HDF5简介
Posted 逗逗飞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDF5简介相关的知识,希望对你有一定的参考价值。
原文链接:http://web.mit.edu/fwtools_v3.1.0/www/H5.intro.html#Intro-TOC
该文章主要介绍HDF5数据模块和编程模块。 作为入门级别的,快速上手文档,HDF5简介希望为您提供足够的信息,让您对HDF5如何工作和使用的基本了解。 如果您了解当前版本的HDF,将使您在接下来的文章阅读更加顺利,但这不是必需的。 HDF5文档中提供了实际使用HDF5所需的更全面的信息。 可用的文件包括:
- HDF5 User’s Guide. 在适当的情况下,本简介将参考“用户指南”的具体章节。
- HDF5 Reference Manual.
- 什么是HDF5
HDF5是一种全新的分层数据格式产品,由数据格式规范和支持库实现组成。HDF5旨在解决较旧的HDF产品的一些限制,满足现代系统和应用需求。
我们鼓励您查看HDF5,格式和库,并向我们提供有关您喜欢或不喜欢的反馈,以及您希望添加的新功能。
为什么HDF5?
HDF5的发展受到老HDF格式和库中的一些限制。 其中一些限制是:
- 单个文件不能存储超过20,000个复杂对象,单个文件不能大于2 GB。
- 数据模型不太一致,所需的对象类型更多,数据类型也受到限制。
- 库的源码过于复杂,不支持并行I / O,而且在线程应用中难以使用。
HDF5包括以下改进:
- 一种新的文件格式旨在解决HDF4.x的一些缺陷,特别是需要存储更大的文件和每个文件更多的对象。
- 一个更简单,更全面的数据模型,只包含两个基本结构:记录结构的多维数组和分组结构。
- 一个更简单,更好设计的库和API,改进了对并行I / O,线程和现代系统和应用程序强加的其他要求的支持。
注意:HDF和HDF5是两种不同的产品。 HDF是一种数据格式,最早在20世纪80年代开发,目前在版本4.x(HDF Release 4.x)中。 HDF5是1998年首次发布的新数据格式,旨在更好地满足科学计算不断增长的需求,并更好地利用计算系统日益增长的能力。 HDF5目前在版本1.x(HDF5版本1.x)。
当前版本的更改
HDF5在当前版本和以前主要版本之间的更改详细列表可以在RELEASE.txt文件中找到,在“HDF5应用程序开发人员指南”的文档“HDF5 Software Changes from Release to Release”中的高亮摘要。
2. HDF5文件组织和数据模型
HDF5文件以分层结构组织,其中包含两个主要结构:组和数据集。
- HDF5 group:分组结构包含零个或多个组或数据集的实例,以及支持元数据(metadata)。
- HDF5 dataset:数据元素的多维数组,以及支持元数据。
使用组和组成员在许多方面类似于在UNIX中使用目录和文件。 与UNIX目录和文件一样,HDF5文件中的对象通常通过给出其完整(或绝对)路径名来描述。
/表示根组。
/ foo表示根组中名为foo的成员。
/ foo / zoo表示组foo的成员,而组foo则是根组的成员。
任何HDF5组或数据集可能具有关联的属性列表。 HDF5属性是用户定义的HDF5结构,提供有关HDF5对象的额外信息。 下面更详细地描述属性。
HDF5 Groups
HDF5组是包含零个或多个HDF5对象的结构。 一个组包含两部分:
- A group header(组头),其中包含组名和组属性列表。
- A group symbol table(组符号表),它是属于该组的HDF5对象的列表。
HDF5 Datasets
数据集存储在文件中,分为两部分:标题和数据数组。 标题包含解释数据集的数组部分所需的信息,以及描述或注释数据集的元数据(或指向元数据的指针)。 标题信息包括对象的名称,维度,数字类型,有关数据本身存储在磁盘上的信息,以及用于加速访问数据集或维护文件完整性的库的其他信息。任何标题中有四个基本信息类别: name , datatype , dataspace , and storage layout : name:数据集名称是一系列字母数字的ASCII字符。 Datatype:HDF5可以定义许多不同类型的数据类型。 数据类型有两类:原子数据类型和复合数据类型。 原子数据类型也可以是系统特定的,也可以是NATIVE,所有数据类型都可以命名:
