猿创征文|数据开发也能双轮驱动?
Posted 炒香菇的书呆子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了猿创征文|数据开发也能双轮驱动?相关的知识,希望对你有一定的参考价值。
本篇文章主要讲解DataFactory的维度建模概念,业务驱动模型开发流程以及两种开发模式的对比。
通过本文了解DataFactory双轮驱动指哪两种开发模式?它们的具体流程是什么?分别适合什么场景?如何选择适合自己的模式?助力大家数据开发之旅~
DataFactory数据开发两种模式
DataFactory概览
DataFactory是一个全场景,一站式的数据开发平台,DataFactory涵盖了集成,建模,运算,治理,探索,存储整个端到端的功能,同时也提供了多种开放模式。
DataFactory可以让用户沉淀资产,编排过程中产生的工程,app等应用可以作为我们的资产。而产生的工程可以作为自研领域的DPL,由DPL语言来描述生产运行过程,DPL语言屏蔽了具体的引擎技术栈,可以在长时间内沉淀数据开发应用资产,具有较强的兼容性。
下图简略的描述了DataFactory开发流程步骤,在接入数据之后,进行模型开发,数据探索,把数据进行清洗,转换,达到我们想要的数据处理结果。处理后的结果支持大屏程序,支持我们后续的运营和运维。

