云享团——基于大数据开发套件的增量同步策略
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云享团——基于大数据开发套件的增量同步策略相关的知识,希望对你有一定的参考价值。
免费开通大数据服务:https://www.aliyun.com/product/odps
转载自云享团
因为近期遇到用户在做ETL操作导入数据到MaxCompute的时候,对如何设置数据同步策略有疑惑,所以今天第一波我们来聊一下数据的同步策略,根据数据的特性,看看哪些数据适合增量同步,哪些适合全量同步,又是如何实现的?请认真看完下面的介绍,这些问题都不是事儿。
我们把需要同步的数据,根据数据写入后是否会发生变化分为:会变化的数据(人员表比如说,人员的状态会发生变化)和不会发生变化的数据(一般是日志数据)。针对这两种场景,我们需要设计不同的同步策略。这里以把业务RDS数据库的数据同步到MaxCompute为例做一些说明,其他的数据源的道理是一样的。根据等幂性原则(也就是说一个任务,多次运行的结果是一样的,这样才能支持重跑调度。如果任务出现错误,也比较容易清理脏数据),我每次导入数据都是导入到一张单独的表/分区里,或者覆盖里面的历史记录。
备注说明:本文的测试时间是2016-11-14,全量同步是在14号做的,同步历史数据到ds=20161113这个分区里。至于本文涉及的增量同步的场景,配置了自动调度,把增量数据在15号凌晨同步到ds=20161114的分区里。数据里有一个时间字段optime,用来表示这条数据的修改时间,从而判断这条数据是否是增量数据。
不变的数据
对应这种场景,因为数据生成后就不会发生变化,我们可以很方便地根据数据的生成规律进行分区,比较常见的是根据日期进行分区,比如每天一个分区。以下是测试数据:
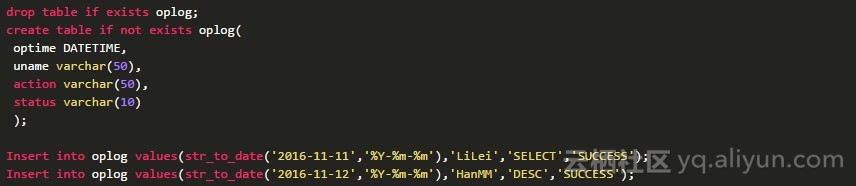
这里有2条数据,当成历史数据。我先做一次全量数据同步,到昨天的分区里。配置方法如下:
先在MaxCompute创建好表:

然后配置了历史数据数据同步: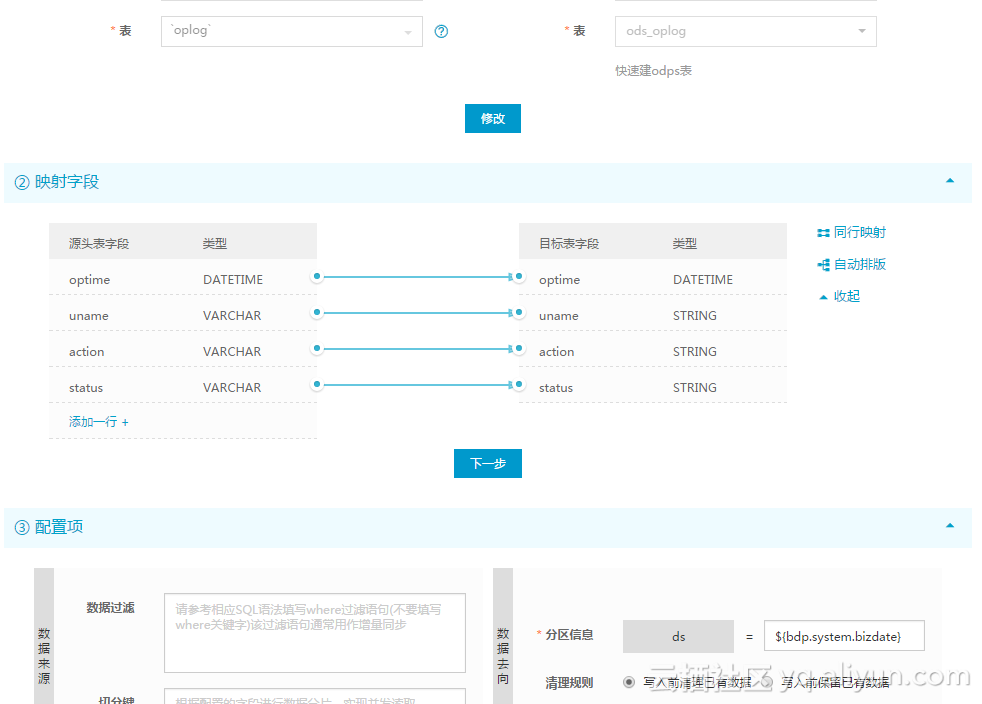
因为只需要跑一次,做以下测试就可以了。测试后到数据开发里把任务的状态改成暂停(最右边的调度配置了)并重新发布,免得明天他继续跑了。之后到MaxCompute里看一下结果: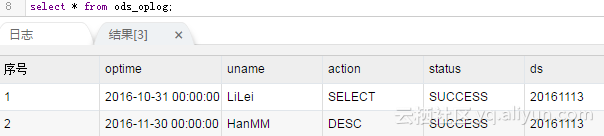
