大数据日志可视化分析(Hadoop+SparkSQL)
Posted biyezuopinvip
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据日志可视化分析(Hadoop+SparkSQL)相关的知识,希望对你有一定的参考价值。
目 录
1 概述 6
1.1 开发背景 6
1.2 开发意义 6
1.3 论文结构 7
1.4 本章小结 8
2 关键技术和使用的工具环境等的说明 9
2.1 IDEA简介 9
2.2 html/CSS简介 9
2.3 Spark简介 10
2.4 SparkSQL简介 10
2.5. Hadoop简介 11
2.6. ECharts简介 11
2.7. mysql简介 11
2.5 本章小结 12
3 需求分析 13
3.1 功能需求分析 13
3.2 业务流程分析 13
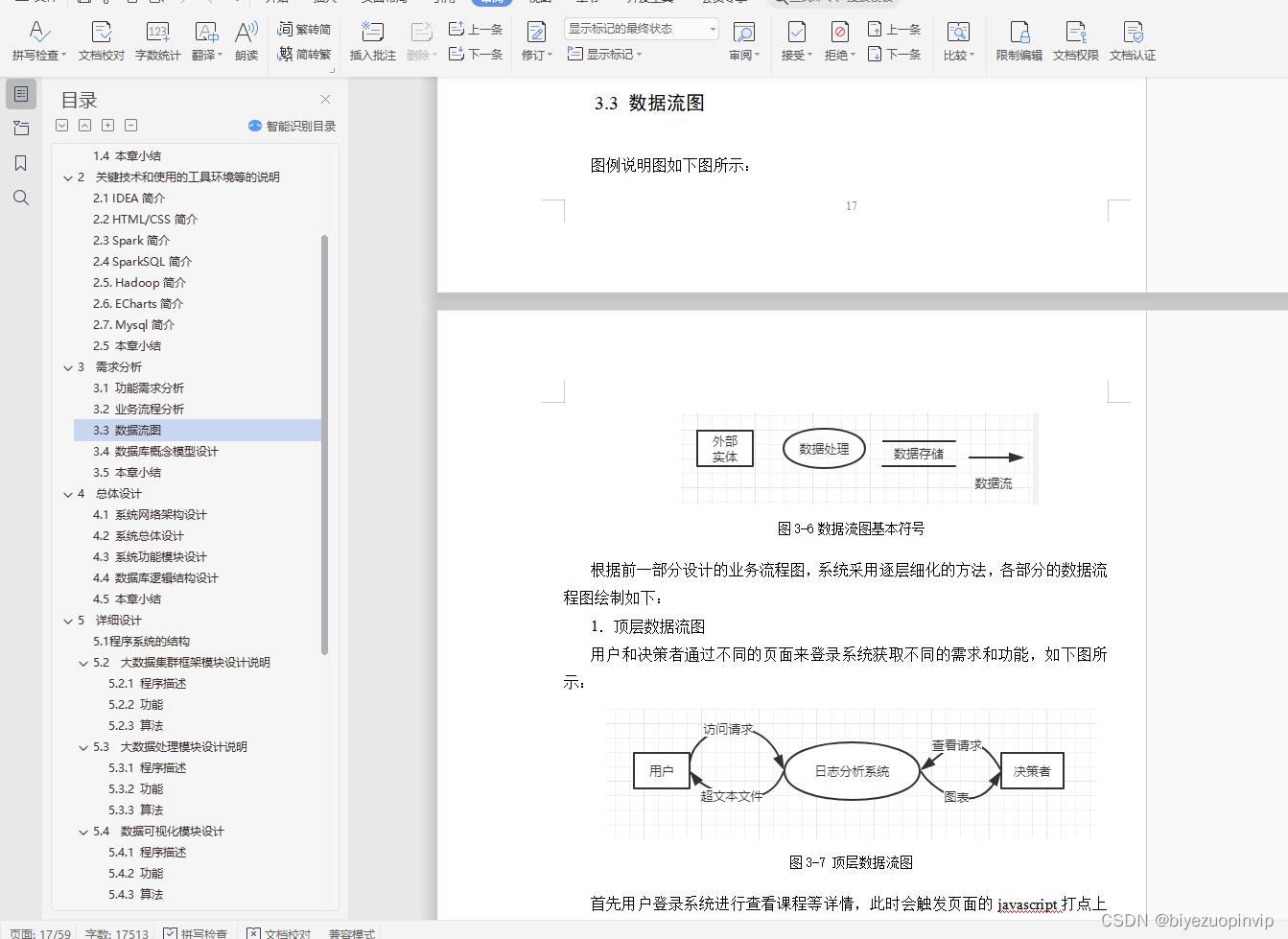
3.3 数据流图 17
3.4 数据库概念模型设计 20
3.5 本章小结 20
4 总体设计 21
4.1 系统网络架构设计 21
4.2 系统总体设计 21
4.3 系统功能模块设计 22
4.4 数据库逻辑结构设计 24
4.5 本章小结 24
5 详细设计 25
5.1 程序系统的结构 25
5.2 大数据集群框架模块设计说明 25
5.2.1 程序描述 25
5.2.2 功能 25
5.2.3 算法 26
5.3 大数据处理模块设计说明 26
5.3.1 程序描述 26
5.3.2 功能 27
5.3.3 算法 27
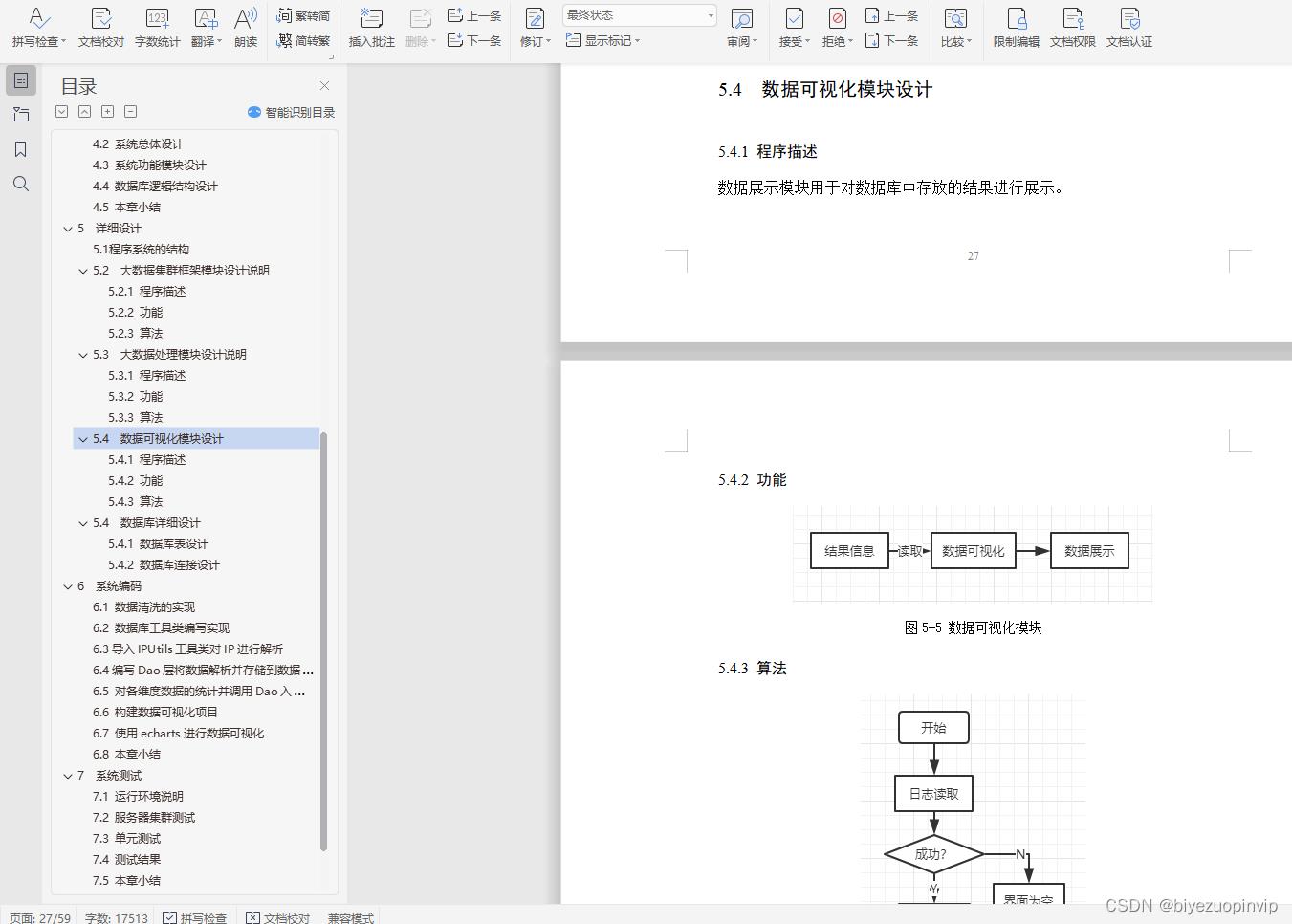
5.4 数据可视化模块设计 27
5.4.1 程序描述 27
5.4.2 功能 28
5.4.3 算法 28
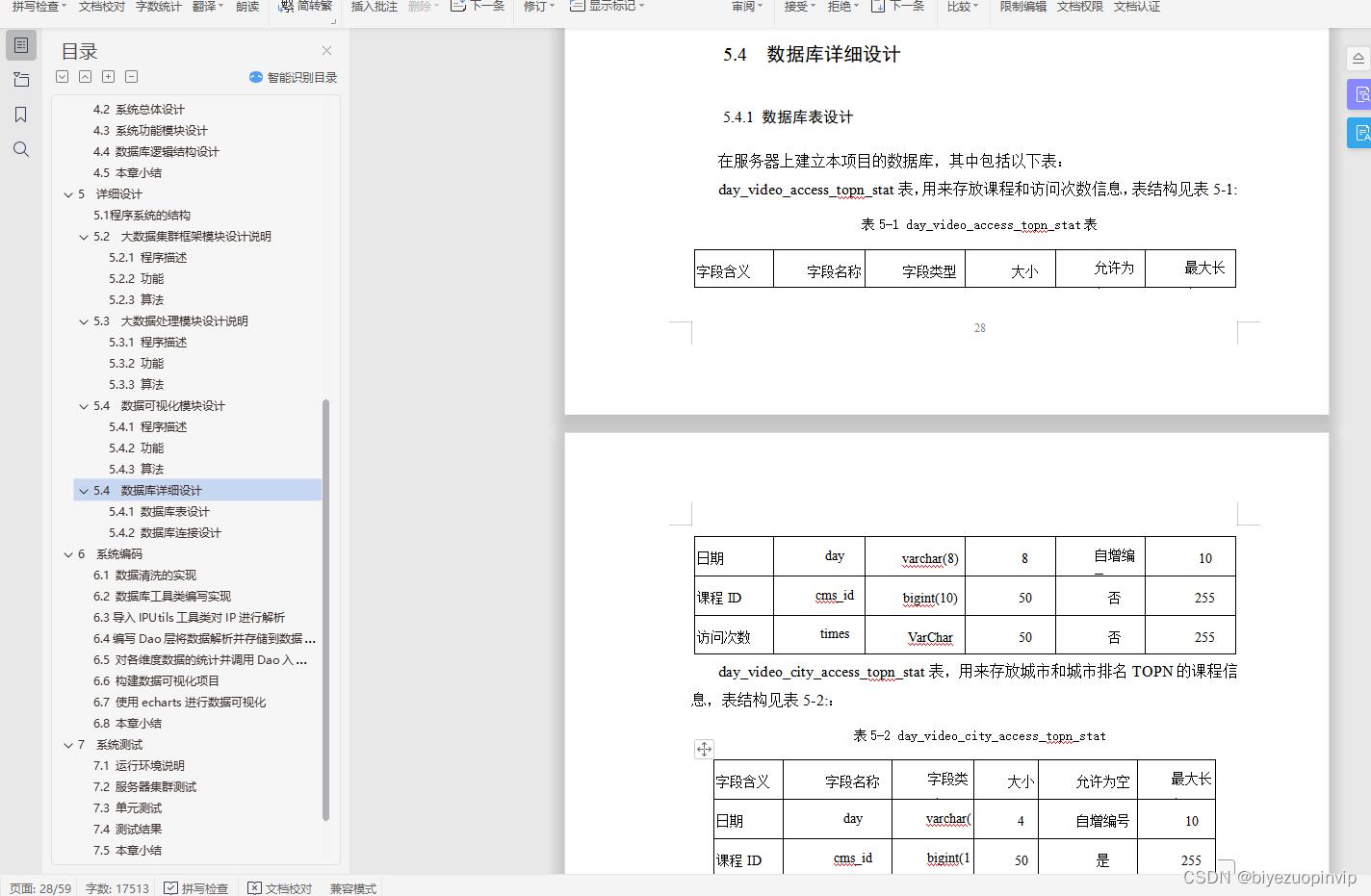
