机器学习sklearn----支持向量机SVC核函数性质探索
Posted iostreamzl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习sklearn----支持向量机SVC核函数性质探索相关的知识,希望对你有一定的参考价值。
文章目录
前言
前面我们了解了在不同的数据分布下,不同核函数的表现效果,但是实际应用中我们的数据往往有很多的特征,导致我们很难知道具体的数据分布情况,让我们比较难选择较好的核函数。当然了选择“rbf”一直是一个不错的选择。
但是每个核函数都有自己的优势和弊端,这篇文章我们会试着对这些核函数进行探索,使用的数据集是sklearn中的乳腺癌数据集。
本文中使用到的所有依赖库
from sklearn.datasets import load_breast_cancer # 乳腺癌数据集
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV # 网格搜索
from sklearn.preprocessing import StandardScaler # 标准化,使得数据服从0-1分布
from sklearn.decomposition import PCA # 降维
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import warnings
import time
%matplotlib inline
warnings.filterwarnings("ignore")
原始数据集探索
导入 数据
datas = load_breast_cancer()
X, y = datas.data, datas.target
X.shape # (569, 30)
尝试画出数据的分布
# 对于这样的有30个特征的数据集,就比较难以知道它的分布了
# 但是我们可以试着使用PCA降维来看看保留两个特征剩余的信息量,试着画出分布图
pca2 = PCA(n_components=2).fit(X)
X_new = pca2.transform(X)
print("剩余信息量: %.3f" % pca2.explained_variance_ratio_.sum())
plt.scatter(X_new[:, 0], X_new[:, 1], c=y)
# 看起来感觉是线性的,但是有一部分的点可能是覆盖在一起了,也可能是样本不均衡
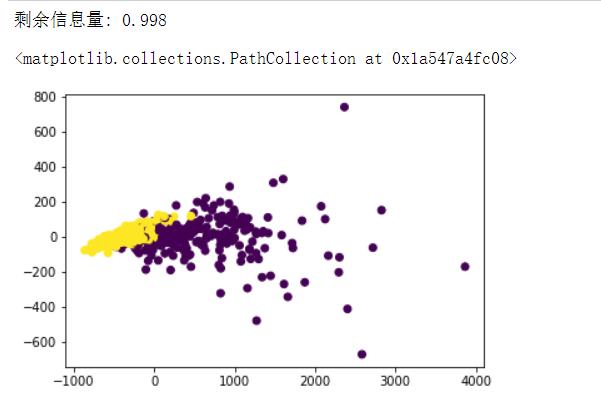
这里降维后的数据集所包含的信息量达到了99%,基本上上面的分布就是实际的数据分布了,这里数据选择的比较巧合,实际中是很少有这种情况的。
训练测试集分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
核函数性质探究
看不同核函数的表现
# 查看每一种核函数的耗时
for k in ['linear', 'rbf', 'sigmoid', 'poly'] :
s = time.time()
# cache_size: 使用多少MB的内存来计算,根据电脑性能来选择
svc = SVC(kernel=k, cache_size=6000).fit(X_train, y_train)
score = svc.score(X_test, y_test)
e = time.time()
print("for kernel cost seconds, the test score is ".format(k,
round(e-s, 5),
score))

这里只能跑出前三个核函数的结果,对于多项式核函数poly跑不出来结果(我自己跑了3小时,感兴趣的可以自己去试试)。这里可以看出多项式核函数poly是一个比较耗时的方式,这是由于poly会进行高次的计算,在SVC中有一个参数degree,默认为3,在这个500个样本30个特征的数据集上poly核函数很难跑出结果。
但是看前三个核函数的结果,明显线性核函数linear的效果非常好,在结合前面的分布图,可以预想数据分布基本确定是线性的了,那么就可以将degree设置为1,那么poly也能跑出结果了
# 查看每一种核函数的耗时
for k in ['linear', 'rbf', 'sigmoid', 'poly'] :
s = time.time()
# cache_size: 使用多少MB的内存来计算,根据电脑性能来选择
svc = SVC(kernel=k, cache_size=6000, degree=1).fit(X_train, y_train)
score = svc.score(X_test, y_test)
e = time.time()
print("for kernel cost seconds, the test score is ".format(k,
round(e-s, 5),
score))

