Flink 架构——状态管理
Posted 果汁华
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink 架构——状态管理相关的知识,希望对你有一定的参考价值。
一、前言
状态的计算是流处理框架要实现的重要功能,因为稍复杂的流处理场景都需要记录状态,然后在新流入数据的基础上不断更新状态。下面的几个场景都需要使用流处理的状态功能:
-
数据流中的数据有重复,想对重复数据去重,需要记录哪些数据已经流入过应用,当新数据流入时,根据已流入过的数据来判断去重。
-
检查输入流是否符合某个特定的模式,需要将之前流入的元素以状态的形式缓存下来。比如,判断一个温度传感器数据流中的温度是否在持续上升。
-
对一个时间窗口内的数据进行聚合分析,分析一个小时内某项指标的75分位或99分位的数值。
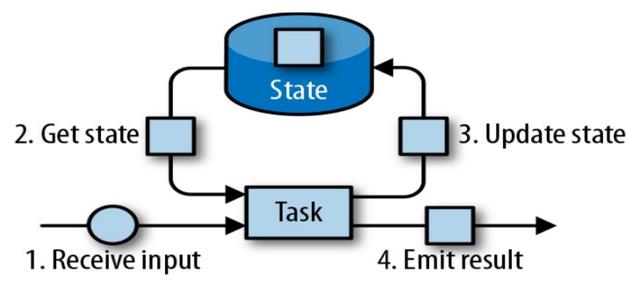
一个状态更新和获取的流程如下图所示,一个算子子任务接收输入流,获取对应的状态,根据新的计算结果更新状态。一个简单的例子是对一个时间窗口内输入流的某个整数字段求和,那么当算子子任务接收到新元素时,会获取已经存储在状态中的数值,然后将当前输入加到状态上,并将状态数据更新。
二、状态类型
Flink有两种基本类型的状态:托管状态(Managed State)和原生状态(Raw State)。
两者的区别:Managed State是由Flink管理的,Flink帮忙存储、恢复和优化,Raw State是开发者自己管理的,需要自己序列化。
对Managed State继续细分,它又有两种类型:Keyed State和Operator State。
2.1、Keyed State
Flink 为每个键值维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个key对应的状态。当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的key。因此,具有相同key的所有数据都会访问相同的状态。
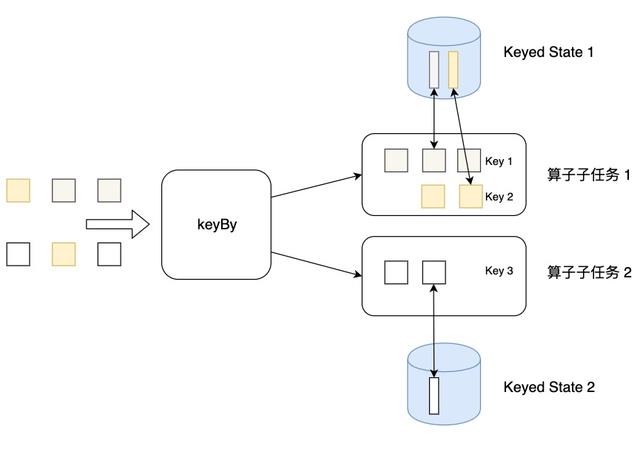
Flink 提供了以下数据格式来管理和存储键控状态 (Keyed State):
-
ValueState:存储单值类型的状态。可以使用
update(T)进行更新,并通过T value()进行检索。 -
ListState:存储列表类型的状态。可以使用
add(T)或addAll(List)添加元素;并通过get()获得整个列表。 -
ReducingState:用于存储经过 ReduceFunction 计算后的结果,使用 增加元素。
-
AggregatingState:用于存储经过 AggregatingState 计算后的结果,使用
add(IN)添加元素。 -
FoldingState:已被标识为废弃,会在未来版本中移除,官方推荐使用
AggregatingState代替。 -
MapState:维护 Map 类型的状态。
2.2、Operator State
Operator State可以用在所有算子上,每个算子子任务或者说每个算子实例共享一个状态,流入这个算子子任务的数据可以访问和更新这个状态。
算子状态不能由相同或不同算子的另一个实例访问。
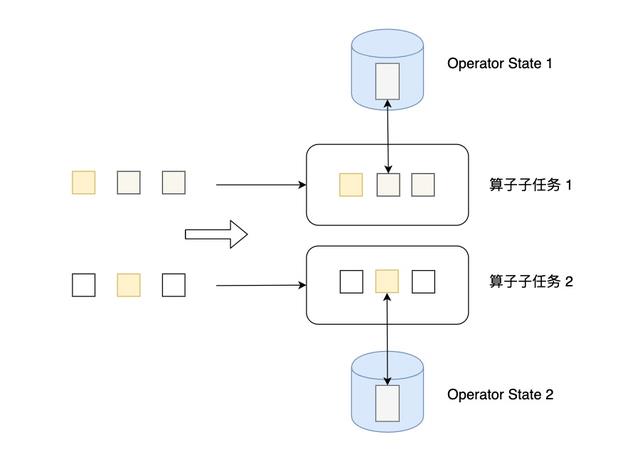
Flink为算子状态提供三种基本数据结构:
-
ListState:存储列表类型的状态。
-
