MaxCompute SQL 现状与展望
Posted kiydkafa
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MaxCompute SQL 现状与展望相关的知识,希望对你有一定的参考价值。
票选最美云上大数据暨大数据技术峰会上,阿里云飞天一部高级专家振禹为大家带来题为“MaxCompute SQL 现状与展望”的演讲。本文重点解析了MaxCompute SQL 现状,详细介绍了各种功能,其中包括编译器用户友好功能、复杂类型、CTE、参数化视图和SEMI JION等,接着说明了MaxCompute SQL即将完成与推进中的功能,最后作了简要总结。
以下是精彩内容整理:
MaxCompute SQL 现状
目前MaxCompute SQL能力不是很强,虽然在性能、安全和成本控制上得到了业界一直认定,很多用户利用它支撑自己的核心业务,但也有对其不满意的方面,MaxCompute SQL与大数据运算方面的Hive、Orcale、SQL Server等都有很大差异,在标准的SQL支持上也有改进的地方。
开源生态需求
在做SQL兼容或扩充时,考虑到优先级将功能分成三方面,具体如下:
- 横向功能。横向功能影响所有用户、所有场景,是现阶段重点问题;
– 数据类型与内建函数
– UDF二进制兼容
– 外部文件存储与不同格式支持
– 标准语言功能
- 纵向功能。纵向功能适应用户不同场景需求;
– 外表支持,多数据格式支持
– CLUSTERED TABLE/TRANSFORM/CUBE
- 特色功能
– MaxCompute Studio 等易用性改进
– 特色语言功能 – TABLE VARIBLE, Parameterized View
编译器用户友好功能
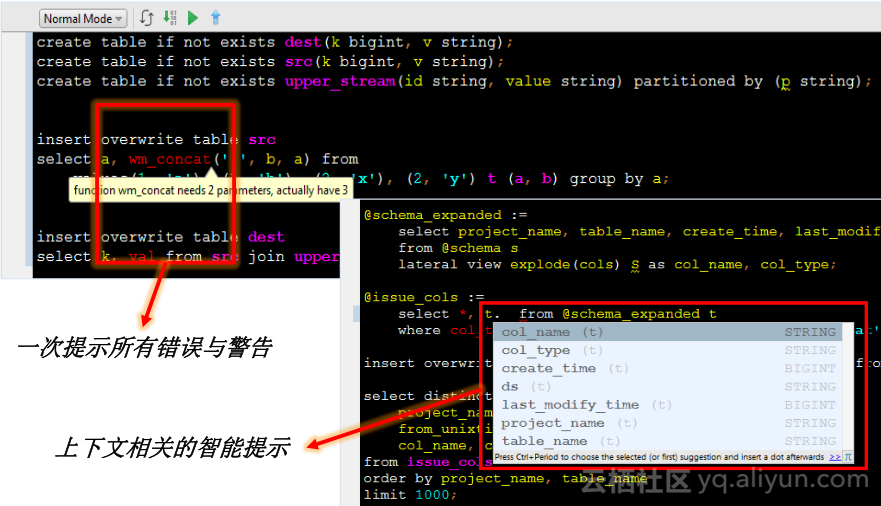
对于分布式系统,性能、成本都非常重要,更重要的是作为开发者的时间,如果大家花大量时间在查各种语言功能、写错就要debug半天、发现某参数没有传对等琐碎事情上,在集中开发时会浪费大家大量时间,不论MaxCompute还是Hive,目前都只支持提交有一个语句,如果在一个文件中一次提交多个语句,实际上也是一句一句向服务器提交的,如果最后一句出现语法或语义错误,也不会在client报告,可能前面几句已经执行若干小时才跑到最后一句,然后通知你最后一句某函数参数传错,这种情况会让人沮丧。MaxCompute 基于新一代SQL引擎,提供了新数据开发的IDE,叫MaxCompute Studio,MaxCompute Studio作了编译器深度集成,方便解决上述问题。
