社招MX面试总结
Posted TiWalker
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了社招MX面试总结相关的知识,希望对你有一定的参考价值。
毕业若干年后的第一次面试,虽然面试前尽力的准备了,但是自我感觉表现得并不是十分完美吧。有一些问题,可能前面看过,但没真正理解,就没回答上来。想来有点遗憾,但只能更加地努力准备接下来的面试。
先简单介绍下面试的流程:
1.首先是面试官简单的公司介绍,主要是确保相关的兴趣匹配度方面。应该就是为了相互了解,双向奔赴。这个挺好的,前面我也说过,找工作真的是像相亲一样,没有那么多的条条框框,每个人处的情景都不一样。特别是在候选人都差不多的情况下,更是感觉公司和个人看上眼了就定了。对于求职者,建议:
a.对公司有简单的了解;b.提前准备一些公司的提问问题;c.展示出对公司的兴趣
2.然后就是让挑一个项目,说出自己的成就感。这个真的是要最好提前准备,包括这个之前的正式自我介绍。项目主要是突出自己的难点,或者遇到的困难问题,然后是如何解决的。这个最好提前想清楚,这样才能信手拈来。
3.具体的技术问题
a.C文件的编译过程
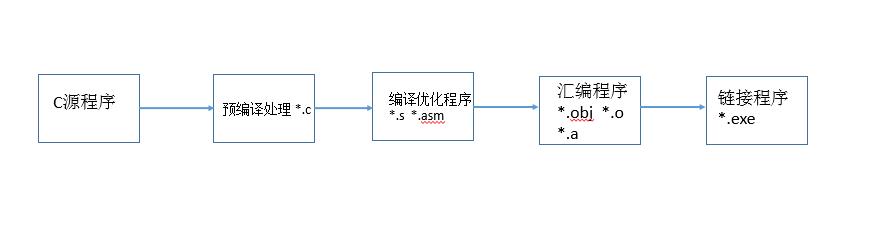
以上是Windows,我觉得重要要回答预编译, 然后是汇编,然后是机器语言,最后链接成为一个可执行程序。
预处理阶段:对源文件中文件包含关系(头文件)、预编译语句(宏定义)进行分析和替换,生成预编译文件。生成 .i 或 .ii 文件
编译阶段:将预编译文件进行词法分析、语法分析、语义分析及优化之后,生成汇编代码文件。
汇编阶段:将汇编文件转化成机器码(二进制文件),生成可重定位目标代码,生成.o文件
链接阶段:将多个目标文件及所需的库连接成最终的可执行目标文件。
b.C++新特性lamda表达式
lambda表达式是C++11标准中非常重要的一个新特性,它用于定义匿名函数,使得代码更加灵活简洁。lambda表达式与普通函数类似,也有参数列表、返回值类型和函数体,只是它的定义方式更简洁,并且可以在函数内部定义。
根据捕获规则,捕获列表有以下5种常用的捕获形式:
空捕获,表示lambda表达式不捕获任何变量。
变量捕获,表示捕获局部变量var。如果捕获多个变量,变量之间用“,”分隔。
引用捕获,表示以引用方式捕获局部变量var。
隐式捕获,表示捕获所有的局部变量。
隐式引用捕获,表示以引用方式捕获所有的局部变量。
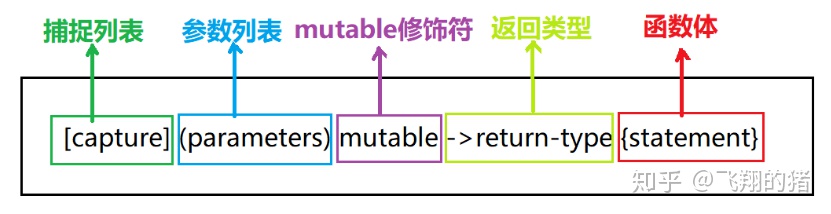
[]:什么也不捕获
[=]:捕获所有一切变量,都按值捕获
[&]:捕获所有一切变量,都按引用捕获
[=, &a]:捕获所有一切变量,除了a按引用捕获,其余都按值捕获
[&, =a]:捕获所有一切变量,除了a按值捕获,其余都按引用捕获
[a]:只按值捕获a
[&a]:只按引用捕获a
[a, &b]:按值捕获a,按引用捕获b
std::function
c.define和inline的区别
宏定义的使用类似函数,但是没有参数压栈,代码生成的开销,由预处理器来实现,调用的方式也是使用简单的文本替换,不会对参数的类型以及返回值的类型进行检查,因此使用宏具有一定的安全隐患。无法使用编译器类型检查的优势,且部分可以转换的返回值也无法进行转换。
inline函数,区别与函数调用过程当中的控制转移,inline函数在编译期间将使用该内联函数的位置处替换为函数体,因此可以直接执行不需要进行跳转。优势是减少了调用时的开销,缺点是增加了代码的长度,增加了程序的内存消耗。而且inline 函数也会由编译器来执行类型检查,因此尽量使用inline函数来替换#define定义的宏。
内联函数和宏的区别:
1)内联函数在运行时可调试,而宏定义不可以
2)编译器会对内联函数的参数类型做安全检查或自动类型转换,而宏定义则不会
3)内联函数可以访问类的成员变量,而宏定义则不能