测试通过后。往mysql里多写一些数据作为增量数据:

然后配置同步任务如下。需要特别注意的是数据过滤这的配置,通过这个配置,可以在15号的凌晨的同步的时候,把14号全天新增的数据查询出来,然后同步到增量分区里。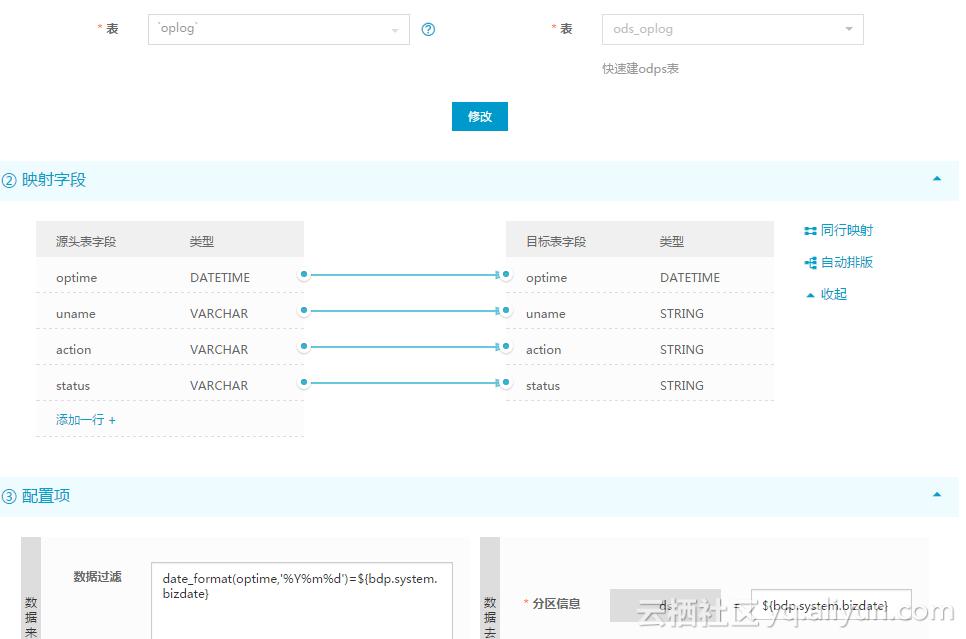
这个任务需要发布,设置调度周期为每天调度,第二天过来一看,MaxCompute里的数据变成了: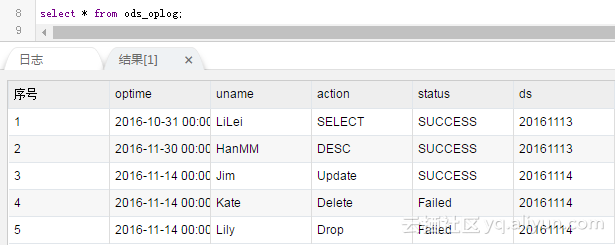
会变的数据
如人员表、订单表一类的会发生变化的数据,根据数据仓库的4个特点里的反映历史变化的这个特点的要求,我们建议每天对数据进行全量同步。也就是说每天保存的都是数据的全量数据,这样历史的数据和当前的数据都可以很方便地获得。不过如果真实的场景下因为某些特殊情况,需要每天也只做增量同步,因为MaxCompute不支持Update语句来修改数据,只能用别的一些方法来实现。两种同步策略的具体方法如下:
首先我们需要造一些数据:
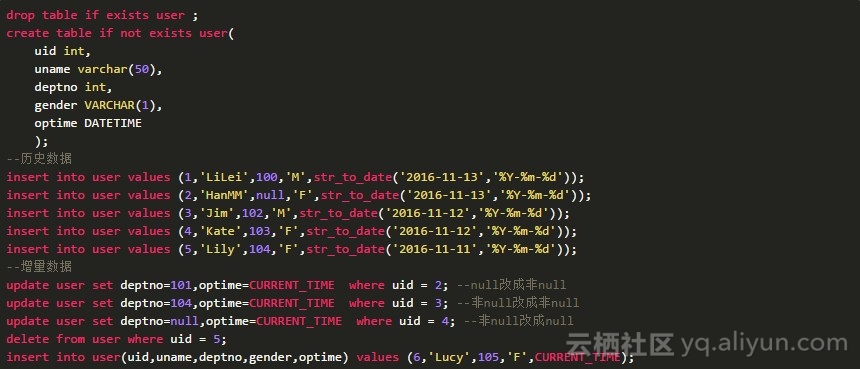
- 每天全量同步
每天全量同步同步比较简单:

