魅族推荐平台架构解析
Posted 魅族技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了魅族推荐平台架构解析相关的知识,希望对你有一定的参考价值。
一、“推荐”
关于“推荐”这个词,相信大家并不陌生,平时浏览网站(特别是电商网站)时看到的很多网站的首页的内容是通过系统推荐给大家的。
1、推荐能做什么?
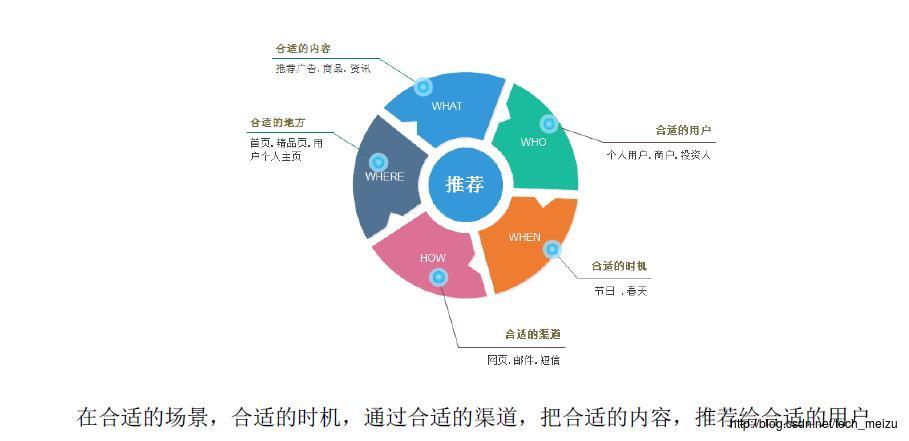
在网站首页或一些精品页,可以推荐网站自身的内容。比如电商网站,在情人节当天可以推荐节日相关商品,在换季的时候可以推荐一些当季的服装等。总之就是在合适的场景通过合适的渠道把合适的内容推荐给合适的用户。
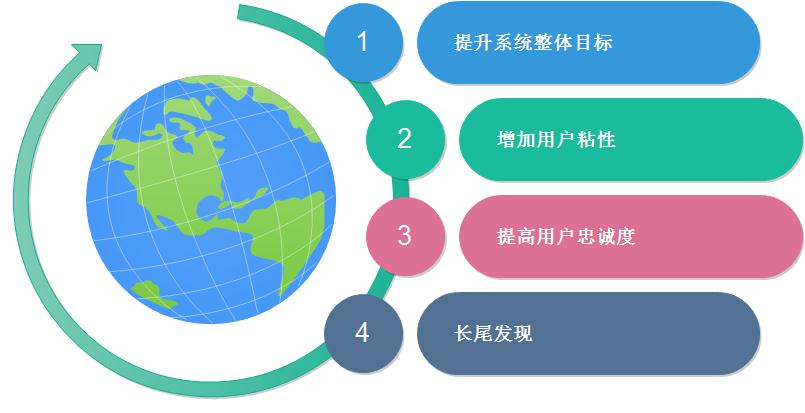
2、推荐有什么作用?