5.4 数据库详细设计 28
5.4.1 数据库表设计 28
5.4.2 数据库连接设计 30
6 系统编码 32
6.1 数据清洗的实现 32
6.2 数据库工具类编写实现 34
6.3导入IPUtils工具类对IP进行解析 36
6.4编写Dao层将数据解析并存储到数据库中 36
6.5 对各维度数据的统计并调用Dao入库 40
6.6 构建数据可视化项目 45
6.7 使用echarts进行数据可视化 47
6.8 本章小结 50
7 系统测试 51
7.1 运行环境说明 51
7.2 服务器集群测试 51
7.3 单元测试 52
7.4 测试结果 55
7.5 本章小结 55
结束语 56
参考文献 58
致 谢 59
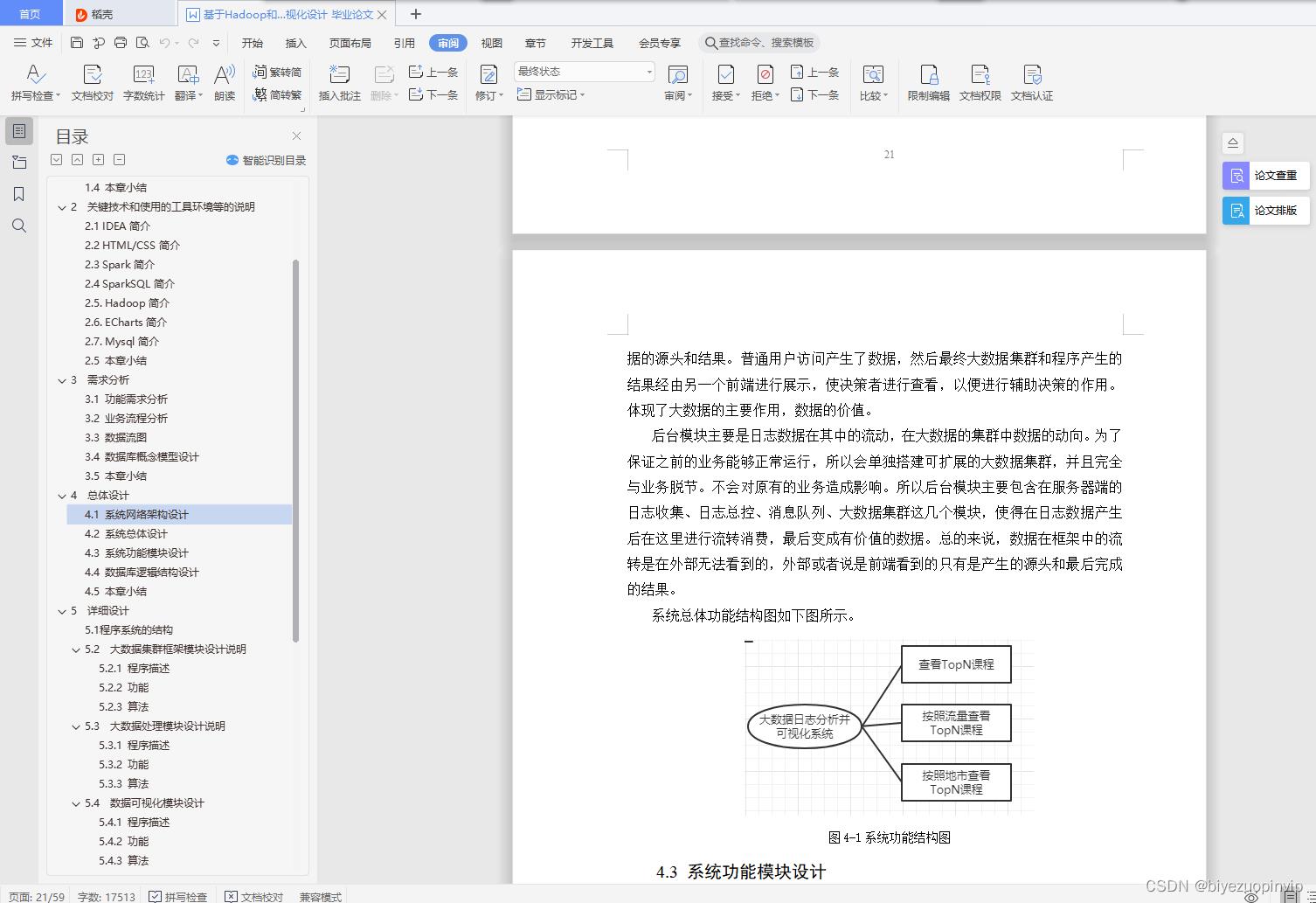
4.2 系统总体设计
根据以往的设计分析,根据系统开发的基本概念,可以对本次系统进行分解。从模块可以分为前端展示模块和后台数据处理模块。
前台模块主要是让普通用户进行访问,以便产生大数据需要的日志信息,然后最终的决策者看到的是最终数据流经后台并分析产生的结果。所以前端模块是数据的源头和结果。普通用户访问产生了数据,然后最终大数据集群和程序产生的结果经由另一个前端进行展示,使决策者进行查看,以便进行辅助决策的作用。体现了大数据的主要作用,数据的价值。
后台模块主要是日志数据在其中的流动,在大数据的集群中数据的动向。为了保证之前的业务能够正常运行,所以会单独搭建可扩展的大数据集群,并且完全与业务脱节。不会对原有的业务造成影响。所以后台模块主要包含在服务器端的日志收集、日志总控、消息队列、大数据集群这几个模块,使得在日志数据产生后在这里进行流转消费,最后变成有价值的数据。总的来说,数据在框架中的流转是在外部无法看到的,外部或者说是前端看到的只有是产生的源头和最后完成的结果。
系统总体功能结构图如下图所示。