d.智能指针
动态内存管理经常会出现两种问题:一种是忘记释放内存,会造成内存泄漏;一种是尚有指针引用内存的情况下就释放了它,就会产生引用非法内存的指针。
为了更加容易(更加安全)的使用动态内存,引入了智能指针的概念。智能指针的行为类似常规指针,重要的区别是它负责自动释放所指向的对象。标准库提供的两种智能指针的区别在于管理底层指针的方法不同,shared_ptr允许多个指针指向同一个对象,unique_ptr则“独占”所指向的对象。标准库还定义了一种名为weak_ptr的伴随类,它是一种弱引用,指向shared_ptr所管理的对象,这三种智能指针都定义在memory头文件中。
e.右值引用
值得一提的是,左值的英文简写为“lvalue”,右值的英文简写为“rvalue”。很多人认为它们分别是"left value"、"right value" 的缩写,其实不然。lvalue 是“loactor value”的缩写,可意为存储在内存中、有明确存储地址(可寻址)的数据,而 rvalue 译为 "read value",指的是那些可以提供数据值的数据(不一定可以寻址,例如存储于寄存器中的数据)。
通常情况下,判断某个表达式是左值还是右值,最常用的有以下 2 种方法。
1) 可位于赋值号(=)左侧的表达式就是左值;反之,只能位于赋值号右侧的表达式就是右值。
2) 有名称的、可以获取到存储地址的表达式即为左值;反之则是右值。
右值引用是为了移动语义和完美转发。
f.SIGV信号
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM 16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP 21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ 26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR 31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3 38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8 43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13 48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12 53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7 58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2 63) SIGRTMAX-1 64) SIGRTMAX
h.全局变量修改监控,watch原理
所谓软件观点(software watchpoint),即用 watch 命令监控目标变量(表达式)后,GDB 调试器会以单步执行的方式运行程序,并且每行代码执行完毕后,都会检测该目标变量(表达式)的值是否发生改变,如果改变则程序执行停止。
可想而知,这种“实时”的判别方式,一定程度上会影响程序的执行效率。但从另一个角度看,调试程序的目的并非是为了获得运行结果,而是查找导致程序异常或 Bug 的代码,因此即便软件观察点会影响执行效率,一定程度上也是可以接受的。
所谓硬件观察点(Hardware watchpoint),和前者最大的不同是,它在实现监控机制的同时不影响程序的执行效率。简单的理解,系统会为 GDB 调试器提供少量的寄存器(例如 32 位的 Intel x86 处理器提供有 4 个调试寄存器),每个寄存器都可以作为一个观察点协助 GDB 完成监控任务。
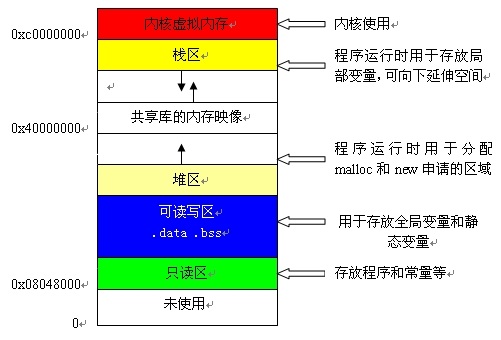