UnionListState:存储列表类型的状态,与 ListState 的区别在于:如果并行度发生变化,ListState 会将该算子的所有并发的状态实例进行汇总,然后均分给新的 Task;而 UnionListState 只是将所有并发的状态实例汇总起来,具体的划分行为则由用户进行定义。
-
BroadcastState:用于广播的算子状态。如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。
# 触发指定id的作业的Savepoint,并将结果存储到指定目录下
bin/flink savepoint :jobId [:targetDirectory]点机制
为了使 Flink 的状态具有良好的容错性,Flink 提供了检查点机制 (CheckPoints) 。通过检查点机制,Flink 定期在数据流上生成 checkpoint barrier ,当某个算子收到 barrier 时,即会基于当前状态生成一份快照,然后再将该 barrier 传递到下游算子,下游算子接收到该 barrier 后,也基于当前状态生成一份快照,依次传递直至到最后的 Sink 算子上。当出现异常后,Flink 就可以根据最近的一次的快照数据将所有算子恢复到先前的状态。
4.1、开启检查点
默认情况下 checkpoint 是禁用的。通过调用 StreamExecutionEnvironment 的 enableCheckpointing(n) 来启用 checkpoint,里面的 n 是进行 checkpoint 的间隔,单位毫秒。
Checkpoint 其他的属性包括:
-
精确一次(exactly-once)对比至少一次(at-least-once):你可以选择向
enableCheckpointing(long interval, CheckpointingMode mode)方法中传入一个模式来选择使用两种保证等级中的哪一种。对于大多数应用来说,精确一次是较好的选择。至少一次可能与某些延迟超低(始终只有几毫秒)的应用的关联较大。
4.2、保存点机制
保存点机制 (Savepoints) 是检查点机制的一种特殊的实现,它允许通过手工的方式来触发 Checkpoint,并将结果持久化存储到指定路径中,主要用于避免 Flink 集群在重启或升级时导致状态丢失。示例如下:
# 触发指定id的作业的Savepoint,并将结果存储到指定目录下 bin/flink savepoint :jobId [:targetDirectory]
五、状态后端
Flink 提供了多种 state backends,它用于指定状态的存储方式和位置。
状态可以位于 Java 的堆或堆外内存。取决于 state backend,Flink 也可以自己管理应用程序的状态。为了让应用程序可以维护非常大的状态,Flink 可以自己管理内存(如果有必要可以溢写到磁盘)。默认情况下,所有 Flink Job 会使用配置文件 flink-conf.yaml 中指定的 state backend。
但是,配置文件中指定的默认 state backend 会被 Job 中指定的 state backend 覆盖。
横向扩展相关来于:Flink状态管理详解:Keyed State和Operator List State深度解析 checkpoint 相关来于:Apache Flink v1.10 官方中文文档
状态一致性相关来于:再忙也需要看的Flink状态管理
以上是关于Flink 架构——状态管理的主要内容,如果未能解决你的问题,请参考以下文章