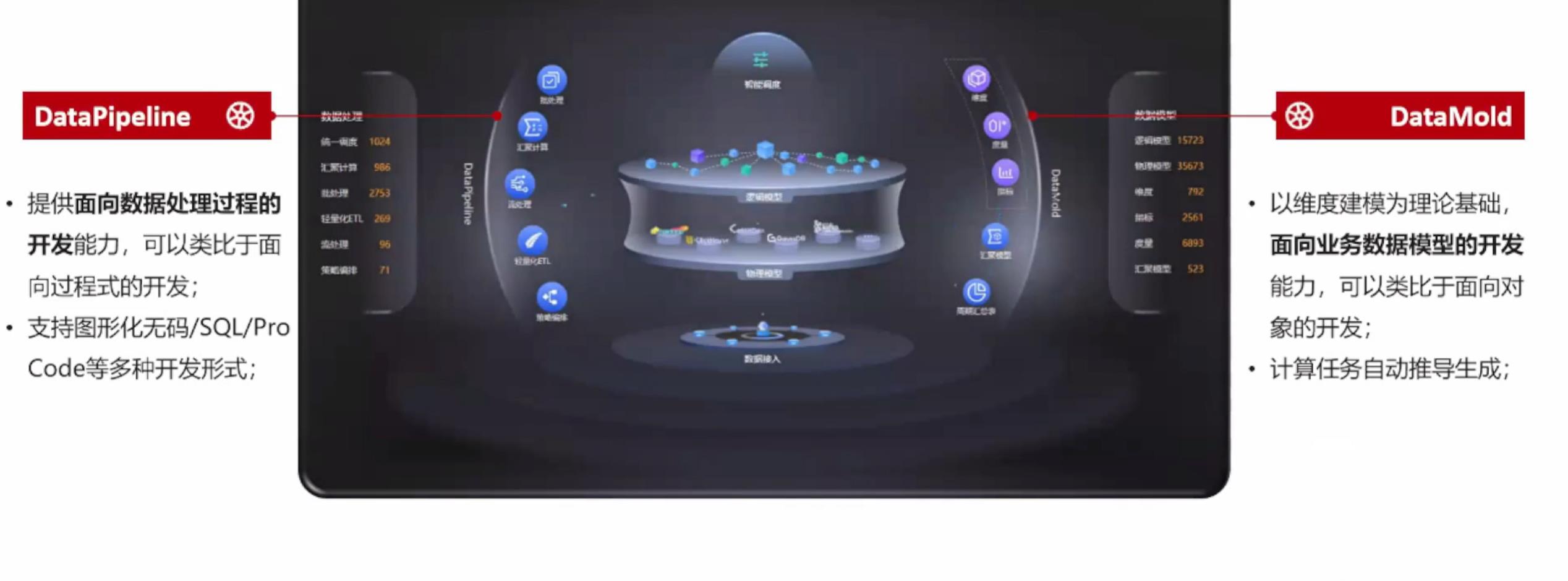
DataPipeline提供面向数据处理过程的开发能力,可以类比于面向过程式的开发,它将数据处理的步骤简化成一个结点,每个结点组合成一个管道,数据从管道中流过的时候,从一个结点到另外一个结点,面向的是数据处理的过程,同时也支持图形化无码/SQL/ProCode等多种开发形式。
第二种开发模式DataMold以维度建模为理论基础,面向业务数据模型的开发能力,基于业务抽象模型,以模型来驱动开发,更聚焦于业务逻辑本身,可以类比于面向对象的开发,计算任务自动推导生成;
这两种模式都是DataFactory非常重要的模式,下面我们对两种模式进行一个详细的对比。
面向数据处理过程开发
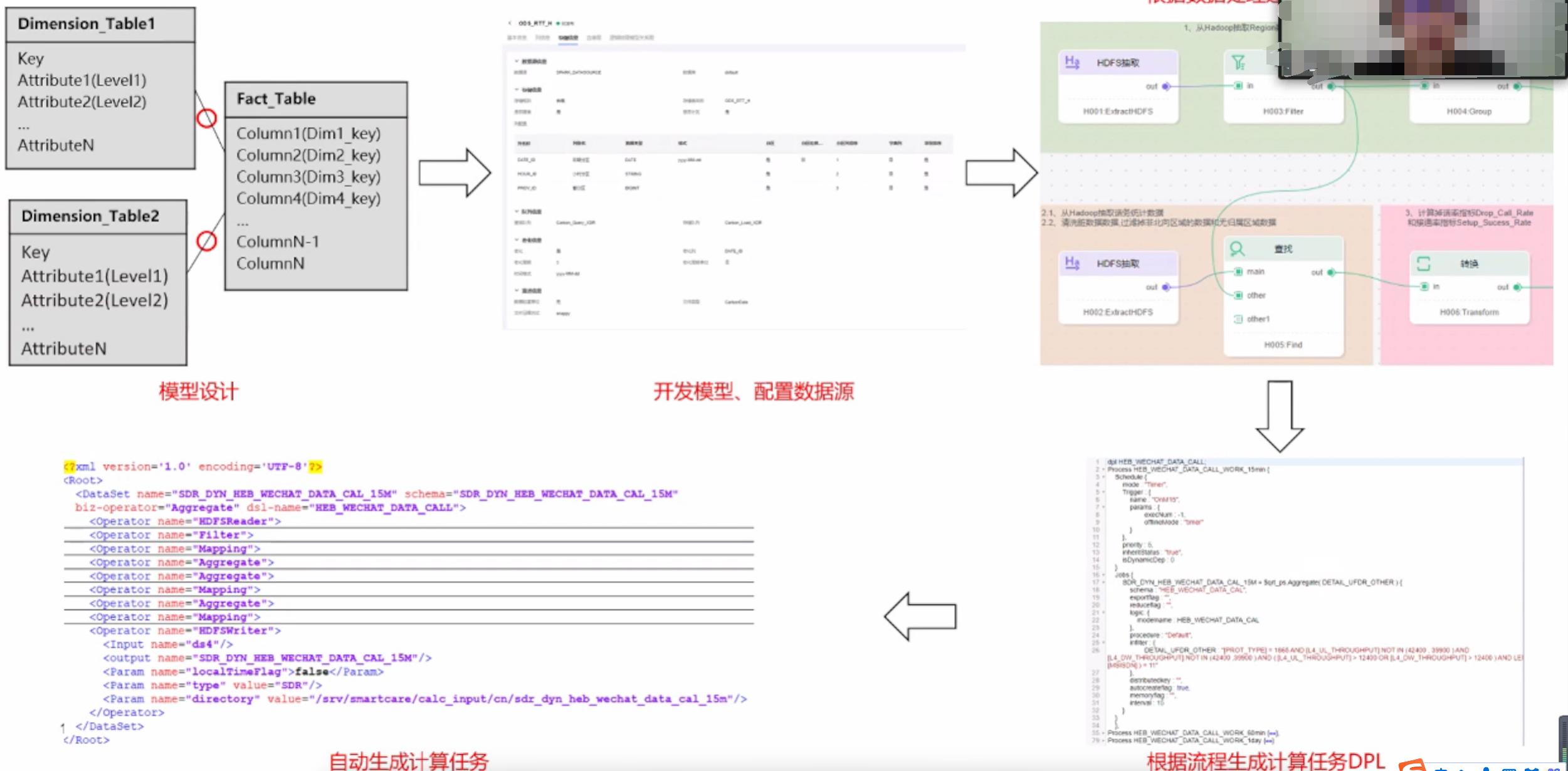
面向数据处理过程开发首先要先将业务和数据梳理出来,然后根据数据选择模型,将模型和数据源准备处理,下一步进入数据处理流程,每个单页提供一个数据处理模式,一步一步往下走。这个流程会被DataFactory转换成建模语言DPL。在后续进行编译转换可以将DPL转换成可直接使用的语言。