图为MaxCompute Studio的两个窗口,左侧窗口中,第一个语句中有函数多传了一个参数,最后一个语句中有一列在原表中不存在,MaxCompute Studio在进行文本编辑时就可以将所有信息错误标注出来,并能告诉大家错误是怎样的,将鼠标放在红色部位即可显示,MaxCompute SQL是一个集成在开发环境中的插件,大家可以当即修正错误,确保在client端解决掉所有错误,而且MaxCompute SQL引擎可以对不安全转换发出警告;右侧窗口中,使用MaxCompute Studio,可以自动列出所有columns,该功能上下文相关,包括buliding function和keywords的提醒,随着敲击都可以计时提醒哪些东西是否合法,您只要使用这个功能,自然而然做到程序零错误。
该功能的目的是提高用户开发效率、降低服务负载;目前具备compiler错误恢复能力,提供强大多error, warning功能,赋能MaxCompute Studio;未来,我们会提供更强大与精准的提示能力,会推出代码重构能力,我们也会在集成代码MaxCompute Studio里向大家提供智能建议。
基本数据类型

目前MaxCompute1.0支持6个数据类型,对于绝大部分场景足够,可以减少迁移成本,作为连接第三方工具(Tableau,HiveHPL)。比如integer ,MaxCompute1.0提供BEGINT数据类型,简洁的好处是减少选择,但有时数据类型丰富也确实能够带来更强的表达能力,尤其是从其它系统向MaxCompute迁移时,可能需要将类型进行映射,所以在MaxCompute即将推出将基本数据类型扩充,支持全部Hive数据类型和常量表示,时间类型支持国际化 ,时区可订制。未来我们会进一步扩充数据类型,修正decimal类型,既能改善性能、节省存储,也能够把业务场景里的行为表现精确。
复杂类型
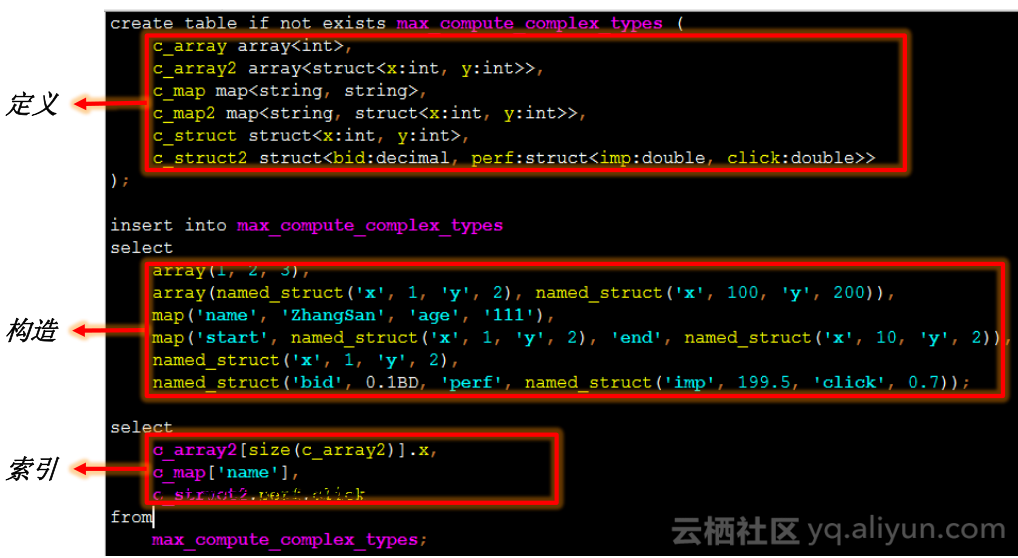
