基于优化LSTM 模型的股票预测
Posted 彭祥.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于优化LSTM 模型的股票预测相关的知识,希望对你有一定的参考价值。
LSTM自诞生以来,便以其在处理时间序列方面的优越性能在预测回归,语音翻译等领域广受青睐。今天,主要研究的是通过对LSTM模型的优化来实现股票预测。其实,关于股票预测,LSTM模型已经表现的相当成熟,然而,其以及具有很大的提升空间,比如,股市的影响因素多种多样,这篇论文的重点,便是从若干个影响因素中,挑选出占比最大的几个特征,从而能够达到减少模型运算消耗的目的,下面,便是论文的相关介绍。
理论基础
由于神经网络预测模型具有显著的非线性,我们把神经网络模型归为非线性预测模型。神经网络分为两大类。第一类 人 工 神 经 网 络 (ANN),如 MP 神 经 网 络 和BP神经网络。ANN 作为早期的神经网络模型,在 股 票 预 测方面亦做出了杰出贡献:Deng提出 DAE-BP模 型 对 股 票 先进行 DAE降维,再 使 用 BP神 经 网 络 进 行 股 价 预 测,取 得 了不错的预测结果。可 惜 的 是,ANN 模 型 结 构 过 于 单 一,存 在以下问题:
1)过拟合,导致模型的泛化能力大大减弱;
2)存在局部极值问题,即梯度下降过程中达到局部极小值点就停止工作,不能精准下降至全局极小值点,导致模型预测能力大大减弱;
3)优化过程中容易因为神经元权重过多、过 繁,导 致 梯度消失或者梯 度 爆 炸 问 题,最终使神经网络模型预测失效。
第二类神经网络则是相对于 ANN 来说,更深层次、更 高 效 的深度神经网络模型(DNN),如卷积神经网络(CNN)、循 环 神经网络(RNN)和长短期记忆神经网络(LSTM)。这一类神经网络模型是当前研究金融预测领域最高效、前沿的预测模型,其具有多方面优势。
1)对输入变量的形式没有限制,与 预 测问题可能相关的信息均可被作为模型输入,这一点极大满足了股票市场容易被各式各样的信息所干扰影响的特征。
2)有效拟合输入变量间的非线性复杂关系,提高样本拟合程度,同时通过神经元权重循环使用原理,大大减少了神经元权重的数量,有效防止过拟合现象。
3)通过 DNN 中tanh激活函数,能够显著解决 ANN 中的梯度爆炸和梯度消失问题。
本文在股票价格影响因素选取中创新性地将消费者情绪和财务数据、基本面数据等多种数据融合,通过深度学习 LASSO 方法和 PCA 分析法对影响股票价格的多种因素进行降维筛选,使各输入数据之间的相关性最大化,再分别导入目前最前沿的 LSTM 神经网络模型[10-14]进行预测,并进行准确性和稳定性的对比,发现其中最高效的股票模型预测方法。
研究方法
LASSO
实证分析中,通常会设置尽可能多的自变量,选取自变量时容易出现偏主观意愿的疏漏,从而导致实证分析失真。而LASSO 方法是一个能够客观筛选有效变量并且解决多重共线性等问题的估计方法。它 是1997年 由 Tibshirani提 出 的一种压缩估计方法,通过构造一个惩罚函数,让回归系数的绝对值之和在小于一个常数的约束条件下,使得回归模型残差
