学习笔记之——Semi-direct Visual Odometry (SVO)
Posted gwpscut
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习笔记之——Semi-direct Visual Odometry (SVO)相关的知识,希望对你有一定的参考价值。
本博文为本人学习SVO的学习笔记,本博文大部分内容来源于网络各种参考资料,本博文仅为本人学习记录用。
SVO是一种半直接法的视觉里程计,结合了基于特征点方法的优点(并行追踪和建图、提取关键帧)和直接法的优点(快速、准确)。
补充:VO分为直接法与特征点法:
-
基于特征点方法的单目VO思路:从图像中提取稀疏特征,使用描述子进行特征点匹配,再进行初始化(根据对极约束估计相机的位姿,再根据三角化得到特征点的深度(以初始化时的 t 为单位1,计算特征点的深度)),然后可以转化为PnP问题,通过构造BA(求最小化重投影误差)优化问题求解后续的位姿和路标点位置(场景结构)。
-
基于直接法的单目VO思路:直接根据像素灰度信息获得相机运动和对应点的投影,最初不知道第二帧中的哪个 p_2 对应着第一帧中的 p_1 ,此时根据估计的相机位姿来找 p_2 。当估计的位姿不好时, p_2 与 p_1 会有明显不同(灰度不变假设),这时通过构造优化问题(最小化光度误差),不断调整位姿以减小像素灰度差别,最终得到位姿的最优估计和投影点位置。
SVO的框架如下图所示:
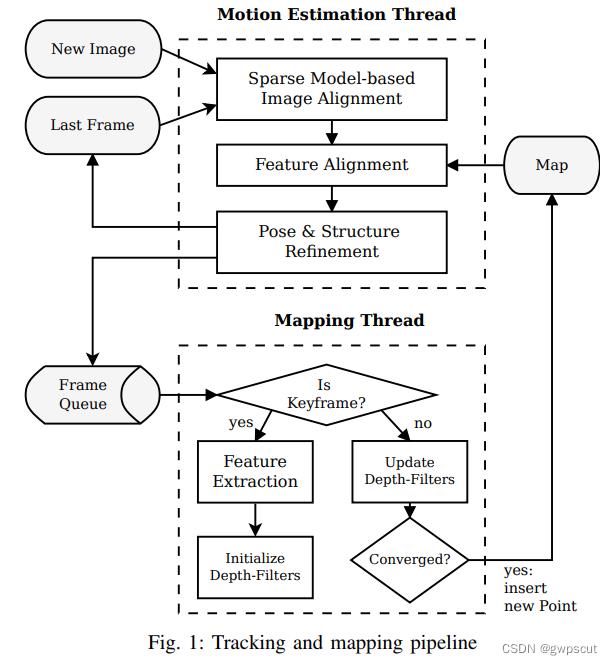
原理
如上图所示。SVO整体上分为两个线程:
-
一个线程用于估计相机位姿:实现了相对位姿估计的半直接方法。
-
一个线程用于建图:为每一个要被估计的3D点对应的2D特征初始化概率深度滤波器,当深度滤波器的不确定性足够小(收敛)时,在地图中插入相应的3D点(更新地图),并用来估计位姿。
对于EVO而言,其实也就是类似SVO的框架下实现的。且它的代码框架也是依赖于SVO。如下图所示
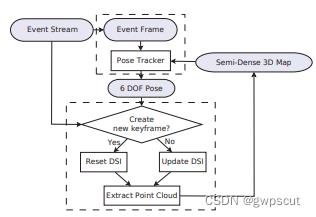
https://ieeexplore.ieee.org/ielaam/7083369/7797562/7797445-aam.pdf
GitHub - uzh-rpg/rpg_dvs_evo_open: Implementation of EVO (RA-L 17)
而对于esvo其实也是类似的tracking与mapping的框架吧
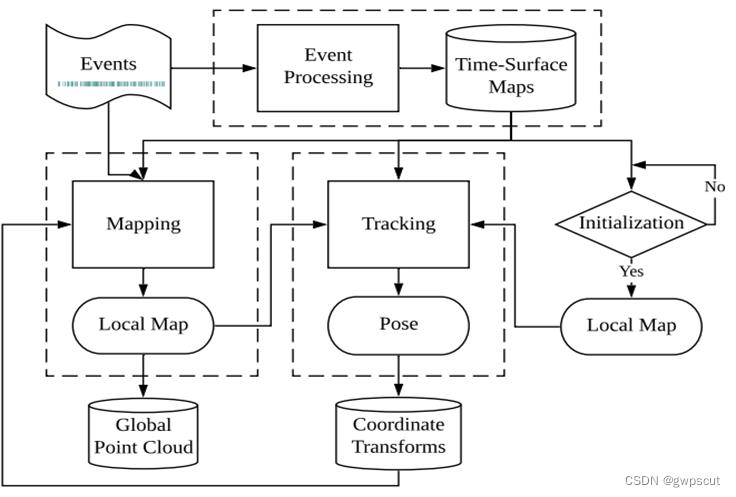
更多的关于event-based 3D reconstruction介绍可以看下面视频,本博文就单纯学习SVO了
Survey for 3D Reconstruction using Event Camera
Tracking(位姿估计线程)
第一步
第一步是通过基于模型的稀疏图像对齐进行位姿的初始化,具体一点说就是通过最小化相同路标点投影位置对应的像素之间的光度误差,得到相对于前一帧的相机姿态(相对位姿)。注意这里优化的对象是帧间的相对位姿(直接法)。
相邻两帧间的位姿通过最小化相同路标点投影位置对应的像素之间的光度误差计算得出:
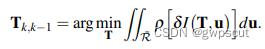
其中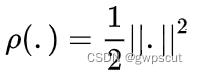 ,被积因式
,被积因式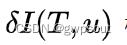 根据定义写为:
根据定义写为:
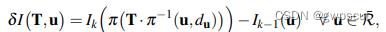
上式中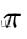 为相机的投影模型,
