翻译: Deep Learning深度学习平台Hugging Face 开源代码和技术构建训练和部署 ML 模型
Posted AI架构师易筋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了翻译: Deep Learning深度学习平台Hugging Face 开源代码和技术构建训练和部署 ML 模型相关的知识,希望对你有一定的参考价值。
1. 什么是Hugging Face🤗
Hugging Face 是一个社区和数据科学平台,提供:
- 使用户能够基于开源 (OS) 代码和技术构建、训练和部署 ML 模型的工具。
- 一个广泛的数据科学家、研究人员和 ML 工程师社区可以聚集在一起分享想法、获得支持并为开源项目做出贡献的地方。
2. 🔥 通过社区推进人工智能
随着最近向混合和灵活工作实践的转变,我们开始看到更多地使用和采用使数据科学团队、专家和业余爱好者能够远程协作的工具。
事实上,在人工智能的进步方面,操作系统社区变得越来越重要。没有任何一家公司,甚至“科技巨头”都无法靠自己的力量“解决人工智能”——共享知识和资源以加速和推进是未来的发展方向!
Hugging Face 通过提供一个社区“中心”来满足这一需求。这是一个任何人都可以共享和探索模型和数据集的中心位置。他们希望成为一个拥有最多模型和数据集的地方,目标是让所有人的人工智能民主化。
3. 🚀 入门 -> Git 的托管库
当您注册成为 Hugging Face 的成员时,您将获得一个基于 Git 的托管存储库,您可以在其中存储:模型、数据集和空间。我们将在本节的后面部分深入挖掘其中的每一个。