面向业务数据模型开发
DataMold通过建立星型模型,基于事实表定义度量,指标等业务模型,创建汇聚模型的统计周期,这一步以后,制定目标输出结果,开发汇聚计算任务,制定计算汇总周期,依赖引擎。后续根据配置生产DPL语言。

两种模式对比
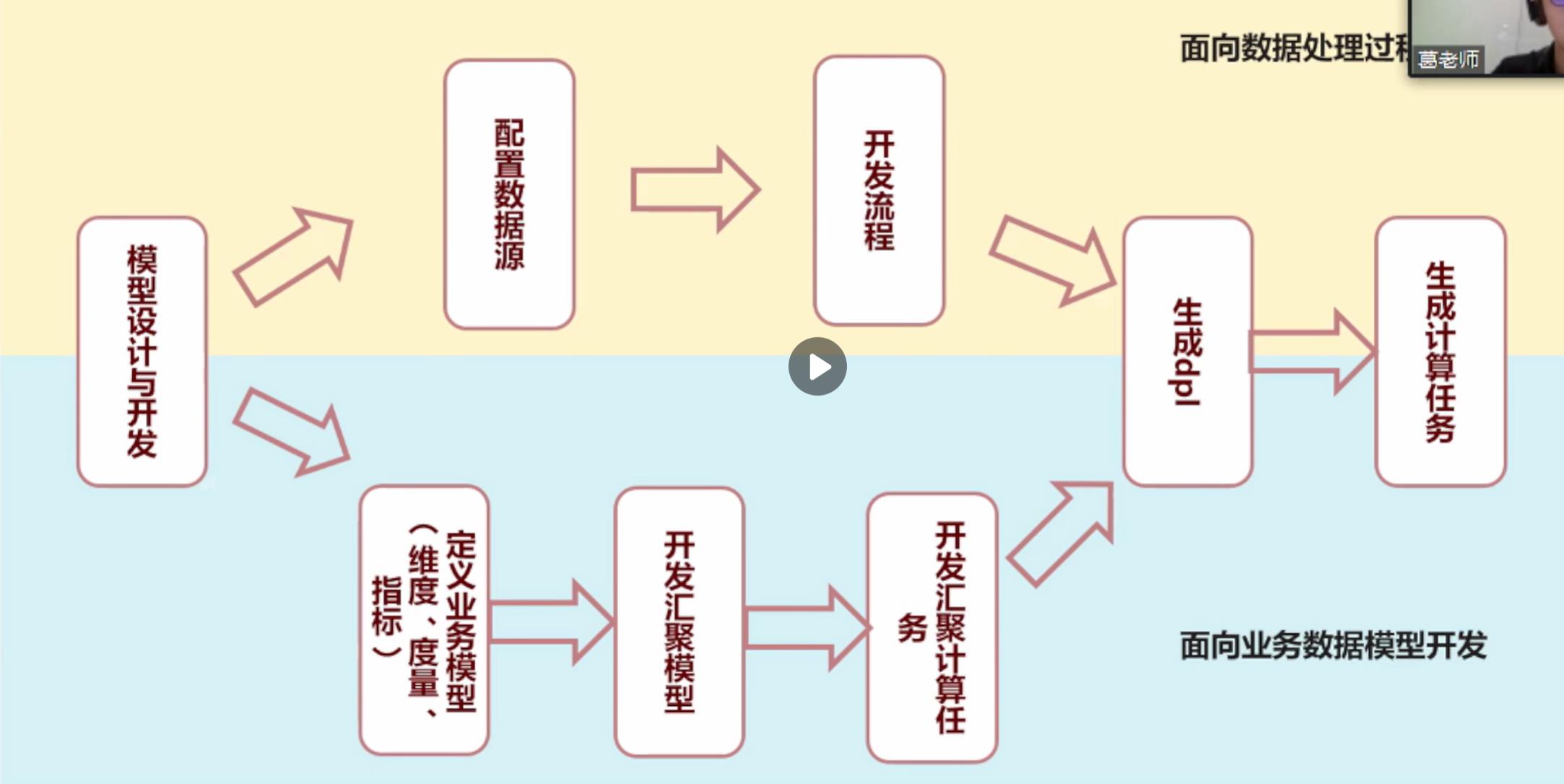
要把业务转换成模型语言,首先要对其进行抽象,明确业务来源,格式,字段。中间的过程是两种开发模式有区别的地方。这个流程详细的描述了数据处理的每一个过程,一开始设计的模型,并没有指定数据怎样进行计算,业务相关的模型需要放到汇聚模型,生成计算任务进而生成DPL建模语言。
面向业务数据模型的开发流程
概述
面向业务数据模型开发,是模型驱动开发与维度建模的有机结合。
模型驱动开发MDD (Model Driven Development)的基本思想是让开发中心从编程、制造等具体最终实现转 移到高级别抽象中去.诵过模型转成代码来驱动部分或全部的自动化开发。

维度建模按照事实表、维度表来构建数据仓库、数据集市,面向分析场景而生,针对分析场景构
建数仓模型。
