最终结果一定是一致的。
4.2 引入幂等性之前
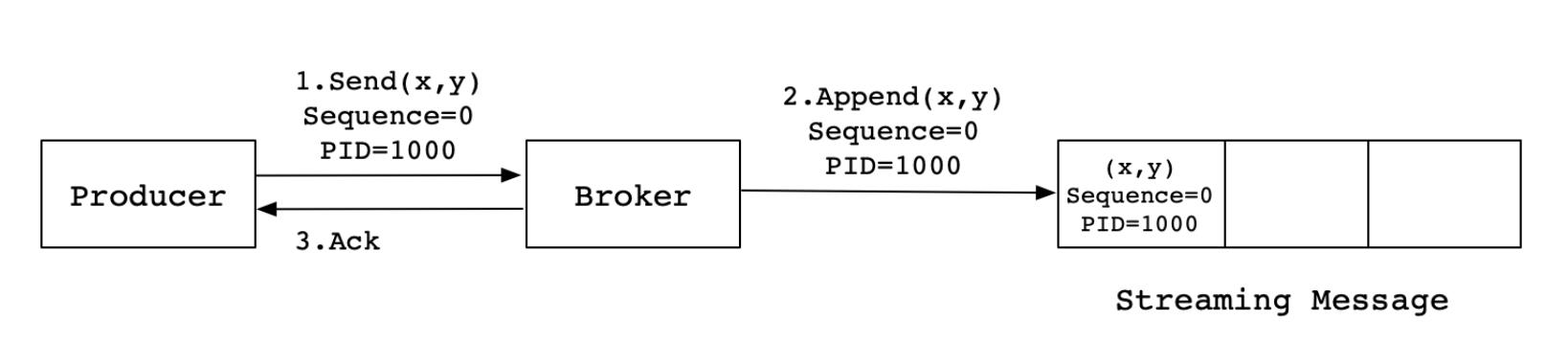
Producer 向 Broker 发送消息,然后 Broker 将消息追加到消息流中后再给 Producer 返回 Ack 信号值。实现流程如下:

生产中,会出现各种不确定的因素,比如在 Producer 在发送给 Broker 的时候出现网络异常。比如以下这种异常情况的出现:

上图这种情况,当 Producer 第一次发送消息给 Broker 时,Broker 将消息 (x2,y2) 追加到了消息流中, 但是在返回 Ack 信号给 Producer 时失败了(比如网络异常) 。此时,Producer 端触发重试机制,将消息 (x2,y2) 重新发送给 Broker,Broker 接收到消息后,再次将该消息追加到消息流中,然后成功返回 Ack 信号给 Producer。这样下来,消息流中就被重复追加了两条相同的 (x2,y2) 的消息。
4.3 引入幂等性之后
Kafka为了实现幂等性,在 0.11.0 版本之后,它在底层设计架构中引入了ProducerID和SequenceNumber。
ProducerID:在每个新的 Producer 初始化时,会被分配一个唯一的 ProducerID,这个 ProducerID 对客户端使用者是不可见的。SequenceNumber:对于每个 ProducerID,Producer 发送数据的每个 Topic 和 Partition 都对应一个从 0 开始单调递增的 SequenceNumber 值。