现在让我们开始运行吧!
注册成为社区个人贡献者是免费的。也有一个“专业”计划和单独的付费版。
我继续注册了,在这个过程中你还可以链接到主页、Github 和 Twitter 帐户,如下图所示:
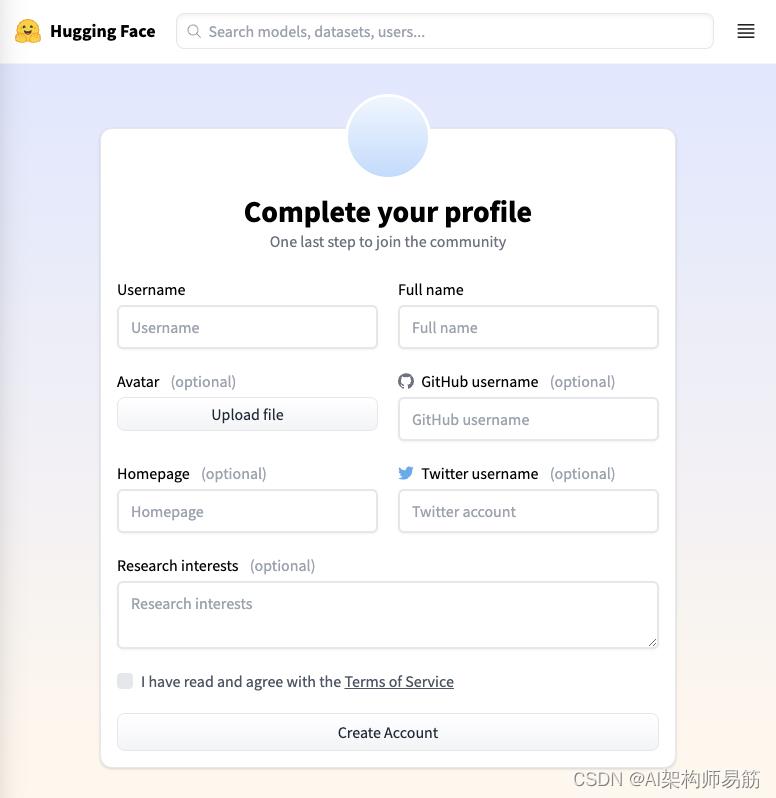
图 1:hugging face,社区帐户注册表单
创建帐户后,您将被重定向到您的个人存储库。在此页面中,您可以做很多事情,包括:
- 查看您的活动源
- 查看您的个人资料和设置
- 创建新模型、数据集或空间
- 查看 Hugging Face 社区当前的流行趋势
- 查看您所属的组织列表并跳转到各自的领域
- 利用有用的资源和文档
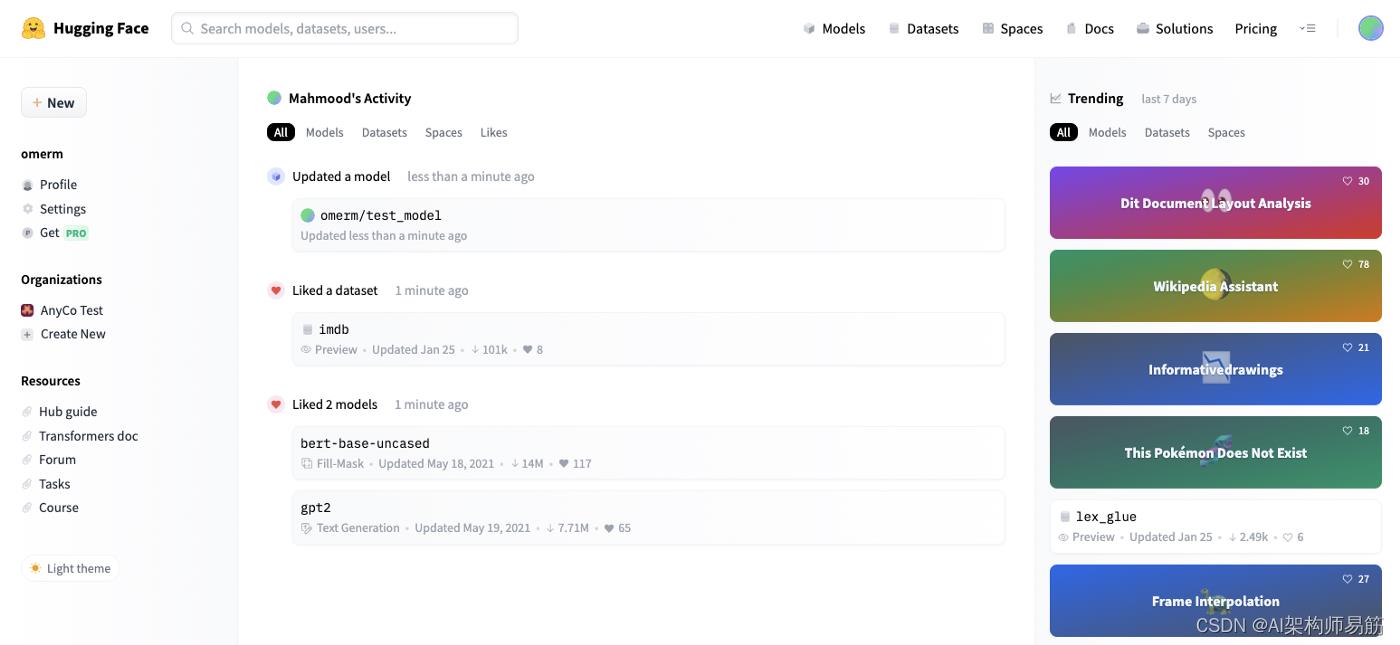
图 2:hugging face,用户配置文件/存储库
存储库的核心是您的活动提要,当您开始创建(或喜欢)模型、数据集和空间时,它会被填充。
现在我们已经启动并运行了,让我们进行更深入的研究…
3.1 Model 模型
当您创建一个新的“模型”时,它实际上是一个 Git 存储库,用于存储与您要共享的 ML 模型相关的文件。它具有您期望的所有好处,例如版本控制、分支、可发现性等。
💡 我将在本节中描述的步骤(包括数据集和空间)都可以使用Hub API Endpoints通过命令行以编程方式实现。
单击 Hub 中的“+新建”按钮,然后选择“模型”,您将进入一个对话框,您可以在其中指定名称和操作系统许可证的类型,您将根据这些许可证贡献模型的代码和相关资产。