重点关注如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。星型模型和雪花模型就是典型的维度模型。我们在进行维度建模的时候会建一张事实表,这个事实表就是星型模型的中心维度表就是向外发散的星星。
常用术语
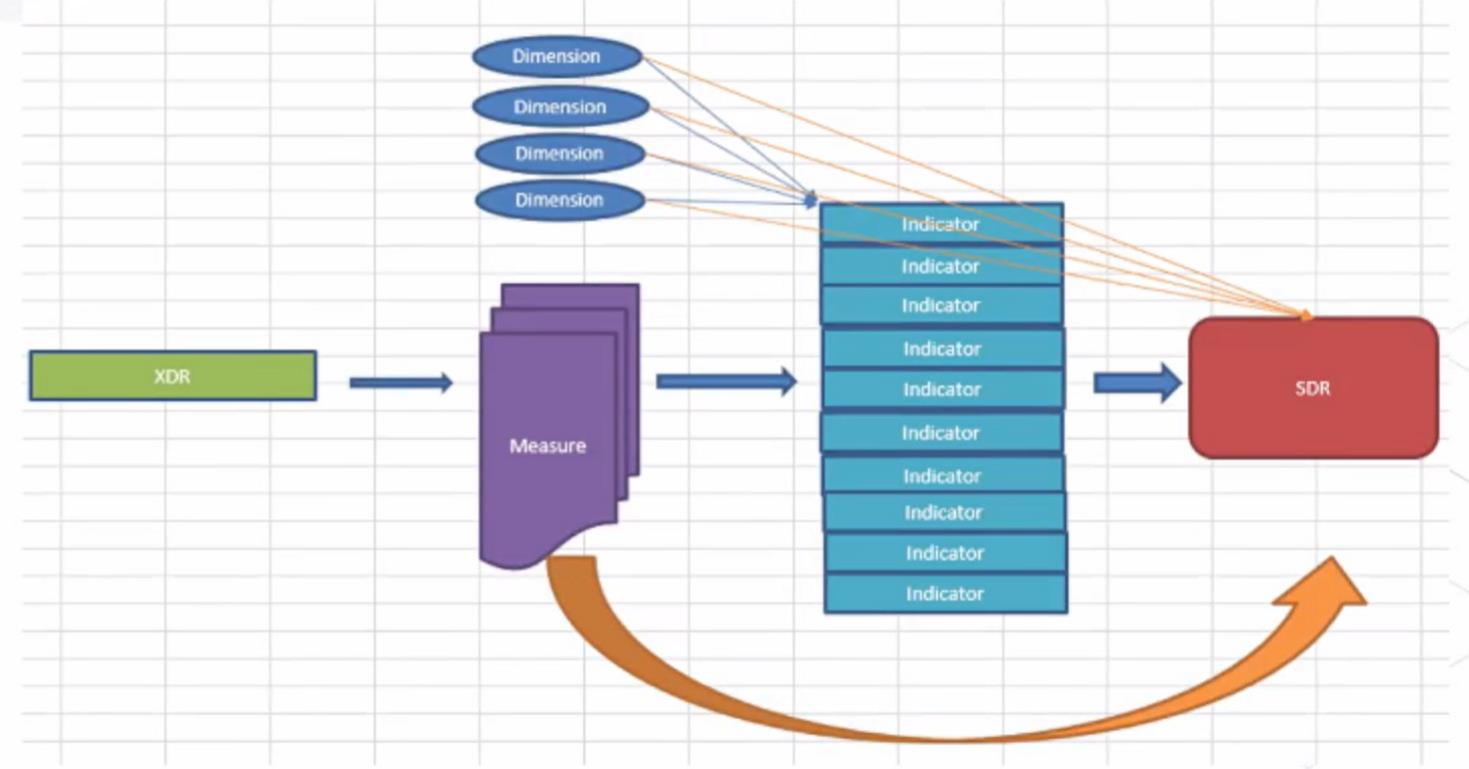
详单表(XDR) : x Detail Record CDR(呼叫详细记录)单据。又叫事实表。事实表中存放的事实数据,通常包含大量的数据行。事实表的主要特点是包含数值数据(事实)。
维度(Dimension) :是人们观察数据的特定角度,是考虑问题时的一类属性,属性集合构成。在统计过程中用于汇聚,聚合,例如按照用户的维度统计某用户的一天上网的总流量。
度量(Measure) :定义基于详单进行的计数统计,更偏重于网络或系统层面,例如“通话创建成功次数"和"通话创建请求次数"等。
指标(Indicator):定义基于Measure计算结果后的统计,更偏重与用户关注的指标层面,例如“PDP创建成功率",其计算公式: (PDP创建成功次数/PDP创建请求次数)*100。
SDR表: Statistic Detail Record(统计详细记录),基于详单进行的用户指标统计,主要进行维度汇聚和指标计算,支撑上层应用查询。