同样,这是一种理想状态下的发送流程。实际情况下,会有很多不确定的因素,比如 Broker 在发送 Ack 信号给 Producer 时出现网络异常,导致发送失败。异常情况如下图所示:
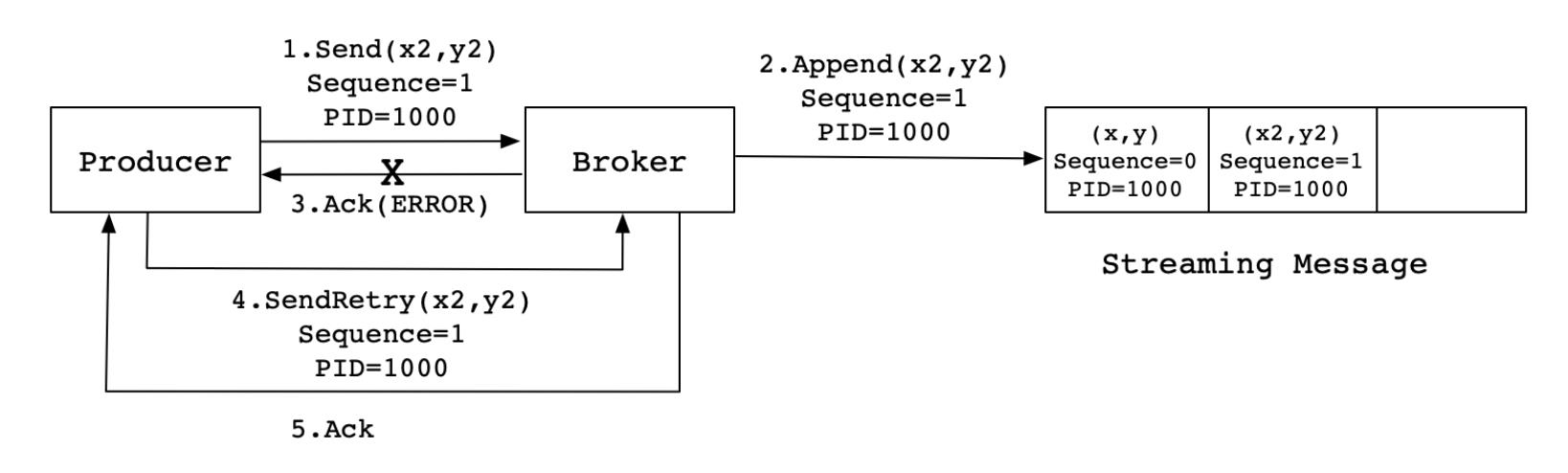
当 Producer 发送消息 (x2,y2) 给 Broker 时,Broker 接收到消息并将其追加到消息流中。此时,Broker 返回 Ack 信号给 Producer 时,发生异常导致 Producer 接收 Ack 信号失败。对于 Producer 来说,会触发重试机制,将消息 (x2,y2) 再次发送,但是,由于引入了幂等性,在每条消息中附带PID(ProducerID) 和 SequenceNumber。相同的 PID 和 SequenceNumber 发送给 Broker,而之前 Broker 缓存过之前发送的相同的消息,那么在消息流中的消息就只有一条 (x2,y2),不会出现重复发送的情况。
4.4 源码分析
直接看 org.apache.kafka.clients.producer.internals.Sender#run 方法,然后跟进 runOnce 方法:
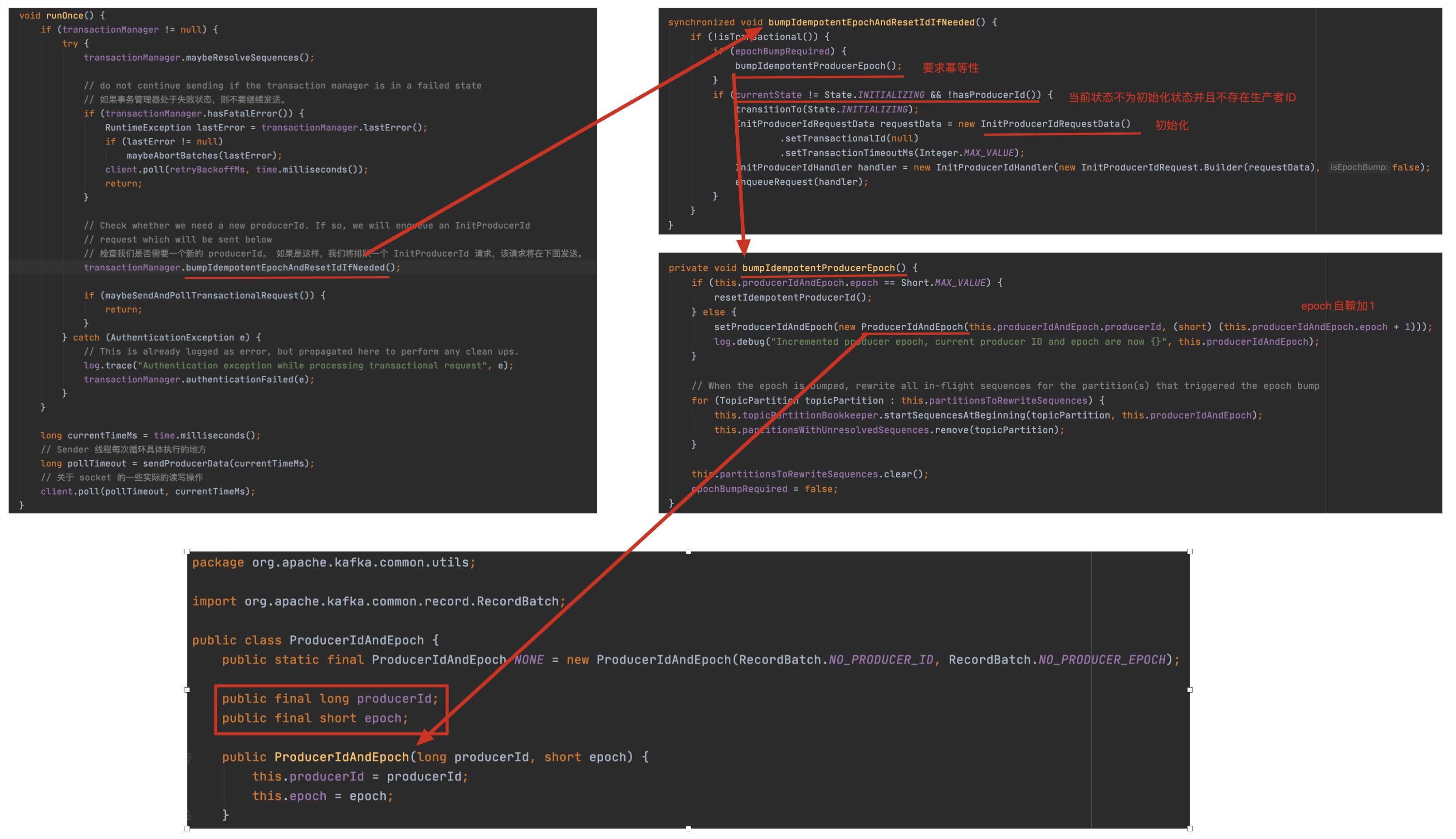
细心地读者可能会问了,老周啊,你上面不是说的 SequenceNumber 么,怎么 ProducerIdAndEpoch 里是 epoch 啊?没错,老周这里的版本是 2.7.0 了,跟以前的老版本有点不一样,但意思是一样的,之前是序列号,现在的是代。
