MMDetection理解
Posted Arrow
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MMDetection理解相关的知识,希望对你有一定的参考价值。
MMDetection理解
- 1. Model整体构建流程和思想
- 2 整体抽象
- 3. Head 流程
- 4. Backbone
- 5. 常用算法
1. Model整体构建流程和思想
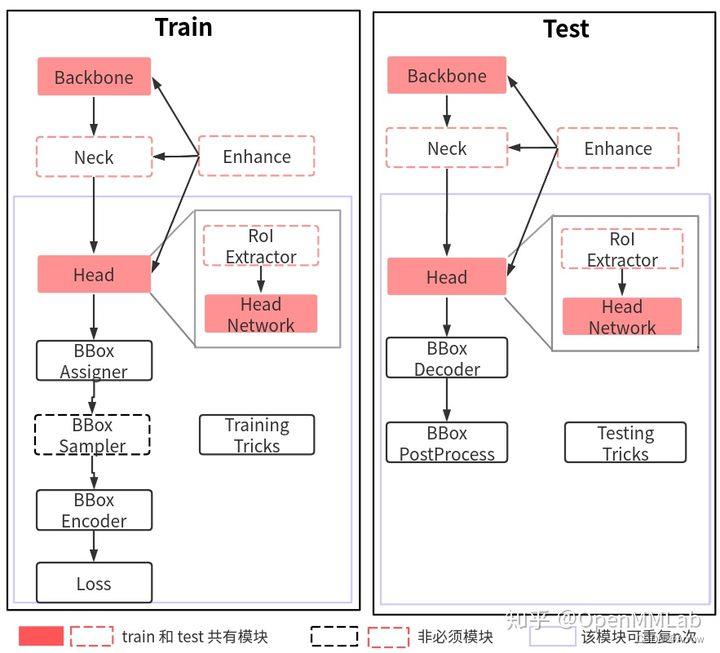
1.1 训练核心组件
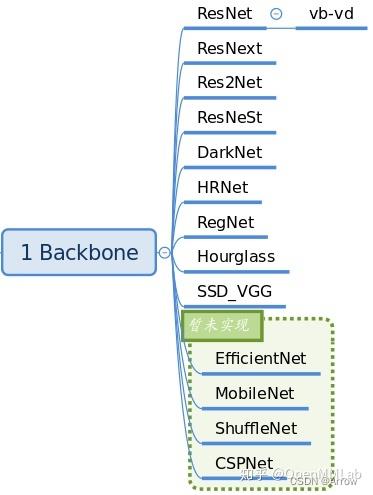
1.1.1 Backbone
- 功能:特征提取
- 常用的Backbone:ResNet 系列、ResNetV1d 系列和 Res2Net 系列
- 典型用法
# 骨架的预训练权重路径
pretrained='torchvision://resnet50',
backbone=dict(
type='ResNet', # 骨架类名,后面的参数都是该类的初始化参数
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch'),
- 支持的Backbones
1.1.2 Neck
- 功能:
- 是 backbone 和 head 的连接层
- 主要负责对 backbone 的特征进行高效融合和增强,能够对输入的单尺度或者多尺度特征进行融合、增强输出等
- 常用的Neck:FPN
- 典型用法
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048], # 骨架多尺度特征图输出通道
out_channels=256, # 增强后通道输出
num_outs=5), # 输出num_outs个多尺度特征图
- 支持的Necks

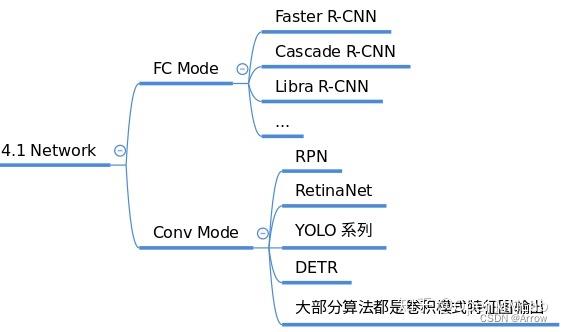
1.1.3 Head
- 功能:
- 负责分类、框和点的回归
- 在网络构建方面,理解目标检测算法主要是要理解 head 模块
- 常用的Head:每个算法都包括一个独立的 head
- 常用的Heads
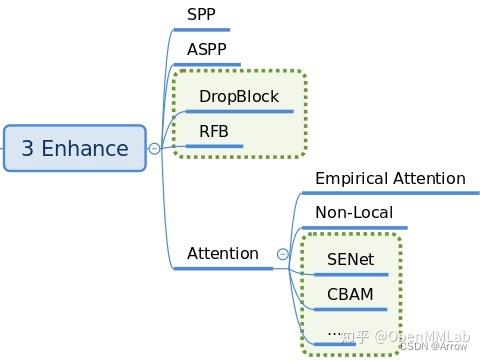
1.1.4 Enhance
- 功能:
- enhance 是即插即用、能够对特征进行增强的模块
- 其具体代码可以通过 dict 形式注册到 backbone、neck 和 head 中,非常方便
- 常用的enhance模块: SPP、ASPP、RFB、Dropout、Dropblock、DCN 和各种注意力模块 SeNet、Non_Local、CBA 等
- 支持的Enhances
1.1.5 BBox Assigner
- 功能:
- 正负样本属性分配模块作用是进行正负样本定义或者正负样本分配(可能也包括忽略样本定义),正样本就是常说的前景样本(可以是任何类别),负样本就是背景样本。
- 因为目标检测是一个同时进行分类和回归的问题,对于分类场景必然需要确定正负样本,否则无法训练。
- 该模块至关重要,不同的正负样本分配策略会带来显著的性能差异,目前大部分目标检测算法都会对这个部分进行改进。
- 支持的BBox Assigner
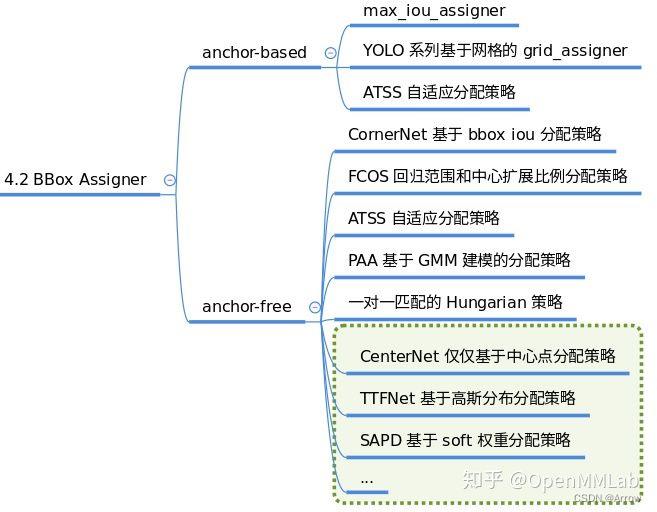
