深度学习生成对抗网络GAN|GANWGANWGAN-UPCGANCycleGANDCGAN
Posted Lydia.na
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习生成对抗网络GAN|GANWGANWGAN-UPCGANCycleGANDCGAN相关的知识,希望对你有一定的参考价值。
文章目录
论文连接: 必读的10篇关于GAN的论文
| 方法 | 通俗含义 | |
|---|---|---|
| 对抗学习 | 找对手互怼 | GAN |
| 自监督学习 | 自己找标签学习 | GAN、word2vec |
| 弱监督学习 | 学校拧螺丝、工作造火箭 | CAM(可解释性分析) |
| 半监督学习 | 标签不够多、不够难、不够准 | |
| 知识蒸馏 | 找老师教我学习 | |
| 多模态学习 | 调动各类感官学习 | |
| 迁移学习 | 举一反三学习 | fine-tuning |
| 集成学习 | 三个臭皮匠学习 | |
| 联邦学习 | 用别人的学习资料学习 | 解决隐私计算问题 |
生成对抗网络理论基础:GAN、WGAN、Improved GAN。
一、Typical GAN
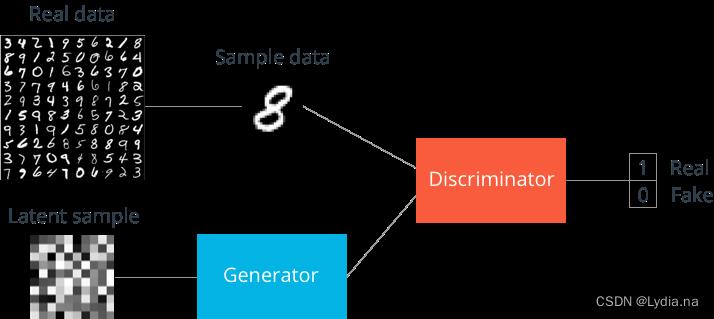
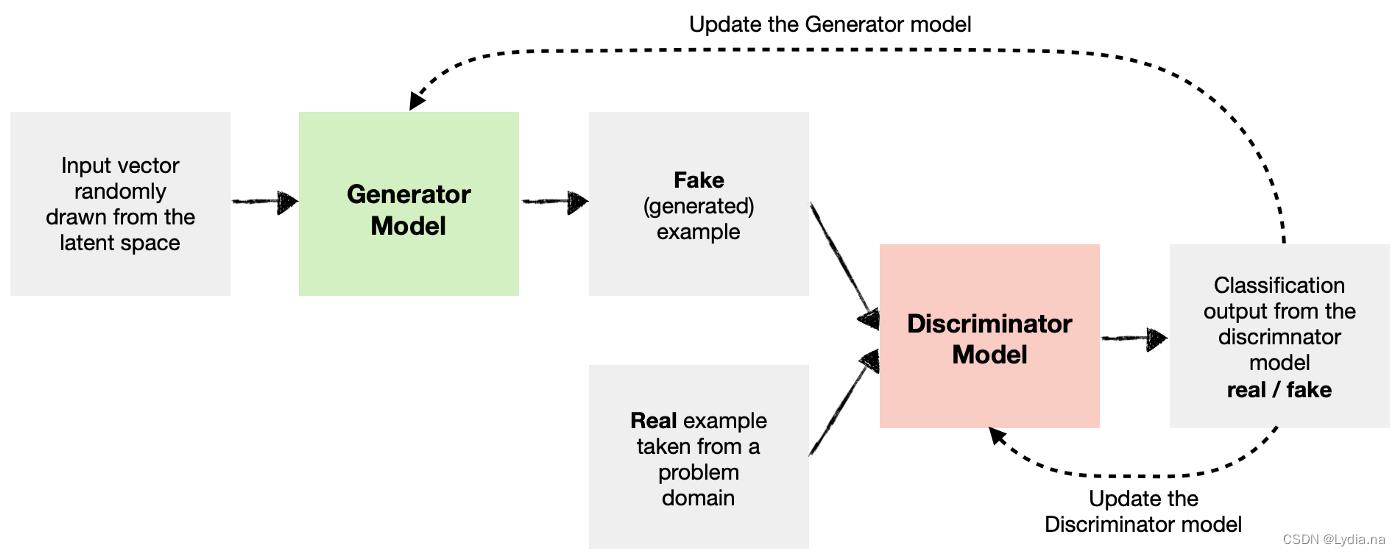
优化目标函数:
min
G
max
D
V
(
D
,
G
)
=
E
x
∼
p
d
a
t
a
(
x
)
[
l
o
g
D
(
x
)
]
+
E
z
∼
p
z
[
l
o
g
(
1
−
D
(
G
(
z
)
)
)
]