- 原子数据类型是在数据类型接口级别不可再分的数据类型,例如整数和浮点数。
- NATIVE数据类型是原子数据类型的特定于系统的实例。
- 复合数据类型由原子数据类型组成。
- 命名的数据类型是原子或复合数据类型,它们被专门指定为跨数据集共享。
原子类包括整数,浮点数,字符串,位字段和位字段。 (注意:只有整数,浮点数和字符串类在当前实现中可用。)
整数类型的属性包括size,order(endian-ness)和signed-ness(signed / unsigned)。
浮点类型的属性包括指数和尾数的大小和位置以及符号位的位置。
当前实现中支持的数据类型有:
- 整数数据类型:小和大端格式的8位,16位,32位和64位整数
- 浮点数:IEEE 32位和64位浮点数,以小和大端格式
- 引用
- 字符串
NATIVE架构的基本名称不遵循与其他规则相同的规则。 相反,本机类型名称与C类型名称相似。 下图显示了几个例子。
Examples of Native Datatypes and Corresponding C Types
| Example | Corresponding C Type |
H5T_NATIVE_CHAR | signed char |
H5T_NATIVE_UCHAR | unsigned char |
H5T_NATIVE_SHORT | short |
H5T_NATIVE_USHORT | unsigned short |
H5T_NATIVE_INT | int |
H5T_NATIVE_UINT | unsigned |
H5T_NATIVE_LONG | long |
H5T_NATIVE_ULONG | unsigned long |
H5T_NATIVE_LLONG | long long |
H5T_NATIVE_ULLONG | unsigned long long |
H5T_NATIVE_FLOAT | float |
H5T_NATIVE_DOUBLE | double |
H5T_NATIVE_LDOUBLE | long double |
H5T_NATIVE_HSIZE | hsize_t |
H5T_NATIVE_HSSIZE | hssize_t |
H5T_NATIVE_HERR | herr_t |
H5T_NATIVE_HBOOL | hbool_t |
有关详细信息,请参阅HDF用户指南中的 数据类型。
复合数据类型是将多个数据类型的集合表示为单个单元的复合数据类型,类似于C中的结构的复合数据类型。复合数据类型的部分称为成员。 复合数据类型的成员可以是任何数据类型,包括另一个复合数据类型。 可以从整体类型读取复合类型的成员。
命名数据类型 通常每个数据集都有自己的数据类型,但有时我们可能希望在多个数据集之间共享一个数据类型。 这可以使用命名数据类型完成。 命名数据类型独立于任何数据集存储在文件中,并由具有该数据类型的所有数据集引用。 命名的数据类型可能具有关联的属性列表。 有关详细信息,请参阅HDF用户指南中的 数据类型。
数据空间。 数据集数据空间描述数据集的维度。 数据集的维度可以是固定的(不变的),或者它们可以是无限的,这意味着它们是可扩展的(即它们可以变大)。
数据空间的属性由数组的 等级(维数),数组的实际维度以及数组的维数的最大大小组成。 对于固定维数据集,实际大小与维度的最大大小相同。 当维度无限制时,最大大小设置为值H5P_UNLIMITED。 (下面的例子显示了如何创建可扩展数据集。)
数据空间还可以描述数据集的部分,使得可以对选择进行部分I / O操作。 数据空间借口(H5S)支持选择。 给定一个n维数据集,目前有四种方法进行部分选择:
- 选择一个逻辑上连续的n维hyperslab。
- 选择一个不连续的hyperslab组成的元素或元素块(hyperslab)等间距。
- 选择hyperslab联合。
- 选择独立点列表。
有关详细信息,请参阅HDF用户指南中的 数据空间。
Storage layout.(存储布局)
HDF5格式可以以各种方式存储数据。 默认存储布局格式是连续的,这意味着数据以与内存中组织的线性方式相同的方式进行存储。 目前为HDF5定义了另外两种存储布局格式:紧凑,分块。 将来可能会添加其他存储布局。紧凑型存储:当数据量很小并且可以直接存储在对象头中时使用。 (注意:本版本不支持紧凑型存储。)