开发流程详解
业务模型驱动的开发流程主要由一下几个步骤组成
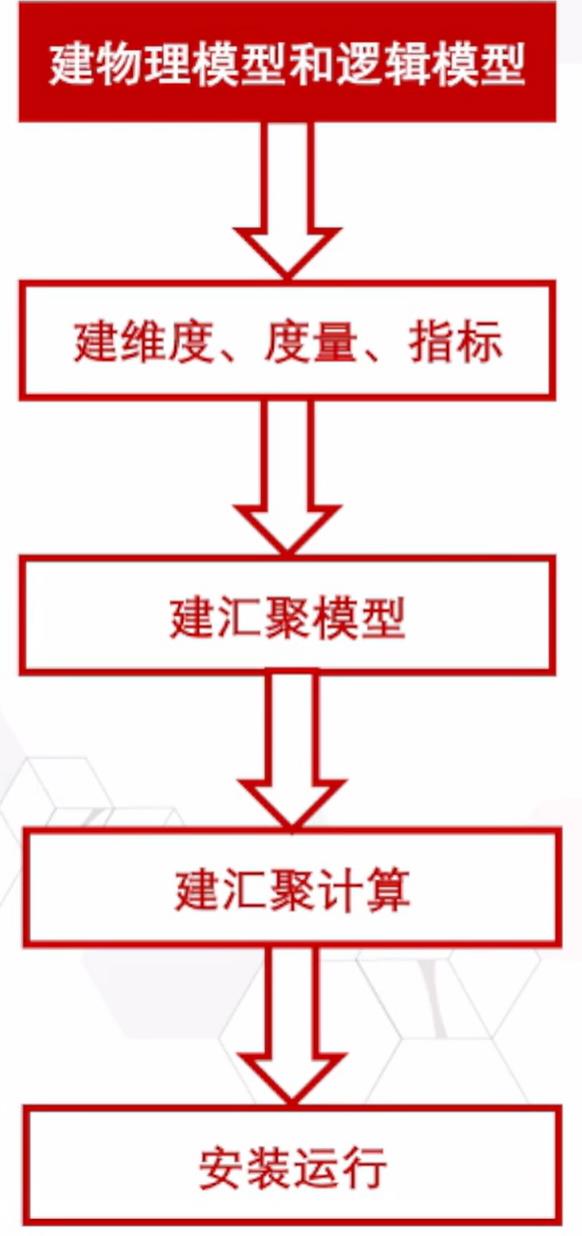
首先是模型选取模型包括逻辑模型和物理模型,逻辑模型描述的是实体,数据属性。物理模型在逻辑模型的基础上补充了逻辑模型缺少的上下文。例如数据粒度,维度,指标等,还会和硬件,操作系统等有关系。下图为实战过程中的一个逻辑模型,提供了数据表的类型,长度,业务在进行抽象时会将对象构建出来,再将上下文补全生成物理信息。
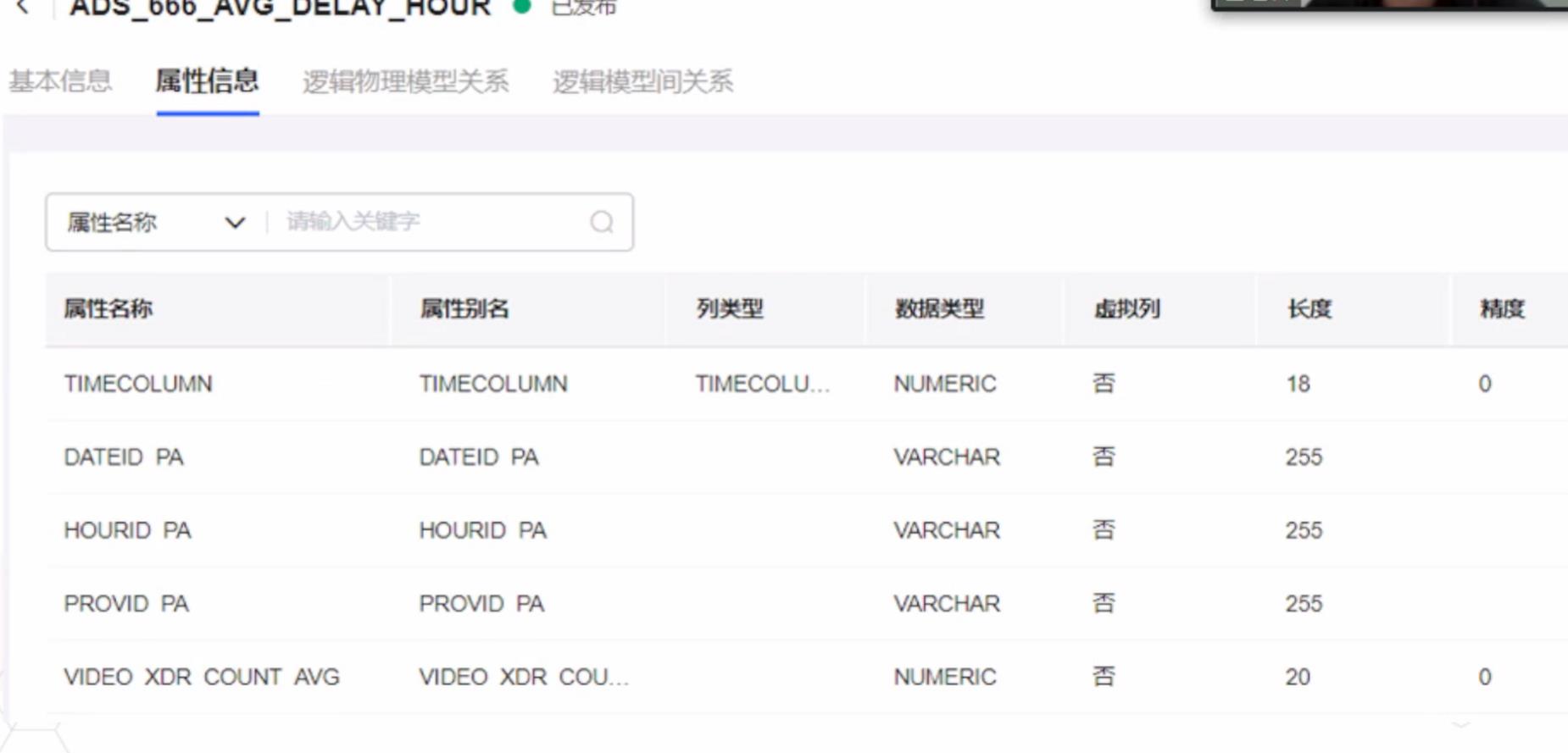
第二步为构建业务模型,也就是维度,度量和指标。主要是表达了我们计算上的逻辑,从不同的维度进行汇总并进行汇聚的计算。
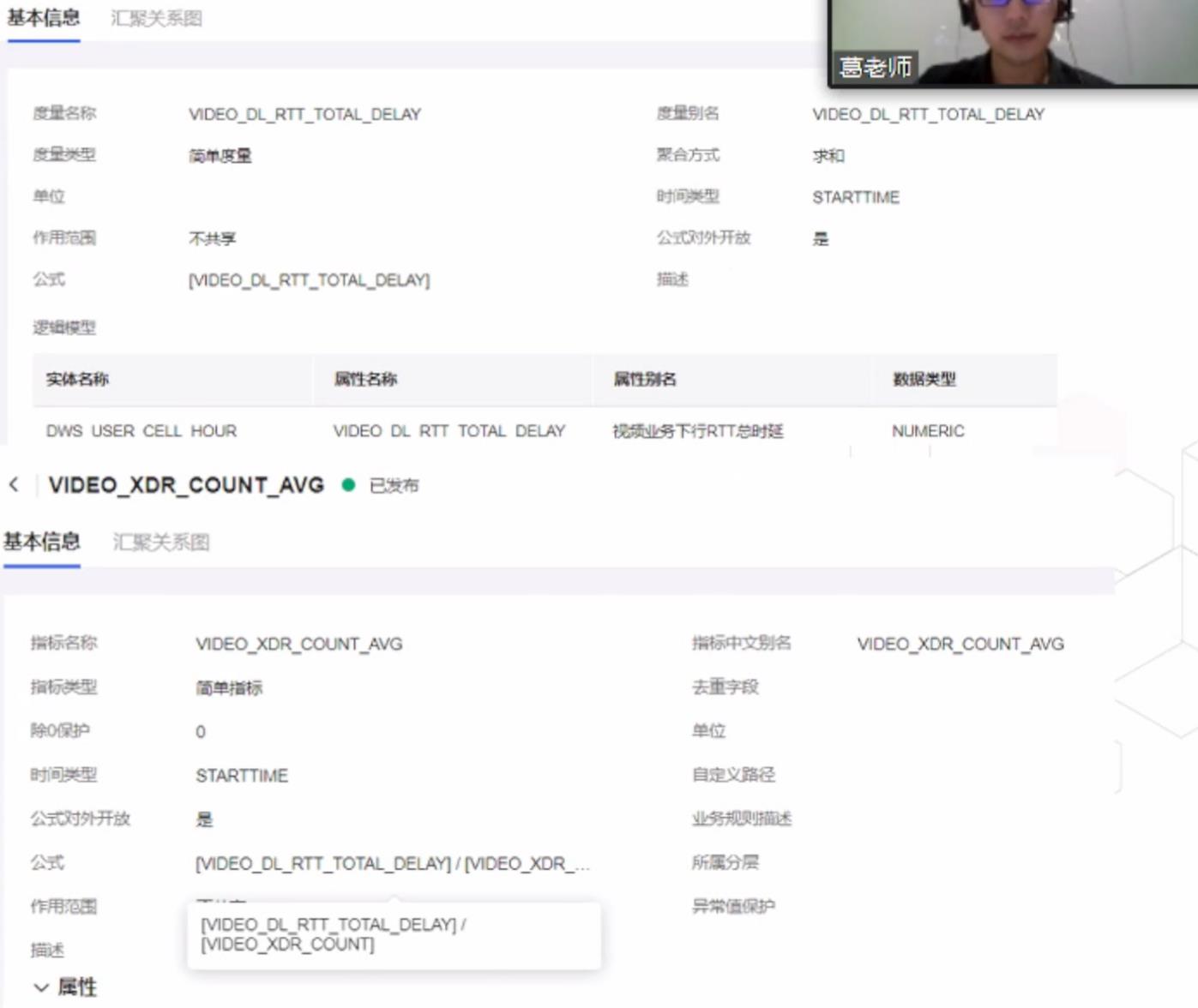
第三步是建立汇聚模型,定义输入和输出
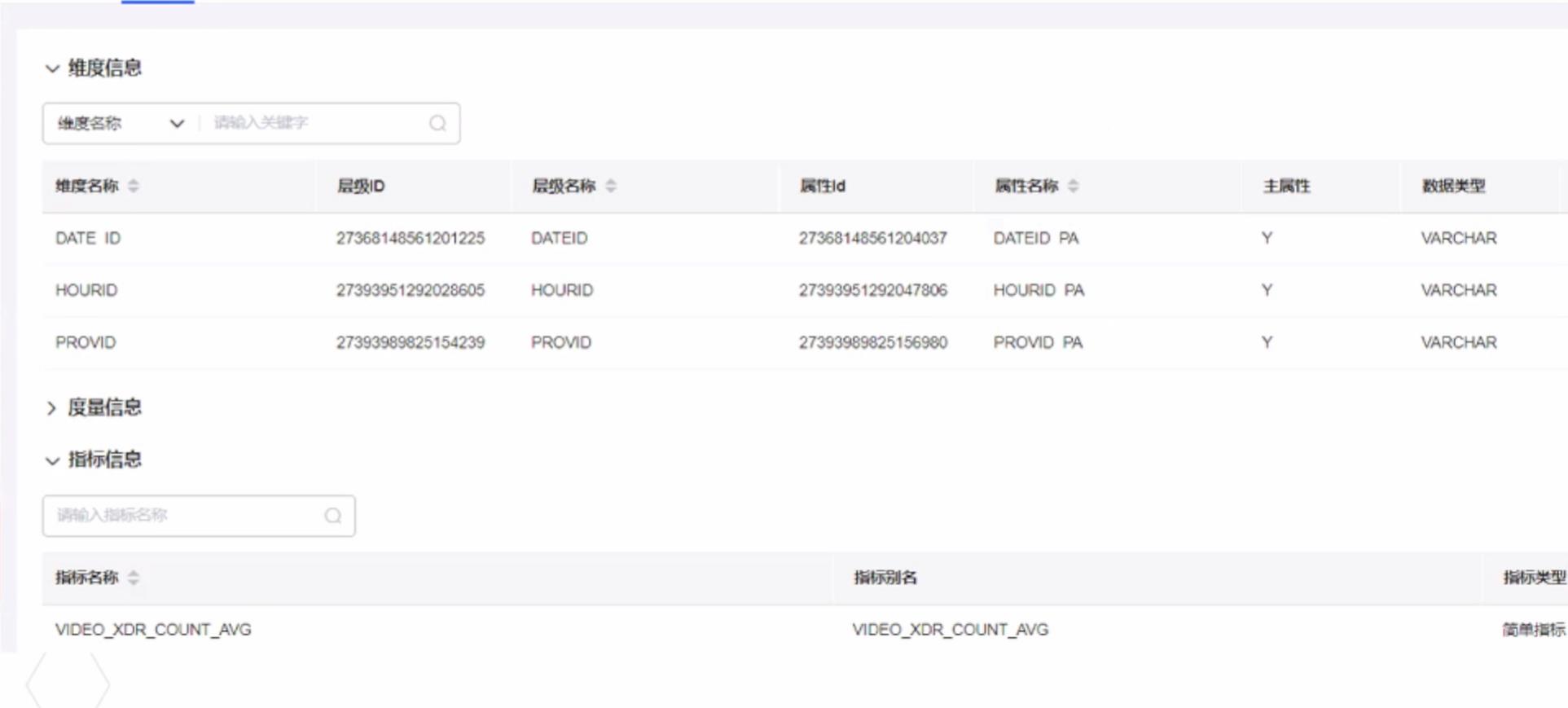
第四步是补充计算逻辑,如执行的偏移时间,执行次数,运行在哪个引擎并将命令下发
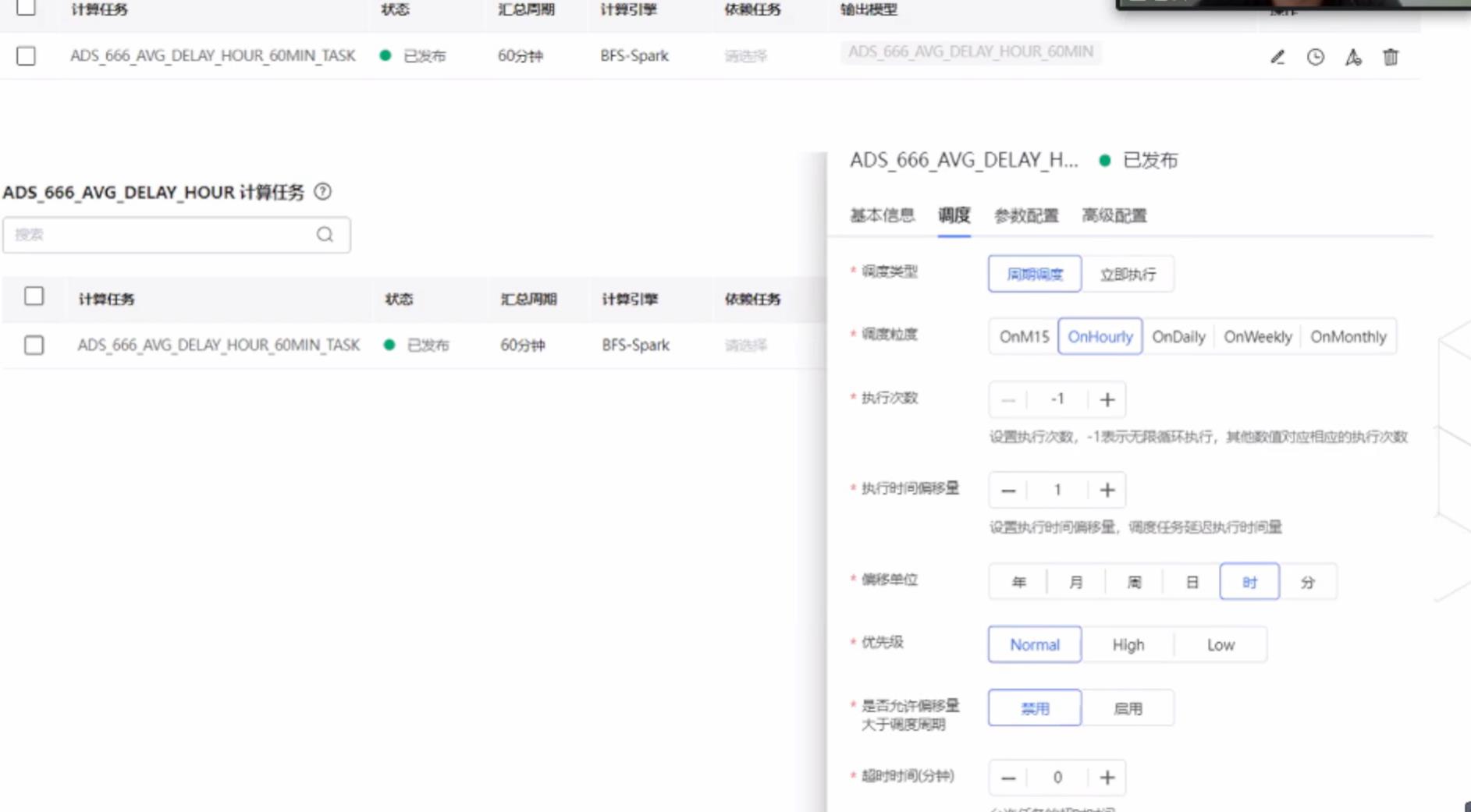
当把整个过程开发完毕,就可以进行编译打包,部署到运行的环境上,在一定的周期内执行并查看运行状况和计算结果