\\min_G\\max_DV(D,G)=\\mathbbE_x\\sim p_data(x)[logD(x)]+ \\mathbbE_z\\sim p_z[log(1-D(G(z)))]
GminDmaxV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz[log(1−D(G(z)))]
其中,G表示生成器,D表示判别器,data,x为真实样本的眼本空间和真实样本,z表示输入的噪声。
判别器的输出为
生成器G:
生成器G是为了生成与真实数据相差较小的数据,因此其目的是最小化目标函数,在训练G时控制判别器D保持不变,优化函数为:
min
G
E
z
∼
p
z
[
l
o
g
(
1
−
D
(
G
(
z
)
)
)
]
\\min_G\\mathbbE_z\\sim p_z[log(1-D(G(z)))]
GminEz∼pz[log(1−D(G(z)))]
若想使该函数最小,
D
(
G
(
z
)
)
)
=
1
D(G(z)))=1
D(G(z)))=1成立,意思为G希望判别器D将生成器生成的图片G(z)判别为真样本,骗过了判别器D。
判别器D:
在训练判别器D时,控制生成器G不变,更新D,优化函数为:
max
D
V
(
D
,
G
)
=
E
x
∼
p
d
a
t
a
(
x
)
[
l
o
g
D
(
x
)
]
+
E
z
∼
p
z
[
l
o
g
(
1
−
D
(
G
(
z
)
)
)
]
\\max_DV(D,G)=\\mathbbE_x\\sim p_data(x)[logD(x)]+ \\mathbbE_z\\sim p_z[log(1-D(G(z)))]
DmaxV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz[log(1−D(G(z)))]