然后配置同步为: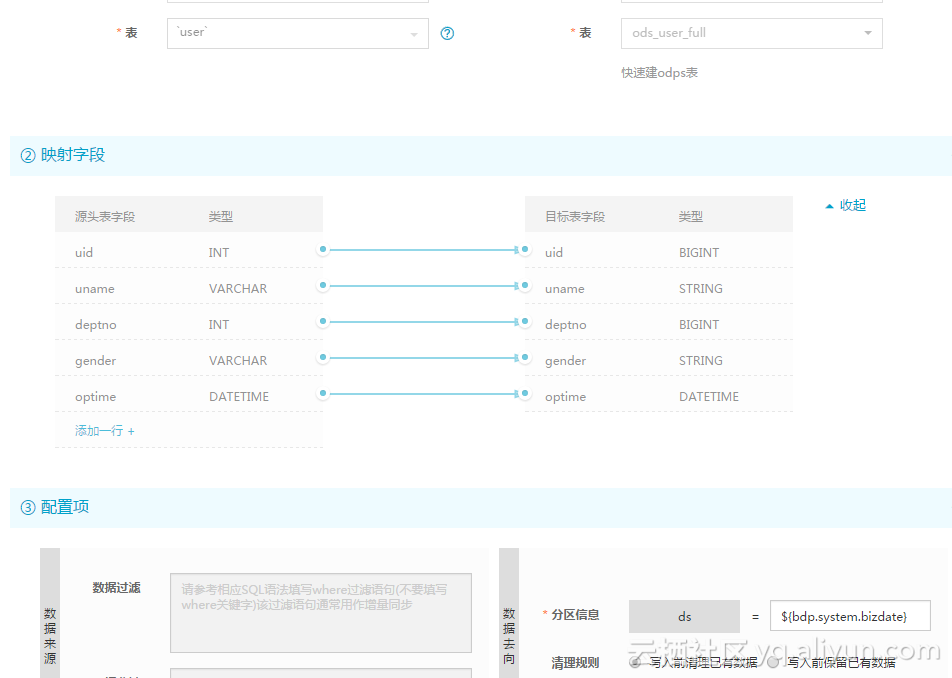
测试后结果为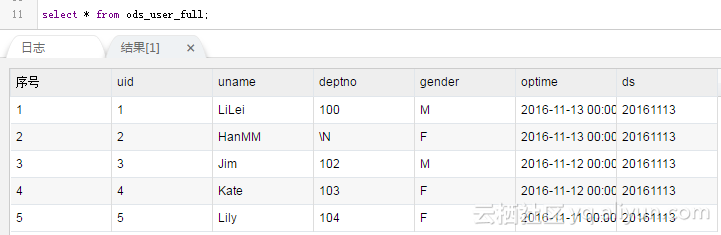
因为每天都是全量同步,没有全量和增量的区别,所以第二天就能看到数据结果为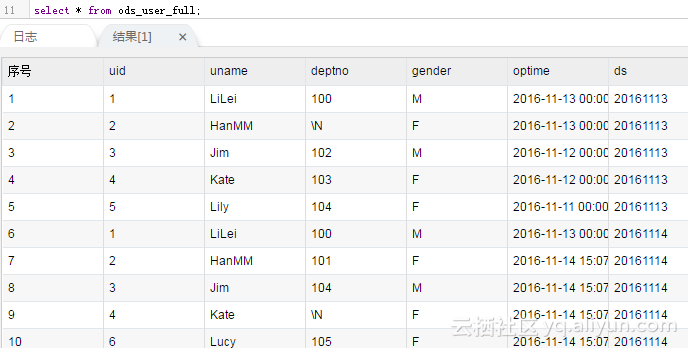
如果需要查询的话,就用where ds =‘20161114’来取全量数据即可了。
- 每天增量同步
非常不推荐用这种方法,只有在极特殊的场景下才考虑。首先这种场景不支持delete语句,因为被删除的数据无法通过SQL语句的过滤条件查到。当然实际上公司里的代码很少直接有直接删除数据的,都是使用逻辑删除,那delete就转化成update来处理了。但是这里毕竟限制了一些特殊的业务场景不能做了,当出现特殊情况可能导致数据不一致。另外还有一个缺点就是同步后要对新增的数据和历史数据做合并。具体的做法如下:
首先需要创建2张表,一张写当前的最新数据,一张写增量数据:

然后全量数据可以直接写入结果表: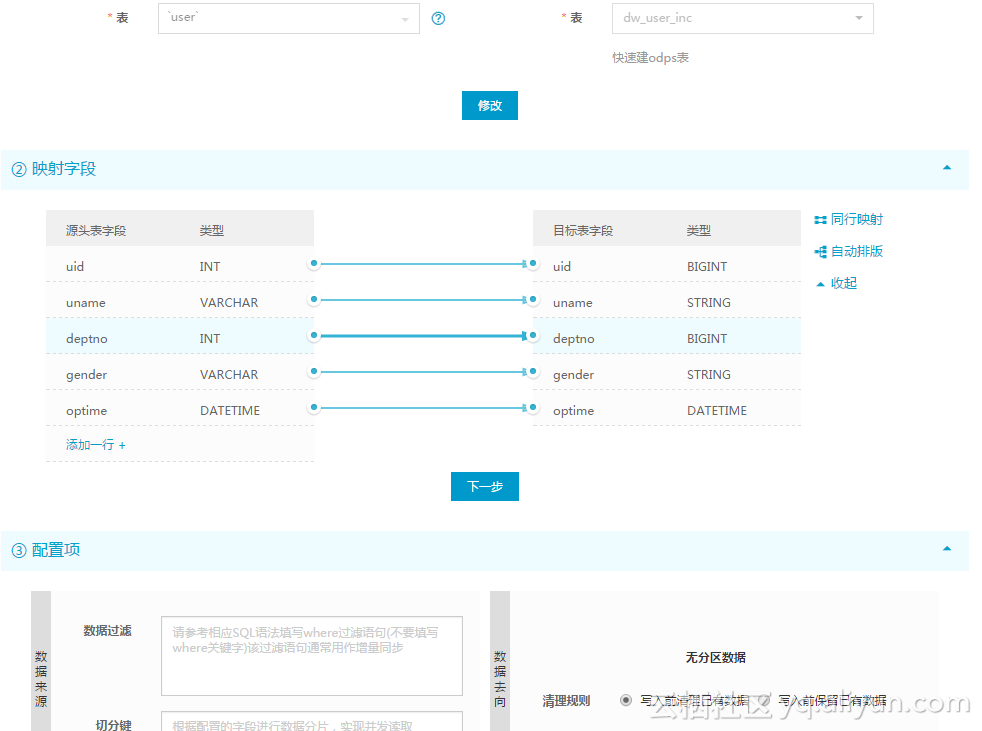