推荐的作用主要有以下4点:
3、推荐在魅族的应用
魅族整个产品线都有用到推荐。包括资讯、视频、应用中心、个性化中心、广告等业务。
4、推荐效果
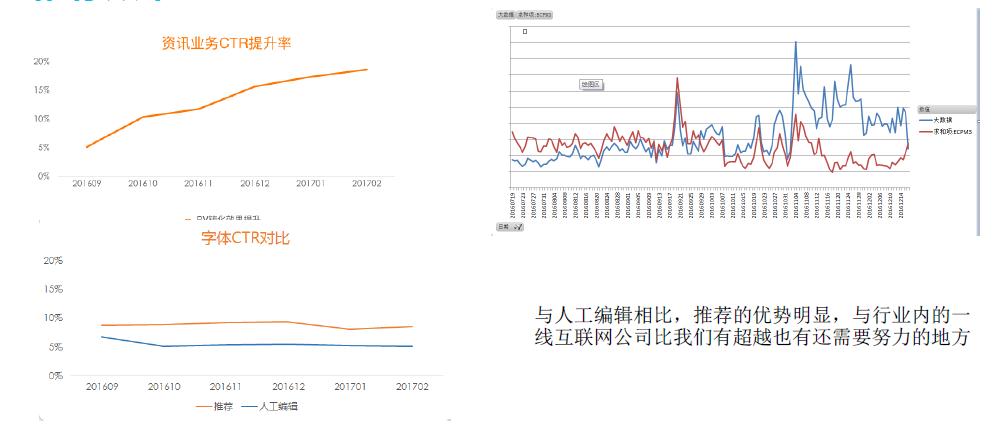
我们的资讯推荐是在2016年9月上线的,上面第一个图是我们资讯业务的CTR效果图,和以前的人工编辑做一个比较。可以看到人工编辑的部分,曲线上升坡度明显,一开始坡度减少的原因是需要时间的积累才能知道用户的行为,提升推荐效果。
第三个图是字体的CTR,字体CTR也明显比人工编辑的效果要好很多。这二个图(最右边)是魅族广告一个ECMP的效果,是跟国内一线互联网比较,一开始我们的效果可能比他们要差,但是经过一段时间之后,明显我们的效果慢慢地比他们要好。
二、魅族推荐平台架构演进
1、平台的核心需求
- 支撑5个以上大产品线在不同场景下推荐业务的需求;
- 保证业务稳定运行,可用性达到99.9%;
- 推荐场景当次请求响应在200毫秒以内;
- 广告预测场景当次请求响应在100毫秒以内;
- 一天需要支撑亿级别的PV量。
2、技术难点:
- 针对于每一个用户的一次推荐需要从万级甚至是十万级别以上的物品中进行挑选用户可能感兴趣的物品;
- 每一次推荐需要同时计算十个甚至是数十个算法数据,一个算法需要计算成百上千个维度;
- 一天需要实时处理上亿条行为日志,进行百亿到千亿次计算;
- 每天需要访问数据存储上十亿次;
- 每天需要支撑上百个数据模型在线更新及实验。
3、魅族推荐平台架构的演变过程
3.1 第一代架构

上图展示的是我们的第一代架构,在这个图里可以看到整个过程比较简单,可以通过这个一线模型计算,计算以后整个用户的数据通过这个模型直接写到库里。
第一代架构存在的问题
这个架构能够满足网站用户访问量在几十万或者几百万规模的数据处理需求。但是当用户访问量呈现大规模增长,问题就暴露出来了。
- 离线计算量大,需要将所有用户的数据进行结果计算,同时浪费机器资源;
- 结果数据更新困难,大批量数据更新对数据库的冲击大,可能直接造成用户访问超时,服务不可用;
- 数据更新延时大,超大数据量计算基本上只能实现T+1的方式进行数据更新,所以数据推荐都是基于旧行为数据进行预测;
- 数据库的瓶颈直接影响算法结果数据输出频率,算法调优困难;
- 扩展困难,所有结果数据已经固定输出,很难插入一些业务上特定的需求。
3.2 第二代架构

整个架构分为两层:
第一层是离线,离线是处理大批量的模型计算,根据离线日志,计算只会产生数据算法的模型。也就是说这个计算只产生了数据模型,而不会计算所有用户并推荐内容,所以比实际推荐结果要小很多,可能只有几百兆或几个G的内容,存储量减少。
第二层是在线,我们把在线模块切割成3个板块:OpenAPI、业务策略计算、实际模型计算。
针对于模型计算板块这个架构的有很多优势。因为从这一代开始变成实时计算,都是基于模型实时在线计算出来,原始的模型推荐的实际数据处理起来方便很多,难度也会减少。
总结起来第二代架构的优势有:
- 用户推荐数据实时根据用户请求进行计算,减少离线计算量及减少数据存储空间;
- 模块分离,业务各性化处理与模型计算分离,系统更抽像化,可复用度越高及可扩展性越好;
- 原始模型的输出到线上比起结果数据输出更轻便,对线上性能影响更小,更方便于算法在线调优。
当然也还是存在一些问题:
- 模型离线训练,用户实时产生的行为无法反馈到模型当中,可能造成推荐结果数据的延迟;
- 业务混布,各业务之间相互影响;
- 由于把离线的部分计算放到线上进行计算,在请求过程中计算量增大,系统响应时长挑战增大;
- 业务接入越多,模型会越来越多,单台机器已经无法装载所有的模型。
接下来的博客中会详细说明魅族推荐平台现状也就是第三代架构,请大家关注。
以上是关于魅族推荐平台架构解析的主要内容,如果未能解决你的问题,请参考以下文章