开发实战演练
下面通过简单的实战来区分一下两种开发模式
实现新需求:
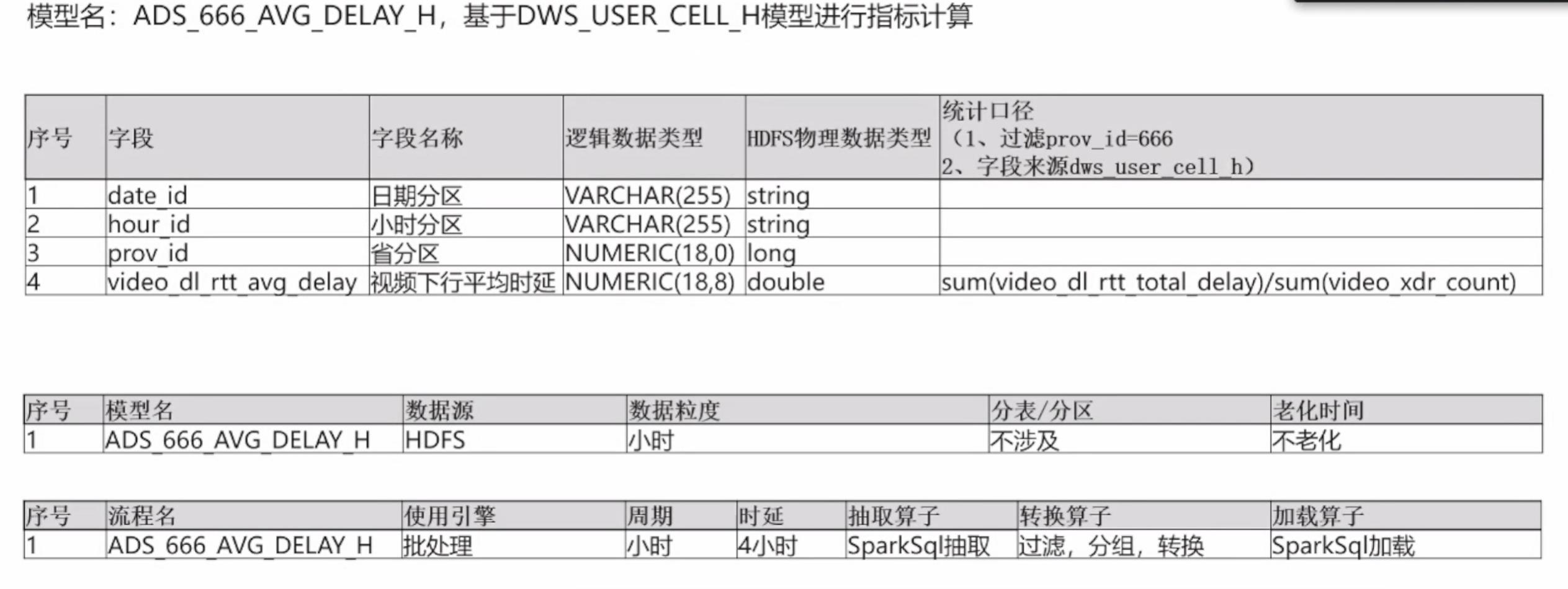
按小时粒度,统计某省(PROV_ID)=666)视频下行业务的平均时延。数据加载到HDFS指定目录
两种开发模式的对比
使用面向数据处理过程开发过程如下
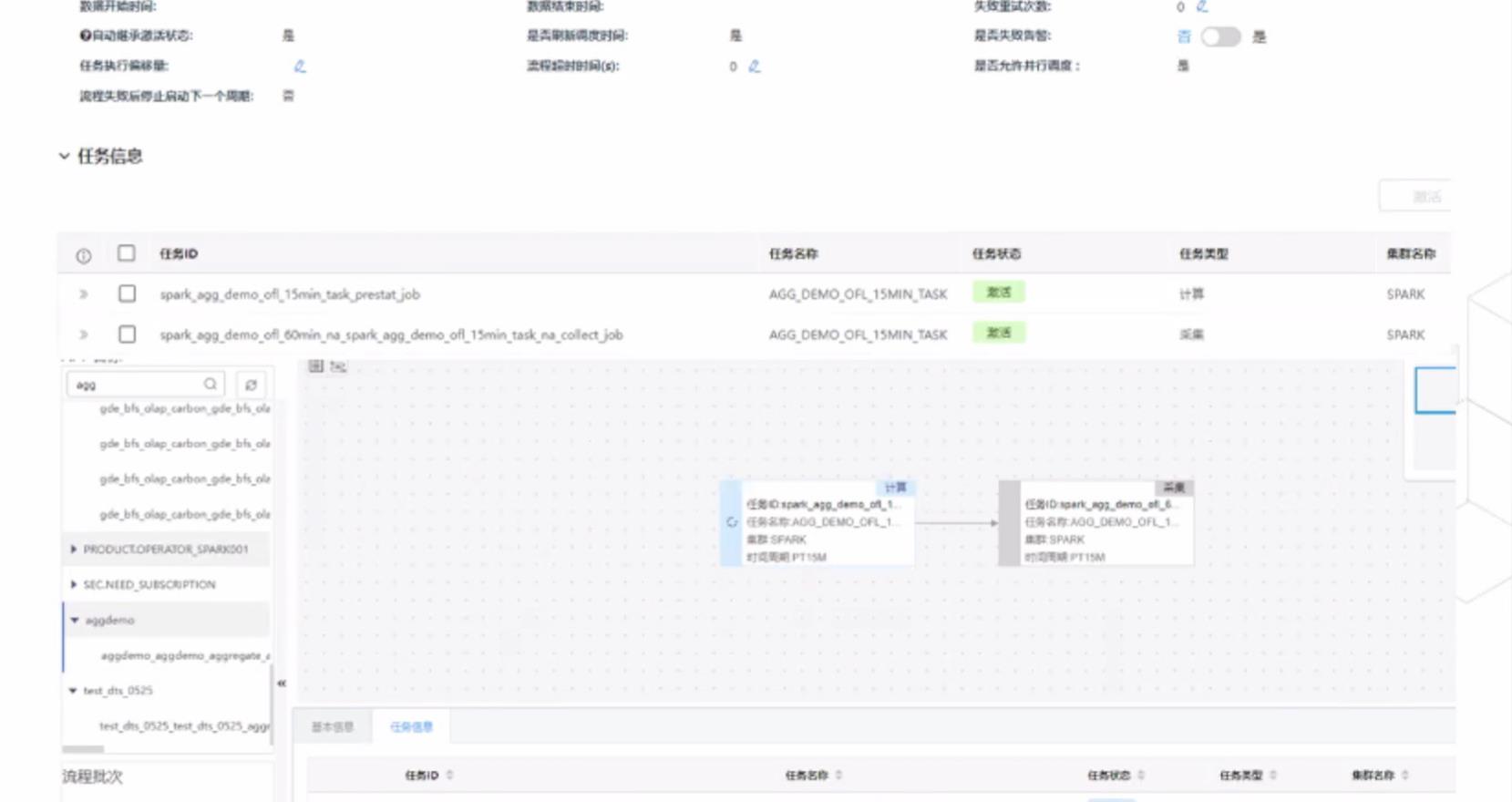
面向数据处理过程开发过程我们主要关注数据处理流程,用到的算子。根据需求我们首先建立模型,这里给出了日期,小时,省份,这三个角度对数据进行统计。
通过使用批处理将数据从源数据抽取出来进行过滤分组转换,计算出结果
实际环境操作如下图
首先建立一个数据流,划分小模块,进行过滤和计算,汇总等。
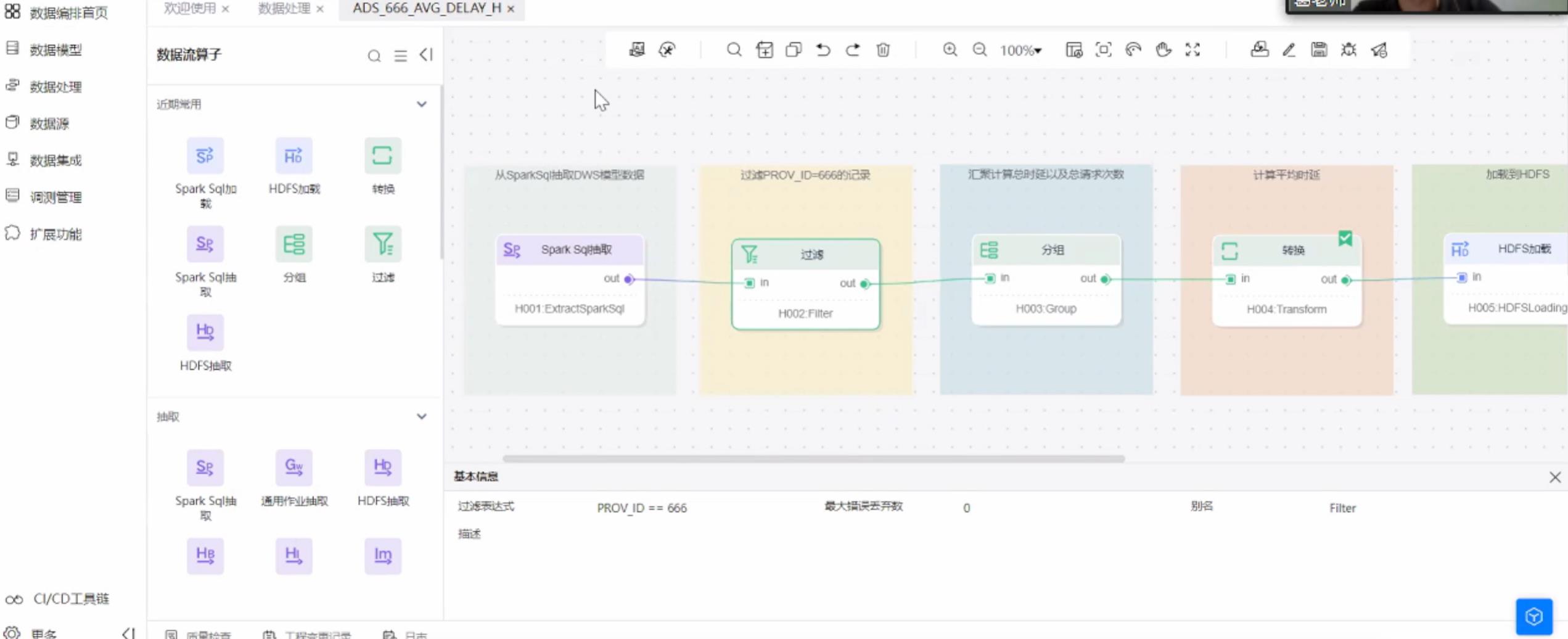
抽取数据,对省份数据为666的进行过滤并显示结果
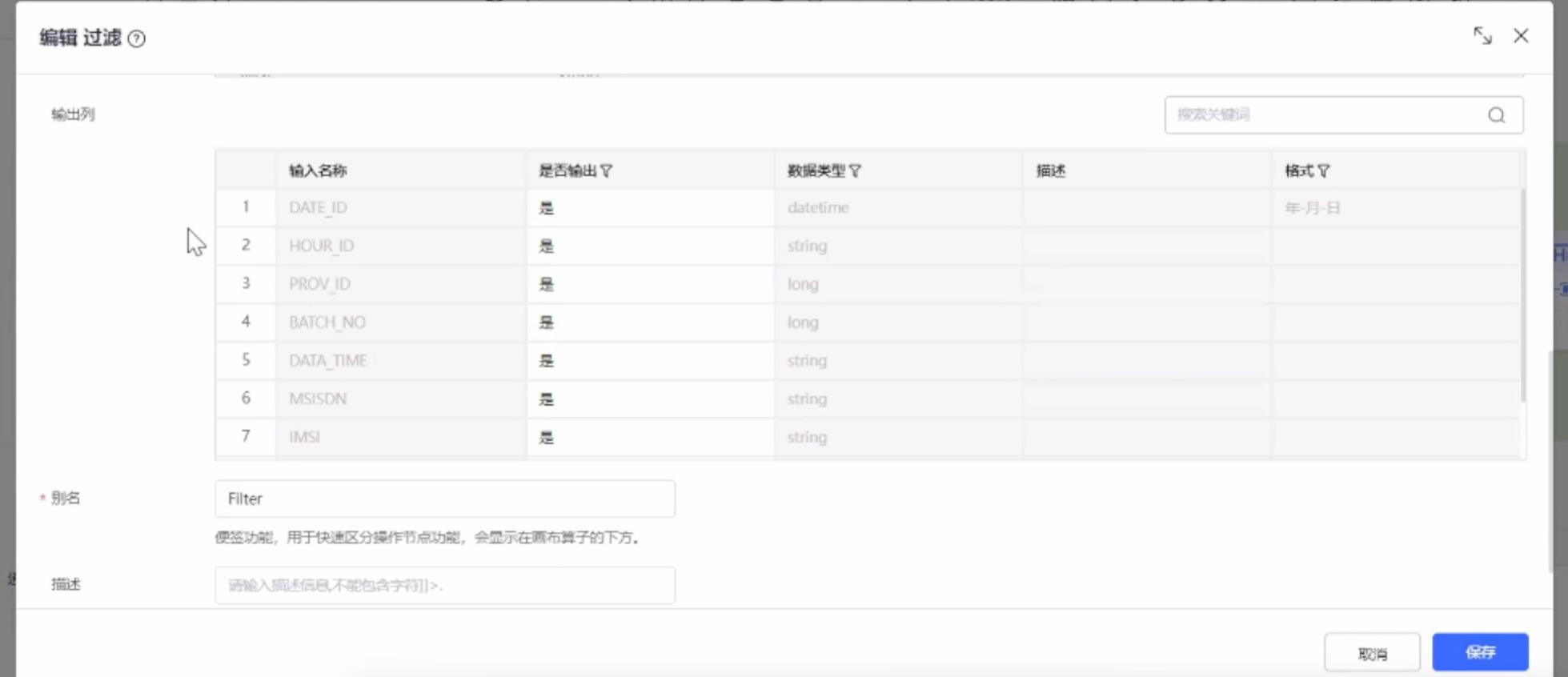
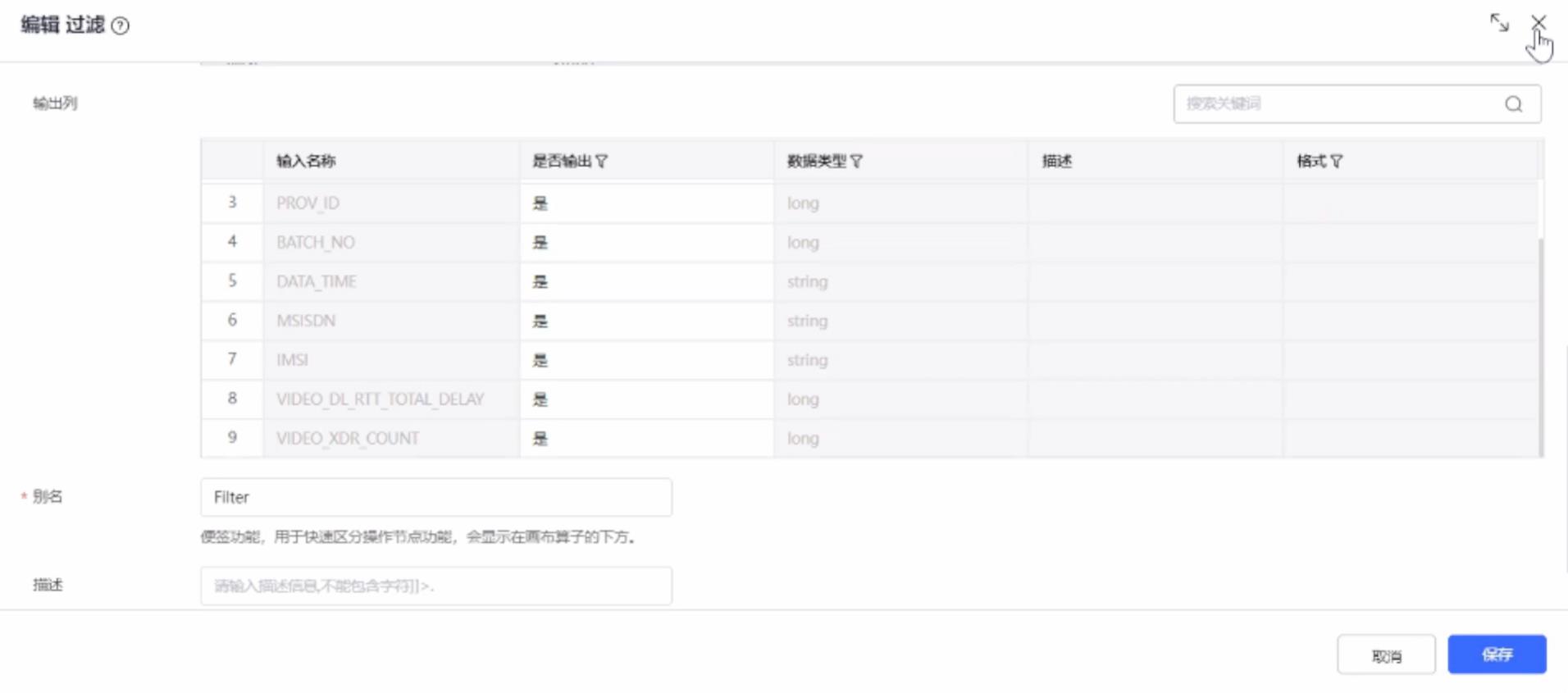
对数据进行分组,汇聚
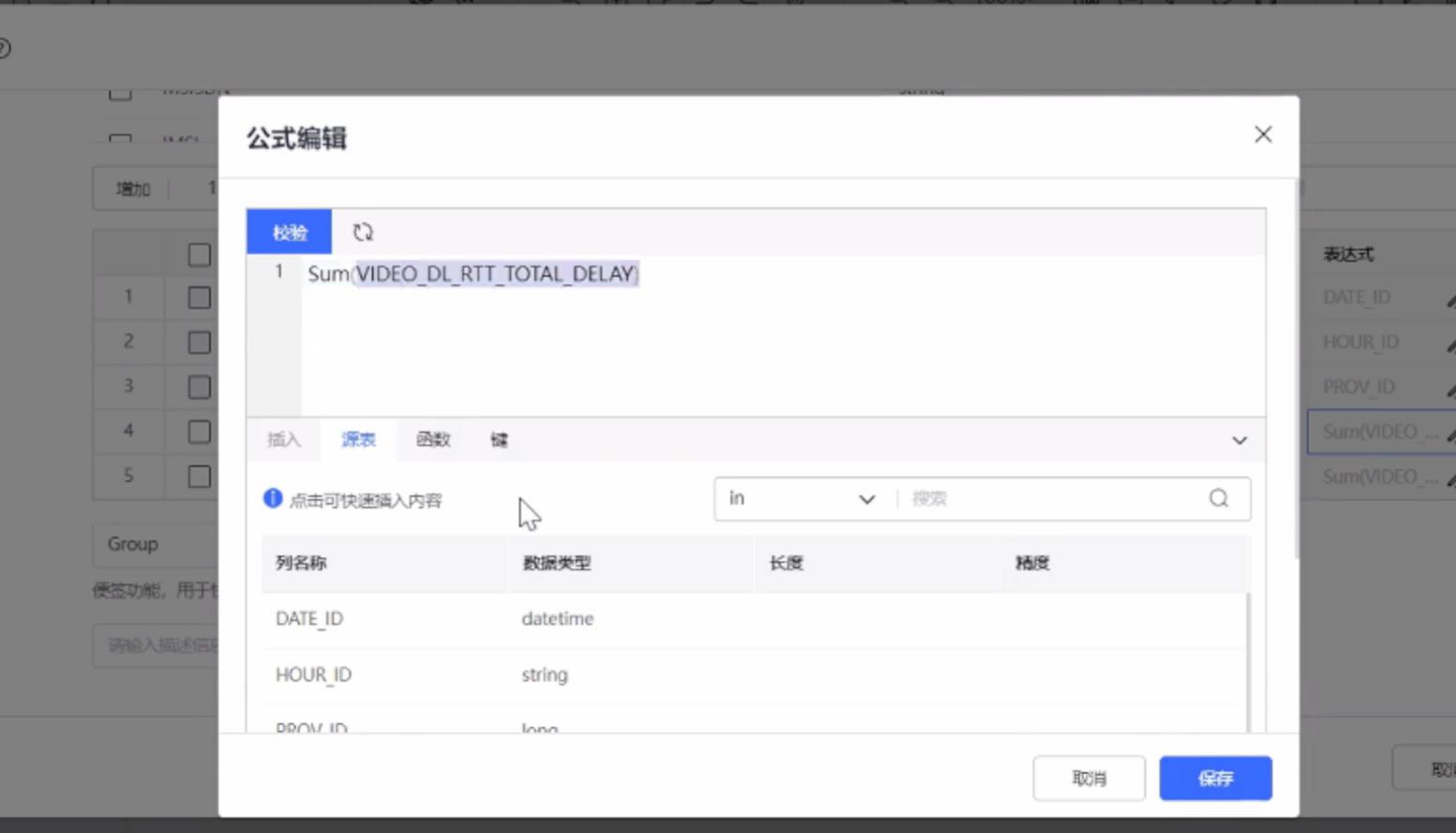
