hive开启自动转化common join和map join 带来的问题
Posted 扫地增
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive开启自动转化common join和map join 带来的问题相关的知识,希望对你有一定的参考价值。
背景:
我们采用的hive版本是3.1.2属于较新版本,此版本下hive本身默认开启map join
相关配置
hive默认开启map join,涉及的配置如下:
hive.auto.convert.join=true
错误分析
错误发生在我们使用曝光转化明细宽表和素材维表进行join时,由于两个表都非常大,我们本意是让他进行common join即可,但是在运行程序时出现了报错:
Error while processing statement: FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.mr.MapredLocalTask
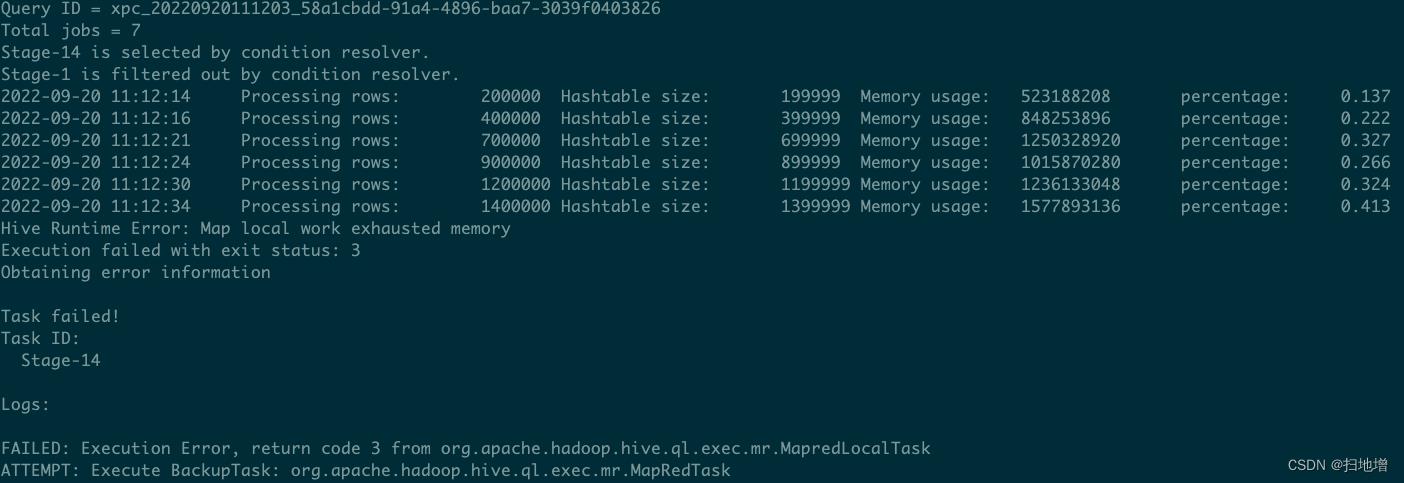
我们发现任务一直在加载hashtable,最终内存不足从而导致报错。
map join原理
MapJoin是指在Map 端进行join,其原理是broadcast join,即把小表作为一个完整的驱动表来进行join操作。通常情况下,要连接的各个表里面的数据会分布在不同的Map中进行处理。即同一个Key对应的Value可能存在不同的Map中。这样就必须等到 Reduce中去连接。要使MapJoin能够顺利进行,那就必须满足这样的条件:除了一份表的数据分布在不同的Map中外,其他连接的表的数据必须在每个Map中有完整的拷贝。Map Join会把小表全部读入内存中,在Map阶段直接拿另外一个表的数据和内存中表数据做匹配 (这时可以使用Distributed Cache将小表分发到各个节点上,以供Mapper加载使用),由于在map时进行了join操作,省去了reduce运行的效率也会高很多。详见笔者之前文章hive sql数据倾斜——大表join小表如何使用map join。
当机器内存不足时,无法在Map端进行join,即会报错。
解决办法:
仅供参考
方法一:关闭hive配置,手动开启mapjoin
- 在hive-site.xml配置,配置完即可生效
<property>
<name>hive.auto.convert.join</name>
<value>false</value>//true修改为false
<description>Enables the optimization about converting common join into mapjoin</description>
</property>
- 在使用map join时对小表手动开启,开启方法可以参考总结好的博客:hive sql数据倾斜——大表join小表如何使用map join
方法二:针对任务在调度时选择是否开启join,同时对多阶段进行手动控制
- 使用hive --hiveconf 配置参数为false
hive.auto.convert.join=false
- 具体代码具体分析即可
解决后效果
以上是关于hive开启自动转化common join和map join 带来的问题的主要内容,如果未能解决你的问题,请参考以下文章