若想使该函数最大,那么每一部分最大,由于必须保证判别器的输出在[0,1]之间。所以该函数最大,
D
(
x
)
=
1
D(x)=1
D(x)=1,
D
(
G
(
z
)
)
)
=
0
D(G(z)))=0
D(G(z)))=0。判别器希望判断出真实样本并且将生成的数据判别为假样本。
既然生成器的目标是最小化生成数据和真实数据之间的距离那么鉴别器就是最大化两者的距离,针对如何计算生成数据和真实数据之间的距离,引入了JS散度的概念来计算,事实上也可以看成是交叉熵乘一个负号。
二、WGAN
GAN,WGAN,WGAN-GP 通俗易懂的原理解释 这个博客写的很好,规避了复杂的数学公式,简单明了地介绍了三者之间的关系,值得学习。
解决了typcial GAN因为JS度量导致生成器G无法学习的问题。
使用JS的缺点: 生成数据跟真实数据之间,使用JS散度去度量这两个数据之间的距离,但是无论这两个距离是什么情况,只要不重叠,JS散度一直都是Log2,只有当这两个数据重合的时候,JS散度才为0。很显然当这两个分布不重叠的时候,二分类正确率却一直为100%,没有办法区别一个好的程度这样一个过程,所以这样就显得没有实际意义。
使用推土距离Wasserstein distance代替JS散度: 使得生成数据和真实数据无交集的时候不会出现像JS一样处于恒等值的方向,使得生成器会一直向好的地方发展而不是之间停止。

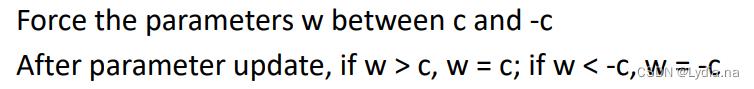
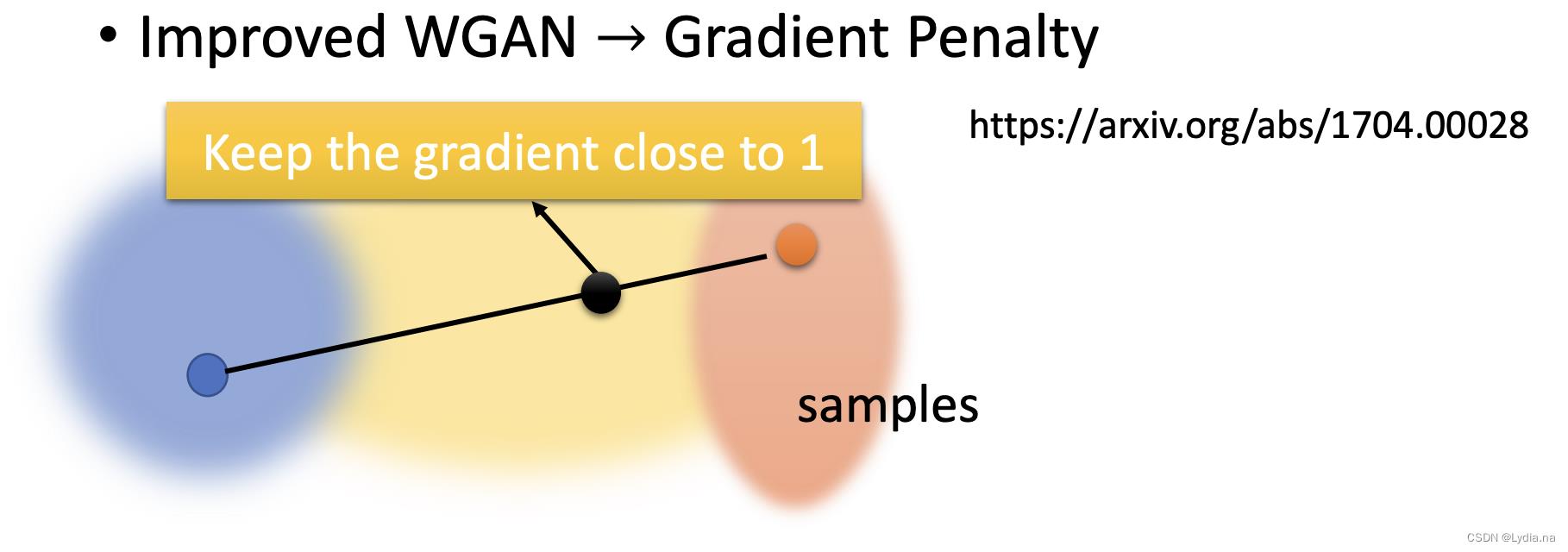
三、Improved GAN (WGAN-GP)
