基于LR的新闻多分类(基于spark2.1.0, 附完整代码)
Posted yhao浩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于LR的新闻多分类(基于spark2.1.0, 附完整代码)相关的知识,希望对你有一定的参考价值。
原创文章!转载请保留原始文章链接,谢谢!
环境:
- Scala2.11.8 + Java1.8.0_112
- Spark2.1.0 + HanLP1.3.2
完整项目代码见我的GitHub:https://github.com/yhao2014/ckoocML
(因为HanLP分词模型太大,未上传至项目中,需要的请从HanLP发布页下载,然后解压后将data目录整个放到ckoocML\\dictionaries\\hanlp\\目录下即可)
注:GitHub上此部分代码已更改,进行了模块划分,主要分成了预处理类Preprocessor.scala和逻辑回归类LRClassifier.scala,以及基于LR分类的训练及测试LRClassTrainDemo.scala、LRClassPredictDemo.scala。但不影响本博文对LR多分类的实现和解读
主体流程
自从引进DataFrame之后,spark在ml方面,开始使用DataFrame作为RDD的上层封装,以屏蔽RDD层次的复杂操作,对应用开发者提供简单的DataFrame,以减少开发量。本文以最新的spark2.1.0版本为基础,构建从数据预处理、特征转换、模型训练、数据测试到模型评估的一整套处理流程。另外,经过综合考虑,本文分词方法选用HanLP分词工具(文档丰富、算法公开、代码开源,并且经测试分词效果比较好),数据使用的是从新闻网站爬取的新闻分类数据,数据格式如下:
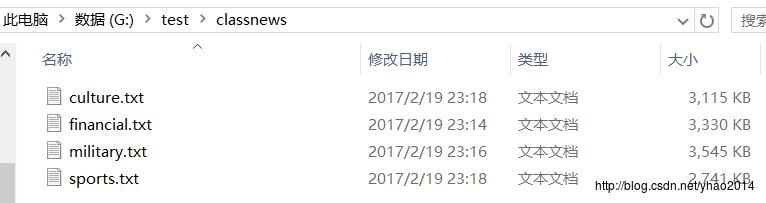

说明:使用了4个分类的数据(文化、财经、军事和体育),每个分类使用了1000条数据,每行一条数据,有4个字段(分类、标题、日期和内容),使用"\\u00EF"作分割符。
一、数据清洗转换
数据预处理步骤主要进行数据清洗、转换操作。主要代码如下:
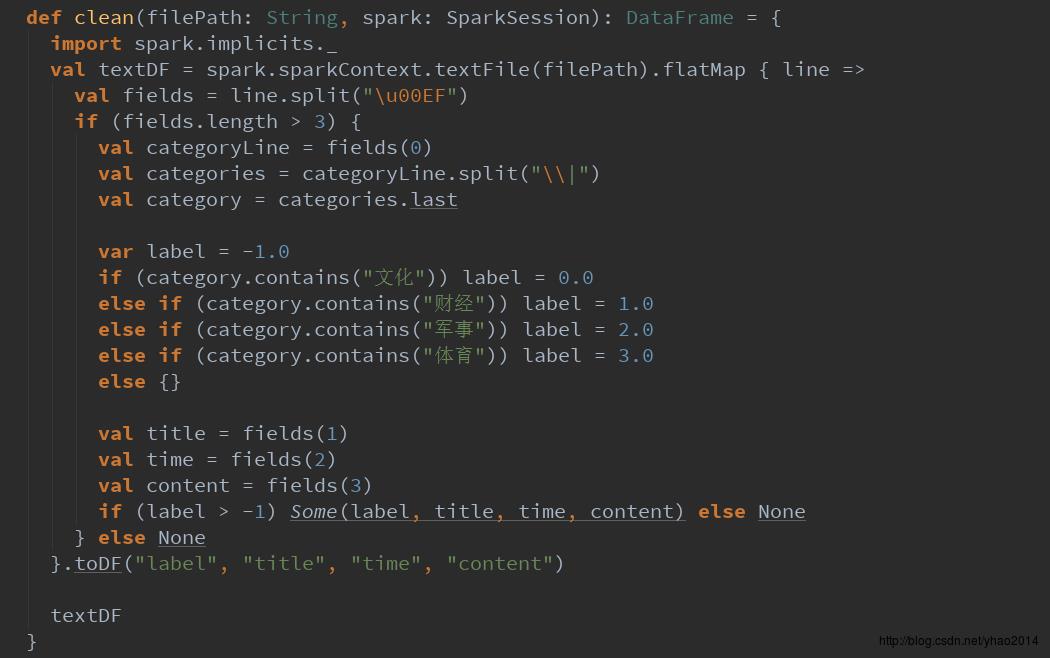
首先从文件加载数据到RDD,然后按分割符进行切分。因为分类字段爬取下来时没有进行清洗,在这里我们需要将其分类提取出来,然后转换为spark上LR算法可以识别的Double形式,并按分类字段过滤掉未提取到分类或者分类不正确的脏数据,然后转换为DataFrame,并指定每个字段的字段名。
注意:这里必须要添加一行import spark.implicits._,否则不能引用到SparkSQL的toDF方法!