1.1.6 BBox Sampler
- 功能:
- 在确定每个样本的正负属性后,可能还需要进行样本平衡操作。
- 本模块作用是对前面定义的正负样本不平衡进行采样,力争克服该问题。
- 一般在目标检测中 gt bbox 都是非常少的,所以正负样本比是远远小于 1 的。
- 而基于机器学习观点:在数据极度不平衡情况下进行分类会出现预测倾向于样本多的类别,出现过拟合,为了克服该问题,适当的正负样本采样策略是非常必要的,一些典型采样策略如下:
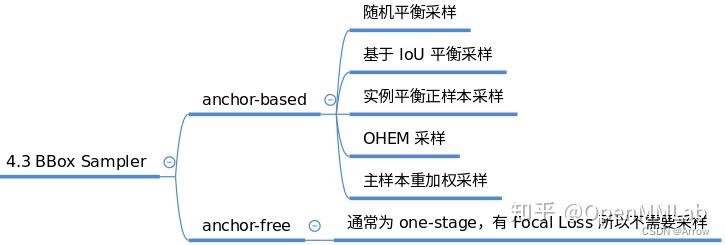
1.1.7 BBox Encoder
- 功能:
- 为了更好的收敛和平衡多个 loss,具体解决办法非常多,而 bbox 编解码策略也算其中一个,bbox 编码阶段对应的是对正样本的 gt bbox 采用某种编码变换(反操作就是 bbox 解码)
- 最简单的编码是对 gt bbox 除以图片宽高进行归一化以平衡分类和回归分支,一些典型的编解码策略如下:
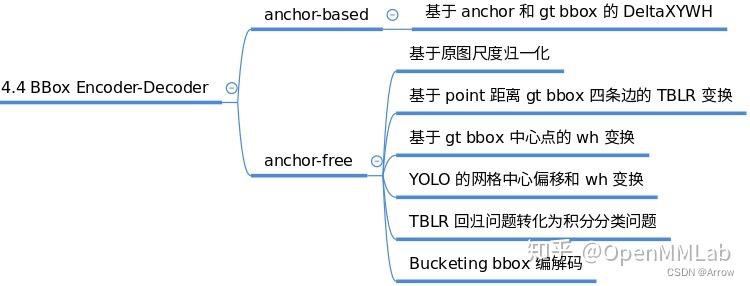
1.1.8 Loss
- 功能:
- Loss 通常都分为分类和回归 loss,其对网络 head 输出的预测值和 bbox encoder 得到的 targets 进行梯度下降迭代训练。
- loss 的设计也是各大算法重点改进对象,常用的 loss 如下:

1.1.9 Training tricks
- 训练技巧非常多,常说的调参很大一部分工作都是在设置这部分超参。这部分内容比较杂乱,很难做到完全统一,目前主流的 tricks 如下所示:
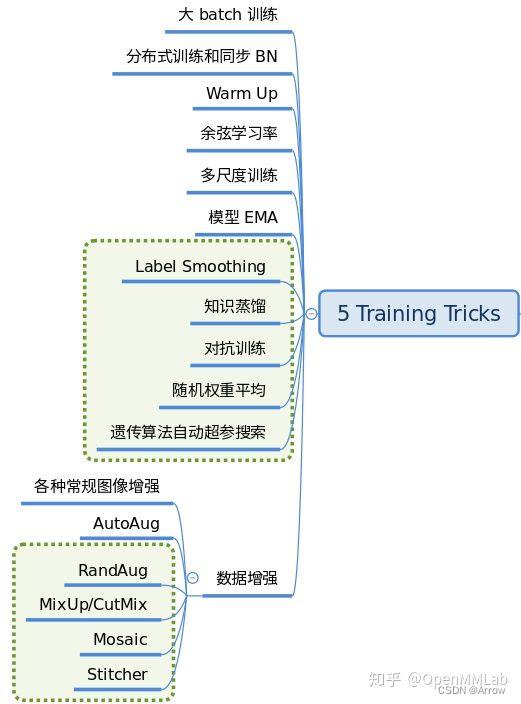
2 整体抽象
2.1 流程抽象
- 整体训练和测试抽象流程图:
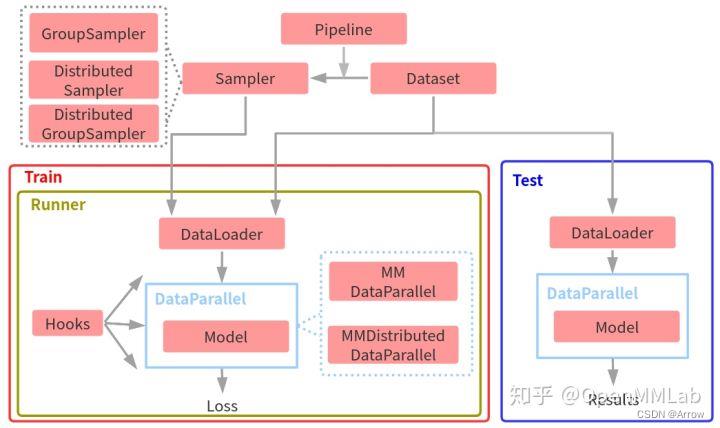
2.1.1 Pipeline
- Pipeline 实际上由一系列按照插入顺序运行的数据处理模块组成,每个模块完成某个特定功能,例如 Resize,因为其流式顺序运行特性,故叫做 Pipeline。
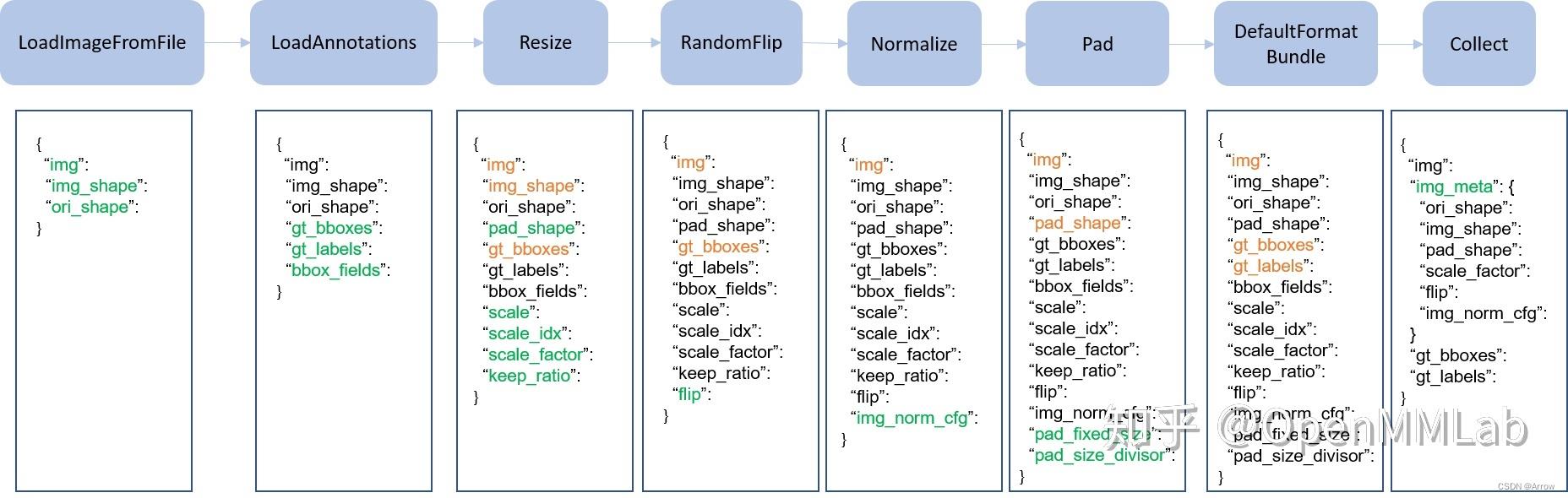
- 上图是一个非常典型的训练流程 Pipeline,每个类都接收字典输入,输出也是字典,顺序执行,其中绿色表示该类运行后新增字段,橙色表示对该字段可能会进行修改。如果进一步细分的话,不同算法的 Pipeline 都可以划分为如下部分:
- 图片和标签加载,通常用的类是 LoadImageFromFile 和 LoadAnnotations
- 数据前处理,例如统一 Resize
- 数据增强,典型的例如各种图片几何变换等,这部分是训练流程特有,测试阶段一般不采用(多尺度测试采用其他实现方式)
- 数据收集,例如 Collect
2.2.2 DataParallel
- 在 MMDetection 中 DataLoader 输出的内容不是 pytorch 能处理的标准格式,还包括了 DataContainer 对象,该对象的作用是包装不同类型的对象使之能按需组成 batch。
- 在目标检测中,每张图片 gt bbox 个数是不一样的,如果想组成 batch tensor,要么你设置最大长度,要么你自己想办法组成 batch。而考虑到内存和效率,MMDetection 通过引入 DataContainer 模块来解决上述问题,但是随之带来的问题是 pytorch 无法解析 DataContainer 对象,故需要在 MMDetection 中自行处理。