i.堆区、栈区、全局区、text段
而C语言的内存模型分为5个区:栈区、堆区、静态区、常量区、代码区。每个区存储的内容如下:
1、栈区:存放函数的参数值、局部变量等,由编译器自动分配和释放,通常在函数执行完后就释放了,其操作方式类似于数据结构中的栈。栈内存分配运算内置于CPU的指令集,效率很高,但是分配的内存量有限,比如ios中栈区的大小是2M。
2、堆区:就是通过new、malloc、realloc分配的内存块,编译器不会负责它们的释放工作,需要用程序区释放。分配方式类似于数据结构中的链表。“内存泄漏”通常说的就是堆区。
3、静态区:全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。程序结束后,由系统释放。
4、常量区:常量存储在这里,不允许修改。
5、代码区:顾名思义,存放代码。
j.栈上申请vector能否返回
vector的空间配置器是data_allocator,也就是simple_alloc,simple_alloc的实现就是std::alloc,根据申请的内存大小,决定用第一级配置器(malloc、free)还是第二级配置器(内存池),所以vector应该是分配在堆上的。可以返回。
k.函数参数压栈
从右往左压栈
l.arm的体系结构,寄存器指针
m.voliate作用
volatile 关键字是一种类型修饰符,用它声明的类型变量表示可以被某些编译器未知的因素更改,比如:操作系统、硬件或者其它线程等。遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问。声明时语法:int volatile vInt; 当要求使用 volatile 声明的变量的值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。而且读取的数据立刻被保存。
这说明这个 volatile 关键字发挥了它的作用。其实不只是内嵌汇编操纵栈"这种方式属于编译无法识别的变量改变,另外更多的可能是多线程并发访问共享变量时,一个线程改变了变量的值,怎样让改变后的值对其它线程 visible。一般说来,volatile用在如下的几个地方:
- 1) 中断服务程序中修改的供其它程序检测的变量需要加 volatile;
- 2) 多任务环境下各任务间共享的标志应该加 volatile;
- 3) 存储器映射的硬件寄存器通常也要加 volatile 说明,因为每次对它的读写都可能由不同意义;
n.互锁的概念
死锁:两个线程争夺资源的过程中,两个互斥量嵌套使用,且使用的顺序不一致;
产生条件:必须有两个互斥量(这里比作金锁,银锁),保护不同的数据共享块;
线程A和B,线程A先锁金锁,后锁银锁;线程B先锁银锁,后锁金锁;
当线程A,金锁lock 成功后,开始进行银锁的lock,这时候,线程后台切换到了线程B,导致银锁lock , 线程B开始执行金锁lock,卡在了金锁lock,这时候线程管理又切换到线程A,线程A开在了银锁lock,这样就造成了死锁,两个线程都卡在了lock函数里,无法解开;
死锁的一般解决方案:
保证互斥量的调用顺序一致;
std::lock函数模版:一次锁住两个或者两个以上的互斥量,要么锁住两个,要么两个都没锁住 ,只锁住一个的时候会主动放开,不会造成死锁问题;(至少两个)
4.一个手动编程题目
题目是不申请空间,合并两个升序数组。
88. 合并两个有序数组 - 力扣(LeetCode) (leetcode-cn.com)
搜集资料的时候,看到总结的好的面经:
面经-C语言基础(一)_alanfengliu的博客-CSDN博客_c语言面经
C++11右值引用(一看即懂) (biancheng.net)
以上,C++ 11语法,以及stl, 算法等还是重点。
以上是关于社招MX面试总结的主要内容,如果未能解决你的问题,请参考以下文章