二、分词
在经过数据预处理之后,我们已经将数据转换为了我们想要的DataFrame格式,并且清洗掉了。接下来我们需要进行分词的操作,将新闻内容切分成一个个词语的形式,以便后续进行停用词去除以及转换为特征向量
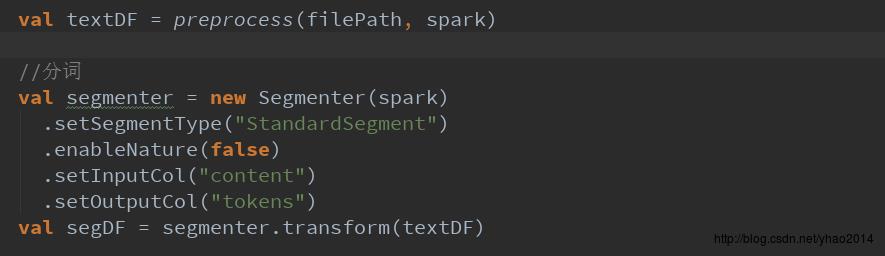
这里我模仿spark的lm包下的StopWordsRemover类创建了Segmenter类,用于对数据进行分词,其内部调用了HanLP分词工具。(由于spark自带的StopWordsRemover等使用的闭包仅限于ml包,自定义的类无法调用,故只是采用了与StopWordsRemover类似的使用形式,内部结构并不相同,并且由于以上原因,Segmenter类没有继承Transformer类,故无法进行pipeline管道操作,此缺陷有待解决)