您还可以控制模型的可见性,即使其公开并使其对 Hugging Face 社区可见或在您的个人存储库或组织中保持私有。
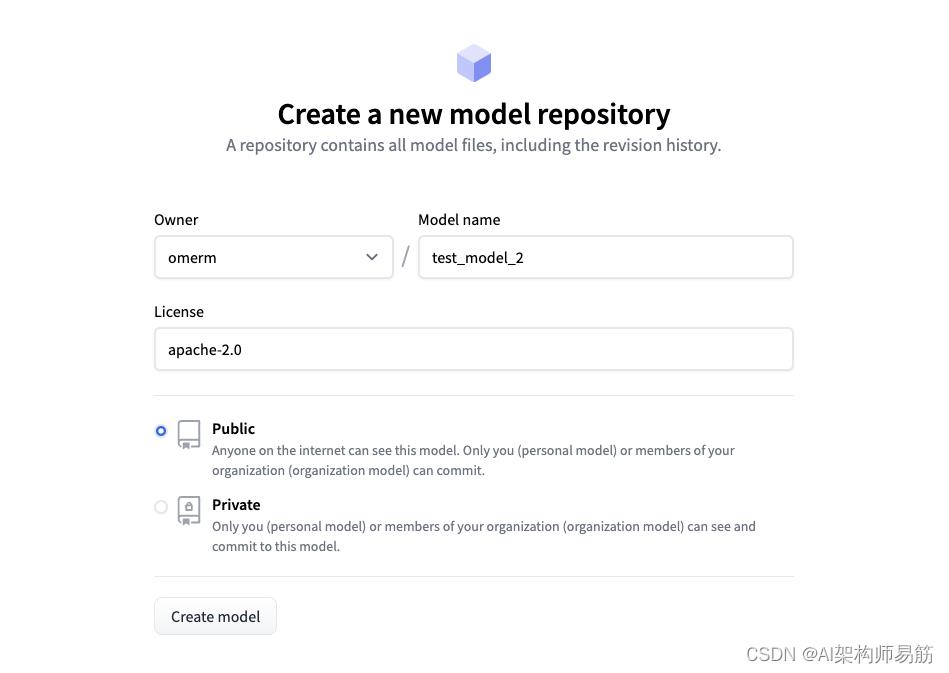
图 3:Hugging Face,创建一个新的模型存储库
创建模型后,您将进入存储库视图,默认选择“模型卡”选项卡:在创建后,您将进入存储库视图,默认选择“模型卡”选项卡:
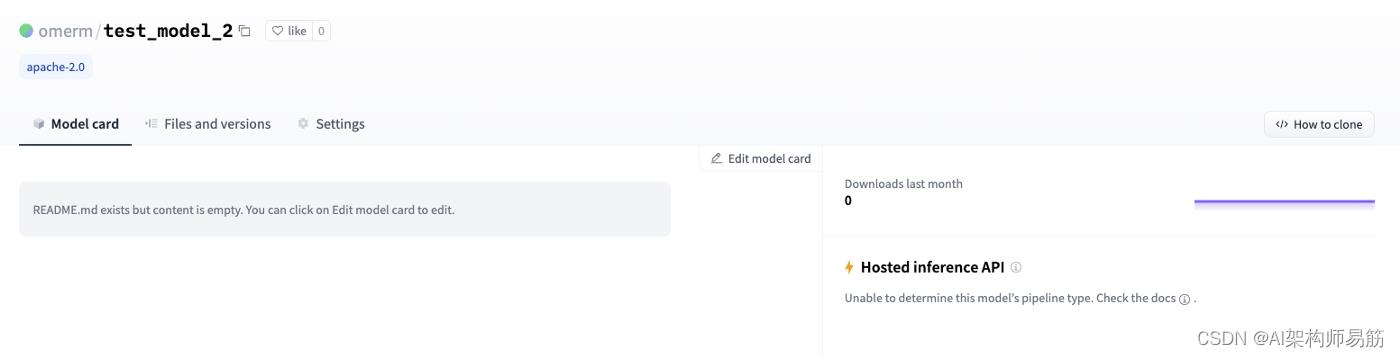
图 4:hugging face,新模型库,模型卡
对于普通的 Git 用户,“文件和版本”选项卡会很熟悉:
图 5:hugging face新模型存储库、文件和版本
我的模型库目前是空的,但下面的屏幕截图显示了一个完全填充的模型卡对于 Hugging Face 社区模型之一的需求:
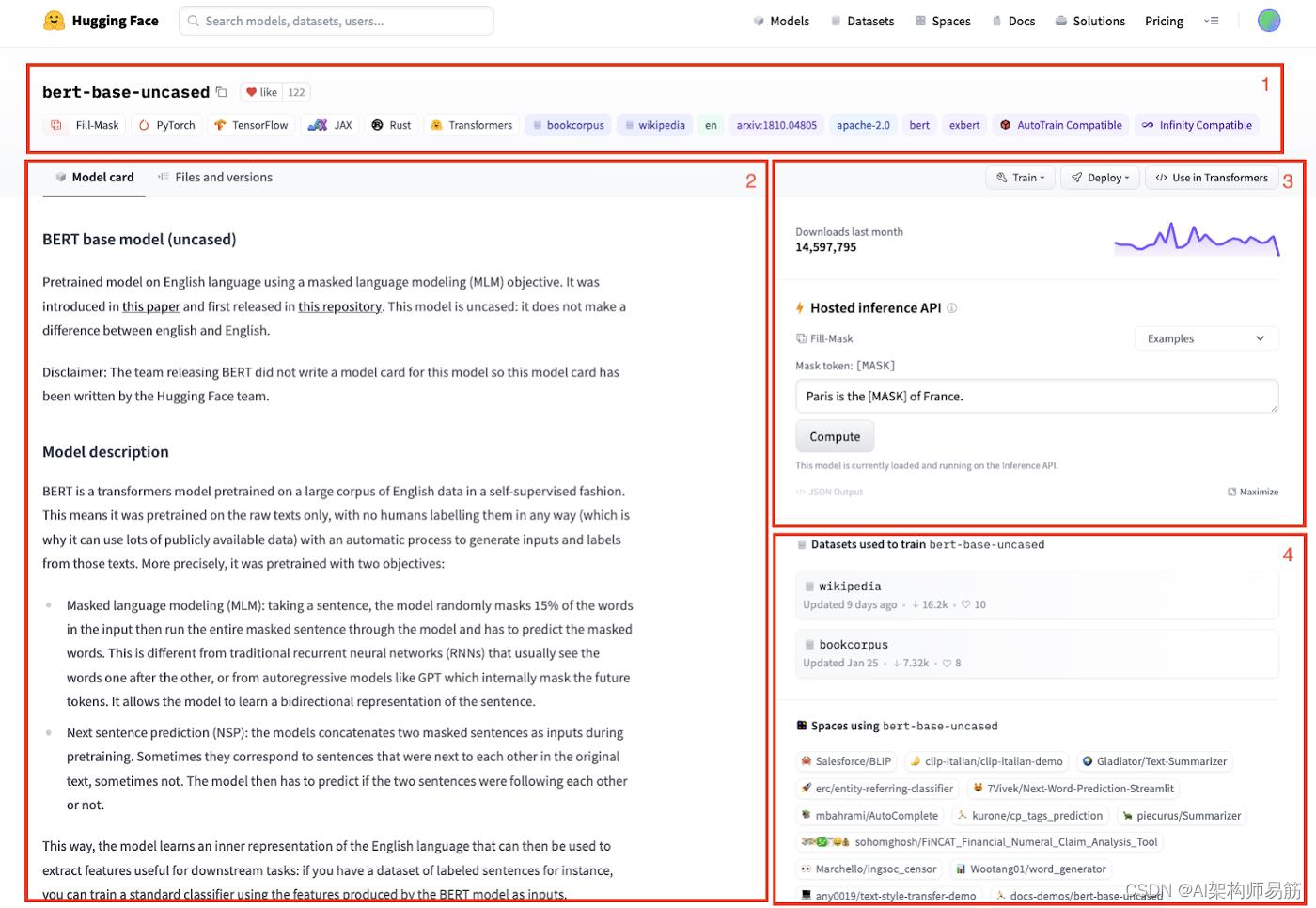
图 6:hugging face Bert base model(uncased),模型卡
元素介绍:
- 在顶部,我们有模型名称、喜欢和紧跟在与模型关联的标签下方。如框架、模型类型和其他属性。
- 模型卡的主体可用于给出模型的概述、如何使用它的代码片段、约束和任何其他相关信息。此项目的内容是通过使用正确的标签填充模型存储库中的 README.md 文件来确定的。
