Python数据清洗 & 预处理入门完整指南
Posted 我爱Python数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python数据清洗 & 预处理入门完整指南相关的知识,希望对你有一定的参考价值。
凡事预则立,不预则废,训练机器学习模型也是如此。数据清洗和预处理是模型训练之前的必要过程,否则模型可能就废了。本文是一个初学者指南,将带你领略如何在任意的数据集上,针对任意一个机器学习模型,完成数据预处理工作。
人们通常认为,数据预处理是一个非常枯燥的部分。但它就是做好准备和完全没有准备之间的差别,也是表现专业和业余之间的差别。就像为度假做好事先准备一样,如果你提前将行程细节确定好,就能够预防旅途变成一场噩梦。
文章目录
那么,应该怎么做呢?
本文将带你领略,如何在任意的数据集上,针对任意一个机器学习模型,完成数据预处理工作。
导入
让我们从导入数据预处理所需要的库开始吧。库是非常棒的使用工具:将输入传递给库,它则完成相应的工作。你可以接触到非常多的库,但在 Python 中,有三个是最基础的库。任何时候,你都很可能最终还是使用到它们。这三个在使用 Python 时最流行的库就是 Numpy、Matplotlib 和 Pandas。Numpy 是满足所有数学运算所需要的库,由于代码是基于数学公式运行的,因此就会使用到它。Maplotlib(具体而言,Matplotlib.pyplot)则是满足绘图所需要的库。Pandas 则是最好的导入并处理数据集的一个库。对于数据预处理而言,Pandas 和 Numpy 基本是必需的。
最适当的方式是,在导入这些库的时候,赋予其缩写的称呼形式,在之后的使用中,这可以节省一定的时间成本。这一步非常简单,可以用如下方式实现:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
现在,可以通过输入如下语句读入数据集:
dataset = pd.read_csv('my_data.csv')
这个语句告诉 Pandas(pd) 来读入数据集。在本文中,我也附上数据集的前几行数据。
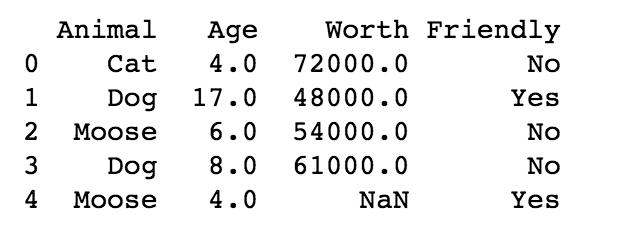
我们有了数据集,但需要创建一个矩阵来保存自变量,以及一个向量来保存因变量。为了创建保存自变量的矩阵,输入语句:
X = dataset.iloc[:, :-1].values
第一个冒号表示提取数据集的全部行,「:-1」则表示提取除最后一列以外的所有列。最后的「.values」表示希望提取所有的值。接下来,我们希望创建保存因变量的向量,取数据的最后一列。输入语句:
y = dataset.iloc[:, 3].values
记住,在查看数据集的时候,索引(index)是从 0 开始的。所以,如果希望统计列数,从 0 开始计数而不是 1。「[:, :3]」会返回 animal、age 和 worth 三列。其中 0 表示 animal,1 表示 age,2 表示 worth。对于这种计数方法,即使你没见过,也会在很短的时间内适应。
如果有缺失数据会怎么样?
事实上,我们总会遇到数据缺失。对此,我们可以将存在缺失的行直接删除,但这不是一个好办法,还很容易引发问题。因此需要一个更好的解决方案。最常用的方法是,用其所在列的均值来填充缺失。为此,你可以利用 scikit-learn 预处理模型中的 inputer 类来很轻松地实现。(如果你还不知道,那么我强烈建议你搞明白它:scikit-learn 包含非常棒的机器学习模型)。在机器学习中,你可能并不适应诸如方法、类和对象这些术语。这不是什么大问题!