为相机的投影模型, 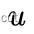 为像素坐标,而
为像素坐标,而 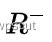 表示深度已知的像素区域,且该区域在上一帧中也有对应投影点。SVO不同于以往工作中知道图像中大部分区域的深度信息,SVO只知道稀疏的特征位置的深度信息。并且使用向量
表示深度已知的像素区域,且该区域在上一帧中也有对应投影点。SVO不同于以往工作中知道图像中大部分区域的深度信息,SVO只知道稀疏的特征位置的深度信息。并且使用向量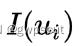 表示特征点周围4*4的像素块的强度值(光度值),两帧图像间相应特征点的该向量之差就是光度误差,对两帧图像间所有的特征点的的光度误差进行最小化,就得到了本节开头列出的非线性优化方程,进一步改写为:
表示特征点周围4*4的像素块的强度值(光度值),两帧图像间相应特征点的该向量之差就是光度误差,对两帧图像间所有的特征点的的光度误差进行最小化,就得到了本节开头列出的非线性优化方程,进一步改写为:
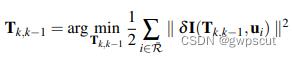
使用高斯牛顿法求解上述优化方程得到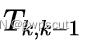 的估计值后,文章还通过引入李代数扰动量
的估计值后,文章还通过引入李代数扰动量 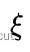 参数化了位姿的增量更新
参数化了位姿的增量更新 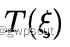 ,该更新增量可以用于更新位姿的估计中:
,该更新增量可以用于更新位姿的估计中:
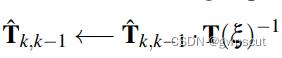
那么这个更新增量 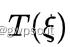 怎么求得呢,文章中给出了较大篇幅的说明,首先由第一步得到的估计位姿对同意路标的进行变换后,由当前帧的强度减去上一帧有扰动量之后的强度:
怎么求得呢,文章中给出了较大篇幅的说明,首先由第一步得到的估计位姿对同意路标的进行变换后,由当前帧的强度减去上一帧有扰动量之后的强度:
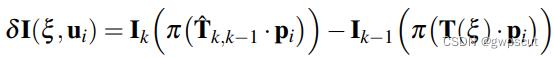
之后再对优化方程求导得到:
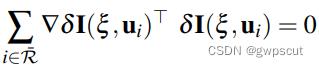
对 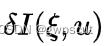 进行线性化:
进行线性化:
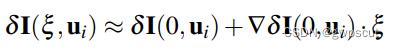
之后再考虑像素强度对扰动的导数,也就是雅可比矩阵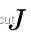 ,联合上述两式可以得到:
,联合上述两式可以得到:
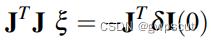
这样就可以解出 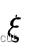 ,进而也就可以解出
,进而也就可以解出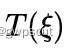 。
。
这一部分中论文还指出一个可以加速计算速度的技巧,由于前一帧图像特征块的强度值不变,以及路标点也不变,因此雅可比矩阵 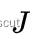 在迭代求解中保持不变,这说明我们可以预先只计算一次雅可比矩阵,这将显著提升计算速度,在作者的代码中也得到了体现。
在迭代求解中保持不变,这说明我们可以预先只计算一次雅可比矩阵,这将显著提升计算速度,在作者的代码中也得到了体现。
至此就完成了该线程的第一步:初估相机位姿,接下来将进行第二步:优化特征块的重投影位置。
