Hadoop/Spark开发环境配置
Posted 成平艺君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop/Spark开发环境配置相关的知识,希望对你有一定的参考价值。
修改hostname bogon 为localhost
查看ip地址
[training@bogon ~]$ sudo hostname localhost
[training@bogon ~]$ hostname
执行结果
此时python 版本为2.7

将python版本升级至3.0及以上
一、 下载欲升级python版本 Python-3.4.5,将包放于本机与虚似机的共享目录下,上传至虚似机的opt目录下
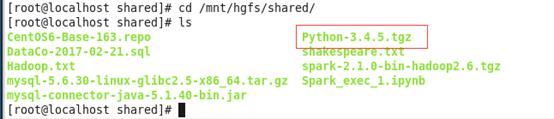

二、 解压

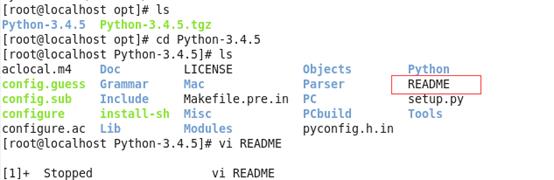
三、阅读README安装步骤,根据实验步骤向下执行
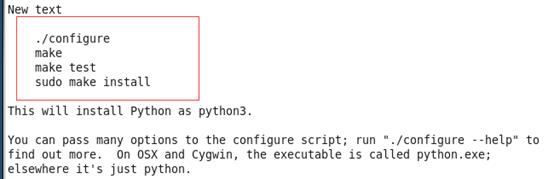
执行完成后出现Succssfully,恭喜你!安装成功!

四、配置环境变量,让Spark用到新版本的Python。编辑 ~training/.bashrc,添加如下内容,并在相应位置下载ipython3


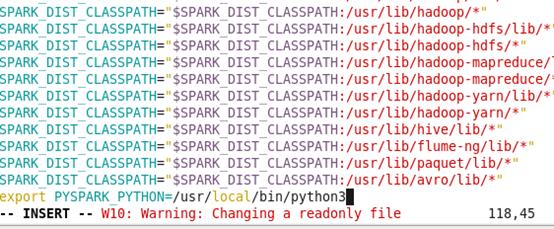
五、 修改 spark-evn.sh 配置文件中的对应参数PYSPARK_PYTHON,此文件一般在 /etc/spark/conf 或者Spark 安装目录的conf 目录下。
六、 Python和ipython都升级完成,但是spark的版本是1.6的,下面我们开始升级spark
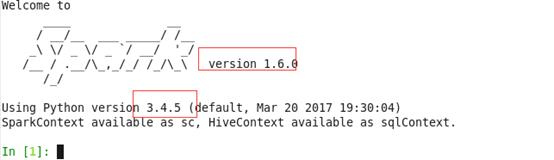
此时我们已经将python升级到3.4.5,但是spark的版本没有改变!!
升级spark
一、将共享文件夹中的要升级的spark版本到opt目录下
二、解压
[training@localhost opt]$ tar -zvxf spark-2.1.0-bin-hadoop2.6.tgz
[training@localhost conf]$ ls /opt/
spark-2.1.0-bin-hadoop2.6.tgz spark-2.1.0-bin-hadoop2.6
三、修改新版Spark配置文件,将Hadoop、hive 配置文件拷贝到Spark配置文件目录中:
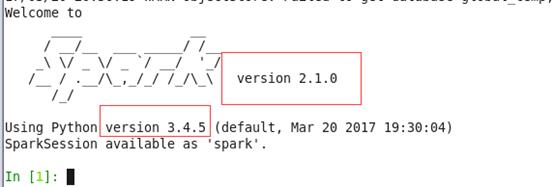
四、安装成功后的页面
五、虽然下载成功了,但是对于一些日常代码的编写与保存不好,所以我们需要下载一个notebook
运行界面
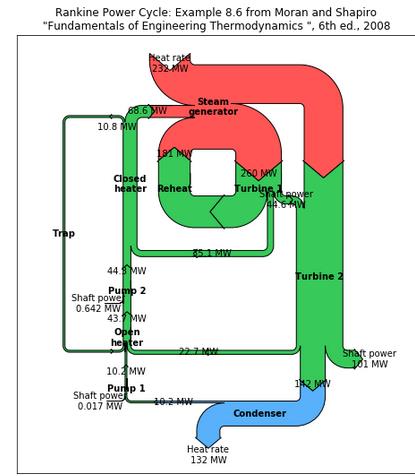
安装matplotlib 库