复杂类型在广告等场景常用,方便UDF开发,复杂类型也是很常用的一些功能,Maxcompute1.0也支持复杂类型,array和map,但是会有些限制,比如array和map下标类型必须是常量,不能嵌套;到了2.0支持struct,没有任何限制,可以任意嵌套。比如广告商打广告,每个广告会有出价竞标keyywords,随着不同的出价可以拿到广告中impression click,形成几条曲线,每一个广告点性能的数据形成了struct,所有的出价点形成了array。我们支持除UNION(Hive不推荐使用)外全部Hive复杂数据类型,所有Hive配套函数。未来,我们会进一步扩充复杂类型支持,放松限制,排序去重,支持UDT。
SQL语法 - CTE
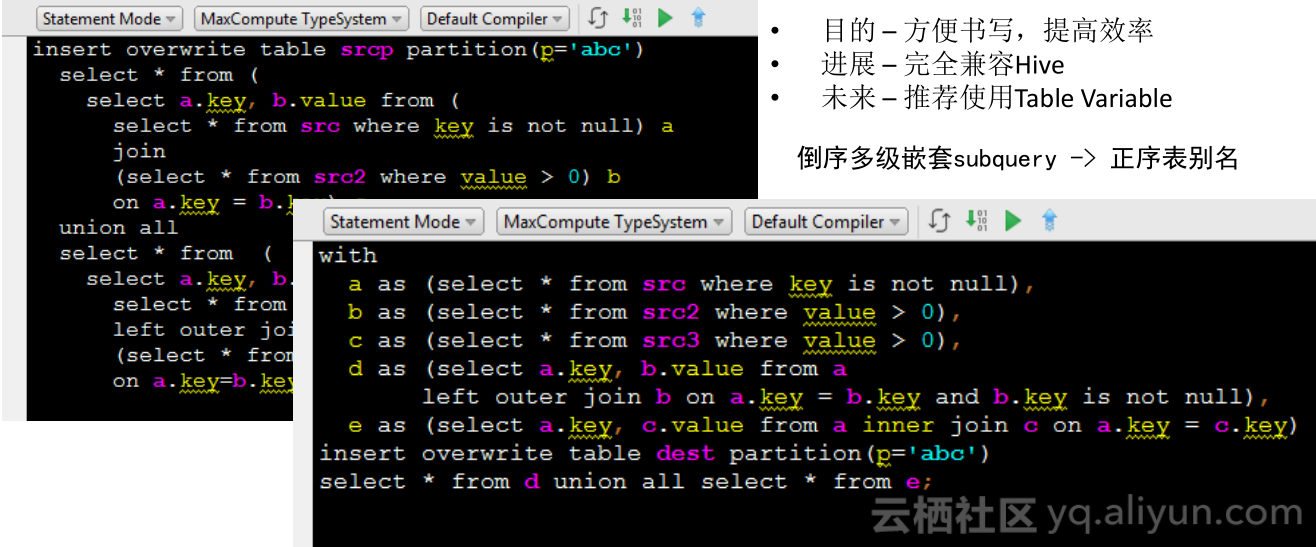
CTE为common table expression,在各个数据库语言中比较常用,完全兼容Hive。左侧图所示,如果写复杂的SQL,要依赖层层嵌套的subquery,某些用户的脚本已经嵌套四五层时,书写、维护都很不方便,subquery需要反过来写,不容易处理,并且两个分支上的subquery的SQL一模一样,完全依赖subquery智能将SQL写的一模一样,必须备份两份,会给代码维护带来不方便。而右侧图是与左侧图完全等效的写法,with子句定义了一系列inners,每个inner对应SQL子句,后面就可以直接访问前面对应好的子句,每一个子句相当于定义一个变量,可供多次引用。
VALUES
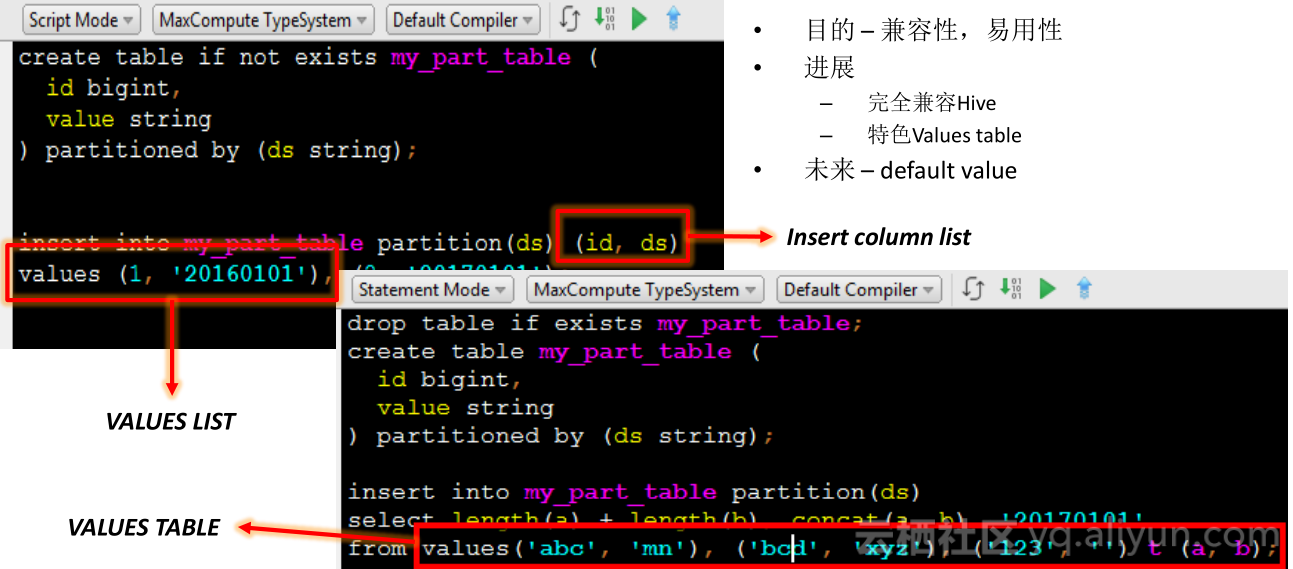
VALUES最常用的地方是insert,当准备不是大量数据时,传统的database用法只需准备一个文本文件,将所有VALUES都准备好,执行有一个SQL语句即可将所有数据准备好,老版本的MaxCompute1.0不支持这种语句,准备数据的方式是通过tunnel上传,虽然方式没有问题,但会给迁移带来额外工作。而在新一代MaxCompute中,insert、VALUES可以支持了,支持Insert column list,Values table选取是MaxCompute的特色功能。
SEMI JION等其他改进

SEMIJOIN是各个数据库系统中常用的功能,常见的体现方式为IN subquery和EXISTS,像Orcale、SQLServer、Hive都会将其转成JOIN,称为半连接,半连接分为ANTI JOIN和SEMIJOIN,SEMIJOIN是指用右表数据过滤左表,右表有就返回左表数据,ANTI JOIN为右表没有即返回左表数据。SEMIJOIN兼容Hive,兼容Impala ANTI JOIN。