除了WGAN的权重修建✂️(weight clipping)策略以外,还有梯度惩罚策略。在损失函数中添加惩罚项。
四、Conditional GAN(CGAN)
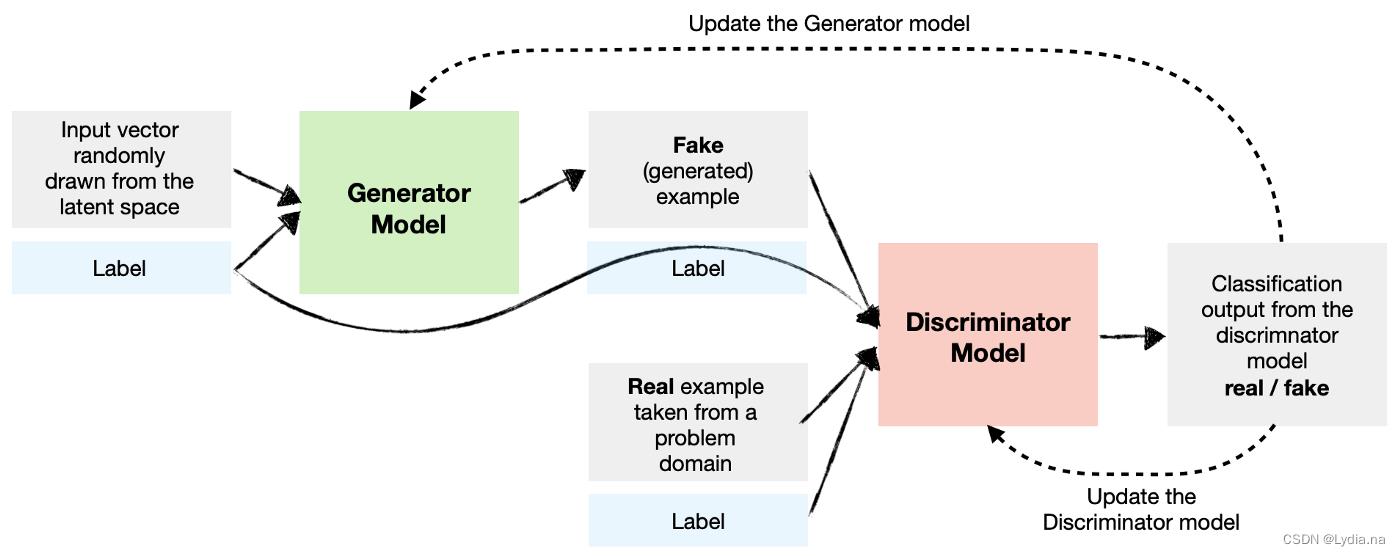
非条件GAN模型是只向生成器输入一个数据分布,根据该数据分布进行学习。而条件GAN模型在输入一个数据分布的同时额外输入一段向量规定生成的图像包含什么特征,这就是conditional GAN。
五、CycleGAN
CycleGAN属于无监督的条件GAN,可以解决不清楚输入和输出对应关系的问题。常见到的应用是风格转换。
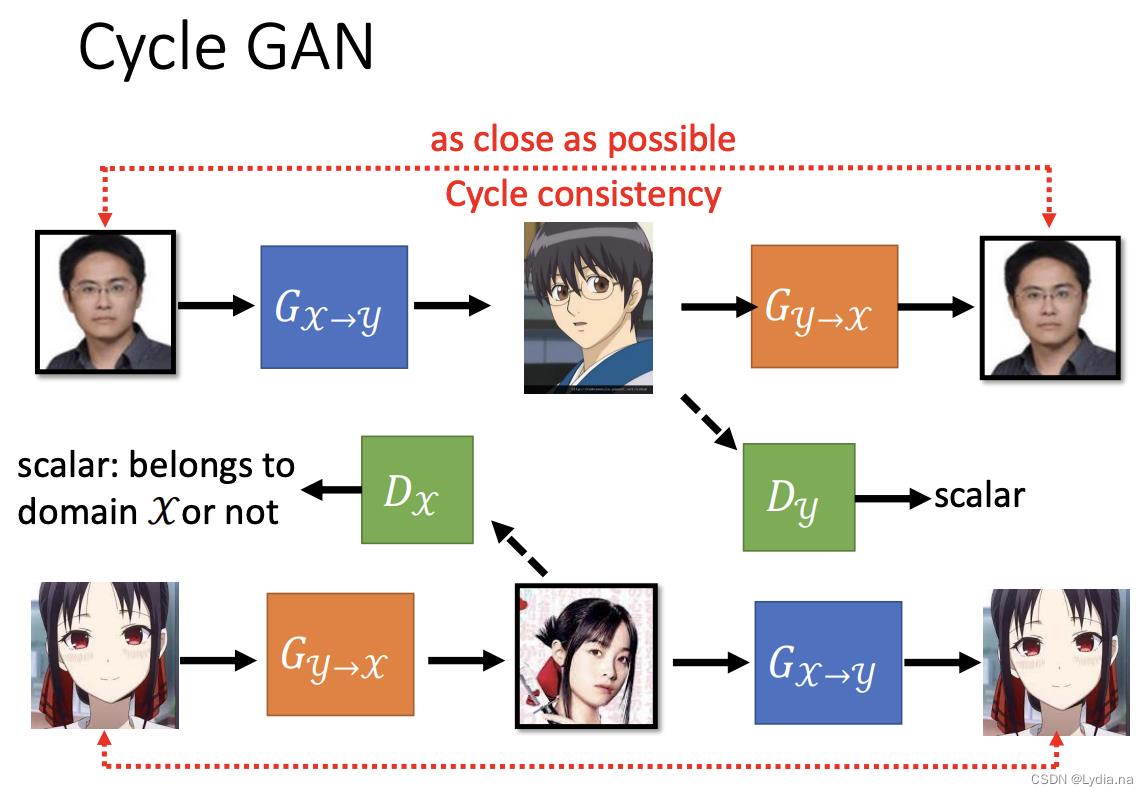
主要思想: 训练四个网络并形成一个Cycle输入一幅图像生成另一个风格图像再让生成图像生成回原来的图像风格,这样的一个形式就是CycleGAN的主要思想,事实上它在训练四个网络包括两个生成器和两个判别器
六、🌟DCGAN
生成器
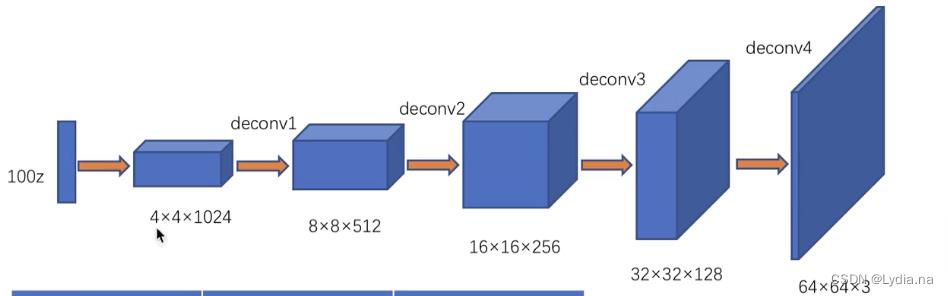
DCGAN的生成器网络结构相较于传统的GAN,DCGAN使用了卷积层代替全连接层,具有四个反卷积层,整个网络没有pooling层和上采样层,石景山使用了带步长(fractional-strided)的卷积/ 专置卷积(tansposed conv)代替了上采样,以增加训练的稳定性。
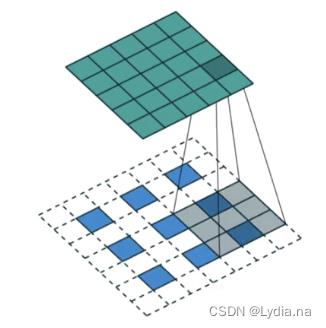
转置卷积:
需填充计算。
判别器
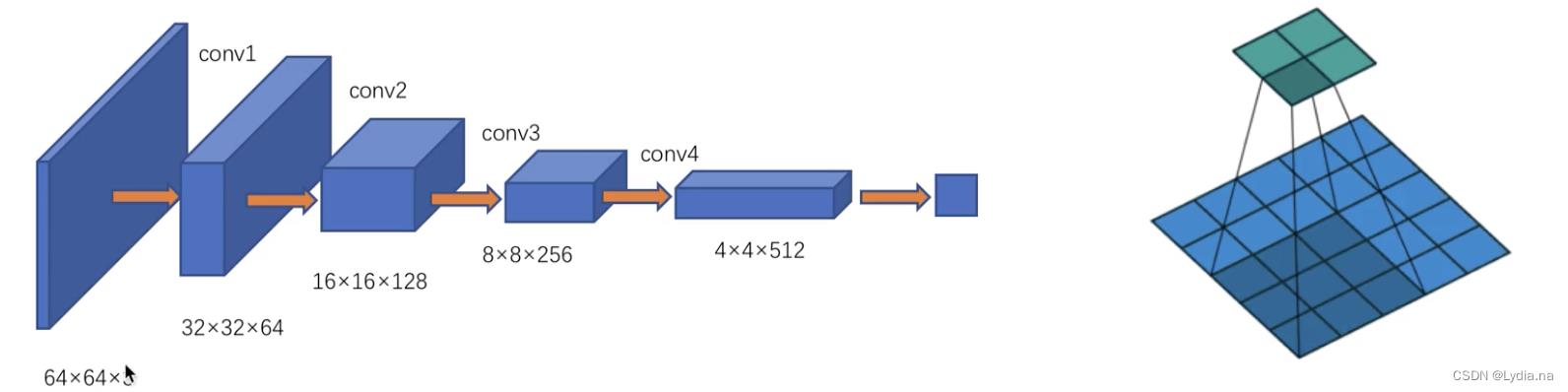
使用strided convolutions进行下采样。