这里将degree设置为1之后poly的效果也是不错的
到目前为止的探索可以得出结论如下:
- 线性核函数相对来说是比较耗时的
- 对于特征比较多的数据,poly很可能计算不出结果
对核函数rbf的表现不佳的思考
这里的结果rbf得分真的是不尽人意,但是在前面的一章中,rbf的表现是很亮眼的,那么造成这样的结果是为什么呢。下面我们对原始数据进一步探索,看看是不是数据的分布等等对结果造成了影响
查看原始数据的统计行描述
df = pd.DataFrame(data=X)
# 使用pandasdescribe函数,显示1%, 10%, 20%, 40%, 60%, 80%, 90%, 99% 分为信息
df.describe(percentiles=[0.01, 0.1, 0.2, 0.5, 0.6, 0.8, 0.9, 0.99]).T
# 原始数据存在偏态和量纲不统一的问题
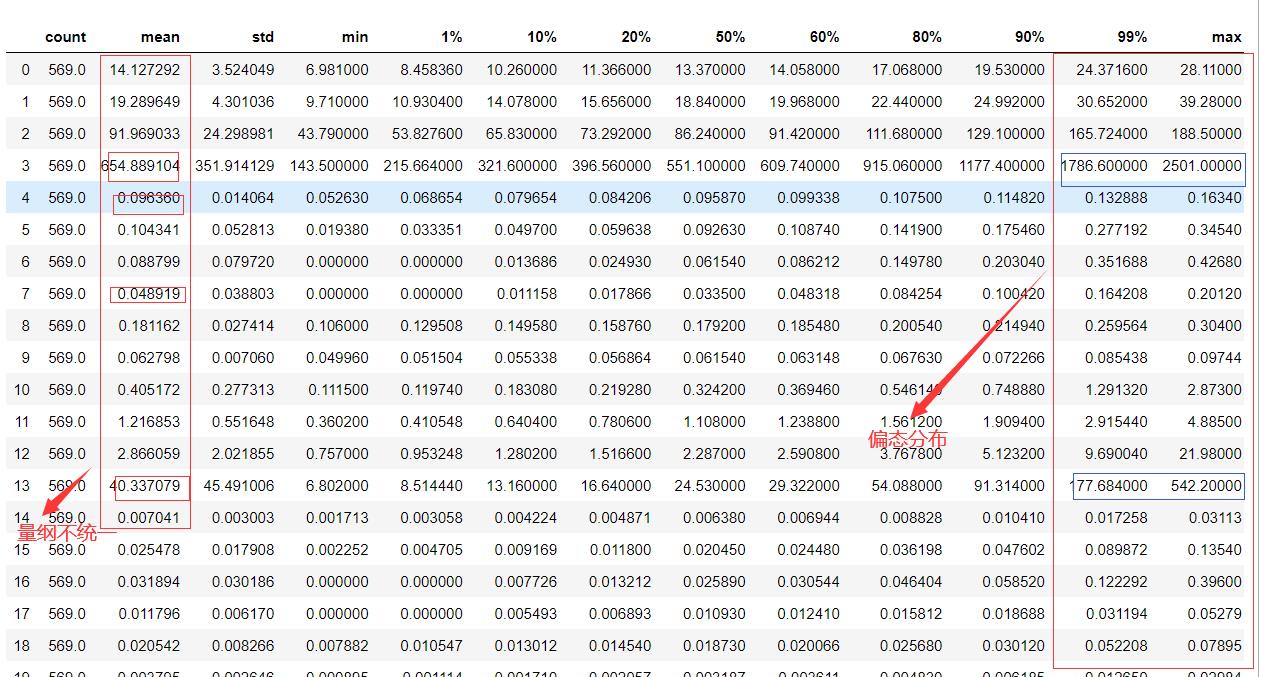
进行数据的无量纲化,让数据有相同的量纲和相同的分布,无量纲化看这篇文章
# 统一量纲,解决分布不均衡问题----数据的无量纲化
X = StandardScaler().fit_transform(X)
df = pd.DataFrame(data=X)
df.describe(percentiles=[0.01, 0.1, 0.2, 0.5, 0.6, 0.8, 0.9, 0.99]).T