4.5 注意
我们上面说了在每个新的 Producer 初始化时,会分配一个 PID,消息发送到的每一个分区都有对应的代号,这些代号从 0 开始单调递增。生产者每发送一条消息就会将 <PID, 分区> 对应的代号值加 1。
Broker 端在内存中为每一对 <PID, 分区> 维护一个序列号 epoch_old。针对生产者发送来的每一条消息,对其代号 epoch_new 进行判断,并作相应处理。
- 只有 epoch_new 比 epoch_old 大 1 时,即 epoch_new = epoch_old + 1 时,Broker 才会接受这条消息;
- epoch_new < epoch_old + 1,说明消息被重复写入,Broker 直接丢弃该条消息;
- epoch_new > epoch_old + 1,说明中间有数据尚未写入,出现了消息乱序,可能存在消息丢失的现象,对应的生产者会抛出 OutOfOrderSequenceException 异常。
代号针对 <PID, 分区>,这意味着幂等生产者只能保证单个主题的单一分区内消息不重复;其次,它只能实现单会话上的幂等性,不能实现跨会话的幂等性,这里的会话即可以理解为:Producer 进程的一次运行。当重启了 Producer 进程之后,则幂等性保证就失效了。
那么你可能会问,如果我想实现多分区以及多会话上的消息无重复,应该怎么做呢?答案就是事务(transaction)或者依赖事务型 Producer。这也是幂等性 Producer 和事务型 Producer 的最大区别!
