ElasticSearch的由来
Posted 愉悦滴帮主)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch的由来相关的知识,希望对你有一定的参考价值。
聊聊Lucene的创始人
我们在了解ElasticSearch的时候,必将绕不开Lucene。因为ElasticSearch是基于Luence开发的。因为Luence又是Doug Cutting开发的,所以我们先了解一下Doug Cutting这个人。
本故事内容来自公众号:酸枣课堂
聊聊Doug Cutting
大数据就两个问题:存储+计算。
1998年9月4日,Google公司在美国硅谷成立。正如大家所知,它是一家做搜索引擎起家的公司。

无独有偶,一位叫Doug Cutting的美国工程师,也迷上了搜索引擎。他做了一个用于文本搜索的函数库(姑且理解为软件的功能组件),命名为Lucene。
Lucene是用Java编写的,其作用是为各种中小型应用软件加入全文检索功能。因为好用而且开源(代码公开),非常受广大开发者们的欢迎。
早期的时候,这个项目被发布在Doug Cutting的个人网站和SourceForge(一个开源的软件网站)。后开,2001年底,lucene成为Apache软件基金会Jakarta项目的一个子项目。

2004年,Doug Cutting再接再厉,在Lucene的基础上和Apache开源伙伴Mike Cafarella合作,开发了一款可以替代当时的主流搜索的开源搜索引擎,命名为Nutch。

Nutch是一个建立在lucene核心之上的网页搜索应用程序,可以下载下来直接使用。它在lucene的基础上加了网络爬虫和一些网页相关的功能,目的就是从一个简单的站内检索推广到全球网络的搜索上,就像Google一样。
Nutch在业内的影响力比Lucene更大。
大批网站采用了Nutch平台,大大降低了技术门槛,使低成本的普通计算机取代高价的Web服务器成为可能。甚至有一段时间,在硅谷有了一股用Nutch低成本的创业的潮流。
随着时间的推移,无论是Google还是Nutch,都面临搜索对象“体积”不断增大的问题。尤其是Google,作为互联网搜索引擎,需要存储大量的网页,并不断优化自己的搜索算法,提升搜索效率。

在这个过程中,Goolge确实找到了不少好办法,并且无私地分享了出来。
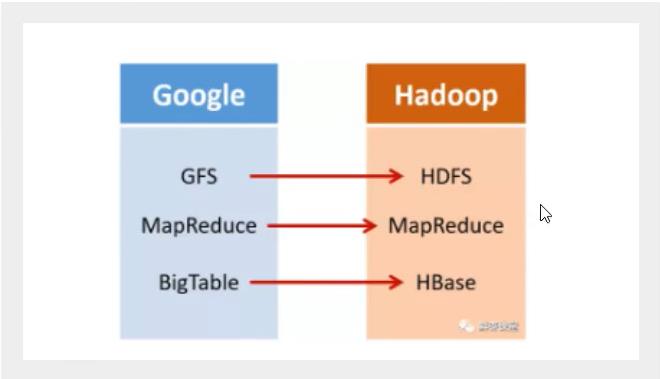
2003年,Google发表了一篇技术学术论文,公开介绍了自己的谷歌文件系统GFS(Google File System)。这是Google公司为了存储海量搜索数据而设计的专用文件存储系统。
第二年,也就是2004年,Doug Cutting基于Google的GFS论文,实现了分布式文件存储系统,并将它命名为NDFS(Nutch Distributed File System)。
还是2004年,Google又发表了一篇技术学术论文,介绍了自己的MapReduce编程模型。这个编程模型,用于大规模数据集(大于1TB)的并行分析运算。
第二年(2005年),Doug Cutting又基于MapReduce,在Nutch搜索引擎实现了该功能。
2006年,当时依然很厉害的Yahoo(雅虎)公司,招安了Doug Cutting。
加盟Yahoo之后,Doug Cutting将NDFS和MapReduce进行了升级改造,并重新命名为Hadoop(NDFS也改名为HDFS,Hadoop Distributed File)。
这个,就是后来大名鼎鼎的大数据框架系统———Hadoop的由来。而Doug Cutting,则被人们称为Hadoop之父。

Hadoop这个名字,实际上使Doug Cutting他儿子的黄色玩具大象的名字。所以,Hadoop的Logo,就是一只奔跑的黄色大象。
我们继续往下说。还是2006年,Google又发表论文了。这次,他们介绍了自己的BigTable。这是一种分布式数据存储系统,一种用来处理海量数据的非关系型数据库。
Doug Cutting当然没有放过,在自己的hadoop系统里面,引入了BigTable,并命名为Hbase。
好吧,反正就是跟紧Google时代的步伐,你出什么,我学什么。所以,Hadoop的核心部分,基本上都有Google的影子。
2008年1月,Hadoop成功上位,正式称为Apache基金会的顶级项目。
同年2月,Yahoo宣布建成了一个拥有一万个内核的Hadoop集群,并将自己的搜索引擎产品部署在上面。7月,Hadoop打破世界纪录,称为最快排序1TB数据的系统,用时209秒。
聊聊Shay Banon
通过上述介绍我们了解到Lucence的由来,并且知道了Lucene是一套信息检索工具包。是一个基于Java编写的jar包。不包含搜索引擎系统。
包含的:索引结构!读写索引的工具!排序,搜索规则。。。工具类!
Lucene和ElasticSearch关系:
ElasticSearch是基于Lucene做了一些封装和增强(我们上手是十分简单的)。
历史由来:
多年前,一个叫做Shay Banon的刚结婚不久的失业开发者,由于妻子要去伦敦学习厨师,他便跟着也去了。他在找工作的过程中,为了给妻子构建一个食谱的搜索引擎,他开始构建一个早期版本的Lucene。
直接基于Luence工作会比较困难,所以Shay开始抽象Lucene代码以便java程序员可以在应用中添加搜索功能。他发布的第一个开源项目,叫做“Compass”。
后开Shay找到一份工作,这份工作处在高性能和内存数据网络的分布式环境中,因此高性能的、实时的、分布式的搜索引擎也就是利索当然需要的。然后他决定重写Compass库使其成为一个独立的服务叫做Elasticsearch。
第一个公开版本出现在2010年2月,在那之后Elasticsearch已经成为GitHub上最受欢用的项目之一,代码贡献者超过300人。一家主营ElasicSearch的公司就此成立,他们一边提供商业支持一边开发新功能,不过Elasticseach将永远开源且对所有人可用。
不过,Shay的妻子依旧等待者她的搜索食谱......
以上是关于ElasticSearch的由来的主要内容,如果未能解决你的问题,请参考以下文章