分块存储:将数据集分成相同大小的“块”,分别存储。 分块有三个重要的好处。
- 即使当要选择的子集与数据集的正常存储顺序正交时,也可以在访问数据集的子集时实现良好的性能。
- 它可以压缩大型数据集,并在访问数据集的子集时仍能获得良好的性能。
- 它可以有效地在任何方向上扩展数据集的维度。
HDF5属性(HDF5 Attributes)
属性是附加到主数据集,组或命名数据类型的小型命名数据集。 属性可用于描述数据集或组的性质和/或预期用途。 一个属性有两个部分:(1)属性名字(2)值。 值部分包含相同数据类型的一个或多个数据条目。属性API(H5A)用于读取或写入属性信息。 访问属性时,可以通过名称或索引值来标识它们。 使用索引值可以遍历与给定对象相关联的所有属性。
HDF5格式和I / O库的设计假设属性是小数据集。 它们总是存储在它们附加到的对象的对象头中。 因此,大型数据集不应作为属性存储。 库没有定义多大叫做“大”,取决于用户的解释。 (具有元数据的大型数据集可以作为辅助数据集存储在具有主数据集的组中)。
有关详细信息,请参阅HDF用户指南中的 属性。
The File as Written to Media(写入媒体的文件)
本节将介绍的是,文件写入磁盘或其他存储介质时,如何查看低级别的元素,用户一般比较熟悉高级别的元素,本文将介绍低级别的元素和用户使用的高级别的元素之间的关系,HDF5 API通常仅向用户公开高级元素; 低级元素常常被隐藏。 本简介的其余部分不会对此部分进行介绍。 磁盘上HDF5文件的格式包含了HDF4和AIO文件格式的几个关键思想,并解决了其中的一些缺点。 新格式比HDF4格式更自我(self-describing)描述,并且更均匀地应用于文件中的数据对象。HDF5文件作为有向图显示给用户。 该图的节点是由HDF5 API公开的较高级别的HDF5对象组成:
- Groups
- Datasets
- Datatypes
- Dataspaces
- A super block
- B-tree nodes (containing either symbol nodes or raw data chunks)
- Object headers
- Collections
- Local heaps
- Free space
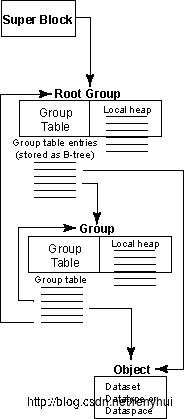 图1. HDF5根组,其他组和对象之间的关系
图1. HDF5根组,其他组和对象之间的关系
 图2 HDF5对象 - 数据集,数据类型或数据空间
HDF5库使用这些较低级别的对象来表示通过API向用户或应用程序呈现的较高级对象。 例如,一个组是一个对象头,它包含指向本地堆的消息和指向符号节点的B-tree。 数据集是一个对象头,其中包含描述数据类型,空间,布局,过滤器,外部文件,填充值等的消息,布局消息指向原始数据块或指向原始数据块的B树。
图2 HDF5对象 - 数据集,数据类型或数据空间
HDF5库使用这些较低级别的对象来表示通过API向用户或应用程序呈现的较高级对象。 例如,一个组是一个对象头,它包含指向本地堆的消息和指向符号节点的B-tree。 数据集是一个对象头,其中包含描述数据类型,空间,布局,过滤器,外部文件,填充值等的消息,布局消息指向原始数据块或指向原始数据块的B树。
有关更多信息,请参阅HDF5文件 格式规范。
3. HDF5应用编程接口(API)
目前的HDF5 API仅在C中实现。该API提供了创建HDF5文件的程序,创建和编写组,数据集及其属性,以及从HDF5文件读取组,数据集及其属性。命名约定
HDF 5库中的所有C例程都以H5 *形式的前缀开头,其中*是一个单字母,表示要执行操作的对象:- H5F: File-level access routines. 文件级别的访问程序
例如:H5Fopen, 表示打开一个hdf5文件 - H5G: Group functions, 用于在对象组上创建和操作
例如:H5Gset,将工作组设置为指定的组。 - H5T: DataType functions, 用于创建和操作简单和复合数据类型,以用作数据数组中的元素。
例如:H5Tcopy,它创建了现有数据类型的副本 - H5S: DataSpace functions, 它创建和操作数据空间,数据数组的元素存储在该数据空间。