- MMDetection 选择了一种比较优雅的实现方式:MMDataParallel 和 MMDistributedDataParallel。具体来说,这两个类相比 PyTorch 自带的 DataParallel 和 DistributedDataParallel 区别是:
- 可以处理 DataContainer 对象
- 额外实现了 train_step() 和 val_step() 两个函数,可以被 Runner 调用
2.2.3 Runner和Hooks
- 对于任何一个目标检测算法,都需要包括优化器、学习率设置、权重保存等等组件才能构成完整训练流程,而这些组件是通用的。为了方便 OpenMMLab 体系下的所有框架复用,在 MMCV 框架中引入了 Runner 类来统一管理训练和验证流程,并且通过 Hooks 机制以一种非常灵活、解耦的方式来实现丰富扩展功能。
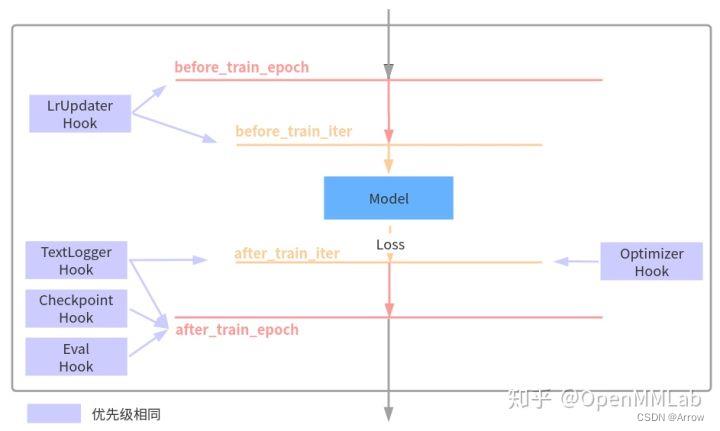
- Runner 封装了 OpenMMLab 体系下各个框架的训练和验证详细流程,其负责管理训练和验证过程中的整个生命周期,通过预定义回调函数,用户可以插入定制化 Hook ,从而实现各种各样的需求。下面列出了在 MMDetection 几个非常重要的 hook 以及其作用的生命周期:
2.2 代码抽象
2.2.1 训练和测试整体代码抽象流程

- 训练代码
#=================== mmdet/apis/train.py ==================
# 1.初始化 data_loaders ,内部会初始化 GroupSampler
data_loader = DataLoader(dataset,...)
# 2.基于是否使用分布式训练,初始化对应的 DataParallel
if distributed:
model = MMDistributedDataParallel(...)
else:
model = MMDataParallel(...)
# 3.初始化 runner
runner = EpochBasedRunner(...)
# 4.注册必备 hook
runner.register_training_hooks(cfg.lr_config, optimizer_config,
cfg.checkpoint_config, cfg.log_config,
cfg.get('momentum_config', None))
# 5.如果需要 val,则还需要注册 EvalHook
runner.register_hook(eval_hook(val_dataloader, **eval_cfg))
# 6.注册用户自定义 hook
runner.register_hook(hook, priority=priority)
# 7.权重恢复和加载
if cfg.resume_from:
runner.resume(cfg.resume_from)
elif cfg.load_from:
runner.load_checkpoint(cfg.load_from)