对数据求和求出平均值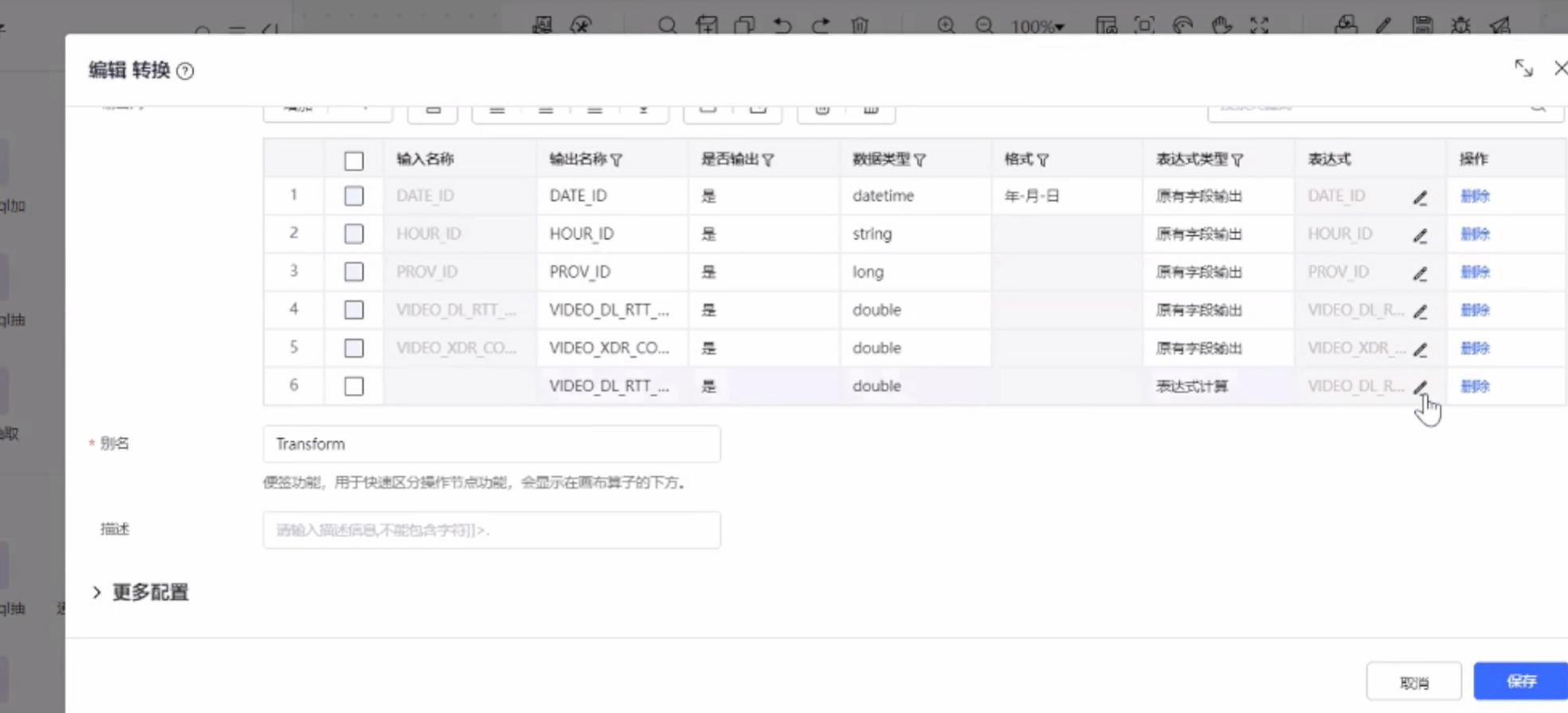
将数据存储到指定路径,完成操作。
面向业务数据模型开发流程相对复杂,但操作少了很多。
首先通过两个度量进行求和,然后对求和后数据进行出发,建立一个指标和维度进行组合形成我们需要的汇聚模型,应用到汇聚计算任务。在处理过程中,加入过滤任务,指定引擎种类来完成对应任务。

实际操作流程如下
通过基于已有表进行数据开发,下表记录了某一次请求的时延。
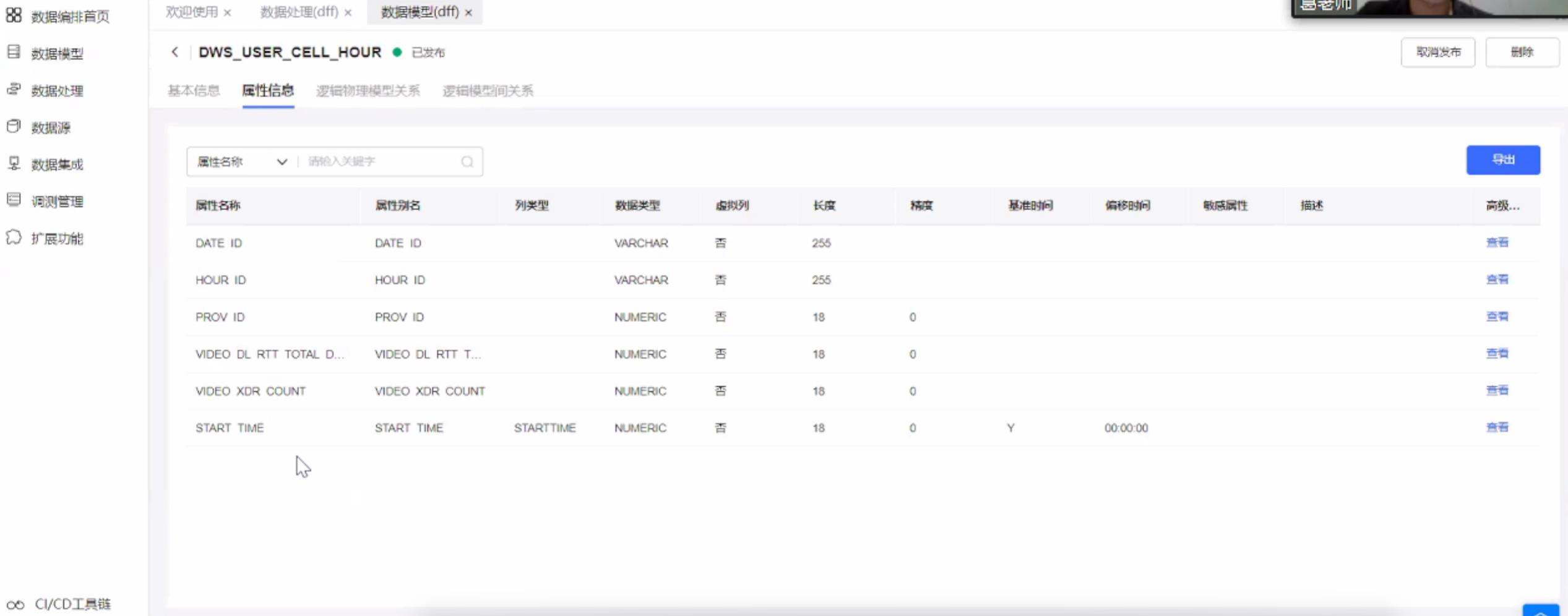
首先要建立逻辑模型和物理模型,根据图标已经得到逻辑模型,再根据上下文建立物理模型。
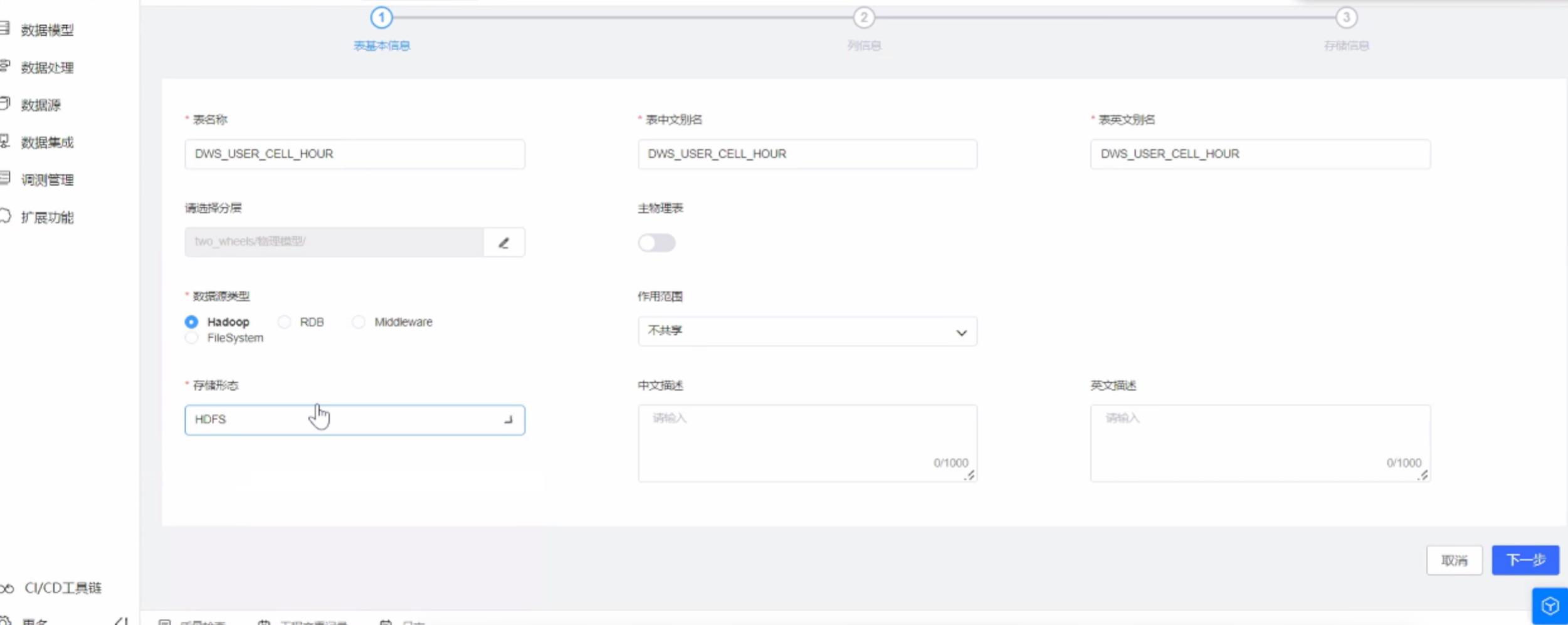
数据源一般由系统自动提供并预制了很多模板。
下一步为建立维度,指定计算模型。
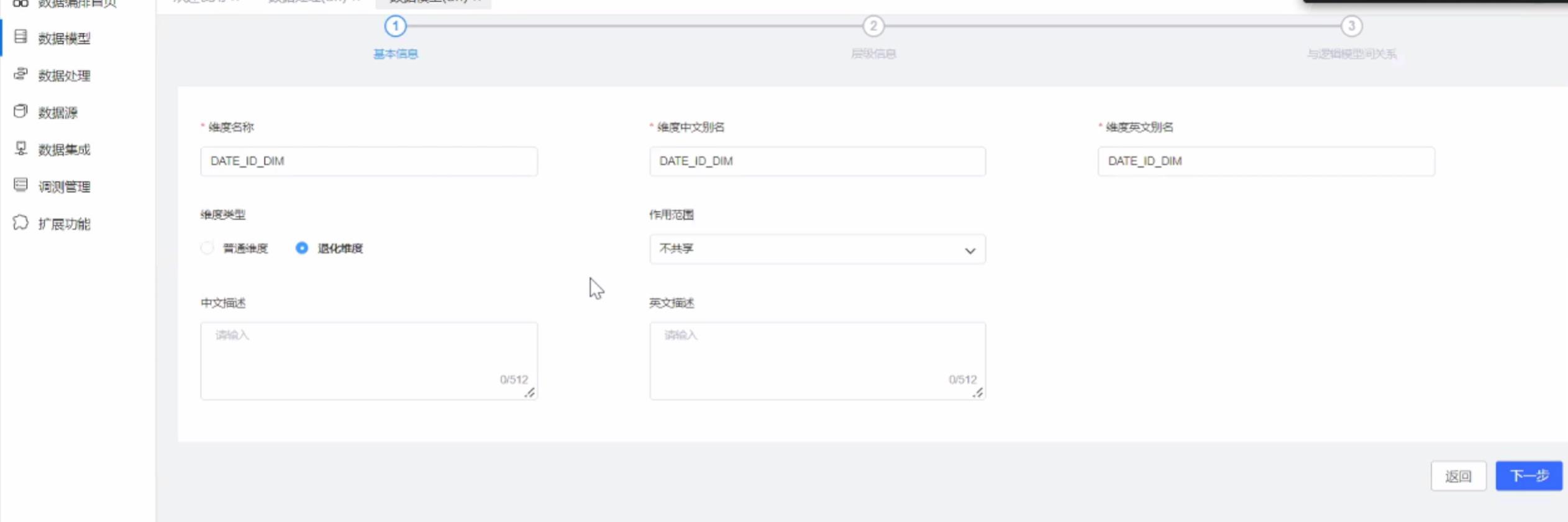
这里的层级表示维度的不同层。
第三步创建维度与逻辑模型的关系。
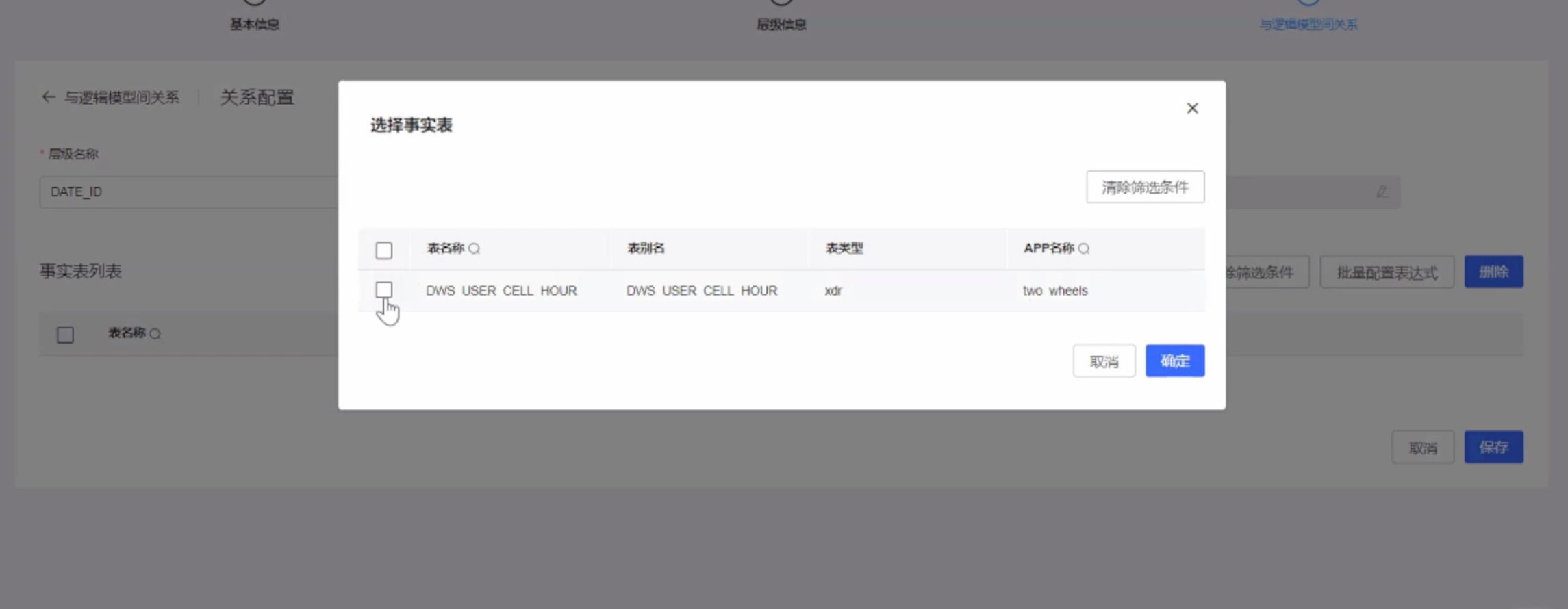
最后对省份进行筛选并进行相关数据关联
面向数据处理过程开发