例如:H5Screate_simple, 它创建简单的数据空间。 - H5D: Dataset functions, 它操纵数据集中的数据,并确定数据将如何存储在文件中。
例如:H5Dread, 它将数据集的全部或部分读入内存的缓冲区。 - H5P: Property list functions,用于操作对象创建和访问属性。
例如:H5Pset_chunk, 它设置一个块的维度和大小。 - H5A: Attribute access and manipulating routines. 属性访问和操作程序。
例如:H5Aget_name, 返回属性的名称。 - H5Z: Compression registration routine. 压缩注册程序。
例如:H5Zregister, 它注册了用于HDF5库的新的压缩和解压缩功能。 - H5E: Error handling routines. 错误处理程序。
例如:H5Eprint, 它打印当前的错误堆栈。 - H5R: Reference routines. 引用例程
例如:H5Rcreate, which creates a reference.这创建了一个引用。 - H5I: Identifier routine. 标识符例程
例如:H5Iget_type, 它返回对象的类型。
Include Files
任何HDF5程序都应包含一些数字定义和声明。 这些定义和声明包含在几个包含文件中。 主要的include文件是hdf5.h. 此文件包含您的程序可能需要的所有其他文件。 确保在使用HDF5库的任何程序中包含hdf5.h。Programming Models
在本节中,我们将介绍如何对文件进行一些基本操作,包括如何编写- Create a file.
- Create and initialize a dataset.
- Discard objects when they are no longer needed.
- Write a dataset to a new file.
- Obtain information about a dataset.
- Read a portion of a dataset.
- Create and write compound datatypes.
- Create and write extendible datasets.
- Create and populate groups.
- Work with attributes.
如何创建HDF5文件
此编程模块显示如何创建文件以及如何关闭文件。- 创建文件
- 关闭文件
hid_t file; /* identifier */
/*
* Create a new file using H5ACC_TRUNC access,
* default file creation properties, and default file
* access properties.
* Then close the file.
*/
file = H5Fcreate(FILE, H5ACC_TRUNC, H5P_DEFAULT, H5P_DEFAULT);
status = H5Fclose(file); 如何创建和初始化用于写入文件的数据集的基本组件
回想一下,数据类型和维度(数据空间)是独立的对象,它们与可能附加到的任何数据集分开创建。 因此,数据集的创建至少需要数据类型,维度和数据集的单独定义。 因此,要创建数据集,需要采取以下步骤:- 为要写入的数据集创建和初始化数据空间。
- 定义要写入的数据集的数据类型。
- 创建并初始化数据集本身。
hid_t dataset, datatype, dataspace; /* declare identifiers */
/*
* Create dataspace: Describe the size of the array and
* create the data space for fixed size dataset.
*/
dimsf[0] = NX;
dimsf[1] = NY;
dataspace = H5Screate_simple(RANK, dimsf, NULL);
/*
* Define datatype for the data in the file.