五、事务
幂等性不能实现多分区以及多会话上的消息无重复,而 Kafka 事务则可以弥补这个缺陷,Kafka 自 0.11 版本开始也提供了对事务的支持,目前主要是在 read committed 隔离级别上做事情。它能保证多条消息原子性地写入到目标分区,同时也能保证 Consumer 只能看到事务成功提交的消息。下面我们就来看看 Kafka 中的事务型 Producer。
事务型 Producer 能够保证将消息原子性地写入到多个分区中。这批消息要么全部写入成功,要么全部失败。另外,事务型 Producer 也不惧进程的重启。Producer 重启回来后,Kafka 依然保证它们发送消息的精确一次处理。
六、最佳实践
6.1 生产端
6.1.1 幂等性 Producer
幂等性 Producer 只适合单个主题的单一分区内消息不重复,其次,它只能实现单会话上的幂等性。
-
设置
enable.idempotence=true,生产者将确保在流中准确地写入每个消息的一个副本。

-
设置
acks = all。代表了你对“已提交”消息的定义。如果设置成 all,则表明所有副本 Broker 都要接收到消息,该消息才算是“已提交”。这是最高等级的“已提交”定义。

-
设置
max.in.flight.requests.per.connection < 5,客户端将在单个连接上发送的未确认请求的最大数量。

具体设置多少,可以参考上文 2.1.4 记录顺序问题,根据自己的业务情况来设置。 -
设置
retries = 3,当出现网络的瞬时抖动时,消息发送可能会失败,此时配置了 retries > 0 的 Producer 能够自动重试消息发送,避免消息丢失。

如果重试达到设定的次数,那么生产者就会放弃重试并返回异常。不过并不是所有的异常都是可以通过重试来解决的,比如消息太大,超过max.request.size参数配置的值时,这种方式就不可行了。 -