将新的数据在跑一次核函数
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# 查看每一种核函数的耗时
for k in ['linear', 'rbf', 'sigmoid', 'poly'] :
s = time.time()
# cache_size: 使用多少MB的内存来计算,根据电脑性能来选择
svc = SVC(kernel=k, cache_size=6000, degree=1).fit(X_train, y_train)
score = svc.score(X_test, y_test)
e = time.time()
print("for kernel cost seconds, the test score is ".format(k,
round(e-s, 5),
score))

可以看到时间的损耗上有了一个质的飞跃,同时rbf,sigmoid两个非线性的核函数的效果也是质的飞跃。
对rbf进一步的调参
既然上面的rbf模型得分达到了最好的效果,那么我们就以rbf为例,来进行进一步的调参。
在SVC中有四个参数(degree, gamma, coef0,C)影响模型的效果,对于poly前三个参数对它都有影响
| 参数 | 含义 |
|---|---|
| degree | 整数默认为3,专门为多项式核函数poly设置,其他的核函数设置了该参水会自动忽略 |
| gamma | 浮点数,默认auto 输入auto,自动让gamma = 1/n_features 输入scale,使用1/(n_features*X.std()) |
| coef0 | 浮点数,默认0 |
| C | 浮点数,必须大于等于0,默认1,对判错数据的乘法系数 |
对于上述参数具体对模型的影响是怎么样的是比较难以确定的,那是很复杂的数学原理,我们只能通过机器学习的方法慢慢的调参来确定最佳的参数组合
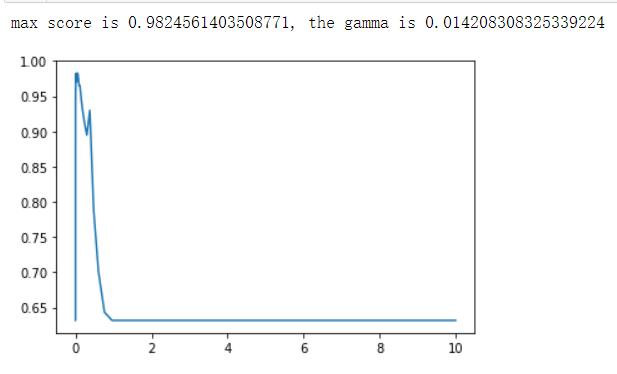
# 返回10^-5到10^1的50个数
gamma = np.logspace(-5, 1, num=60, base=10)
scores = []
for g in gamma :
svc = SVC(kernel='rbf', gamma=g).fit(X_train, y_train)
scores.append(svc.score(X_test, y_test))
print("max score is , the gamma is ".format(max(scores), gamma[scores.index(max(scores))]))
# best score : 0.9824561403508771
plt.plot(gamma, scores)
plt.show()
网格调参,网格搜索的本质是枚举,会枚举出给定的参数列表的每种组合,在一一进行跑模型,选择出最佳的结果
coef = np.linspace(-5, 5, 40)
param_grid = dict(gamma = gamma,
coef0 = coef)
grid = GridSearchCV(SVC(kernel='rbf'),
param_grid=param_grid,
cv=5).fit(X, y)
print("best params \\nbest score ".format(grid.best_params_, grid.best_score_))
# best params 'coef0': -5.0, 'gamma': 0.036251170499885355
# best score 0.9753954305799648
相比于上面的只有gamma参数,效果下降了,看来不需要coef0是一个很好的选择。
调参C
C = np.linspace(0.01, 5, 50)
scores = []
for c in C :
svc = SVC(kernel='rbf', gamma=0.014208308325339224, C=c).fit(X_train, y_train)
scores.append(svc.score(X_test, y_test))
print("the best score is the c is ".format(max(scores), C[scores.index(max(scores))]))
plt.plot(C, scores)
plt.show()

模型效果又提高了一些,还不错
以上是关于机器学习sklearn----支持向量机SVC核函数性质探索的主要内容,如果未能解决你的问题,请参考以下文章