* We will store little endian integer numbers.小端整型数据
*/
datatype = H5Tcopy(H5T_NATIVE_INT);
status = H5Tset_order(datatype, H5T_ORDER_LE);
/*
* Create a new dataset within the file using defined
* dataspace and datatype and default dataset creation
* properties.
* NOTE: H5T_NATIVE_INT can be used as datatype if conversion
* to little endian is not needed.
*/
dataset = H5Dcreate(file, DATASETNAME, datatype, dataspace, H5P_DEFAULT);当不再需要对象时如何丢弃
数据类型,数据空间和数据集对象一旦程序不再需要,就应该被释放。 由于每个都是独立的对象,所以必须单独释放(或关闭)。 以下代码行关闭了上一节中创建的数据类型,数据空间和数据集。H5Tclose(datatype);
H5Dclose(dataset);
H5Sclose(dataspace);如何将数据集写入新文件
在定义了数据类型,数据集和数据空间参数之后,通过调用H5Dwrite来写出数据。/*
* Write the data to the dataset using default transfer
* properties.使用默认传输属性将数据写入数据集。
*/
status = H5Dwrite(dataset, H5T_NATIVE_INT, H5S_ALL, H5S_ALL,
H5P_DEFAULT, data);示例1包含创建文件和数据集的程序,并将数据集写入文件。
/*
* This example writes data to the HDF5 file.
* Data conversion is performed during write operation.
*/
#include
#define FILE "SDS.h5"
#define DATASETNAME "IntArray"
#define NX 5 /* dataset dimensions */
#define NY 6
#define RANK 2
int
main (void)
hid_t file, dataset; /* file and dataset handles */
hid_t datatype, dataspace; /* handles */
hsize_t dimsf[2]; /* dataset dimensions */
herr_t status;
int data[NX][NY]; /* data to write */
int i, j;
/*
* Data and output buffer initialization.
*/
for (j = 0; j < NX; j++)
for (i = 0; i < NY; i++)
data[j][i] = i + j;
/*
* 0 1 2 3 4 5
* 1 2 3 4 5 6
* 2 3 4 5 6 7
* 3 4 5 6 7 8
* 4 5 6 7 8 9
*/
/*
* Create a new file using H5F_ACC_TRUNC access,
* default file creation properties, and default file
* access properties.
*/
file = H5Fcreate(FILE, H5F_ACC_TRUNC, H5P_DEFAULT, H5P_DEFAULT);
/*
* Describe the size of the array and create the data space for fixed
* size dataset.
*/
dimsf[0] = NX;
dimsf[1] = NY;
dataspace = H5Screate_simple(RANK, dimsf, NULL);
/*
* Define datatype for the data in the file.
* We will store little endian INT numbers.
*/
datatype = H5Tcopy(H5T_NATIVE_INT);
status = H5Tset_order(datatype, H5T_ORDER_LE);
/*
* Create a new dataset within the file using defined dataspace and
* datatype and default dataset creation properties.
*/
dataset = H5Dcreate(file, DATASETNAME, datatype, dataspace,
H5P_DEFAULT);
/*
* Write the data to the dataset using default transfer properties.
*/
status = H5Dwrite(dataset, H5T_NATIVE_INT, H5S_ALL, H5S_ALL,
H5P_DEFAULT, data);
/*
* Close/release resources.
*/
H5Sclose(dataspace);
H5Tclose(datatype);
H5Dclose(dataset);
H5Fclose(file);
return 0;
获取有关数据集的信息
通常需要查询文件以获取有关数据集的信息。 例如,我们经常需要知道与数据集相关联的数据类型,以及数据空间信息(例如等级和维度)。 有几个“获取”例程用于获取此信息。 以下代码段说明了我们如何获得这种信息:/*
* Get datatype and dataspace identifiers and then query
* dataset class, order, size, rank and dimensions.