# 8.运行,开始训练
runner.run(data_loaders, cfg.workflow, cfg.total_epochs)
2.2.2 Runner 训练和验证代码抽象
- runner 对象内部的 run 方式是一个通用方法,可以运行任何 workflow,目前常用的主要是 train 和 val。
- 当配置为:workflow = [(‘train’, 1)],表示仅仅进行 train workflow,也就是迭代训练
- 当配置为:workflow = [(‘train’, n),(‘val’, 1)],表示先进行 n 个 epoch 的训练,然后再进行1个 epoch 的验证,然后循环往复,如果写成 [(‘val’, 1),(‘train’, n)] 表示先进行验证,然后才开始训练
- 当进入对应的 workflow,则会调用 runner 里面的 train() 或者 val(),表示进行一次 epoch 迭代。其代码也非常简单,如下所示:
def train(self, data_loader, **kwargs):
self.model.train()
self.mode = 'train'
self.data_loader = data_loader
self.call_hook('before_train_epoch')
for i, data_batch in enumerate(self.data_loader):
self.call_hook('before_train_iter')
self.run_iter(data_batch, train_mode=True)
self.call_hook('after_train_iter')
self.call_hook('after_train_epoch')
def val(self, data_loader, **kwargs):
self.model.eval()
self.mode = 'val'
self.data_loader = data_loader
self.call_hook('before_val_epoch')
for i, data_batch in enumerate(self.data_loader):
self.call_hook('before_val_iter')
with torch.no_grad():
self.run_iter(data_batch, train_mode=False)
self.call_hook('after_val_iter')
self.call_hook('after_val_epoch') # will call all the registered hooks
- 核心函数实际上是 self.run_iter(),如下:
def run_iter(self, data_batch, train_mode, **kwargs):
if train_mode:
# 对于每次迭代,最终是调用如下函数
outputs = self.model.train_step(data_batch,...)
else:
# 对于每次迭代,最终是调用如下函数
outputs = self.model.val_step(data_batch,...)
if 'log_vars' in outputs:
self.log_buffer.update(outputs['log_vars'],...)