Segmenter类具体实现如下:
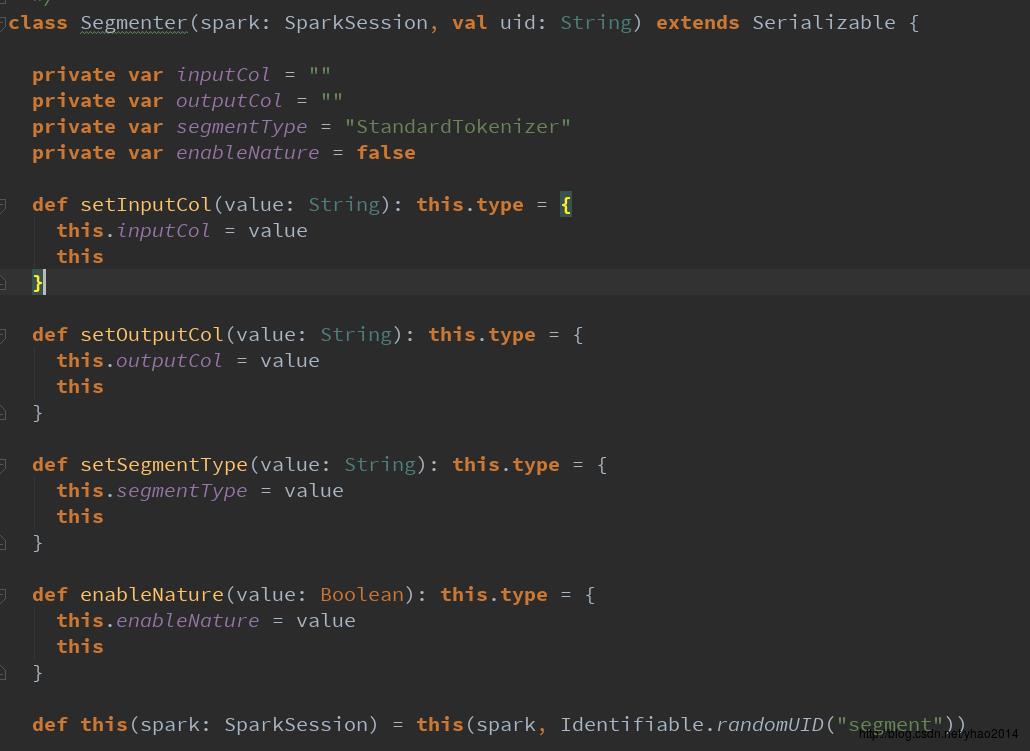
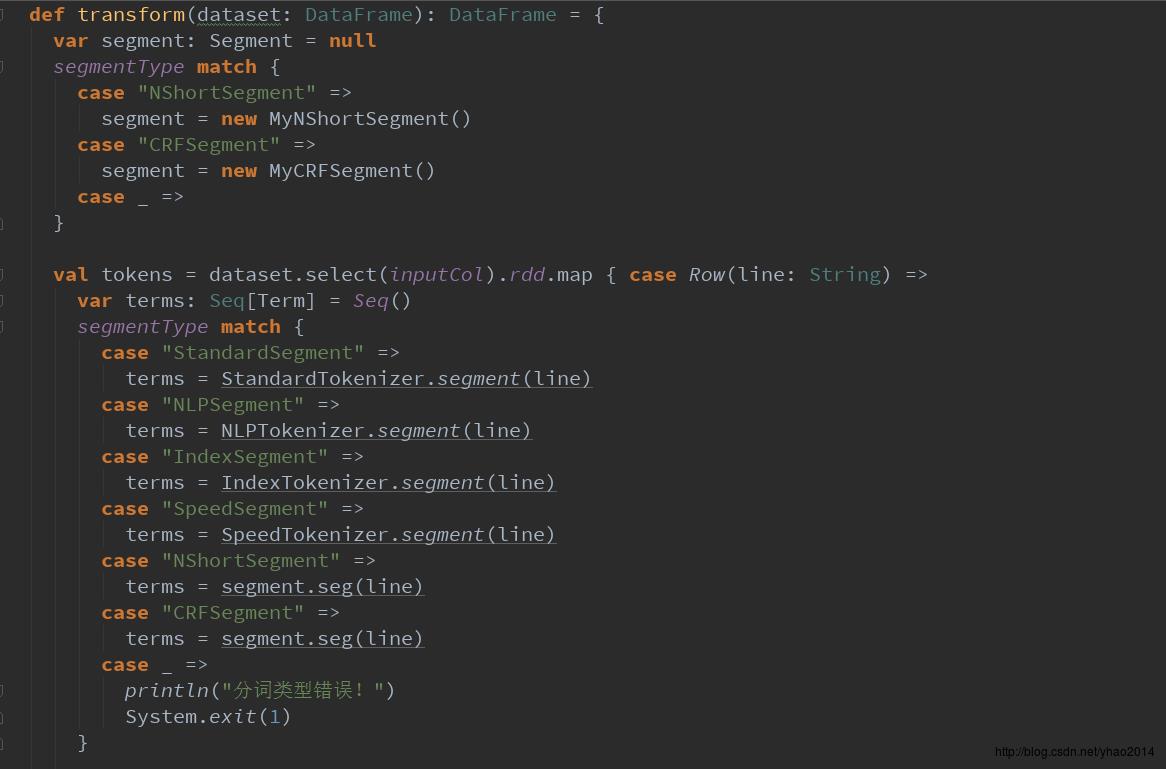
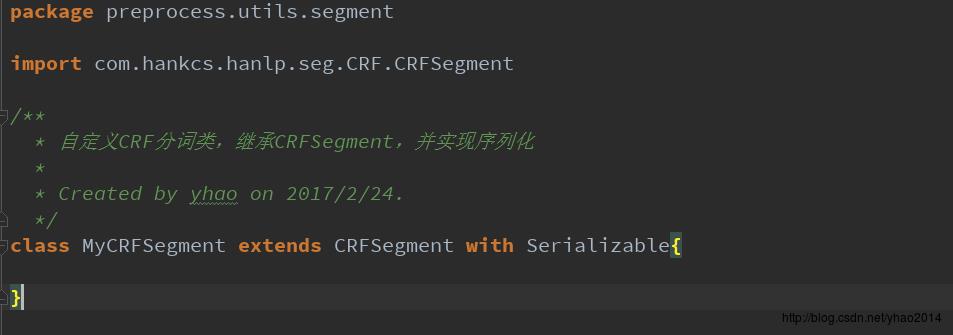
主要在transform方法中调用了HanLP相关的分词方法。注意,如果使用NShortSegment和CRFSegment,需要new相应的对象,这里我自己创建了MyNShortSegment和MyCRFSegment类,继承了HanLP中对应的类,并继承了Serializable特质(其实并没有做什么操作~)。主要是因为HanLP没有对它们实现序列化,直接在RDD中使用它们会报错。(当然你也可以对HanLP的源码进行修改,再重新打包。个人觉得比较麻烦,并且不易跟进HanLP发布进度,所以没去弄~)