*/
datatype = H5Dget_type(dataset); /* datatype identifier */
class = H5Tget_class(datatype);
if (class == H5T_INTEGER) printf("Data set has INTEGER type \\n");
order = H5Tget_order(datatype);
if (order == H5T_ORDER_LE) printf("Little endian order \\n");
size = H5Tget_size(datatype);
printf(" Data size is %d \\n", size);
dataspace = H5Dget_space(dataset); /* dataspace identifier */
rank = H5Sget_simple_extent_ndims(dataspace);
status_n = H5Sget_simple_extent_dims(dataspace, dims_out);
printf("rank %d, dimensions %d x %d \\n", rank, dims_out[0], dims_out[1]);读取和写入数据集的一部分
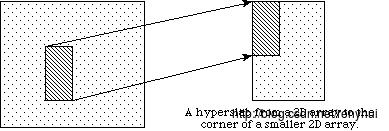
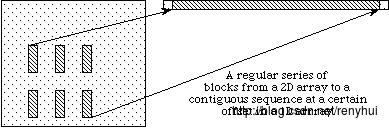
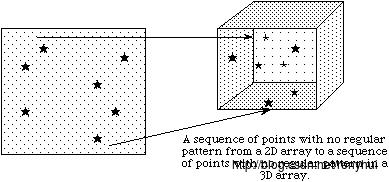
在之前的讨论中,我们描述了如何使用一个写(或读)操作访问整个数据集。 HDF5还支持在一个读/写操作中访问数据集的部分(或选择)。 目前选择仅限于hyperslabs,他们的合并,以及独立的点序列。 这两种类型的选择将在以下部分中讨论。 选择读取/写入的几个示例情况如下图所示。
a
 b
b
c

d

在实施例(a)单根hyperslab从在文件中的二维阵列的中间读取并存储在存储器中的一个较小的两维阵列的角落。 在(b)中,从文件中的二维数组中读取一系列块,并作为存储器中的一维数组中某个偏移量的连续序列值存储。 在(c)中,从文件中的二维数组中读取没有规则图案的点序列,并将其存储为存储器中三维数组中没有规则图案的点序列。在(d)中在文件数据空间hyperslabs的联合被读取,并且数据被存储在存储器数据空间hyperslabs的另一个结合。
如这些例子所示,每当我们对数据执行部分读/写操作时,必须提供以下信息:文件数据空间,文件数据空间选择,内存数据空间和内存数据空间选择。 在指定了所需的信息后,对HDF5读/写功能H5Dread(write)的单次调用完成对数据部分的实际读/写操作。
选择hyperslabs
Hyperslabs是数据集的一部分。 hyperslab选择可以是点的逻辑上连续的集合中的数据空间,或者它可以是在数据空间点或块的规则图案。 下图显示了8x12数据空间中定期间隔3x2的块的选择。Hyperslab selection
|
|
|
|
|
|
|
| ||||
|
|
|
|
|
|
|
| ||||
|
|
|
|
|
|
|
| ||||
|
|
|
|
|
|
|
| ||||
|
|
|
|
|
|
|
| ||||
|
|
|
|
|
|
|
| ||||
start: hyperslab的起始位置。 在示例中,start为(0,1)。stride: 要分离要选择的每个元素或块的元素数。 在示例中,步幅是(4,3)(每隔4行取一次,每隔3列取一次)。 如果stride参数设置为NULL,则每个维度中的步幅大小默认为1。count: 沿着每个维度选择的元素或块的数量。 在这个例子中,count是(2,4)。block:从数据空间中选择的块的大小。 在该示例中,块为(3,2)。 如果块参数设置为NULL,则块大小默认为每个维中的单个元素,就像块数组设置为全1。
数据复制的顺序是什么?