self.outputs = outputs
- 上述 self.call_hook() 表示在不同生命周期调用所有已经注册进去的 hook,而字符串参数表示对应的生命周期。以 OptimizerHook 为例,其执行反向传播、梯度裁剪和参数更新等核心训练功能:
@HOOKS.register_module()
class OptimizerHook(Hook):
def __init__(self, grad_clip=None):
self.grad_clip = grad_clip
def after_train_iter(self, runner):
runner.optimizer.zero_grad()
runner.outputs['loss'].backward()
if self.grad_clip is not None:
grad_norm = self.clip_grads(runner.model.parameters())
runner.optimizer.step()
- 可以发现 OptimizerHook 注册到的生命周期是 after_train_iter,故在每次 train() 里面运行到 self.call_hook(‘after_train_iter’) 时候就会被调用,其他 hook 也是同样运行逻辑。
2.2.3 Model 训练和测试代码抽象
- 训练和验证的时候实际上调用了 model 内部的 train_step 和 val_step 函数,理解了两个函数调用流程就理解了 MMDetection 训练和测试流程。
- 由于 model 对象会被 DataParallel 类包裹,故实际上上此时的 model,是指的 MMDataParallel 或者 MMDistributedDataParallel。以非分布式 train_step 流程为例,其内部完成调用流程图示如下:
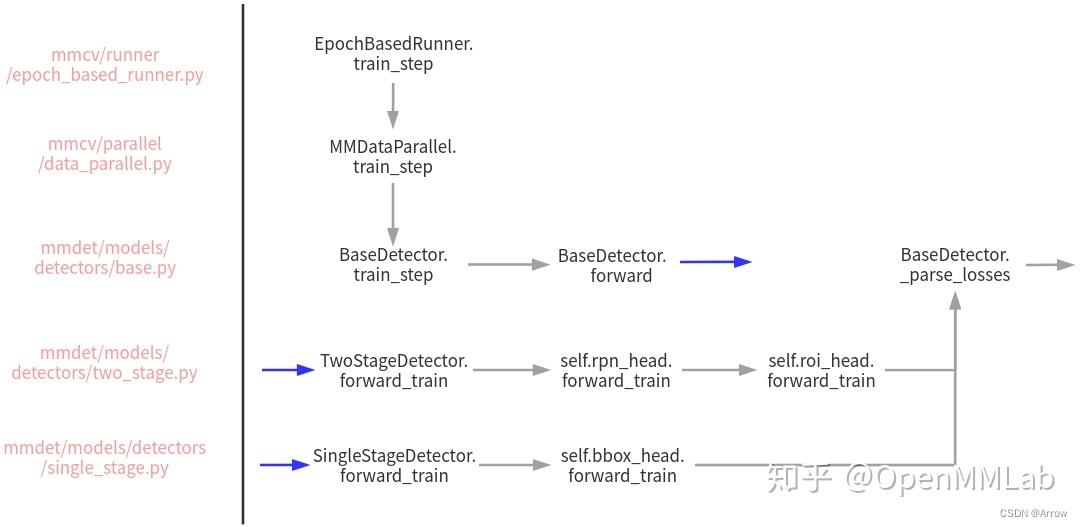
- 调用 model 中的 train_step
#=================== mmdet/models/detectors/base.py/BaseDetector ==================
def train_step(self, data, optimizer):
# 调用本类自身的 forward 方法
losses = self(**data)
# 解析 loss
loss, log_vars = self._parse_losses(losses)
# 返回字典对象
outputs = dict(
loss=loss, log_vars=log_vars, num_samples=len(data['img_metas']))
return outputs
def forward(self, img, img_metas, return_loss=True, **kwargs):
if return_loss:
# 训练模式
return self.forward_train(img, img_metas, **kwargs) # 在各种算法子类中实现
else:
# 测试模式
return self.forward_test(img, img_metas, **kwargs) # 在各种算法子类中实现
- forward_train 和 forward_test 需要在不同的算法子类中实现,输出是 Loss 或者 预测结果。
- 目前提供了两个具体子类,TwoStageDetector 和 SingleStageDetector ,用于实现 two-stage 和 single-stage 算法。
- 对于 TwoStageDetector 而言,其核心逻辑是:
#============= mmdet/models/detectors/two_stage.py/TwoStageDetector ============
def forward_train(...):
# 先进行 backbone+neck 的特征提取
x = self.extract_feat(img)
losses = dict()
# RPN forward and loss
if self.with_rpn:
# 训练 RPN
proposal_cfg = self.train_cfg.get('rpn_proposal',
self.test_cfg.rpn)
# 主要是调用 rpn_head 内部的 forward_train 方法
rpn_losses, proposal_list = self.rpn_head.forward_train(x,...)
losses.update(rpn_losses)
else:
proposal_list = proposals
# 第二阶段,主要是调用 roi_head 内部的 forward_train 方法
roi_losses = self.roi_head.forward_train(x, ...)
losses.update(roi_losses)
return losses
- 对于 SingleStageDetector 而言,其核心逻辑是:
#============= mmdet/models/detectors/single_stage.py/SingleStageDetector ============
def forward_train(...):
super(SingleStageDetector, self).forward_train(img, img_metas)
# 先进行 backbone+neck 的特征提取
x = self.extract_feat(img)
# 主要是调用 bbox_head 内部的 forward_train 方法
losses = self.bbox_head.forward_train(x, ...)