测试matplotlib 库
import matplotlib.pyplot as plt
from matplotlib.sankey import Sankey
fig = plt.figure(figsize=(8, 9))
ax = fig.add_subplot(1, 1, 1, xticks=[], yticks=[],
title="Rankine Power Cycle: Example 8.6 from Moran and "
"Shapiro\\n\\x22Fundamentals of Engineering Thermodynamics "
"\\x22, 6th ed., 2008")
Hdot = [260.431, 35.078, 180.794, 221.115, 22.700,
142.361, 10.193, 10.210, 43.670, 44.312,
68.631, 10.758, 10.758, 0.017, 0.642,
232.121, 44.559, 100.613, 132.168] # MW
sankey = Sankey(ax=ax, format=\'%.3G\', unit=\' MW\', gap=0.5, scale=1.0/Hdot[0])
sankey.add(patchlabel=\'\\n\\nPump 1\', rotation=90, facecolor=\'#37c959\',
flows=[Hdot[13], Hdot[6], -Hdot[7]],
labels=[\'Shaft power\', \'\', None],
pathlengths=[0.4, 0.883, 0.25],
orientations=[1, -1, 0])
sankey.add(patchlabel=\'\\n\\nOpen\\nheater\', facecolor=\'#37c959\',
flows=[Hdot[11], Hdot[7], Hdot[4], -Hdot[8]],
labels=[None, \'\', None, None],
pathlengths=[0.25, 0.25, 1.93, 0.25],
orientations=[1, 0, -1, 0], prior=0, connect=(2, 1))
sankey.add(patchlabel=\'\\n\\nPump 2\', facecolor=\'#37c959\',
flows=[Hdot[14], Hdot[8], -Hdot[9]],
labels=[\'Shaft power\', \'\', None],
pathlengths=[0.4, 0.25, 0.25],
orientations=[1, 0, 0], prior=1, connect=(3, 1))
sankey.add(patchlabel=\'Closed\\nheater\', trunklength=2.914, fc=\'#37c959\',
flows=[Hdot[9], Hdot[1], -Hdot[11], -Hdot[10]],
pathlengths=[0.25, 1.543, 0.25, 0.25],
labels=[\'\', \'\', None, None],
orientations=[0, -1, 1, -1], prior=2, connect=(2, 0))
sankey.add(patchlabel=\'Trap\', facecolor=\'#37c959\', trunklength=5.102,
flows=[Hdot[11], -Hdot[12]],
labels=[\'\\n\', None],
pathlengths=[1.0, 1.01],
orientations=[1, 1], prior=3, connect=(2, 0))
sankey.add(patchlabel=\'Steam\\ngenerator\', facecolor=\'#ff5555\',
flows=[Hdot[15], Hdot[10], Hdot[2], -Hdot[3], -Hdot[0]],
labels=[\'Heat rate\', \'\', \'\', None, None],
pathlengths=0.25,
orientations=[1, 0, -1, -1, -1], prior=3, connect=(3, 1))
sankey.add(patchlabel=\'\\n\\n\\nTurbine 1\', facecolor=\'#37c959\',
flows=[Hdot[0], -Hdot[16], -Hdot[1], -Hdot[2]],
labels=[\'\', None, None, None],
pathlengths=[0.25, 0.153, 1.543, 0.25],
orientations=[0, 1, -1, -1], prior=5, connect=(4, 0))
sankey.add(patchlabel=\'\\n\\n\\nReheat\', facecolor=\'#37c959\',
flows=[Hdot[2], -Hdot[2]],
labels=[None, None],
pathlengths=[0.725, 0.25],
orientations=[-1, 0], prior=6, connect=(3, 0))
sankey.add(patchlabel=\'Turbine 2\', trunklength=3.212, facecolor=\'#37c959\',
flows=[Hdot[3], Hdot[16], -Hdot[5], -Hdot[4], -Hdot[17]],
labels=[None, \'Shaft power\', None, \'\', \'Shaft power\'],
pathlengths=[0.751, 0.15, 0.25, 1.93, 0.25],
orientations=[0, -1, 0, -1, 1], prior=6, connect=(1, 1))
sankey.add(patchlabel=\'Condenser\', facecolor=\'#58b1fa\', trunklength=1.764,
flows=[Hdot[5], -Hdot[18], -Hdot[6]],
labels=[\'\', \'Heat rate\', None],
pathlengths=[0.45, 0.25, 0.883],
orientations=[-1, 1, 0], prior=8, connect=(2, 0))
diagrams = sankey.finish()
for diagram in diagrams:
diagram.text.set_fontweight(\'bold\')
diagram.text.set_fontsize(\'10\')
for text in diagram.texts:
text.set_fontsize(\'10\')
# Notice that the explicit connections are handled automatically, but the
# implicit ones currently are not. The lengths of the paths and the trunks
# must be adjusted manually, and that is a bit tricky.
plt.show()
运行结果
以上是关于Hadoop/Spark开发环境配置的主要内容,如果未能解决你的问题,请参考以下文章