- 您可以训练模型以对其进行微调,甚至可以通过指向AWS SageMaker实例或 Hugging Face 自己的Infinity容器化基础设施来部署它。如果您想在自己的代码中使用模型,‘</> Use…’ 将弹出一个代码片段,说明如何根据用于构建模型的框架导入它。另一个非常简洁的功能是托管推理 API,它允许您显示一个小部件,该小部件允许用户将样本值传递给模型以测试其输出。Hosted Inference API 小部件由模型文件中包含的元数据确定。
- 最后,您还可以查看有关哪些数据集用于训练模型以及使用该模型的空间的元数据。
💡拥有详细的模型卡很重要,因为它可以帮助用户了解何时以及如何应用您的模型
3.2 Dataset数据集
创建新数据集遵循与创建新模型非常相似的流程。单击 Hub 中的“+ New”按钮,然后选择“Dataset”。您指定名称、许可证类型、公共或私人访问权限。然后您会看到一个存储库视图,其中包含“数据集卡”、“文件和版本”,类似于模型存储库中的内容。
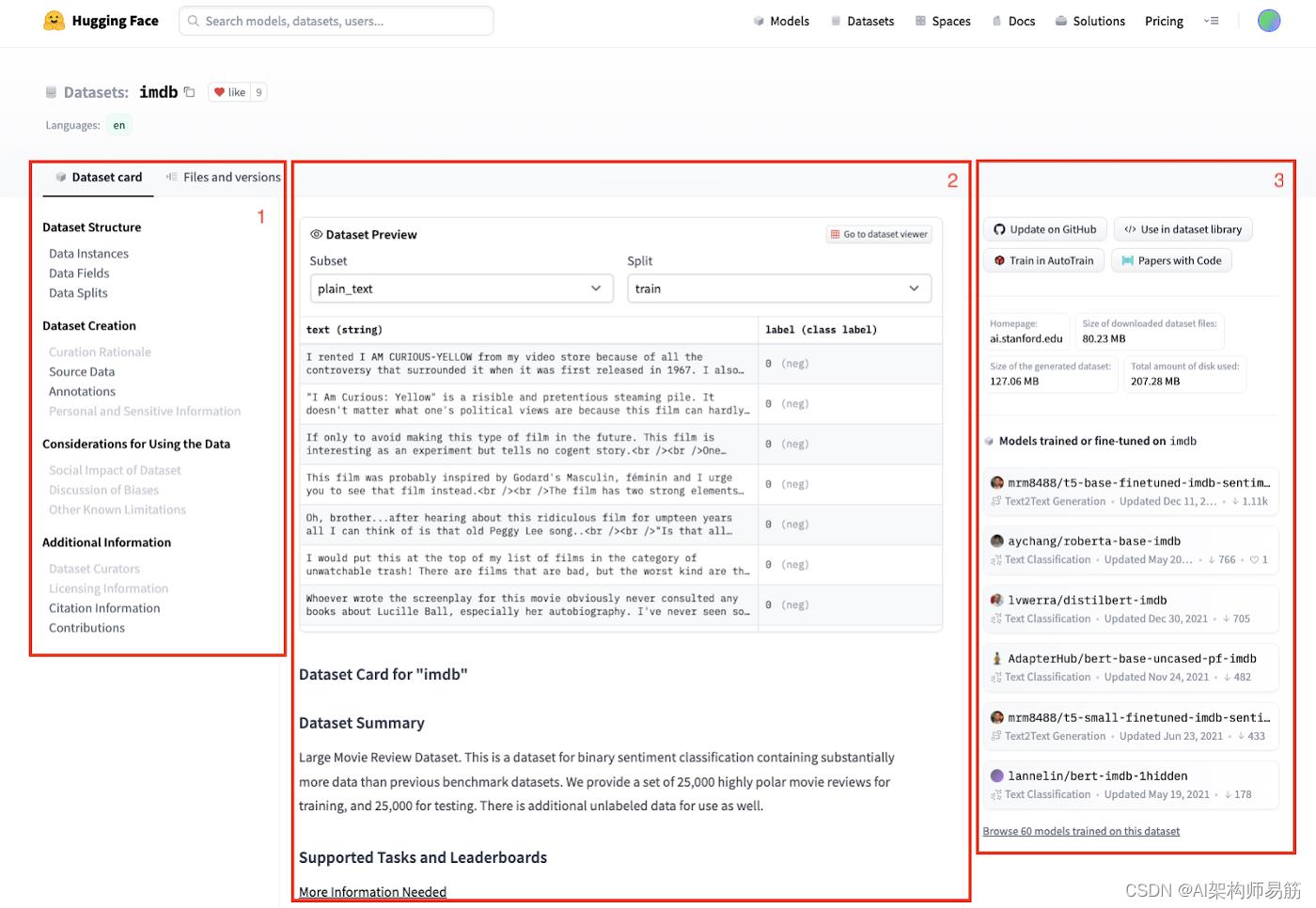
图 7:hugging face,imdb 数据集,数据集卡
再次强调关键要素:
- 除了数据集标题、喜欢和标签外,您还可以获得一个目录,以便您可以跳到数据集卡片正文中的相关部分。
- 数据集卡的主体可以配置为包含嵌入式数据集预览。这非常方便,因为它显示了特征、数据拆分和子集(如果有)。这些项目和之前项目的内容是通过使用正确的标签填充数据集存储库中的 README.md 文件来确定的。
- 最后,您可以快速链接到 GitHub 存储库,以及通过 Hugging Face python 数据集库使用数据集的代码片段。还有其他元数据,例如数据集的来源、大小以及 Hugging Face 社区中的哪些模型已在数据集上进行过训练。