return losses
2.2.4 测试流程
- 由于没有 runner 对象,测试流程简单很多,下面简要概述:
- 调用 MMDataParallel 或 MMDistributedDataParallel 中的 forward 方法
- 调用 base.py 中的 forward 方法
- 调用 base.py 中的 self.forward_test 方法
- 如果是单尺度测试,则会调用 TwoStageDetector 或 SingleStageDetector 中的 simple_test 方法,如果是多尺度测试,则调用 aug_test 方法
- 最终调用的是每个具体算法 Head 模块的 simple_test 或者 aug_test 方法
3. Head 流程
3.1 Head 模块整体概述
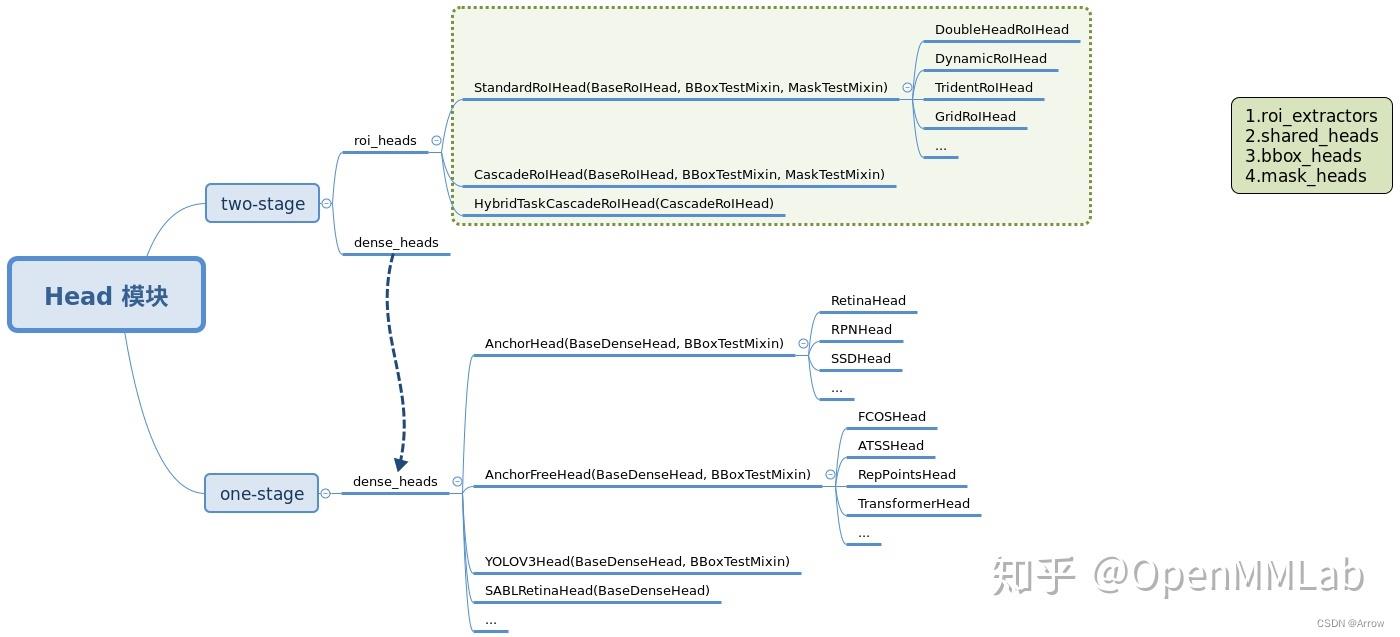 - 目前 MMDetection 中 Head 模块主要是按照 stage 来划分,主要包括两个 package: dense_heads 和 roi_heads , 分别对应 two-stage 算法中的第一和第二个 stage 模块,如果是 one-stage 算法则仅仅有 dense_heads 而已。
- 目前 MMDetection 中 Head 模块主要是按照 stage 来划分,主要包括两个 package: dense_heads 和 roi_heads , 分别对应 two-stage 算法中的第一和第二个 stage 模块,如果是 one-stage 算法则仅仅有 dense_heads 而已。
3.1.1 Anchor-based与Anchor-free的本质区别 (分类方法)
3.1.1.1 本质区别 (分类方法 IoU v.s. SSC)
- Anchor-based和Anchor-free方法的本质区别:如何定义正负训练样本, 参考论文《Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection》
- IoU: Intersection over Union
- SSC:Spatial and Scale Constraint
3.1.1.2 Anchor-based
- 代表算法:Faster R-CNN、SSD、RetinaNet、YoloV2/V3等
- 方法分类:
- two-stage:
- Faster R-CNN:由一个单独的区域建议网络(RPN: region proposal network)和一个区域预测网络(R-CNN: region proposal network)组成
- one-stage:2
- SSD:single shot multibox detector
- two-stage:
- Anchor是什么?