同时,MaxCompute还支持Implicit Join和UNION [DISTINCT]。
查询过程与参数化视图
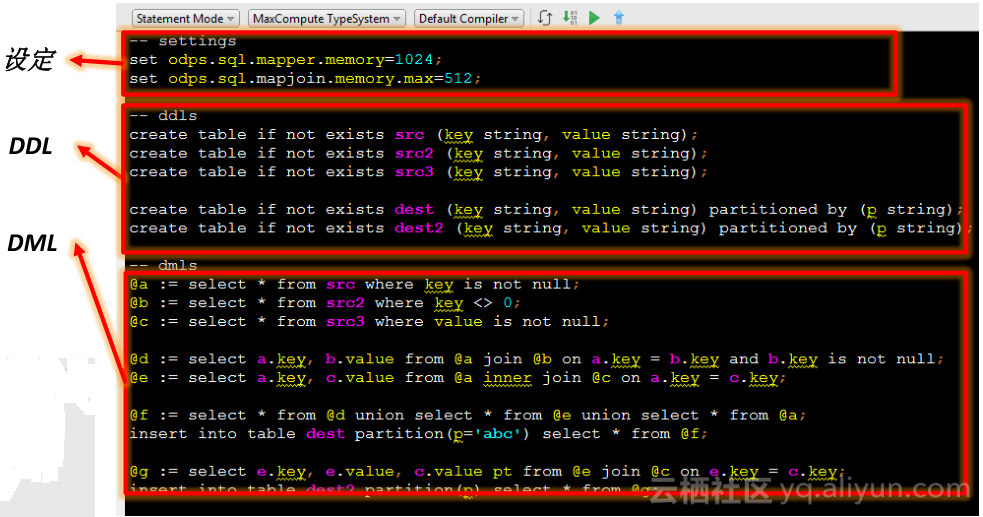
在大数据查询时,会将所有语句编成统一一个执行计划运行,避免做一个一个语句的操作,对于Hive来说,也可以将一系列语句写到文件中提交,语句之间完全是分开提交的,服务器端每次看到的只是原本文本文件中的一个语句,中间的联系主要靠表实现,表达能力和性能方面都是有欠缺的。
图为MaxCompute Studio截图,通过查询过程写出一个程序,可以看到分成三个部分:首先set语句定义一些设定,其次DDL语句准备一些table,最后是一系列的DML查询语句,此查询语句与传统查询方式不同,每一个都是定义变量等同于查询语句,变量可以反复使用,它比CTE更加灵活,可以任意引用,多次insert。查询过程中会形成单一完整的一个执行计划,这与写一个复杂语句在性能上是没有区别的,整个程序会一次性提交到服务器端一次性执行,会在维护性和性能方面带来很大好处。
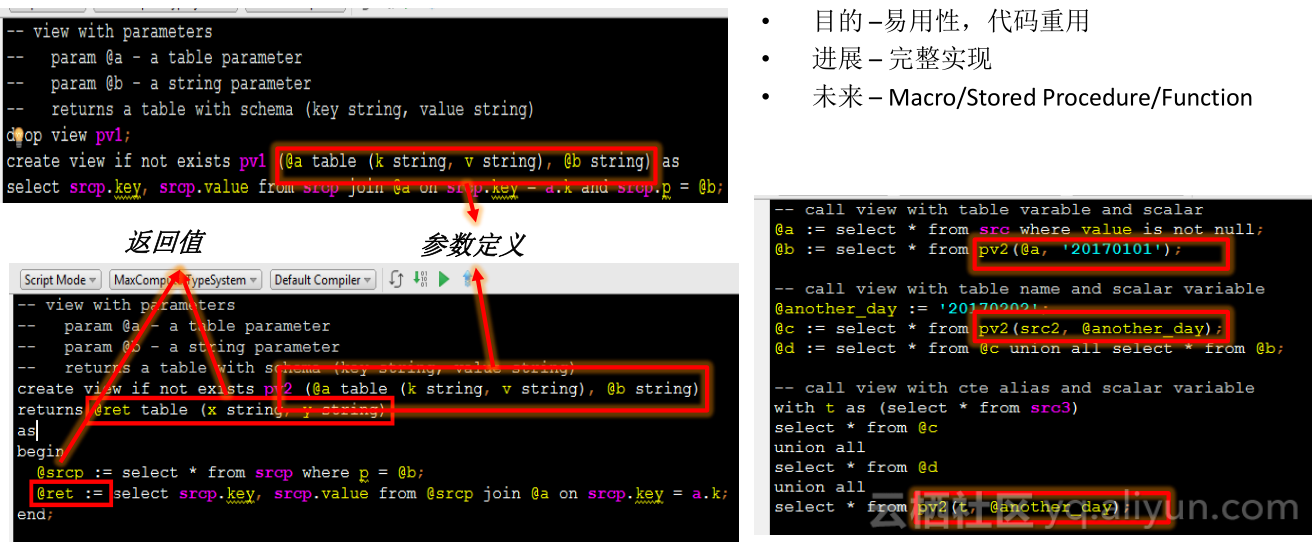
MaxCompute支持视图,根据数据表提供有意义的运算,这些运算不一定要每次计算出来,而是直接写SQL语句,这些语句就变成了视图,SQL语句就从准备好的表里抽取数据,做出一定运算后再提供给调用者调用,这样做的好处是封装保证了底层改变时不需要让所有调用者都做任何变化,只需将view更新,另外,代码可以反复使用。
图中可以看出,左侧有两个参数化view。第一个可以提供参数列表,表中有表变量和string变量,SQL语句可以直接引用这些变量;第二个begin-end里就是查询过程,写法完全一样,区别是它可以引用参数列表提供的参数,对于view来说,定义一个返回变量,对变量进行赋值即可。右边图中可以看到如何调用参数化的view,以后大家可以完全在MaxCompute上提供用查询语言写出的过程库和函数库,提供给别人去用。
内建函数
语言本身以及语言提供的函数库是否易用和丰富很重要,兼容性也是必须要考虑的问题。
我们大大新增了函数 ,扩充接近一倍,具体包括以下函数:
– 数学函数 log2,log10,bin, hex,unhex,crc32,sha1,shar2,degrees,nullif,radians,sign,e,pi,
factorial,cbrt, shiftleft, shiftright, shiftrightunsigned
– 日期函数 unix_timestamp, to_date, year, quarter, month, day, dayofmonth, hour, minute,
second,millisecond,nanosecond,date_add, date_sub, from_utc_timestamp, current_date,
current_timestamp, add_months, last_day, next_day, trunc, months_between
– 字符串函数 concat_ws, lpad, rpad, replace, soundex, substring_index
– 聚合函数 collect_list, collect_set
– 表操作函数 posexplode, stack, inline, parse_url_tuple
– 复杂类型操作函数 map,struct,named_struct, map_values,map_keys, sort_array
未来支持全部Hive Built-in函数(包括Window函数)与其他DBMS典型函数,目前有些函数调用了Java,改为Native提高性能。
UDF/UDAF/UDTF
- 目的
– 降低用户迁移成本
– 兼容生态工具
– 扩大MaxCompute自身能力,例如HPL
- 进展
– 二进制兼容Hive2.1 UDF/UDAF/UDTF, 无需迁移 ,注册成MaxCompute函数就能用
– 限制安全沙箱,很多第三方库因使用受限功能无法使用 (访问磁盘,使用反射等)
- 未来
– 安全支持虚拟化,第三方库可用
– 注册方式兼容(不一定需要,与Session支持统一考虑)
– UDT (User Defined Type) – 与Java的无缝集成
EXTERNAL TABLE / STORED AS
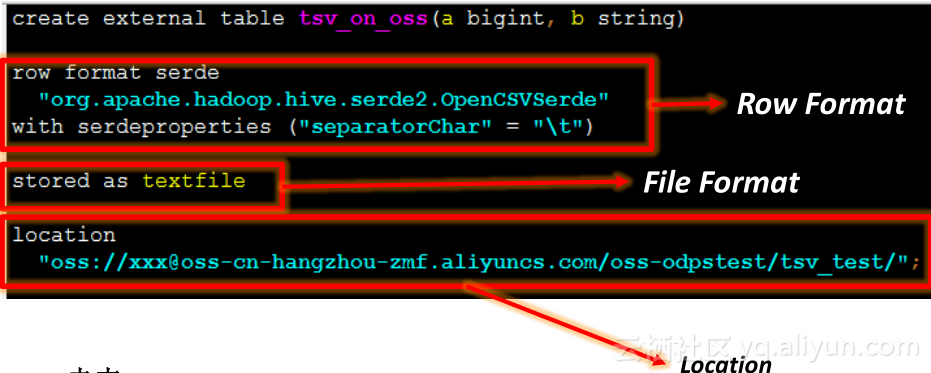