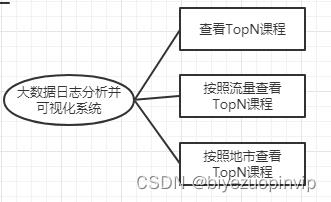
图4-1系统功能结构图
4.3 系统功能模块设计
1.用户访问日志采集:日志采集是大数据的数据来源,也是本系统的基石。用户访问了页面之后,页面的跳转、用户的信息将会被收集到nginx服务器上,从而完成数据的来源收集。这也是整个大数据的基石。
2.大数据日志信息采集:日志信息收集到nginx上的日志文件中,需要将大数据,即日志收集到大数据框架中,所以日志采集是很重要的一部分。日志收集将日志信息从文件中收取,实际上是进行实时的监控,发现日志信息的增多便动态的将日志收集然后发送出去。
3.大数据日志信息总控:大数据日志信息经过各个节点的收集之后,会统一汇总到一个节点上进行处理,那就是日志总控节点,总控节点是由一个flume组成的,负责对所有传来的数据进行管理,管理的方式是打上不同的topic信息,并转发到不同的消息队列中。充当一个生产者的角色,使得数据在流向上进行了有序的管理。也为消息队列增加了数据的源头。
4.消息队列:消息队列是将所有的消息进行存储,里面有不同的topic,将系统的所有消息进行分类的存放和管理,因为是应用生产者消费者模型,所以消息产生出来后,不同的程序都可以在消息队列中进行订阅不同的消息,从而使得整个消息系统变得有序和便于管理,最重要的大数据系统的特征:可扩展和容错。
5.spark集群:spark集群是整个大数据的处理系统,负责对程序的分发和处理,由于基于内存,所以运行速度是很快的,可以对海量的数据进行处理,彰显了大数据的实力。多节点的spark集群中运行sparkSQL程序对消息队列中的消息进行消费。并且是编写的分析、处理程序的运行容器,是其运行的基础。
6.Hdfs集群:为了模拟企业的大数据处理平台,将hadoop集群搭建了起来,底层是hdfs进行存储的系统,上层有yarn进行统一的资源调度。Spark运行的时候将运行在hdfs之上,这也是通常的企业的做法。