- 就是事先通过手工或聚类方法设定好的具有不同尺寸、宽高比的方框。这些方框覆盖了整张图像,目的是为了防止漏检。
- 在模型训练过程中,根据anchor与ground truth的IoU(交并比)损失对anchor的长宽以及位置进行回归,使其越来越接近ground truth,在回归的同时预测anchor的类别,最终输出这些回归分类好的anchors。
- two-stage方法要筛选和优化的anchors数量要远超one-stage方法,筛选步骤较为严谨,所以耗费时间要久一些,但是精度要高一些。在常用的检测基准上,SOTA的方法一般都是anchor-based的。
3.1.1.3 Anchor-free
- 代表算法:CornerNet、ExtremeNet、CenterNet、FCOS, YoloV1等
- 方法分类:
- keypoint-based
- center-based
3.1.1.4 本质区别分析
- 区别1:分类子任务,即定义(或选取)正负样本的方法
- 区别2:回归子任务,即从锚定箱(anchor box)或锚定点(anchor point)开始的回归
3.1.1.4.1 分类子任务 (确定正负样本)
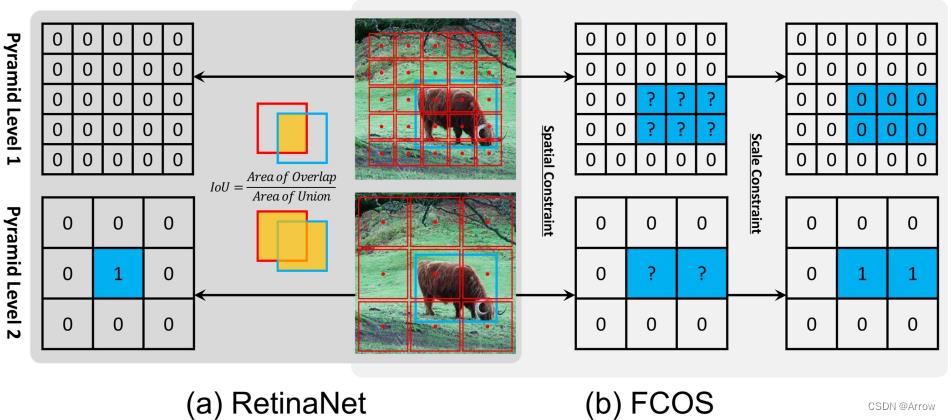
- 上图中1为正,0为负
- 蓝色框: 真实值( ground-truth)
- 红色框:anchor box (锚框)
- 红色点:anchor point (锚点)
- RetinaNet:使用IoU同时在spatial and scale dimension选择正样本(1)
- 选择与groundTruth的IoU>=0.5(positive threshold)的初设anchor为正样本1,IOU<(negative threshold)的为负样本0,其他忽略,其中的两个threshold都是我们人为拟定的,对训练样本中所有的检测目标都适用,如图(a)所示。
- IoU来定义正负样本的方式会导致小尺寸物体的正样本数量相对大尺寸物体正样本数量偏少,进而对小样本检测性能不高。
- 模型对这种人为拟定的超参(positive/negative threshold)敏感。
- FCOS:首先在spatial dimension发现候选正样本(?),然后在scale dimension选择最后的正样本(1)
- FCOS没有默认anchor box,而是默认anchor point,如图(b)所示。
- FCOS有两步骤,首先是Spatial Constraint,如果默认point在目标内即预设为?,在目标外预设为0;然后是Scale Constarint(这部分细节这就不提了,可在FCOS论文中找到),大意是如果在这层feature map里需要regress的值 minumun value<(regress value)<maxinum value则设置该点为正样本,如果超出maximun value或小于minumun value则为负样本。
- 这一步是为了让不同层的(FPN中)feature map来处理不同大小的目标的regress。大的feature map处理小样本,小的feature map处理大样本。这也是FCOS能比Retina获得更多正样本的原因。
3.1.1.4.2 回归子任务 (回归目标的位置)
- 在分类任务中,正负样本已经确定,在本任务中,从正样本处回归目标的位置
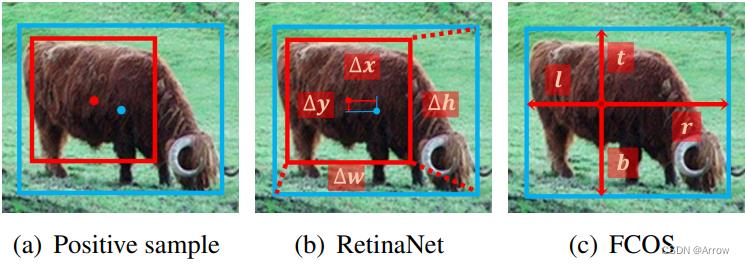
- 蓝色点: 目标的中心,真实值( ground-truth)
- 蓝色框: 目标的边界,真实值( ground-truth)
- 红色框:anchor box的边界
- 红色点:anchor box的中心(anchor point)
- RetinaNet回归:从anchor box回归,输出anchor box与object box间的四个偏移量 (offsets: Δ x , Δ y , Δ w , Δ h \\Delta x, \\Delta y, \\Delta w, \\Delta h Δx,Δy,Δw,Δh)
- FCOS回归:从anchor point 回归,输出anchor point到object边界框的四个距离值 (distances: l e f t , r i g h t , t o p , b o t t o m left, right, top, bottom left,right,top,bottom)
3.1.1.4.3 RetinaNet与FCOS的分类回归比较
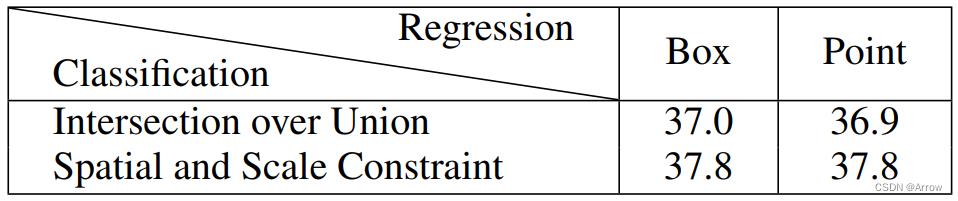
- RetinaNet:分类采用Intersection over Union(IoU),回归采用Bounding Box (BOX)
- FCOS:分类采用Spatial and scale Constraint,回归采用Point方式收敛
- 比较目的:由于分类和回归方式都不同,上表想证明到底是分类方式还是回归方式导致检测模型的性能不同。
- 分类方法相同:Table中显示当分类方式一样(横向对比),比如,IoU时,使用Box回归(mAP:37.0)与使用Point回归(mAP:36.9)时性能差别不大;同时,分类使用Spatial and Scale Constraint时,使用Box回归(mAP:37.8)与使用Point回归(mAP:37.8)时性能也差别不大。
- 回归方法相同:Table中显示当回归方式一样(纵向对比),比如,Box时,使用IoU分类(mAP:37.0)比使用Spatial and Scale Constraint分类(mAP:37.8)时性能低;同时,回归使用Point时,使用IoU分类(mAP:36.9)比使用Spatial and Scale Constraint分类(mAP:37.8)性能低。