3.3 Spaces空间
Spaces 为您提供了一个以自包含 ML 演示应用程序的形式展示您的工作的地方。如果您正在寻找灵感,有很多社区贡献的空间可供您查看。
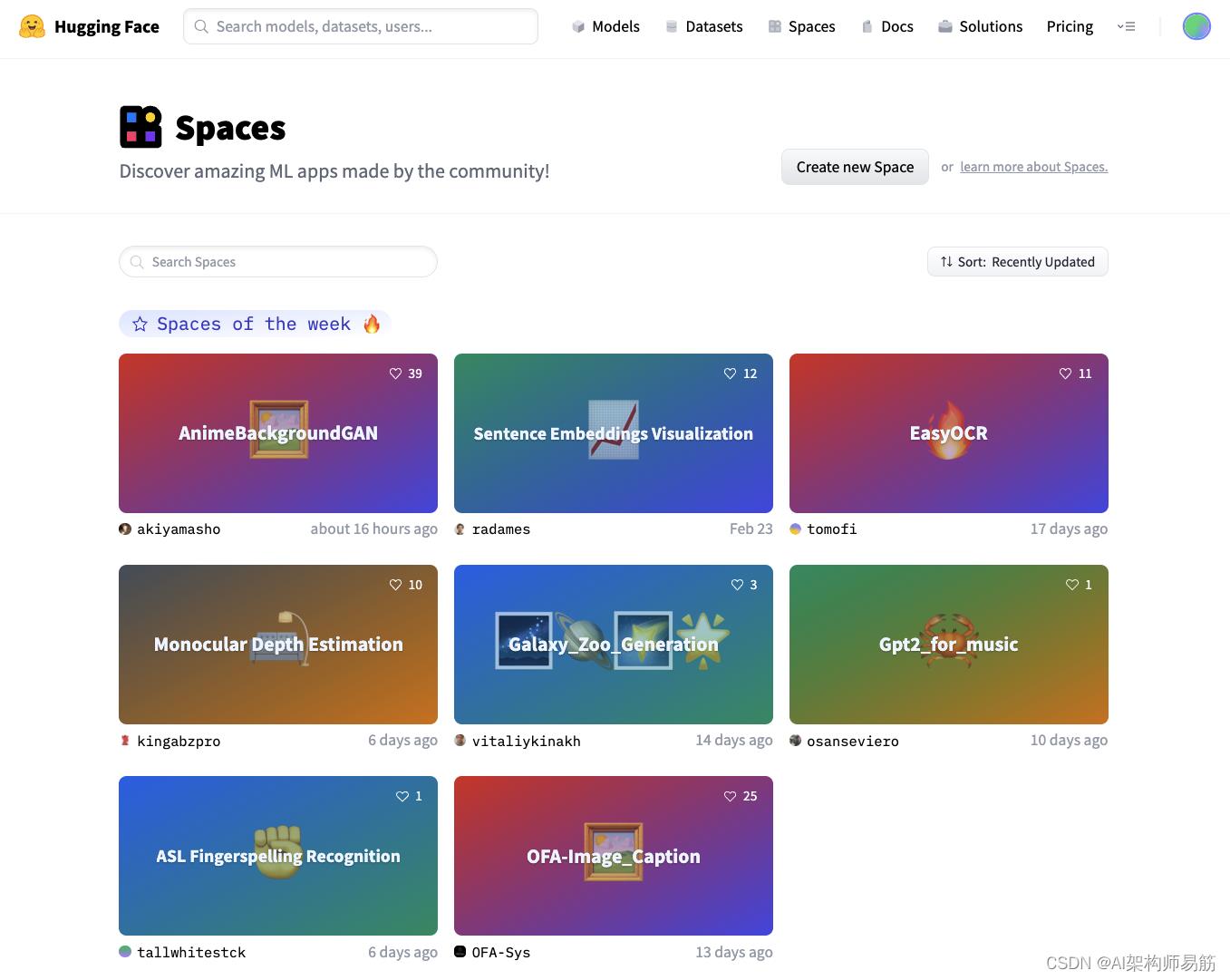
图 8:hugging face,社区空间
这是构建项目组合的好方法,可以在演示、与组织中的同事或更广泛的 ML 生态系统协作时使用。
要开始使用,请单击 Hub 中的“+ New”按钮,然后选择“Space”。这会将您带到一个对话框,您可以在其中指定空间的名称和许可证类型。
您还需要选择一个 SDK。在撰写本文时,您可以从两个基于 Python 的框架中进行选择来托管应用程序:Gradio或Streamlit。或者,您可以只使用自定义 html。
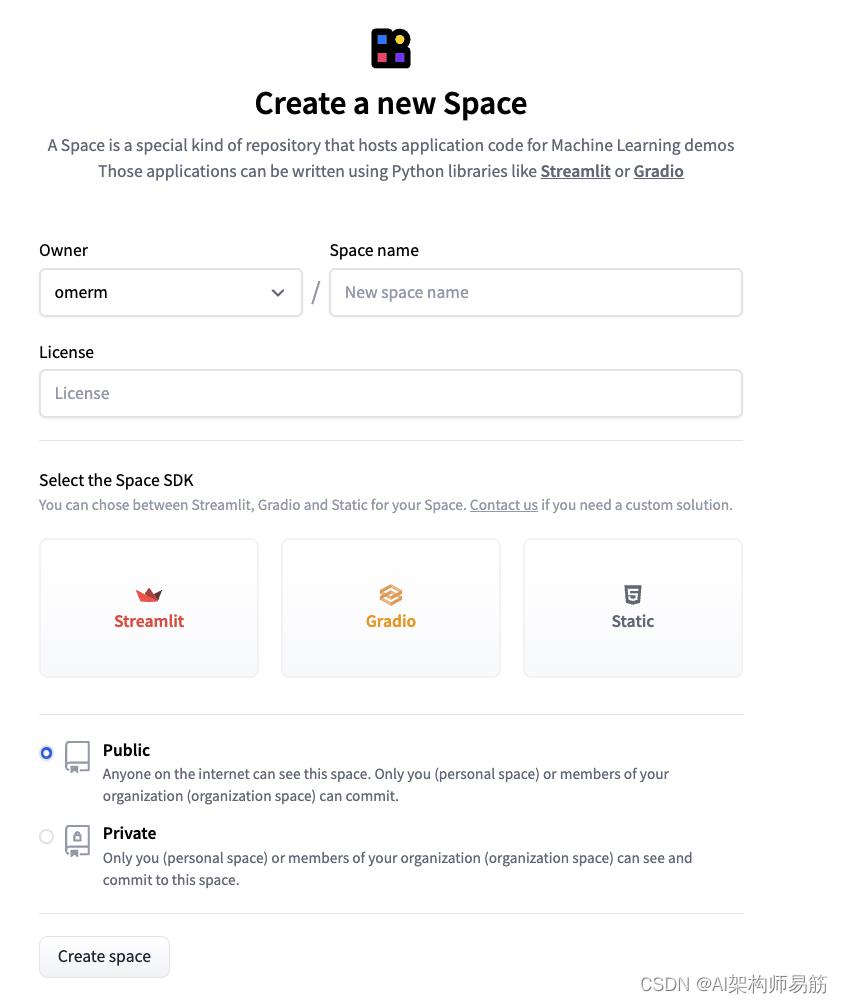
图 9:Hugging Face,创建新模型存储库
与创建新模型或数据集时一样,一旦创建,您将被定向到空间存储库。应用卡是您的演示出现的地方。
为方便起见,我只选择了自定义 HTML 选项,并通过“文件和版本”选项卡编辑了 index.html 文件以进行说明。但是您可以在此处嵌入任何内容,包括 iFrame 中的内容。
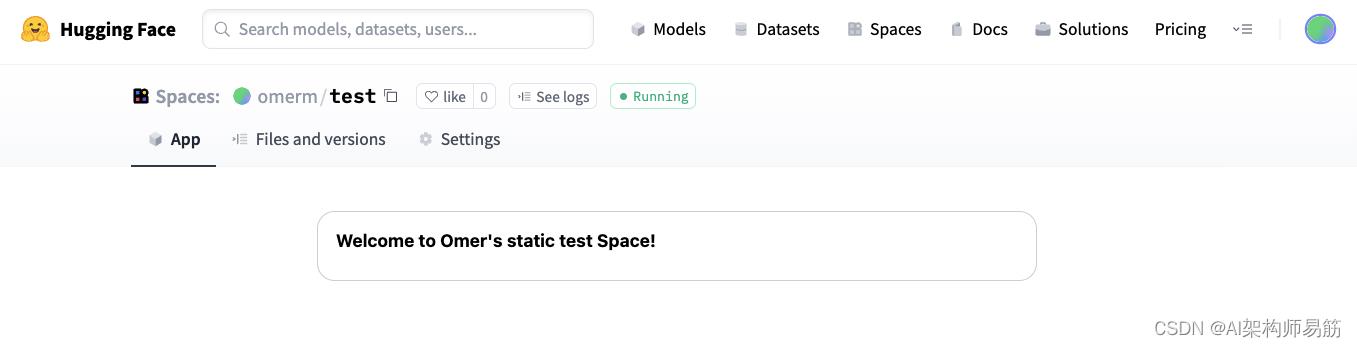
图 10:hugging face、空间、应用卡
创建空间并返回您的个人资料后,您将看到它出现在您的活动源中并准备与世界分享!返回您的个人资料,您会看到它出现在您的活动提要中,并准备与世界分享!