设置
retry.backoff.ms = 300,合理估算重试的时间间隔,可以避免无效的频繁重试。

它用来设定两次重试之间的时间间隔,避免无效的频繁重试。在配置retries和retry.backoff.ms之前,最好先估算一下可能的异常恢复时间,这样可以设定总的重试时间大于这个异常恢复时间,以此来避免生产者过早地放弃重试。
6.1.2 事务型 Producer
能实现多分区以及多会话上的消息无重复,即使进程的重启。Producer 重启回来后,Kafka 依然保证它们发送消息的精确一次处理。
其它参数和上面的幂等性 Producer 参数一致,多加一个:
- 设置
transactional.id。这就支持了跨多个生产者会话的可靠性语义,因为它允许客户端在启动任何新事务之前确保使用相同 TransactionalId 的事务已经完成,最好为其设置一个有意义的名字。

事务型 Producer 代码应该这样写:
producer.initTransactions();
try
producer.beginTransaction();
producer.send(record1);
producer.send(record2);
producer.commitTransaction();
catch (KafkaException e)
producer.abortTransaction();
和普通 Producer 代码相比,事务型 Producer 的显著特点是调用了一些事务 API,如 initTransaction、beginTransaction、commitTransaction 和 abortTransaction,它们分别对应事务的初始化、事务开始、事务提交以及事务终止。
这段代码能够保证 record1 和 record2 被当作一个事务统一提交到 Kafka,要么它们全部提交成功,要么全部写入失败。