7.数据落地:因为要对数据进行离线处理,所以要先将数据落地到本地的磁盘上,然后才能进行离线批处理,因为sparkSQL是用来进行离线批处理的,没办法进行实时流处理计算,使用程序对kafka消息队列的消息进行读取和消费,最终存储到本地的文件中等待后续的处理。
8.数据清洗:因为保存的数据有很多在传输过程中可能产生了错乱,或者因为各种不稳定的问题产生了很多没法处理的格式,所以使用数据清洗对海量的数据进行清洗,保证剩余有效的数据,不然会导致程序处理过程中出错,在清洗的过程中将数据整理成规整的格式化有结构的数据。
9.数据落地:将数据清洗后形成的结构化数据进行落地,落地后形成parquet文件。。
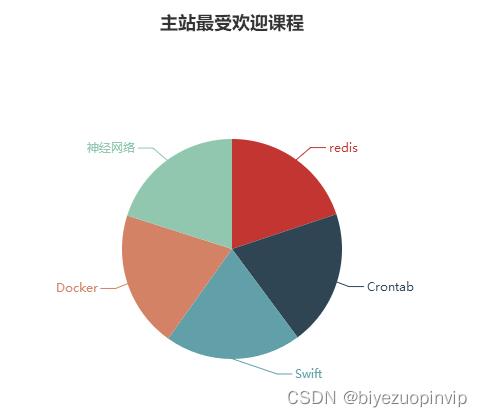
10.数据分析访问量大的课程:读取规整的格式数据,对数据进行统计操作,并最终统计出各个课程的访问量,并进行落地操作,本次落地直接存储到Mysql数据库中。
11.数据分析流量最大的课程:同样对数据进行读取后,对数据进行统计分析操作,这次统计的是各个课程流量的访问情况,根据转发的链接进行评价。最终统计结果直接存入到Mysql数据库中。
12.数据分析各个地市课程访问的排名:对数据读取后,使用程序对其进行分析处理,先根据IP进行解析地市信息,然后对各个地市的课程进行统计操作。最终结果也将存入到Mysql数据库表中。
13.前端展示系统:使用echarts开源框架对Mysql数据库中的数据进行可视化,对不同的结果进行展示,本文转载自http://www.biyezuopin.vip/onews.asp?id=13356以便决策者可以查看和分析。
4.4 数据库逻辑结构设计
课程(课程编号, 访问时间, 访问次数)
主键:课程编号
城市(城市名, 课程编号)
主键:城市名 外键:课程编号
课程流量(课程编号, 流量数量)
主键:课程编号