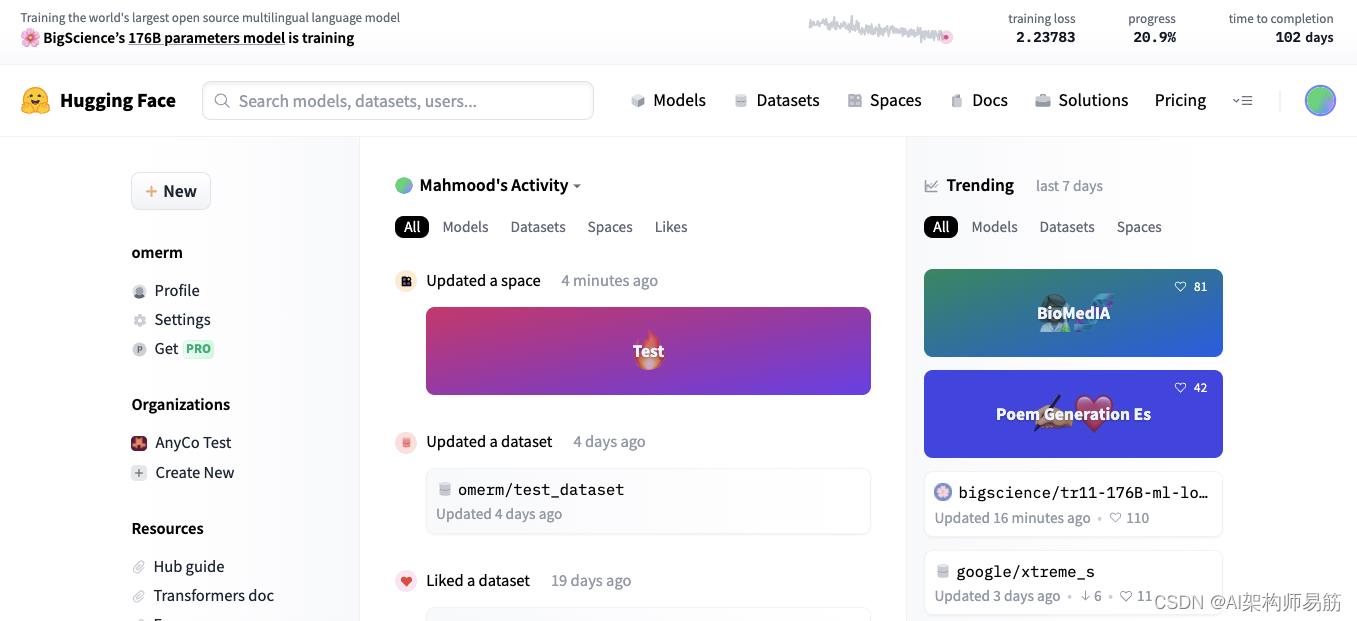
图 11:hugging face,带有更新空间的用户配置文件/存储库
4. 🏄🏽♂️ 探索社区
4.1 社区模式
在您的个人(或组织)存储库之外,您还可以探索由 Hugging Face 社区贡献的所有数以万计的模型、数据集和空间。
您可以从始终显示在网页顶部的顶级导航菜单访问它们。
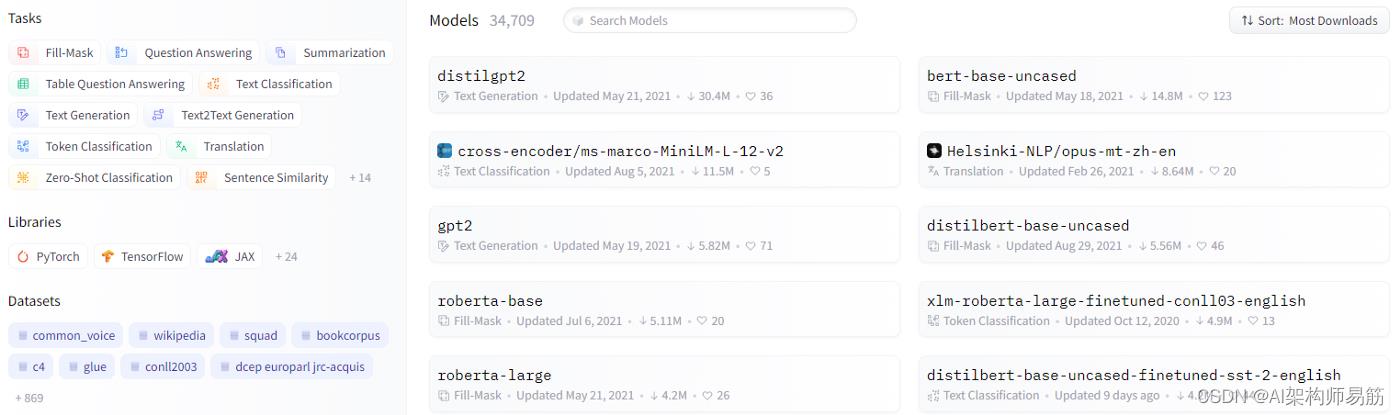
图 12:hugging face,社区模型
社区存储库中大约 ⅔ 的模型是在 PyTorch 中构建的,但对于 TensorFlow 和其他常见 ML 库中可用的每个主要任务,通常都有替代方案。
每个都将有一个模型卡,如上面的模型部分所示,其中包含作者提供的关键信息以及一个托管的推理 API,用于查看模型的示例输入和输出。在“文件和版本”选项卡中,有一个存储库视图中所有文件的列表以及一个包含先前模型运行和保存以供参考的文件夹。
4.2 Tasks任务
现在,您可能会花费大量时间在众多不同的社区模型中搜寻,试图找到一个可以帮助解决您正在尝试解决的挑战的模型。
相反,Hugging Face 通过提供模型的精选视图为您省去了麻烦,具体取决于您尝试使用 AI 处理的任务。
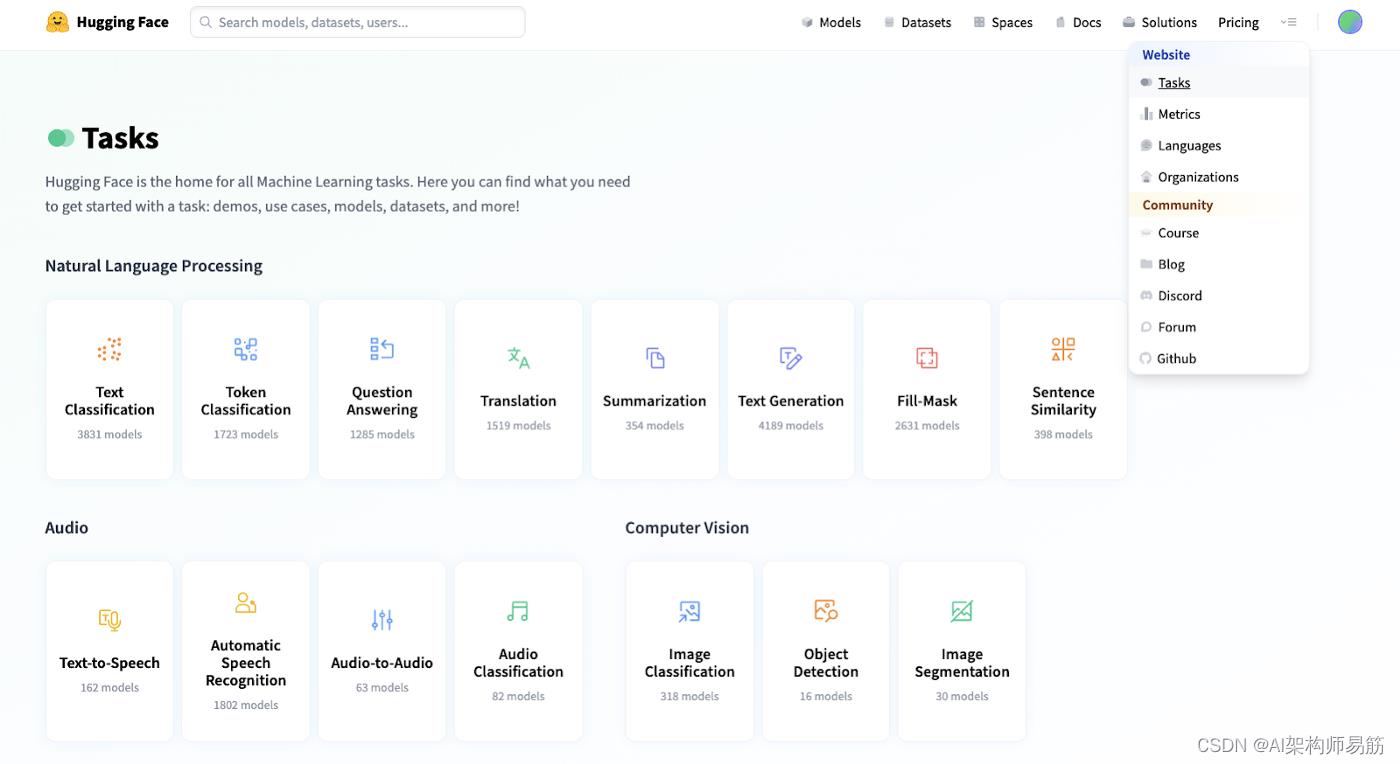
图 13:hugging face,顶级导航和任务页面
Hugging Face 的大部分社区贡献都属于 NLP(自然语言处理)模型的范畴。但您也可以找到与音频和计算机视觉模型任务相关的模型。
每个任务的文档都以直观和直观的方式进行了解释。除了图表,每个解释都附有一个简短的 youtube 视频以及使用推理 API 的演示链接和社区制作的模型链接。
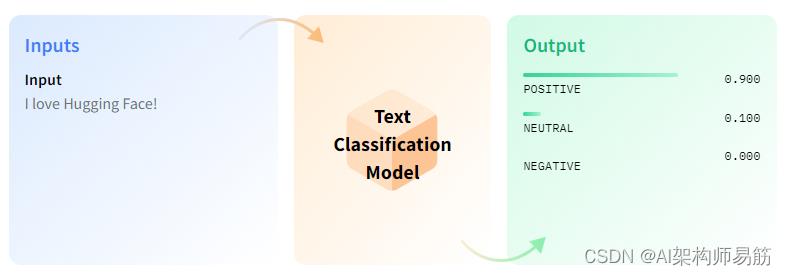
图 14:hugging face、任务、文本分类文档
还描述了可能的用例和任务变体。许多任务描述页面将包括用于培训的笔记本和脚本,以帮助入门。这些脚本涵盖了从设置和加载数据集到预处理(使用 Tokenizer)、模型比较和微调(使用 Trainer API)的端到端过程。
5. 📔 把所有东西放在一起!
在最后一部分中,我们将了解如何轻松地开始使用 Hugging Face和 Python notebook 一起使用Transformers 、Trainer 和 Inference API 的用例。
使用 Hugging Face 工具的主要优势之一是您可以减少从头开始创建和训练模型的训练时间、资源和环境影响。通过微调现有的预训练模型,而不是从头开始训练所有内容,您可以在更短的时间内从数据到预测。