6.1.3 不在乎数据丢失的场景
你可能会问了,我的系统存在这种场景,我不在乎数据的丢失,该怎么配呢?你不会让我配置上面那些幂等性、事务型的参数吧?比如我的可能是日志收集的系统,这会导致系统吞吐量严重降低。
别着急,针对这种场景也有有有相应的方案的,那上面的参数别管了,
- 设置
ack=0,不需要 Broker 接收到消息的确认也不需要重试。
6.2 消费端
6.2.1 消费事务型 Producer 消息
设置 isolation.level=read_committed 参数的值即可

- read_uncommitted:这是默认值,表明 Consumer 能够读取到 Kafka 写入的任何消息,不论事务型 Producer 提交事务还是终止事务,其写入的消息都可以读取。很显然,如果你用了事务型 Producer,那么对应的 Consumer 就不要使用这个值。
- read_committed:表明 Consumer 只会读取事务型 Producer 成功提交事务写入的消息。当然了,它也能看到非事务型 Producer 写入的所有消息。
6.2.2 通用设置
确保消息消费完成再提交。最好把它设置成 enable.auto.commit = false,并采用手动提交位移的方式。这对于单 Consumer 多线程处理的场景而言是至关重要的。

6.2.3 下游消费端做幂等
6.2.3.1 利用数据库的唯一约束实现幂等
比如金融领域,有一张流水表,表里有三个字段:转账单 ID、账户 ID 和变更金额,对于每个转账单每个账户只可以执行一次变更操作,我们可以给转账单 ID 和账户 ID 这两个字段联合起来创建一个唯一约束,这样对于相同的转账单 ID 和账户 ID,表里至多只能存在一条记录。
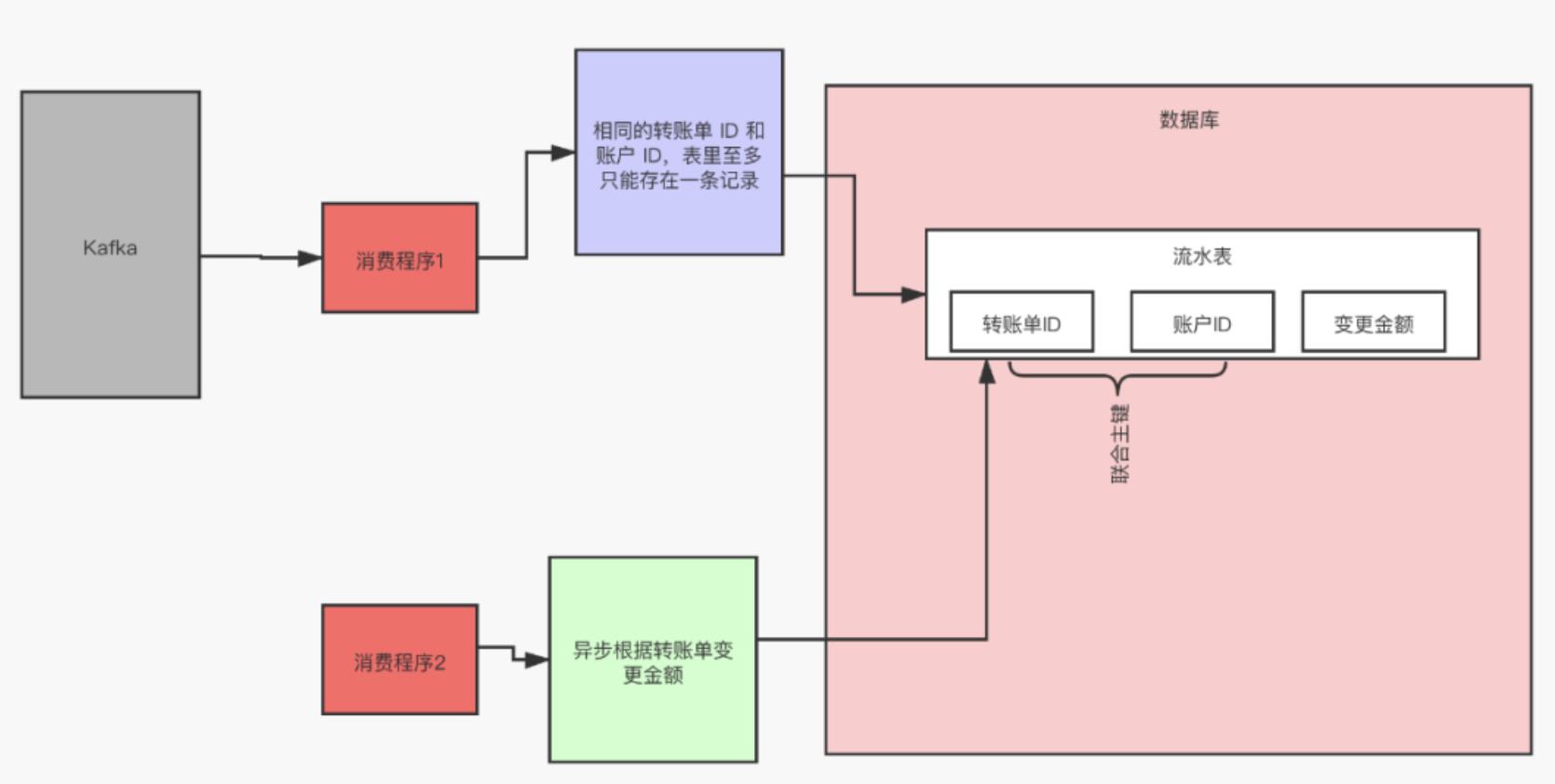