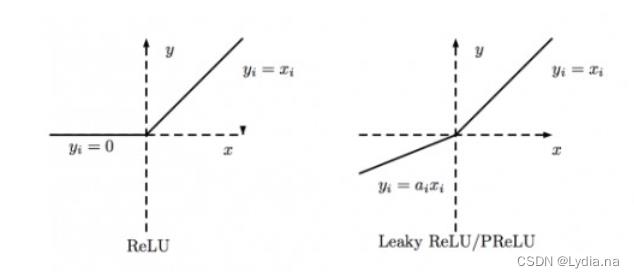
Leaky ReLu
ReLU是将所有的负值都设为零,相反,Leaky ReLU是给所有负值赋予一个非零斜率。Leaky ReLU激活函数是在声学模型(2013)中首次提出的。以数学的方式我们可以表示为:
y = x , x ≥ 0 x a , x < 0 y=\\left\\\\beginmatrix x,x\\ge 0 \\\\ \\fracxa ,x< 0 \\endmatrix\\right. y=x,x≥0ax,x<0
Tricks
- 在网络深层去除全连接层
- 使用带步长的卷积代替池化
- 在生成器的输出层使用tanh函数(生成器的输出层需要一个完整的映射所以使用tanh函数),其他层使用ReLu
- 在判别器中使用leaky Relu激活函数
- 除了生成器G的输出层和判别器D的输入层,其它层上都使用了
Batch Normalization,BN可以稳定学习,有助于处理初始化不良导致的训练问题
参考文章
文章
李宏毅机器学习笔记:GAN
GAN,WGAN,WGAN-GP 通俗易懂的原理解释
各种GAN原理总结及对比
激活函数ReLU、Leaky ReLU、PReLU和RReLU
图片
https://medium.com/towards-data-science/cgan-conditional-generative-adversarial-network-how-to-gain-control-over-gan-outputs-b30620bd0cc8
以上是关于深度学习生成对抗网络GAN|GANWGANWGAN-UPCGANCycleGANDCGAN的主要内容,如果未能解决你的问题,请参考以下文章