5.1. 同步与认证
Hugging Face 通过将您的笔记本与 Hugging Face Hub 同步,鼓励并轻松地与 Hugging Face 社区的其他人分享您制作或微调的内容。如果您使用可以在用户配置文件的“访问令牌”部分生成的令牌登录,它会将您的模型与网站同步。
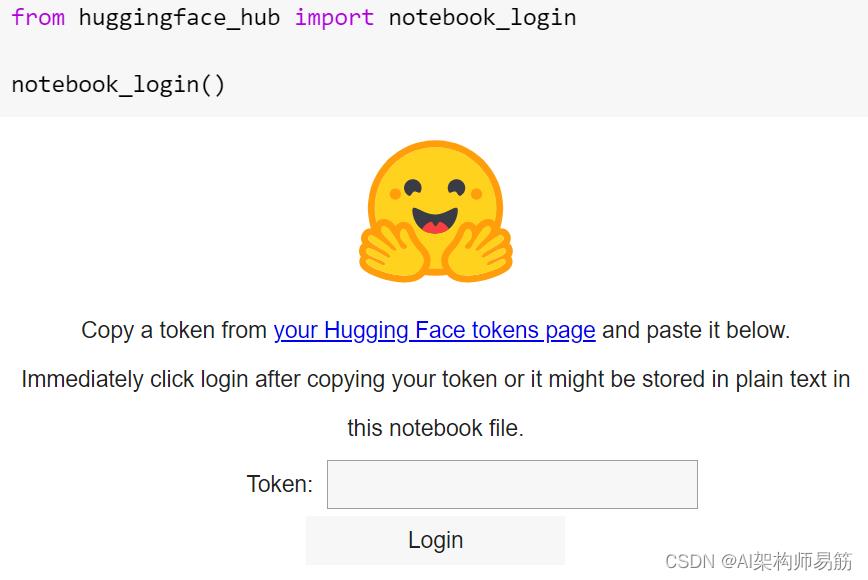
图 15:hugging face、notebook、身份验证
🧐 注意——这里我们使用样板Colab环境,但高级选项允许在 Amazon SageMaker 和 AutoNLP 中进行直接培训,以及多种部署方法,包括 Hugging Face 自己的 Infinity。
5.2. 数据准备
如前所述,如果您正在寻找可以测试或微调模型的东西, Hugging Face Github提供了大量的数据集选择。
在这里,我们试驾 Hugging Face 自己的模型DistilBERT来微调问答模型。
安装并导入必要的库后,我们可以继续使用 Datasets 库在一行中加载数据集。Hugging Face 数据集通常以 Pyarrow 格式构建,但也可以导入 JSON 或 CSV 文件。

图 16:hugging face,笔记本,加载数据集
接下来我们对训练数据进行预处理。Transformers AutoTokenizer 功能用于简化流程。更好的是,许多 Tokenizer 是 Rust 支持的“快速”Tokenizer,可以实现更高效的处理。
样板 Colab 将引导用户了解如何在标记化时截断长文档并考虑上下文拆分。Hugging face 还提供了工具来帮助通过使用偏移映射将标记映射回原始数据上下文。
数据集有一个 map 方法可以将标记化应用于整个数据集。

图 17:hugging face、笔记本、数据集准备
5.3. 根据您的要求微调模型
准备好数据集后,我们可以微调模型。作为转换器库的一部分,有一个 AutoModelForQuestionAnswering 类,它是从模型检查点预训练的。然后我们需要做的就是为 PyTorch 模型定义训练参数并将其传递给 Trainer API。

图 18:hugging face、笔记本、模型训练参数
可以轻松设置超参数以匹配您想要的结果/环境。
5.4. 训练定制模型
以下代码行是启动模型训练过程所需的全部内容。
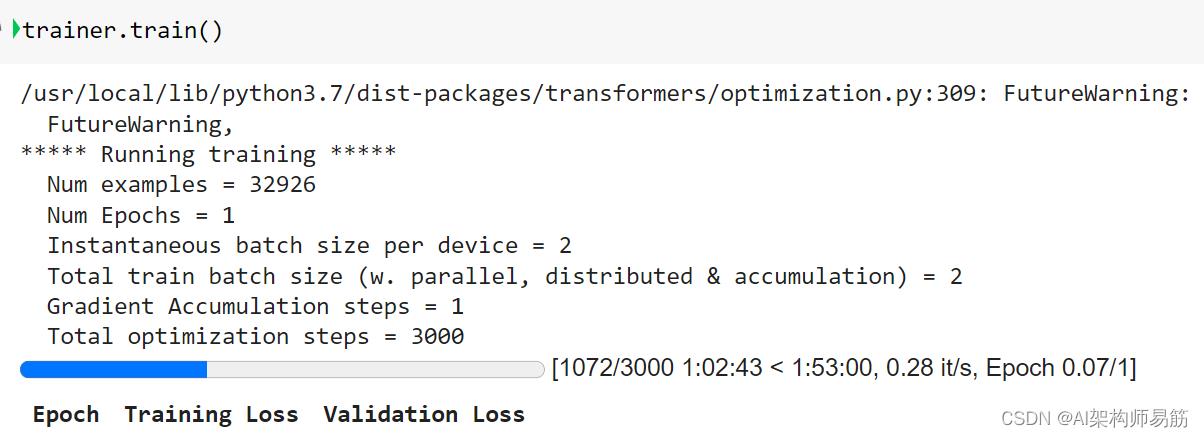
图 19:hugging face、笔记本、模型训练
5.5. 模型输出