- 低门槛,业务人员、无基础或弱基础开发者也可上手
- 数据开发,支持可视化调试;
- 经过抽象,复用程度高;
- 图形化表达与技术实现解耦,支持资产沉淀;·能处理复杂计算场景
- 需要学习掌握后才能进行项目开发;
- 配置较多算子
面向业务数据模型开发
- 需要学习掌握后才能进行项目开发;
- 配置较多算子
- 适用于基于即有的优质事实表开发;
- 仅支持HDFS文件作为输入输出
- 不支持调试,验证较麻烦
两种开发适用场景对比
两者不是非此即彼的关系,没有最好的,只有最适合的。

总结
这两年在人工智能、大数据、云计算等技术的飞速发展下,一个火爆的理念正在迅速传播开,那就是各行各业正在如火如荼的进行着数字化转型。政企在数字化转型中,需要技术人员将传统业务IT化,以实现流程+工具+制度的运作方式,最终完成数字化转型。华为GDE平台将华为多年内部管理运作经验及工具打包,现向外提供整套解决方案,让业务人员通过低代码、流程编排、数据编排完成IT工具搭建,进而实现数字化转型的关键一步。
最后,祝华为GDE平台越来越好, GDE平台的用户借助平台能力及早实现数字化转型,提升核心竞争力,成为行业领导者。
以上是关于猿创征文|数据开发也能双轮驱动?的主要内容,如果未能解决你的问题,请参考以下文章