数据上云,兼容Hadoop/Hive现有数据。在Hadoop/Hive里,数据进入系统最常用的方式是将数据上传到HDFS,在Hive里有external table,可以指定location在哪,再指定数据文件格式,就可以使用了,每天数据往HDFS里上传,在MaxCompute里支持的方式是datahub和tunnel,为的就是方便大家迁移适应各种各样的场景。
目前MaxCompute的进展如下:
– 二进制兼容Hive所有内建文件格式与SerDe(行格式)
– TEXTFILE,SequenceFile,RCFile,AVRO,Par quet, ORC
– 文件按存储在OSS上,直接访问
未来将会支持STORED BY “StorageHandler”支持与OTS,Hbase类的DBMS的互通。
即将完成与推进中的功能
- 支持桶表提高兼容性与性能 – S27试用
– CREATE TABLE … [RANGE] CLUSTERED BY (col1,…) SORTED BY (col1, …) INTO <n> Buckets ...
– hash cluster与hive兼容,提高性能与兼容性
– range cluster,MaxCompute特色,支持海量排序与交互式查询
- 支持Memory Table,以更友好的方式提供类似Spark RDD的功能– S27试用
– 内存中cache热表,提高性能。
ALTER TABLE t SET TBLPROPERTIES(‘cache’=‘true’) ;t 的内容缓存在内存中,多次访问无需读盘
– 与table variable结合,缓存热点查询,提高性能。
@a := CACHE ON SELECT …; -- @a的结果缓存在内存中
@b := SELECT * from @a a join @a b on …; 多次访问 @a ,从内存中直接读取,无需重新计算。
- SQL方面的其他计划中的改进
– UDJ (User Defined Join)
– GROUPING SET, TRANSFORM, session等,根据客户需要有选择的支持
总结
- MaxCompute在提高性能,降低成本的同时,重视改善用户体验,提高开发与使用效率
- 基于ODPS2.0的SQL引擎,MaxCompute希望真正提供货架产品,适应广大客户需求
- 大幅降低迁移成本,提供良好兼容性,让用户轻松迁移,放心迁移
以上是关于MaxCompute SQL 现状与展望的主要内容,如果未能解决你的问题,请参考以下文章