模型运行后,可以通过 Trainer API 使用一行代码将其同步回 Hub:
trainer.push_to_hub()
样板 Colab 文档还包括一个模板,用于创建预测并将其后处理为有意义的输出。
上传后,您的模型卡将类似于下面的屏幕截图,然后可以通过编辑进一步自定义。
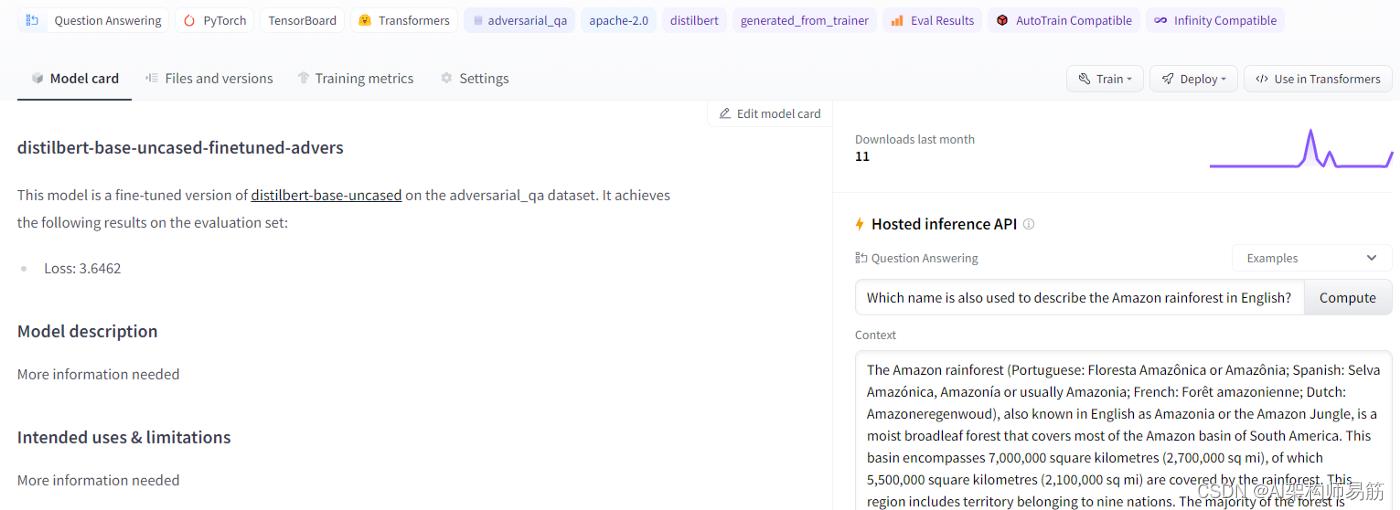
图 20:hugging face,定制模型
然后,您可以使用 Hosted Inference API 在自动生成的模型页面上的 Hugging Face 网站上运行预测,或者将模型检查点加载到 Python 中以开始根据您的微调模型进行预测。
另一个很酷的功能是,如果模型是在 TensorFlow 中创建的,您可以在 Tensorboard 中查看训练指标和模型指标。
至此,我们简要概述了 Hugging Face 是什么、如何开始共享模型和数据集、在社区中导航以及如何为您自己的用例重用现有的社区模型。
6. 📚 进一步阅读和有用的资源
- 课程 https://huggingface.co/course/chapter0/1?fw=pt
- 交互式 API 市场 https://huggingface.co/models?pipeline_tag=zero-shot-classification&sort=downloads
- 代码库、示例和数据 https://github.com/huggingface/transformers
参考
https://towardsdatascience.com/whats-hugging-face-122f4e7eb11a
以上是关于翻译: Deep Learning深度学习平台Hugging Face 开源代码和技术构建训练和部署 ML 模型的主要内容,如果未能解决你的问题,请参考以下文章
翻译: Deep Learning深度学习平台Hugging Face 开源代码和技术构建训练和部署 ML 模型
深度学习经典论文翻译合集Deep Learning Papers Translation(CV)
求Deep learning 【Yann LeCun 1,2 , Yoshua Bengio 3 & Geoffrey Hinton 4,5】全文中文翻译
新开源报道 6百度开源移动端深度学习框架mobile-deep-learning(MDL)
TensorFlow和深度学习入门教程(TensorFlow and deep learning without a PhD)
TensorFlow和深度学习入门教程(TensorFlow and deep learning without a PhD)