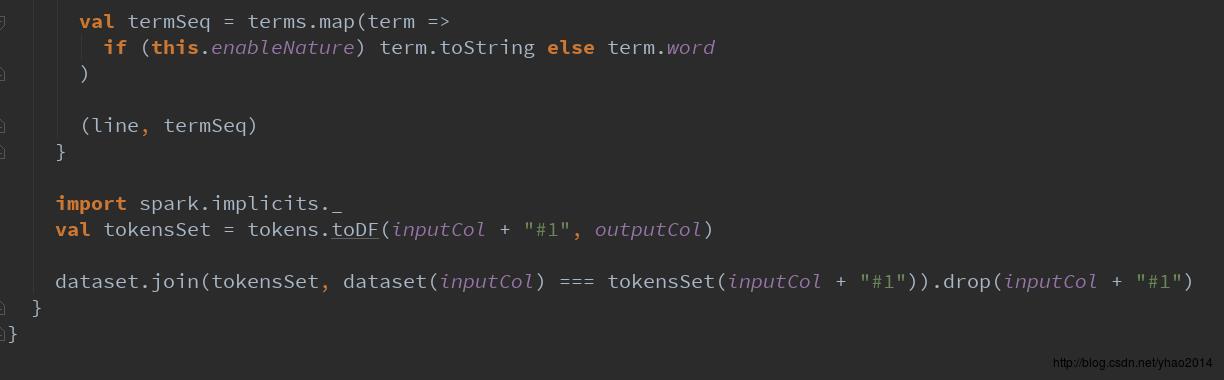
此外,上面Segmenter代码的最后是使用DataFrame的join操作将原DataFrame与分词后的DataFrame进行了连接,与spark使用的schemaType元数据推断DataFrame结构的方式不同。
三、去除停用词
分词之后,我们需要对一些常用的无意义词(通常是语气词、连词等),如:“的”、“我们”、“是”等(统称为“停用词”)进行去除。因为这些词没有多大的意义,但是在自然语言中又经常使用,这些词不去掉会强烈的干扰我们对特征的抽取效果。(比如:在体育分类语料中,“的”共出现500次,“足球”共出现300次,那么谁更能代表体育这个分类呢?谁更应该作为特征被保留下来呢?)
