Java之Hadoop API序列化和反序列化
Posted pblh123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java之Hadoop API序列化和反序列化相关的知识,希望对你有一定的参考价值。
CSDN话题挑战赛第2期
参赛话题:大数据学习成长记录
学习目标:
- 熟悉Java开发
- 掌握Java序列化和反序列化
- Hadoop的mapreduce序列化
软件版本信息
| 工具名称 | 说明 |
|---|---|
| VMware-workstation-full-15.5.1-15018445.exe | 虚拟机安装包 |
| MobaXterm_Portable_v20.3.zip | 解压使用,远程连接Centos系统远程访问使用,支持登录和上传文件 |
| CentOS-7-x86_64-DVD-1511.iso | Centos7系统ISO镜像,不需要解压,VMware安装时需要 |
| jdk-8u171-linuxx64.tar.gz | jdk安装包,上传到Centos系统中使用 |
| hadoop-2.7.3.tar.gz | hadoop的安装包,需要上传到虚拟机中 |
前言/背景
Hadoop学习时,数据的传输通常使用序列化的格式,序列化后的数据传输在网络上更便利,存储上能解压更多空间,其次,在进程间传输时,序列化的字节流更便利。
IDEA-community开发Java
掌握通过IDEA开发Java程序
1,创建新的Maven项目
根据提示完成项目创建

2,配置pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.com.lh</groupId>
<artifactId>GUNBigdata</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<!-- 项目依赖 -->
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.7.3</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>true</minimizeJar>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
3,HadoopPerson类编写
package hdfs;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* @Classname HadoopPerson
* @Description TODO
* @Date 2022/9/7 21:50
* @Created by Tiger_Li
*/public class HadoopPerson implements Writable
private IntWritable id;
private Text name;
private IntWritable age;
private Text phone;
/**
* 无参构造函数
* 必须对属性进行初始化,否则在反序列化时会报出属性为null的错误
*/
public HadoopPerson()
this.id = new IntWritable(0);
this.name = new Text("");
this.age = new IntWritable(0);
this.phone = new Text("");
// 有参的构造函数
public HadoopPerson(int id, String name, int age, String phone)
this.id = new IntWritable(id);
this.name = new Text(name);
this.age = new IntWritable(age);
this.phone = new Text(phone);
// 序列化:将当前对象的属性写入到输出流中
public void write(DataOutput out) throws IOException
this.id.write(out);
this.name.write(out);
this.age.write(out);
this.phone.write(out);
// 反序列化:读取输入流中的数据给当前的对象赋值
public void readFields(DataInput in) throws IOException
this.id.readFields(in);
this.name.readFields(in);
this.age.readFields(in);
this.phone.readFields(in);
@Override
public String toString()
return "HadoopPerson" +
"id=" + id +
", name=" + name +
", age=" + age +
", phone=" + phone +
'';
public IntWritable getAge()
return age;
public void setAge(IntWritable age)
this.age = age;
public Text getName()
return name;
public void setName(Text name)
this.name = name;
public IntWritable getId()
return id;
public void setId(IntWritable id)
this.id = id;
public Text getPhone()
return phone;
public void setPhone(Text phone)
this.phone = phone;
注意:有参构建函数、与无参构造函数的区别
4,本地文件系统中,序列化与反序列化测试类 TestSeriMain
package hdfs;
import java.io.*;
/**
* @Classname TestSeriMain
* @Description 本地文件系统中,序列化与反序列化测试类
* @Date 2022/9/7 16:35
* @Created by Tiger_Li
*/public class TestSeriMain
public static void main(String[] args) throws IOException
ser();
deSer();
//序列化:将HadoopPerson对象写入到本地文件中
public static void ser() throws IOException
// 1. 创建本地File对象,用于存储HadoopPerson对象
File file = new File("D:\\\\pblh123\\\\2022\\\\part-r-00001");
// 2. 创建文件输出流对象,用于接收DataOutputStream的字节流,并将其写入到文件中
FileOutputStream outputstr = new FileOutputStream(file);