-
类就是我们希望为某目的所建立的模型。如果我们希望搭建一个棚子,那么搭建规划就是一个类。
-
对象是类的一个实例。在这个例子中,根据规划所搭建出来的一个棚子就是一个对象。同一个类可以有很多对象,就像可以根据规划搭建出很多个棚子一样。
-
方法是我们可以在对象上使用的工具,或在对象上实现的函数:传递给它某些输入,它返回一个输出。这就像,当我们的棚子变得有点不通气的时候,可以使用「打开窗户」这个方法。
为了使用 imputer,输入类似如下语句。
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values = np.nan, strategy = ‘mean’, axis = 0)
均值填充是默认的填充策略,所以其实不需要指定,加在此处是为了方便了解可以包含什么信息。missing_values 的默认值是 nan。如果你的数据集中存在「NaN」形式的缺失值,那么你应该关注 np.nan,可以在此查看官方文档:
https://scikit-learn.org/stable/modules/generated/sklearn.impute.SimpleImputer.html
为了拟合这个 imputer,输入:
imputer = imputer.fit(X[:, 1:3])
我们只希望在数据存在缺失的列上拟合 imputer。这里的第一个冒号表示包含所有行,而「1:3」则表示我们取索引为 1 和 2 的列。不要担心,你很快就会习惯 Python 的计数方法的。
现在,我们希望调用实际上可以替换填充缺失数据的方法。通过输入以下语句完成:
X[:, 1:3] = imputer.transform(X[:, 1:3])
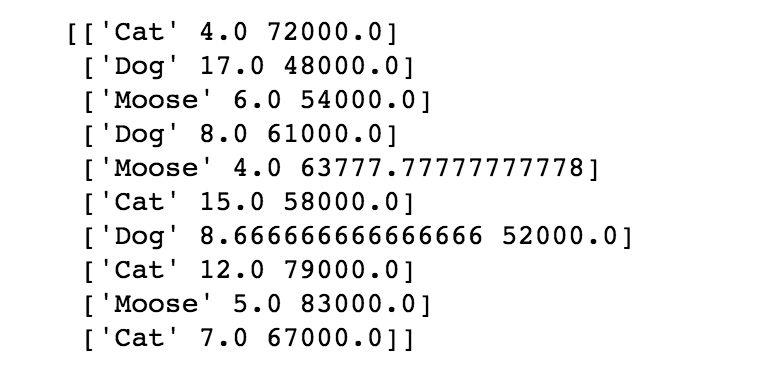
多尝试一些不同的填充策略。也许在某些项目中,你会发现,使用缺失值所在列的中位数或众数来填充缺失值会更加合理。填充策略之类的决策看似细微,但其实意义重大。因为流行通用的方法并不一定就是正确的选择,对于模型而言,均值也不一定是最优的缺失填充选择。
毕竟,几乎所有正阅读本文的人,都有高于平均水平的手臂数。
如果包含属性数据,会怎么样呢?
这是一个好问题。没有办法明确地计算诸如猫、狗、麋鹿的均值。那么可以怎么做呢?可以将属性数据编码为数值!你可能希望使用 sklearn.preprocessing 所提供的 LabelEncoder 类。从你希望进行编码的某列数据入手,调用 label encoder 并拟合在你的数据上。
from sklearn.preprocessing import LabelEncoder
labelencoder_X = LabelEncoder()
X[:, 0] = labelencoder_X.fit_transform(X[:, 0])
(还记得括号里的数字所表示的含义吗?「:」表示希望提取所有行的数据,0 表示希望提取第一列)
这就是将第一列中的属性变量替换为数值所需的全部工作了。例如,麋鹿将用 0 表示,狗将用 2 表示,猫将用 3 表示。
你发现什么潜在问题了吗?
标注体系暗含以下信息:所使用的数值层级关系可能会影响模型结果:3 比 0 的数值大,但猫并不一定比麋鹿大。
我们需要创建哑变量。
我们可以为猫创建一列数据,为麋鹿创建一列数据,……以此类推。然后,将每一列分别以 0/1 填充(认为 1=Yes,0 = No)。这表明,如果原始列的值为猫,那么就会在麋鹿一列得到 0,狗一列得到 0,猫一列得到 1。
看上去非常复杂。输入 OneHotEncoder 吧!