第二步
第二步是通过相应的特征(块)对齐,对重投影点对应的二维坐标进行细化。意思是说,由于先前估计的位姿和路标点位置可能有误差,当前帧中的特征块与参考关键帧中相应的特征块之间会存在光度误差(灰度不变假设),我们在这一步中不考虑相机位姿,而是直接对当前帧中每一个特征块的2D位置进行单独优化以进一步最小化特征块的光度误差,这就建立了重投影点误差,也得到了相同路标点对应的重投影点的较好估计。这一步中优化的对象是当前帧中特征块的2D位置(重投影位置)。
根据第一步得到的相机位姿,我们可以得到在当前帧中可观测到的3D点的投影点(特征点)位置的初步估计。由于第一步的位姿估计和3D点坐标存在误差,因此对投影点位置的初步估计显然也是有误差的。
在构造优化之前,先根据估计的位姿计算当前帧中特征的估计位置,然后对每一个重投影点都识别包含该点的关键帧(来源于地图map,因此该关键帧的信息认为是准确的),然后构造优化问题为:
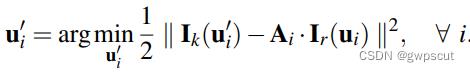
其中误差函数是光度误差 = 当前帧中特征的强度值 - 关键帧 r 中相应特征的强度值,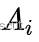 是对参考特征块的仿射变形,之所以使用仿射变形是因为这一步中使用的图像块更大(8*8),并且参考关键帧距离当前帧的距离更远一些(比起前一帧)。这一过程使用LK光流算法求解。
是对参考特征块的仿射变形,之所以使用仿射变形是因为这一步中使用的图像块更大(8*8),并且参考关键帧距离当前帧的距离更远一些(比起前一帧)。这一过程使用LK光流算法求解。
在这一步中,实现了特征块之间更高的相关性(我觉得也可以说是获得特征块更准确的像素位置),但代价是违反了对极约束,因此有了下面这步对位姿和路标点位置的精细化估计。
第三步
最后一步是对相机位姿和路标点位置进行优化估计,这一步中重投影位置是使用上一步中优化后的,参考帧是地图中的关键帧,因此均认为是准确的。优化的对象是路标点位置和相机位姿。
由于第二步之后的特征点坐标 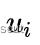 是准确的,因此我们可以再次对相机位姿进行优化估计:
是准确的,因此我们可以再次对相机位姿进行优化估计:
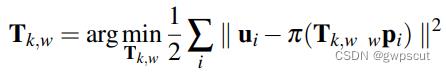
上式的形式是只对位姿进行估计的BA问题,可通过高斯牛顿法进行迭代求解。随后可以再构造最小化重投影误差的优化问题来优化观测到的路标点的位置。
Mapping(建图线程)
-
第一步是从图像帧队列中读入图像帧,并检测图像帧是否是关键帧。
-
如果该帧图像是关键帧的话,就对图像进行特征提取,并对每个2D特征初始化概率深度滤波器,这些滤波器的初始化有很大的不确定性,在随后的图像帧中深度估计都将以贝叶斯方式更新。
-
如果该帧图像不是关键帧的话,就用来更新深度滤波器,当深度滤波器的不确定性足够小时(收敛时),在地图中插入相应的3D点(更新地图),并用来估计位姿
参考资料
SVO Pro Semi-direct Visual-Inertial Odometry and SLAM for Monocular, Stereo, and Wide Angle Cameras
https://rpg.ifi.uzh.ch/docs/TRO17_Forster-SVO.pdf
https://rpg.ifi.uzh.ch/docs/ICRA14_Forster.pdf
GitHub - uzh-rpg/rpg_svo_pro_open
GitHub - uzh-rpg/rpg_svo: Semi-direct Visual Odometry
以上是关于学习笔记之——Semi-direct Visual Odometry (SVO)的主要内容,如果未能解决你的问题,请参考以下文章