基于这个思路,不光是可以使用关系型数据库,只要是支持类似“INSERT IF NOT EXIST”语义的存储类系统都可以用于实现幂等,比如,你可以用 Redis 的 SETNX 命令来替代数据库中的唯一约束,来实现幂等消费。
6.2.3.2 设置前置条件
给数据变更设置一个前置条件,如果满足条件就更新数据,否则拒绝更新数据,在更新数据的时候,同时变更前置条件中需要判断的数据。这样,重复执行这个操作时,由于第一次更新数据的时候已经变更了前置条件中需要判断的数据,不满足前置条件,则不会重复执行更新数据操作。
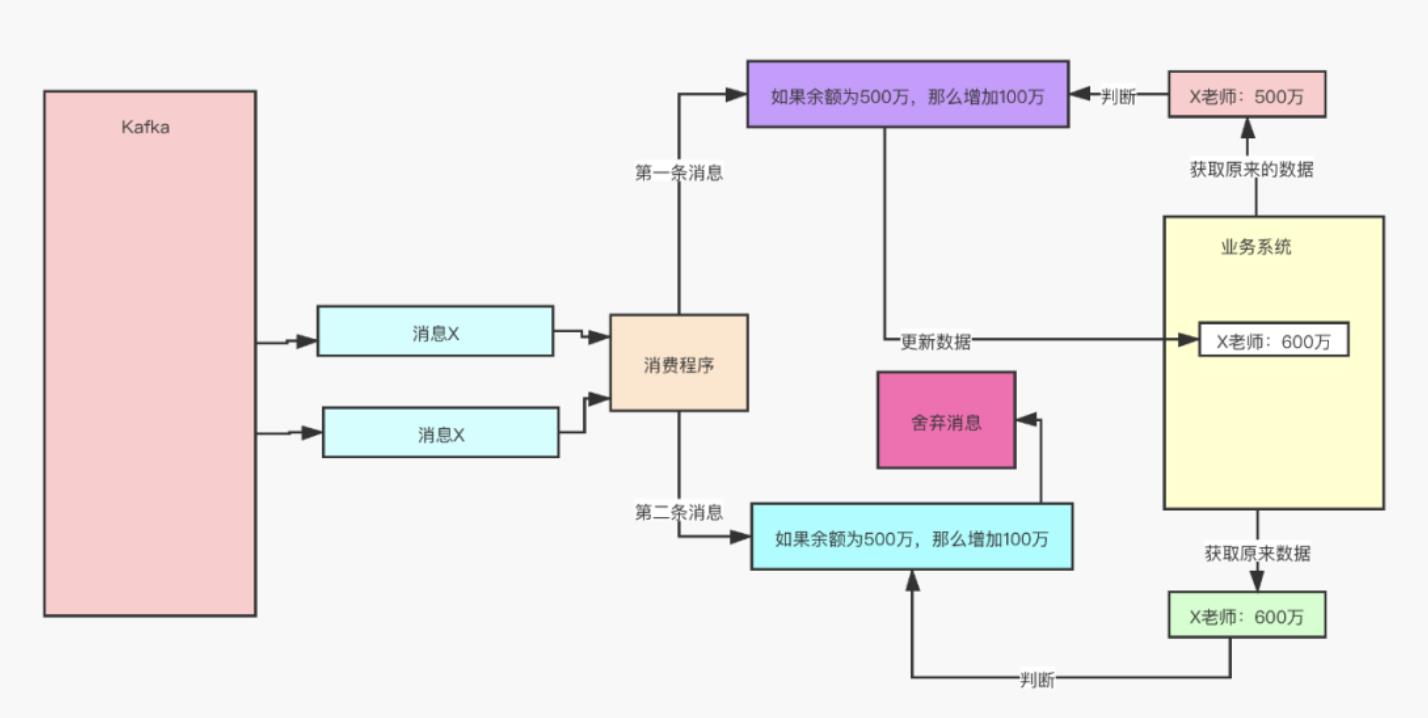
但是,如果我们要更新的数据不是数值,或者我们要做一个比较复杂的更新操作怎么办?用什么作为前置判断条件呢?更加通用的方法是,给你的数据增加一个版本号属性,每次更数据前,比较当前数据的版本号是否和消息中的版本号一致,如果不一致就拒绝更新数据,更新数据的同时将版本号 +1,一样可以实现幂等更新。
不知道小伙伴们有没有发现,这个思想就是大名鼎鼎 CAS 乐观锁机制,其实很多高大上的东西并没有那么难,思想往往很简单。
6.2.3.3 记录并检查操作
如果上面两种方法都不适用你,这里还有一种通用性更强的方法,就是给每条消息都记录一个全局唯一 ID,消费时,先根据这个全局唯一 ID 检查这条消息是否有被消费过,如果没有消费过,才更新数据,然后将消费状态置为已消费。
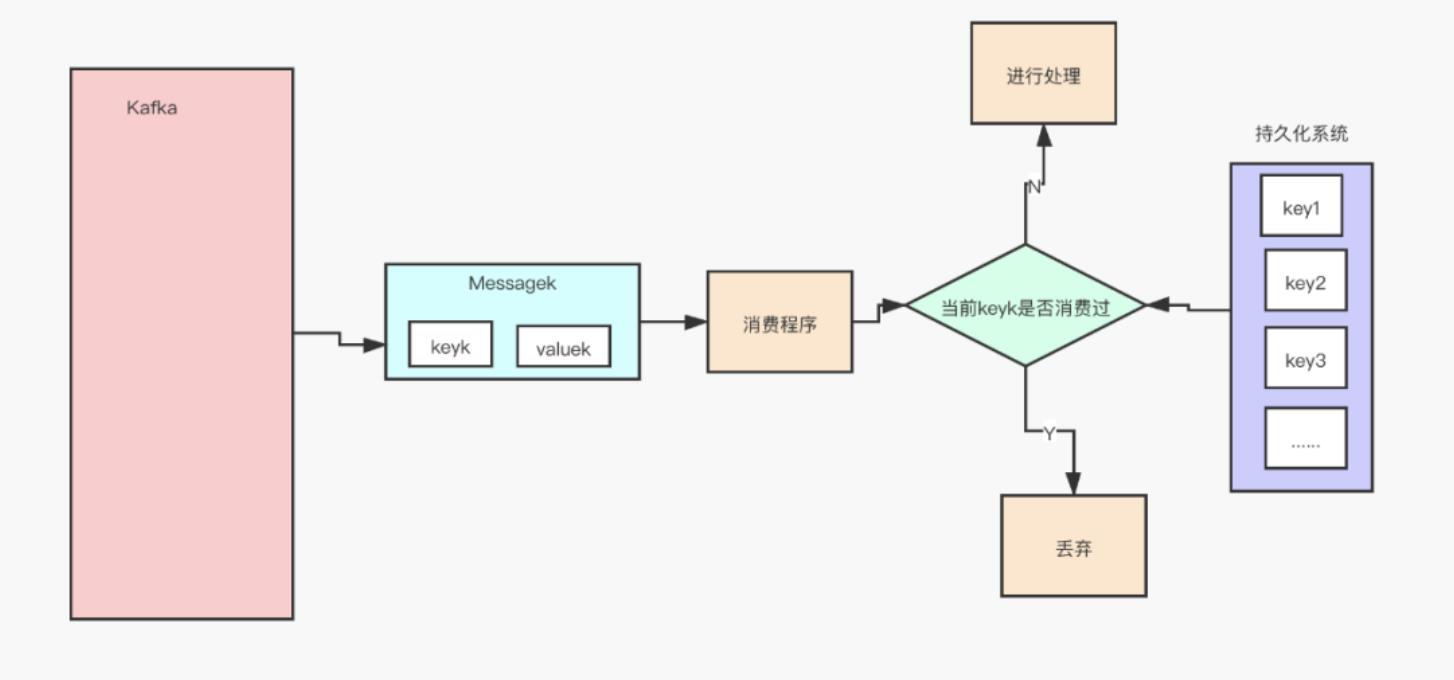
是不是感觉很简单?但里面的坑很大,说到底还是数据一致性不好保证,在“检查消费状态,然后更新数据并且设置消费状态”中,三个操作必须作为一组操作保证原子性,才能真正实现幂等,否则就会出现 Bug。
好了,这就是 Kafka 消息重复的场景以及最佳实践的所有内容了,希望对你实践有所参考意义,我们下期再见。
以上是关于聊聊 Kafka:Kafka 消息重复的场景以及最佳实践的主要内容,如果未能解决你的问题,请参考以下文章