导入编码器,并制定对应列的索引。
from sklearn.preprocessing import OneHotEncoder
onehotencoder = OneHotEncoder(categorical_features = [0])
接着是一点拟合和转换。
X = onehotencoder.fit_transform(X).toarray()
现在,你的那一列数据已经被替换为了这种形式:数据组中的每一个属性数据对应一列,并以 1 和 0 取代属性变量。非常贴心,对吧?如果我们的 Y 列也是如「Y」和「N」的属性变量,那么我们也可以在其上使用这个编码器。
labelencoder_y = LabelEncoder()
y = labelencoder_y.fit_transform(y)
这会直接拟合并将 y 表示为编码变量:1 表示「Y」,0 表示「N」。

训练集与测试集的划分
现在,你可以开始将数据集划分为训练集和测试集了。这已经在之前的图像分类教程一文中论述过了。不过记得,一定要将你的数据分为训练集和测试集,永远不要用测试集来训练!需要避免过拟合。(可以认为,过拟合就像在一次测验前,记忆了许多细节,但没有理解其中的信息。如果只是记忆细节,那么当你自己在家复习知识卡片时,效果会很好,但在所有会考察新信息的真实测验中,都会不及格。)
现在,我们有了需要学习的模型。模型需要在数据上训练,并在另外的数据上完成测试。对训练集的记忆并不等于学习。模型在训练集上学习得越好,就应该在测试集给出更好的预测结果。过拟合永远都不是你想要的结果,学习才是!
首先,导入:
from sklearn.model_selection import train_test_split
现在,可以创建 X_train、X_test、y_train 和 y_test 集合了。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
一种常见的方法是将数据集按 80/20 进行划分,其中 80% 的数据用作训练,20% 的数据用作测试。这也是为何指定 test_size 为 0.2 的原因。你也可以根据自己的需求来任意划分。你并不需要设置 random_state,这里设置的原因是为了可以完全复现结果。
特征缩放
什么是特征缩放?为什么需要特征缩放?
看看我们的数据。我们有一列动物年龄,范围是 417,还有一列动物价值,范围是48,00083,000。价值一栏的数值不仅远大于年龄一栏,而且它还包含更加广阔的数据范围。这表明,欧式距离将完全由价值这一特征所主导,而忽视年龄数据的主导效果。如果欧式距离在特定机器学习模型中并没有具体作用会怎么样?缩放特征将仍能够加速模型,因此,你可以在数据预处理中,加入特征缩放这一步。
特征缩放的方法有很多。但它们都意味着我们将所有的特征放在同一量纲上,进而没有一个会被另一个所主导。
导入相关库开始:
from sklearn.preprocessing import StandardScaler
创建一个需要缩放对象并调用 Standard Scaler 。
sc_X = StandardScaler()
直接在数据集上进行拟合以及变换。获取对象并应用方法。
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
不需要在测试集上进行拟合,只进行变换。
sc_y = StandardScaler()
y_train = sc_y.fit_transform(y_train)
对于哑变量而言是否需要进行缩放?
对于这个问题,有些人认为需要,有些则认为不需要。这取决于你对模型可解释性的看重诚度。将所有数据缩放至同一量纲固然有好处,但缺点是,这丢失了解释每个观测样本归属于哪个变量的便捷性。
对于 Y 呢?如果因变量是 0 和 1,那么并不需要进行特征缩放。这是一个具有明确相关值的分类问题。但如果其取值范围非常大,那么答案是你需要做缩放。
恭喜你,你已经完成了数据预处理的工作!
通过少量的几行代码,你已经领略了数据清洗和预处理的基础。毫无疑问,在数据预处理这一步中,你可以加入很多自己的想法:你可能会想如何填充缺失值。思考是否缩放特征以及如何缩放特征?是否引入哑变量?是否要对数据做编码?是否编码哑变量……有非常多需要考虑的细节。现在,你已经完全了解了这些,可以亲自动手试试了,准备数据吧!
以上是关于Python数据清洗 & 预处理入门完整指南的主要内容,如果未能解决你的问题,请参考以下文章