去除停用词的操作我们直接调用ml包中的StopWordsRemover类:

由于spark的StopWordsRemover类中内置的停用词都是一些英文停用词,而我们在这里处理的是中文语料,故需要加载自己的停用词。这里我使用了HanLPdictionary目录下的stopwords.txt文件提供的停用词。(这里面都是一些基本停用词,如果对停用词要求比较高,可以在网上找几份停用词表进行合并,效果会更好一点)
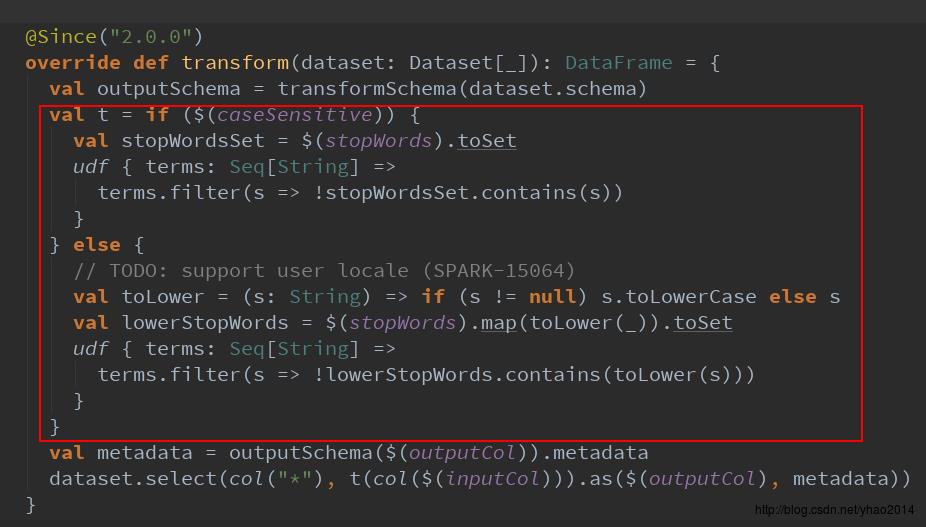
有兴趣的同学可以进到transform方法中看一看,spark官方的去除停用词方法跟我们常用处理一样,将停用词转换成set,然后调用contains进行判断,然后过滤:
四、向量化
由于目前常用的分类、聚类等算法都是基于向量空间模型VSM(即将对象向量化为一个N维向量,映射成N维超空间中的一个点),VSM将数据转换为向量形式,便于对大规模数据进行矩阵操作等,也可以通过计算超空间中两个点之间的距离(一般是余弦距离)来计算两个向量之间的相似度。因此,我们需要将经过处理的语料转换为向量形式,这个过程叫做向量化。
这里我们也调用spark提供的向量化类CountVectorizer类进行向量化操作:
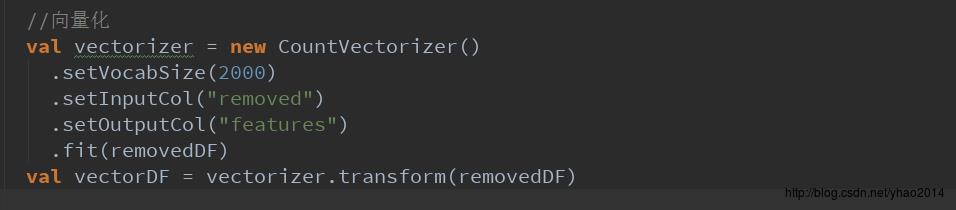
这里的vocabSize是词汇表大小,即转换为向量之后的向量维度。通过阅读fit方法(训练向量化模型,主要是计算vocabulary词汇表的过程),我们可以看到其逻辑也比较简单:wordcount计算词频 --> 计算文档频率 --> 按文档频率过滤-->取词频最大的vocabSize个词
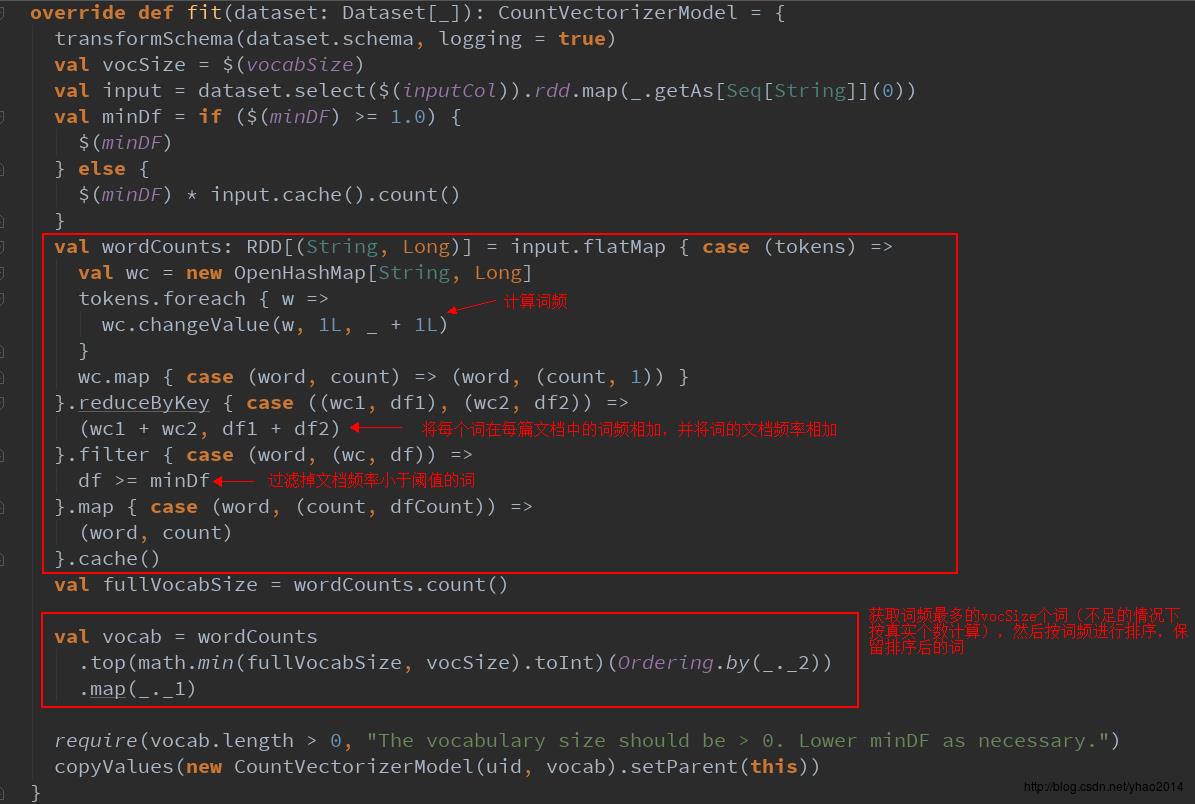
从这里可以看出,所谓的训练CountVectorizer模型仅仅是对词频进行统计,计算出词频最大的vocabSize个词作为词汇表。下面我们继续看看transform方法:
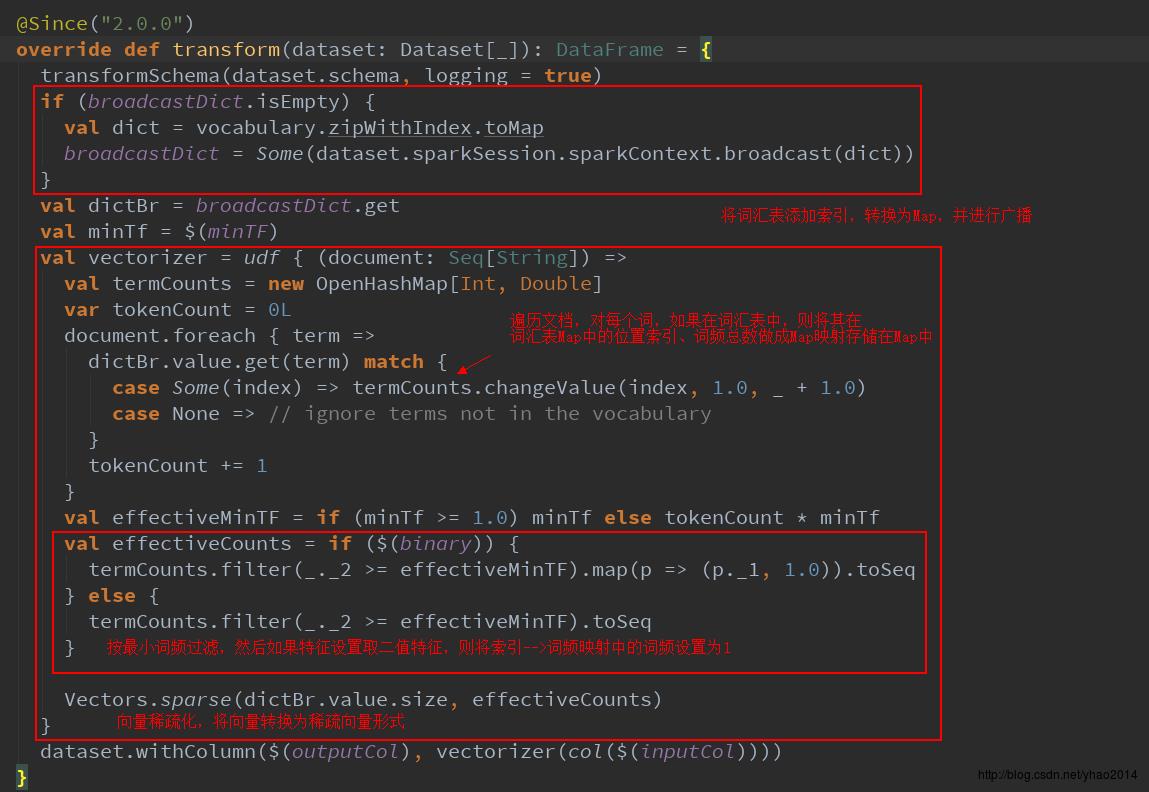
transform方法也比较简单,将词汇表建立索引并转换为Map -->遍历并保留在词汇表中的词,及其词频 -->转换为稀疏向量形式
我们可以将向量化后的数据打印出来看看长什么样儿:
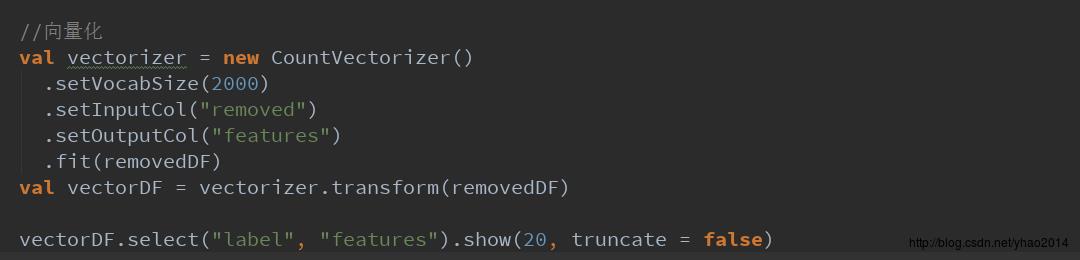
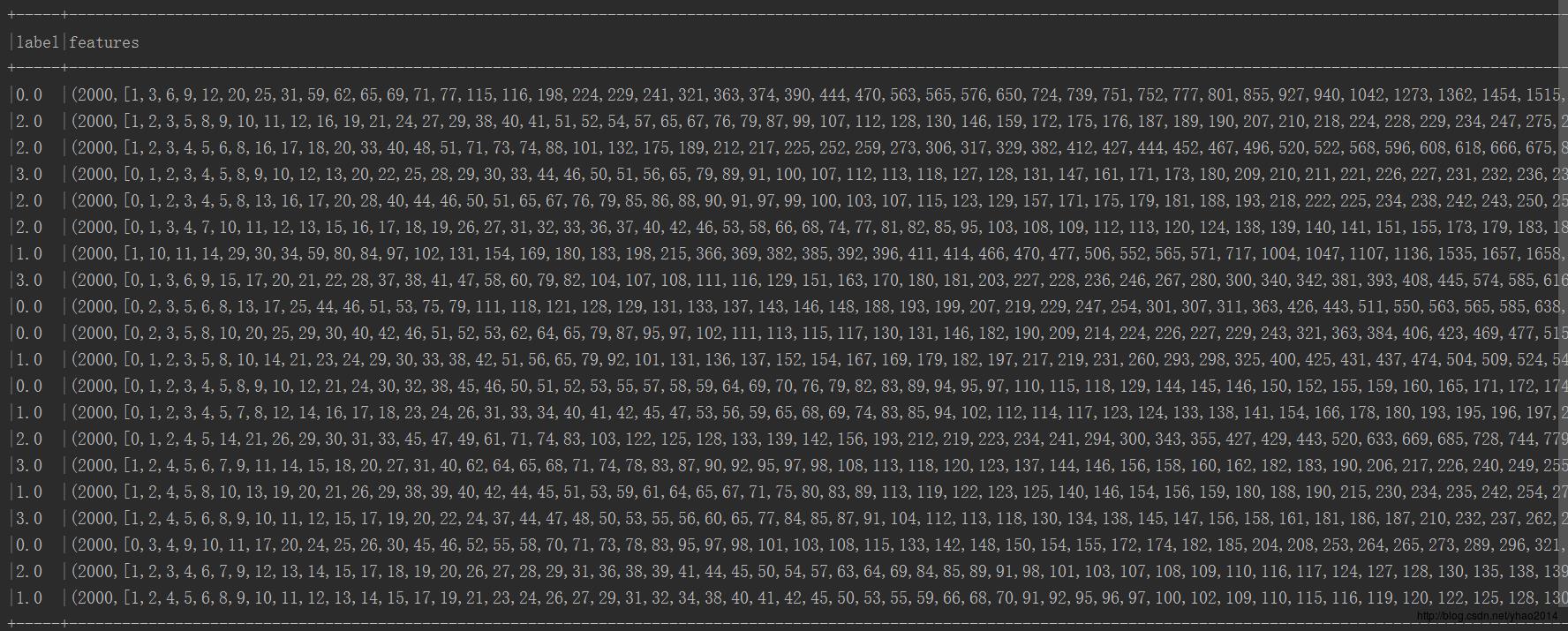