- 结论: 由于模型的性能差异与Classification的方式有关(相关性大),与选择使用box或者Point来进行回归无关(相关性不大)。
3.1.2 dense_heads
- dense_heads 部分主要是按照 anchor-based 和 anchor-free 来划分,对应的类是 AnchorHead 和 AnchorFreeHead, 这两个类主要区别是 AnchorHead 会额外需要 anchor_generator 配置,用于生成默认 anchor。
- 同时可以看到有些类并没有直接继承这两个基类,例如 YOLOV3Head。原因是在该类中大部分函数处理逻辑都需要复写,为了简单就直接继承了 BaseDenseHead,而对于 SABLRetinaHead 而言,由于 SABL 是类似 anchor-based 和 anchor-free 混合的算法,故直接继承 BaseDenseHead 是最合适的做法。用户如果要进行扩展开发,可以依据开发便捷度自由选择最合适的基类进行继承。
3.1.3 roi_heads
- roi_heads 部分主要是按照第二阶段内部的 stage 个数来划分,经典的 Faster R-CNN 采用的是 StandardRoIHead,表示进行一次回归即可,而对于 Cascade R-CNN,其第二阶段内部也包括多个 stage 回归阶段,实现了 CascadeRoIHead,即可以构建任意次数的分类回归结果。
3.1.4 Head内部模块
- RoI 特征提取器 roi_extractor (必备)
- 共享模块 shared_heads
- bbox 分类回归模块 bbox_heads (必备)
- mask 预测模块 mask_heads
3.2 Head 模块构建流程
3.2.1 训练和测试中的Header函数
- 训练流程,two-stage Head核心函数:
- self.rpn_head.forward_train
- self.roi_head.forward_train
- 训练流程,one-stage Head核心函数:
- self.bbox_head.forward_train
- 测试流程:
- 单尺度:调用了 Head 模块自身的 simple_test方法
- 多尺度:调用了 Head 模块自身的 aug_test 方法
3.2.2 dense_heads 模块训练和测试流程
3.2.2.1 训练流程
- dense_heads 训练流程最外层函数是 forward_train, 其实现是在 mmdet/models/dense_heads/base_dense_head.py/BaseDenseHead 中,如下所示:
def forward_train(self,
x,
img_metas,
gt_bboxes,
gt_labels=None,
gt_bboxes_ignore=None,
proposal_cfg=None,
**kwargs):
# 调用各个子类实现的 forward 方法
outs = self(x)
if gt_labels is None:
loss_inputs = outs + (gt_bboxes, img_metas)
else:
loss_inputs = outs + (gt_bboxes, gt_labels, img_metas)
# 调用各个子类实现的 loss 计算方法
losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
if proposal_cfg is None:
return losses
else:
# two-stage 算法还需要返回 proposal
proposal_list = self.get_bboxes(*outs, img_metas, cfg=proposal_cfg)
return losses, proposal_list
- 每个算法的 Head 子类一般不会重写上述方法,但是每个 Head 子类都会重写 forward 和 loss 方法,其中 forward 方法用于运行 head 网络部分输出分类回归分支的特征图,而 loss 方法接收 forward 输出,并且结合 label 计算 loss
3.2.2.1.1 BaseDenseHead
- BaseDenseHead 基类过于简单,对于 anchor-based 和 anchor-free 算法又进一步进行了继承,得到 AnchorHead 或者 AnchorFreeHead 类。
- 在目前的各类算法实现中,绝大部分子类都是继承自 AnchorHead 或者 AnchorFreeHead,其提供了一些相关的默认操作,如果直接继承 BaseDenseHead 则子类需要重写大部分算法逻辑。
3.2.2.1.2 AnchorHead
- 主要是封装了 anchor 生成过程。下面对 forward 和 loss 函数进行分析:
# BBoxTestMixin 是多尺度测试时候调用
class AnchorHead(BaseDenseHead, BBoxTestMixin):
# feats 是 backbone+neck 输出的多个尺度图
def forward(self, feats):
# 对每张特征图单独计算预测输出
return multi_apply(self.forward_single, feats)
# head 模块分类回归分支输出
def forward_single(self, x):
cls_score = self.conv_cls(x