清洗过程:
import org.apache.spark.sql.SaveMode, SparkSession
/**
* 使用Spark完成数据清洗工作
*/
object SparkStatCleanJob
def main(args: Array[String])
val spark = SparkSession.builder().appName("SparkStatCleanJob")
.master("local[2]").getOrCreate()
val accessRDD = spark.sparkContext.textFile("file:///d:/mycode/data/access.log")
val accessDF = spark.createDataFrame(accessRDD
.map(x => AccessConvertUtil.parseLog(x)), AccessConvertUtil.struct)
accessDF.coalesce(1).write.format("parquet").mode(SaveMode.Overwrite)
.partitionBy("day").save("/d:/mycode/data/imooc/clean")
spark.stop()
清洗工具类:
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.LongType, StringType, StructField, StructType
object AccessConvertUtil
// 定义输出的字段
val struct = StructType
Array(
StructField("url", StringType),
StructField("cmsType", StringType),
StructField("cmsId", LongType),
StructField("traffic", LongType),
StructField("ip", StringType),
StructField("city", StringType),
StructField("time", StringType),
StructField("day", StringType)
)
def parseLog(log:String) =
try
val splits = log.split("\\t")
val url = splits(1)
val traffic = splits(2).toLong
val ip = splits(3)
val domain = "http://www.imooc.com/"
val cms = url.substring(url.indexOf(domain) + domain.length)
val cmsTypeId = cms.split("/")
var cmsType = ""
var cmsId = 0l
if(cmsTypeId.length > 1)
cmsType = cmsTypeId(0)
cmsId = cmsTypeId(1).toLong
val city = IpUtils.getCity(ip)
val time = splits(0)
val day = time.substring(0, 10).replaceAll("-","")
// Row中的字段要和Struct中的字段对应
Row(url, cmsType, cmsId, traffic, ip, city, time ,day)
catch
case e:Exception => Row(0)
以上是关于大数据日志可视化分析(Hadoop+SparkSQL)的主要内容,如果未能解决你的问题,请参考以下文章