后面没有显示完,我们取第一条数据看看:

可以看到前面是标签,即类别序号,后面是一个稀疏向量,其元素分别代表:向量维度(2000)、特征索引数组(即词汇表中哪些索引号的词出现在该文档中)、词频数组(词汇表中索引词在该文档中出现的次数),例:最后一个元素1975表示词汇表中第1975个词出现在该文档中,出现的次数是4
五、模型训练
在经过向量化后,数据就可以用来进行分类模型的训练了!这里我们先使用最常用的分类模型——逻辑回归LogisticRegression。spark上提供的LR模型可以实现多分类,正好适用于我们的语料。
下面是分类模型训练的代码:
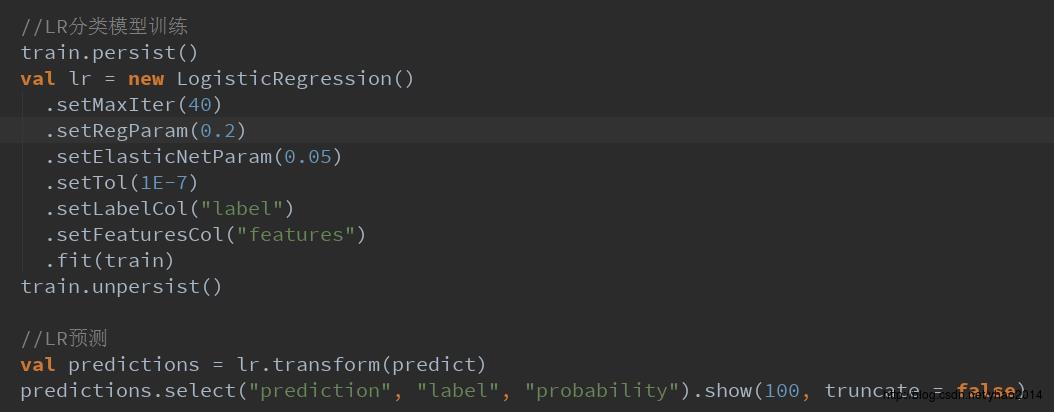
在new一个LogisticRegression时,可以对其参数进行设置,这里大概跟大家说一下:
- setMaxIter:设置最大迭代次数(默认100),具体迭代过程可能会在不足最大迭代次数时停止(参照下一条)
- setTol:设置容错(默认1E-6),每次迭代会计算一个误差值,误差值会随着迭代次数的增加逐渐减小,如果误差值小于设置的容错值,则停止迭代优化
- setRegParam:设置正则化项系数(默认0.0),正则化项主要用于防止过拟合现象,因此,如果你的数据集比较小,特征维数又比较多时,易出现过拟合,此时可以考虑增大正则化项系数
- setElasticNetParam:正则化范式比(默认0.0),正则化一般有两种范式:L1(Lasso)和L2(Ridge)。L1一般用于特征的稀疏化,L2一般用于防止过拟合。这里的参数即设置L1范式的占比,默认0.0即只使用L2范式
- setLabelCol:设置标签列(默认读取“label”列)
- setFeaturesCol:设置特征列(默认读取“features”列)
还有一个参数是setWeightCol,即设置各特征的权重,默认值是将每个特征权重设置为1.0,这里我们使用默认值就好了,如果对特征有特殊要求,可考虑重新设置对应的权重(如将标题作为一项特征,并且标题重要性更高,可将标题这一特征的权重设置大一点)
注意:由于我们的数据稀疏性本来就很高了(2000维的向量只有少数维度有值),因此切记不要把setElasticNetParam设置得过大!!因为s 以上是关于基于LR的新闻多分类(基于spark2.1.0, 附完整代码)的主要内容,如果未能解决你的问题,请参考以下文章