结果如下: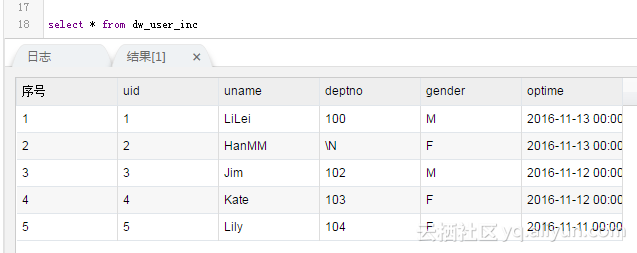
这个只要跑一次的,记得跑好后要暂停掉。
然后把增量数据写入到增量表里: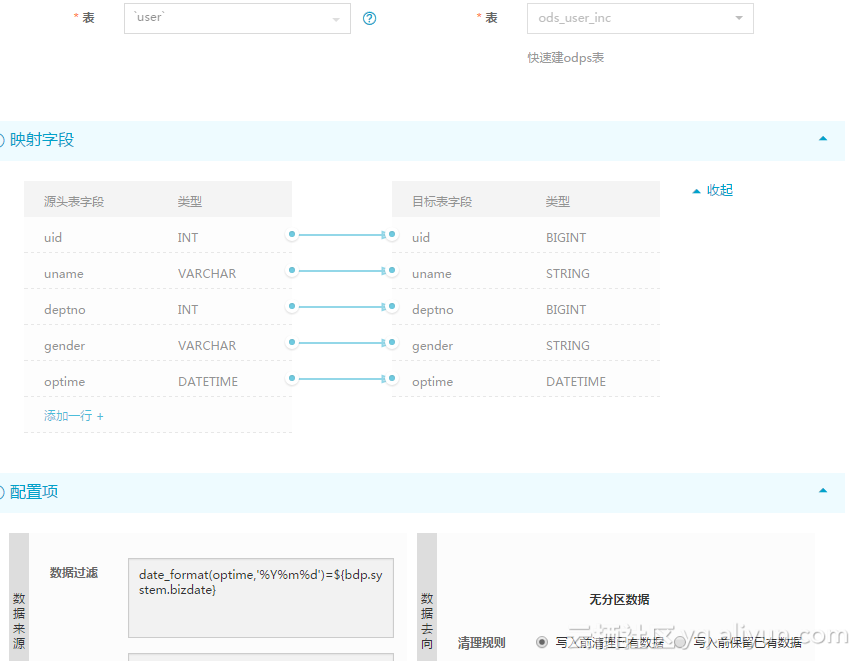
结果如下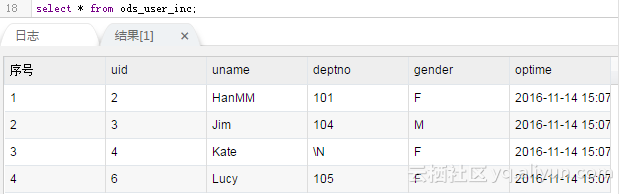
然后做一次合并

最终结果是: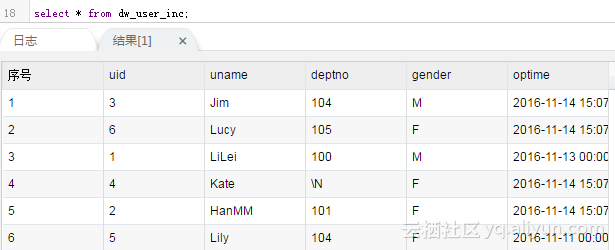
可以看到,delete的那条记录没有同步成功。
对比以上两种同步方式,可以很清楚看到两种同步方法的区别和优劣。第二种方法的优点是同步的增量数据量比较小,但是带来的缺点有可能有数据不一致的风险,而且还需要用额外的计算进行数据合并。如无必要,会变化的数据就使用方法一即可。如果对历史数据希望只保留一定的时间,超出时间的做自动删除,可以设置Lifecycle。
本文的作者技术专家“传学”,一直从事大数据技术支持工作,后续会持续带来大数据的干货分享,如果有什么疑问可以留言或者通过在线工单联系哦。(敏感业务信息不要公开评论哦)

以上是关于云享团——基于大数据开发套件的增量同步策略的主要内容,如果未能解决你的问题,请参考以下文章