当执行实际I / O时,默认情况下,数据值将从一个数据空间复制到另一个数据空间,即所谓的行主或C顺序。 也就是说,假设第一维度变化最慢,第二维度倒数第二慢,等等。没有步长或块的例子。
假设我们想从数据集中的元素<1,2>开始的文件中的数据集中读取一个3x4超级数据(hyperslab )。 为了做到这一点,我们必须创建一个数据空间,描述文件中数据集的总体等级和维数,以及我们从该数据集中提取的hyperslab 的位置和大小。 以下代码说明了在文件数据空间中选择超文本。/*
* Define file dataspace.
*/
dataspace = H5Dget_space(dataset); /* dataspace identifier */
rank = H5Sget_simple_extent_ndims(dataspace);
status_n = H5Sget_simple_extent_dims(dataspace, dims_out, NULL);
/*
* Define hyperslab in the dataset.
*/
offset[0] = 1;
offset[1] = 2;
count[0] = 3;
count[1] = 4;
status = H5Sselect_hyperslab(dataspace, H5S_SELECT_SET, offset, NULL,
count, NULL);请注意,我们必须描述两件事情:内存数组的维度,以及我们希望读取的hyperslab的大小和位置。以下代码说明了如何完成此操作。
/*
* Define memory dataspace.
*/
dimsm[0] = 7;
dimsm[1] = 7;
dimsm[2] = 3;
memspace = H5Screate_simple(RANK_OUT,dimsm,NULL);
/*
* Define memory hyperslab.
*/
offset_out[0] = 3;
offset_out[1] = 0;
offset_out[2] = 0;
count_out[0] = 3;
count_out[1] = 4;
count_out[2] = 1;
status = H5Sselect_hyperslab(memspace, H5S_SELECT_SET, offset_out, NULL,
count_out, NULL);
/*Example 2. How to read a hyperslab from file into memory.
This example reads a hyperslab from a 2-d HDF5 dataset into a 3-d dataset in memory.
/*
* This example reads hyperslab from the SDS.h5 file
* created by h5_write.c program into two-dimensional
* plane of the three-dimensional array.
* Information about dataset in the SDS.h5 file is obtained.
*/
#include "hdf5.h"
#define FILE "SDS.h5"
#define DATASETNAME "IntArray"
#define NX_SUB 3 /* hyperslab dimensions */
#define NY_SUB 4
#define NX 7 /* output buffer dimensions */
#define NY 7
#define NZ 3
#define RANK 2
#define RANK_OUT 3
int
main (void)
hid_t file, dataset; /* handles */
hid_t datatype, dataspace;
hid_t memspace;
H5T_class_t class; /* datatype class */
H5T_order_t order; /* data order */
size_t size; /*
* size of the data element
* stored in file
*/
hsize_t dimsm[3]; /* memory space dimensions */
hsize_t dims_out[2]; /* dataset dimensions */
herr_t status;
int data_out[NX][NY][NZ ]; /* output buffer */
hsize_t count[2]; /* size of the hyperslab in the file */
hsize_t offset[2]; /* hyperslab offset in the file */
hsize_t count_out[3]; /* size of the hyperslab in memory */
hsize_t offset_out[3]; /* hyperslab offset in memory */
int i, j, k, status_n, rank;
for (j = 0; j < NX; j++)
for (i = 0; i < NY; i++)
for (k = 0; k < NZ ; k++)
data_out[j][i][k] = 0;
/*
* Open the file and the dataset.
*/
file = H5Fopen(FILE, H5F_ACC_RDONLY, H5P_DEFAULT);
dataset = H5Dopen(file, DATASETNAME);
/*
* Get datatype and dataspace handles and then query
* dataset class, order, size, rank and dimensions.
*/
datatype = H5Dget_type(dataset); /* datatype handle */
class = H5Tget_class(datatype);
if (class == H5T_INTEGER) printf("Data set has INTEGER type \\n");
order = H5Tget_order(datatype);
if (order == H5T_ORDER_LE) printf("Little endian order \\n");
size = H5Tget_size(datatype);
printf(" Data size is %d \\n", size);
dataspace = H5Dget_space(dataset); /* dataspace handle */
rank = H5Sget_simple_extent_ndims(dataspace);
status_n = H5Sget_simple_extent_dims(dataspace, dims_out, NULL);
printf("rank %d, dimensions %lu x %lu \\n", rank,
(unsigned long)(dims_out[0]), (unsigned long)(dims_out[1]));
/*
* Define hyperslab in the dataset.