// 3. 创建DataOutputStream对象,用于接收HadoopPerson序列化后的字节流,并传递给FileOutputStream
DataOutputStream dataoutputstr = new DataOutputStream(outputstr);
// 4. 利用有参结构函数创建hadoopPerson对象
HadoopPerson aperson = new HadoopPerson(500,"李先生", 31,"15210369999");
// 5. 调用person对象的write方法实现将其序列化后的字节流写入dataOutputStream对象中
aperson.write(dataoutputstr);
// 6. 关闭数据流
dataoutputstr.close();
// 7. 打印提升信息
System.out.println("一条信息序列化成功~");
//反序列化:读取本地文件person.txt中的字节流序列将其转成HadoopPerson对象
public static void deSer() throws IOException
// 1. 指定本地File对象
File file = new File("D:\\\\pblh123\\\\2022\\\\part-r-00001");
// 2. 创建文件输入流对象,用于读取文件内容
FileInputStream inputstr = new FileInputStream(file);
// 3. 创建DataInputStream对象,接收本地文件的字节流,并传输给HadoopPerson对象进行赋值
DataInputStream datainputstr = new DataInputStream(inputstr);
// 4. 利用无惨构建函数创建HadoopPerson对象,调用readFields方法将内容赋值给自己
HadoopPerson person = new HadoopPerson();
person.readFields(datainputstr);
// 5. 关闭数据流
datainputstr.close();
inputstr.close();
// 6. 打印提示信息
System.out.println("反序列化成功:" + person);
5,HadoopPersonMapper Map阶段序列化代码开发
package hdfs;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @Classname hdfsserdeser
* @Description MapReduce中的Mapper来实现Hadoop序列化测试
* @Date 2022/9/7 21:46
* @Created by Tiger_Li
*/public class HadoopPersonMapper extends Mapper<LongWritable, Text, IntWritable,HadoopPerson>
/**
* 通过编写MapReduce中的Mapper来实现Hadoop序列化测试
* 思路:
* 1、创建实现类,实现Writable接口
* 2、在实现类中定义成员变量(成员变量的类型都是Hadoop的数据类型)
* 3、设置get/set方法、无参构造方法、有参构造方法、重写write和readFields方法
* 4、重写toString方法
* 5、编写HadoopPersonMapper类,继承Mapper类(区别在这里)
* 6、编写Driver类,设置Mapper及其输入输出(区别在这里)
*/
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, IntWritable, HadoopPerson>.Context context) throws IOException, InterruptedException
String string = value.toString();
String[] split = string.split(",");
HadoopPerson person = new HadoopPerson(Integer.parseInt(split[0]),split[1],Integer.parseInt(split[2]),split[3]);
context.write(person.getId(),person);
6,HadoopPersonMDriver MapReduce代码开发
package hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @Classname HadoopPersonMDriver
* @Description Drive类
* @Date 2022/9/7 23:12
* @Created by Tiger_Li
*/public class HadoopPersonMDriver
public static void main(String[] args) throws Exception
Job job = Job.getInstance(new Configuration());
job.setMapperClass(hdfs.HadoopPersonMapper.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(HadoopPerson.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(HadoopPerson.class);
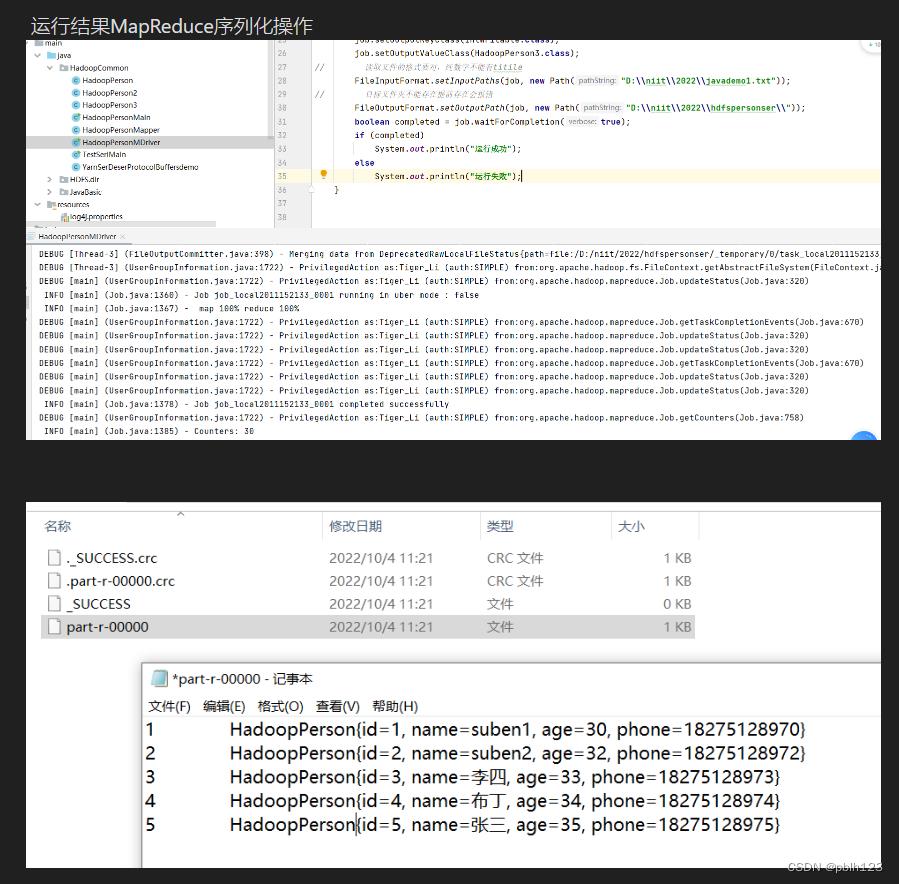
// 读取文件的格式要对,纯数字不能有titile
FileInputFormat.setInputPaths(job, new Path("D:\\\\pblh123\\\\2022\\\\javademo1.txt"));
// 目标文件夹不能存在提前存在会报错
FileOutputFormat.setOutputPath(job, new Path("D:\\\\pblh123\\\\2022\\\\hdfspersonser"));
boolean completed = job.waitForCompletion(true);
if (completed)
System.out.println("文件序列化运行成功");
else
System.out.println("文件序列化运行失败");
javademo1.txt内容如下
1,suben1,30,18275128970
2,suben2,32,18275128972
3,李四,33,18275128973
4,布丁,34,18275128974
5,张三,35,18275128975
个人经验总结
注意理解序列化与反序列化,注意MapReduce中序列化操作与Java本地的序列化操作差别。
以上是关于Java之Hadoop API序列化和反序列化的主要内容,如果未能解决你的问题,请参考以下文章