决策树
Posted 雷八天
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了决策树相关的知识,希望对你有一定的参考价值。
决策树在机器学习算法中处理分类问题。 通过所给的训练数据学习得到一个模型,对新的数据进行分类判断。达到“决策”的效果,我们称这样学习得到的树为决策树。决策树归纳是从有类标号的训练元组中学习决策模型。常用的决策树算法有ID3,C4.5和CART。它们都是采用贪心(即非回溯的)方法,自顶向下递归的分治方法构造。这几个算法选择属性划分的方法各不相同, ID3使用的是信息增益,C4.5使用的是信息增益率,而CART使用的是Gini基尼指数 。下面来简单介绍下决策树的理论知识。内容包含 熵 、 信息增益 、 信息增益率 以及 Gini指数 的概念及公式。
这里讲述我的一些浅显的理解,后面如果有积累,继续更新内容: 熵:1948年香农提出了“信息熵”的概念,解决了对信息的量化度量的问题。 表达的是概率与信息冗余度之间的关系 性质: 单调性:发生概率越大的事件得到的信息量越小 非负性:信息熵非负,得到信息量>=0 累加性:多随机事件同时发生存在的总不确定性 香农从数学上,严格证明了满足上述三个条件的随机变量不确定性度量函数具有唯一形式:
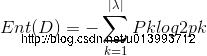 信息增益:
我们用信息增益选择最优的划分属性,信息增益等于总的样本的信息熵减去属性中取值的平均信息熵
所以,信息增益越大,纯度提升越大。
类似与哈夫曼树,我们要的到最优路径,能够最快的判断一个样本的类别。
一个样本进入决策树中,我们要依据之前训练的模型,更快的得到样本的类别。
所以训练过程中,依据训练数据选择每个属性之后,所剩下的样本类别更少,所构建的决策树的路径更短。(纯度)
从公式上理解:信息增益可以理解成剩余的信息量,剩余的信息量越少,离最后得到的结果越近
信息增益:
我们用信息增益选择最优的划分属性,信息增益等于总的样本的信息熵减去属性中取值的平均信息熵
所以,信息增益越大,纯度提升越大。
类似与哈夫曼树,我们要的到最优路径,能够最快的判断一个样本的类别。
一个样本进入决策树中,我们要依据之前训练的模型,更快的得到样本的类别。
所以训练过程中,依据训练数据选择每个属性之后,所剩下的样本类别更少,所构建的决策树的路径更短。(纯度)
从公式上理解:信息增益可以理解成剩余的信息量,剩余的信息量越少,离最后得到的结果越近

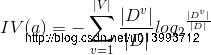

决策树伪代码: 输入:D, A 过程:函数getDecisionTree(D,A) 生成节点node if(D中样本全部属于一类) then 将node编辑为叶子节点 return end if if A != null or D中样本在A上的取值相同 then 将node至于叶子节点,节点类型为任意一个样本的类型 return end if 从A中选取最优的划分属性/Card/ID3/C4.5 for A do 为node生成一个分支节点,Dv表示的D中取值为a的样本子集 ifDv为空 then 将分支节点标记为叶子节点,类别为样本子集中类别最大的类 return else getDecisionTree(Dv, A/a) end if end for
以上是关于决策树的主要内容,如果未能解决你的问题,请参考以下文章