*/
offset[0] = 1;
offset[1] = 2;
count[0] = NX_SUB;
count[1] = NY_SUB;
status = H5Sselect_hyperslab(dataspace, H5S_SELECT_SET, offset, NULL,
count, NULL);
/*
* Define the memory dataspace.
*/
dimsm[0] = NX;
dimsm[1] = NY;
dimsm[2] = NZ ;
memspace = H5Screate_simple(RANK_OUT,dimsm,NULL);
/*
* Define memory hyperslab.
*/
offset_out[0] = 3;
offset_out[1] = 0;
offset_out[2] = 0;
count_out[0] = NX_SUB;
count_out[1] = NY_SUB;
count_out[2] = 1;
status = H5Sselect_hyperslab(memspace, H5S_SELECT_SET, offset_out, NULL,
count_out, NULL);
/*
* Read data from hyperslab in the file into the hyperslab in
* memory and display.
*/
status = H5Dread(dataset, H5T_NATIVE_INT, memspace, dataspace,
H5P_DEFAULT, data_out);
for (j = 0; j < NX; j++)
for (i = 0; i < NY; i++) printf("%d ", data_out[j][i][0]);
printf("\\n");
/*
* 0 0 0 0 0 0 0
* 0 0 0 0 0 0 0
* 0 0 0 0 0 0 0
* 3 4 5 6 0 0 0
* 4 5 6 7 0 0 0
* 5 6 7 8 0 0 0
* 0 0 0 0 0 0 0
*/
/*
* Close/release resources.
*/
H5Tclose(datatype);
H5Dclose(dataset);
H5Sclose(dataspace);
H5Sclose(memspace);
H5Fclose(file);
return 0;
示例与步长和块
考虑上述8x12数据空间,其中我们选择了8个3x2块。 假设我们填写这八个块。Hyperslab selection
|
|
|
|
|
|
|
| ||||
|
|
|
|
|
|
|
| ||||
|
|
|
|
|
|
|
| ||||
|
|
|
|
|
|
|
| ||||
|
|
|
|
|
|
|
| ||||
|
|
|
|
|
|
|
| ||||
这个hyperslab 具有以下参数:start =(0,1),stride =(4,3),count =(2,4),block =(3,2)。
假设内存中的源数据空间是这个50元素的一维数组,称为vector:
A 50-element one dimensional array
|
|
|
|
|
|
|
|
|
|
|
|
以下代码将从向量中写入48个元素到我们的文件数据集,从向量中的第二个元素开始。
/* Select hyperslab for the dataset in the file, using 3x2 blocks, (4,3) stride * (2,4) count starting at the position (0,1). */ start[0] = 0; start[1] = 1; stride[0] = 4; stride[1] = 3; count[0] = 2; count[1] = 4; block[0] = 3; block[1] = 2; ret = H5Sselect_hyperslab(fid, H5S_SELECT_SET, start, stride, count, block); /* * Create dataspace for the first dataset. */ mid1 = H5Screate_simple(MSPACE1_RANK, dim1, NULL); /* * Select hyperslab. * We will use 48 elements of the vector buffer starting at the second element. * Selected elements are 1 2 3 . . . 48 */ start[0] = 1; stride[0] = 1; count[0] = 48; block[0] = 1; ret = H5Sselect_hyperslab(mid1, H5S_SELECT_SET, start, stride, count, block); /* * Write selection from the vector buffer to the dataset in the file. * ret = H5Dwrite(dataset, H5T_NATIVE_INT, midd1, fid, H5P_DEFAULT, vector)这些操作后,文件数据空间将具有以下值。