平方和最小,产生严格等于零的回归系数,从而有效解决回归模型中的多重共线性问题。
LASSO 方法是在普通线性回归模型中增加L1惩罚项,普通线性模型的 LASSO 估计为:

PCA
主成分分析法是一种降维的统计方法,它 借 助 于 一 个 正交变换,将其分量相关的原随机向量转化成其分量不相关的新随机向量,这在代数上表现为将原随机向量的协方差阵变换成对角形阵,在几何上表现为将原坐标系变换成新的正交坐标系,使之指向样本点散布最开的 p 个 正 交 方 向;然 后 对
多维变量系统进行降维处理,使之能以一个较高的精度转换成低维变量系统,再通过构造适当的价值函数,进一步把低维系统转化成一维系统。


LSTM
长短时记忆神经网络 (LongShort-term Memory Net-works,LSTM)是一种特殊 的 RNN 类 型,可以学习长期依赖信息。RNN 神经网络模型一直被广泛用于语言识别和文本分类等多个研究领域[16]。相比于人工神经网络模型(ANN)而言,RNN 神经网络模型可以循环利用神经元的权重参数,能够很好地将历史数据相关 信息应用到预测中去。然 而,RNN 神经网络模型的误差反向传播算法只是像 ANN 神 经网络模型中一样简单,权重的重复利用能够带来好处,也会带来很大弊端,例如梯度爆炸和梯度消失问题,即对历史数据的长期依赖性问题无法有效解决。为解决这两大难题,机 器 学习科 研 工 作 者 们 研 究 出 长 短 时 记 忆神经网络模型(LSTM),如图1所示。
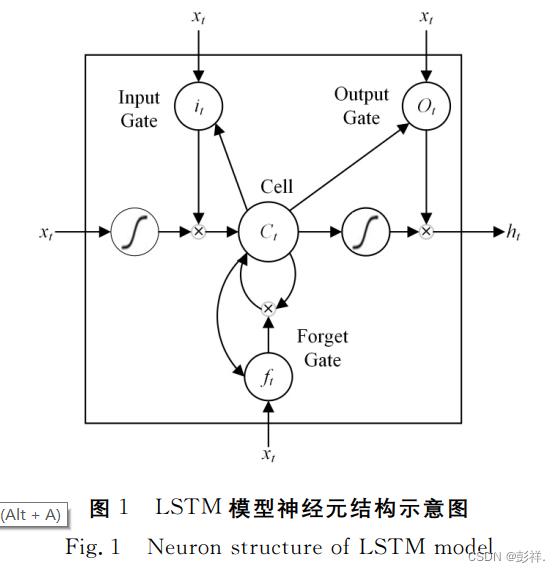
LSTM 模型相较于 RNN 模型最明显的改进是增加了1个细胞状态 C和3个阀门,3个阀门分别是遗忘门f、输 出 门o和输入门i。在 LSTM 模型误差反向传播校正权重时,有些误差可以直接通过输入门传递给下一层神经元,有些误差则可以通过遗忘门去进行数据遗忘,这样就解决了梯度爆炸与消失的难题,即有效地处理历史数据中相关信息的冗余等问题。本文研究的股票价格预测是典型的时序问题,且 某一个时刻的价格受前一时刻和历史多时刻价格影响,所以选择 LSTM 模型进行股票价格预测。
股票价格预测的实证分析
数据来源及指标选取
文章所采用的数据为2015年1月5日 至2020年2月7日的平安银行(0000001)股票数据(数据来源于通达信金融终端),共1240条数 据。其 中80%作为训练集用于训练模型,其余20%作为测试集中来验证模型的泛化能力。
在指标选取的过程中,应尽可能全方面地考虑影响因素,全方位地对问题进行分析,尤其对股票价格波动这种影响因素较多且各因素之间并不呈明显线性关系的难题,在指标选择过程中更应该精准筛选。相较于其他研究,实 验 选 用 股 价的开 盘 价、最 高 最 低 价、成交量以及一 般技术指标 OBV、
KDJ、BIAS等常见的 技 术 指 标,本文创新性地添加了最前沿的 CCI,MFI,MTM 等若干股价判断技术指标以及准确反映投资者心理情绪的 PSY 指 标。这些技术指标能够多方位地涵盖股价波动的潜在信息,具有很强的股价解释性。为 了 更清楚地对这57个技术指标进行理解,表1进行了详细说明。
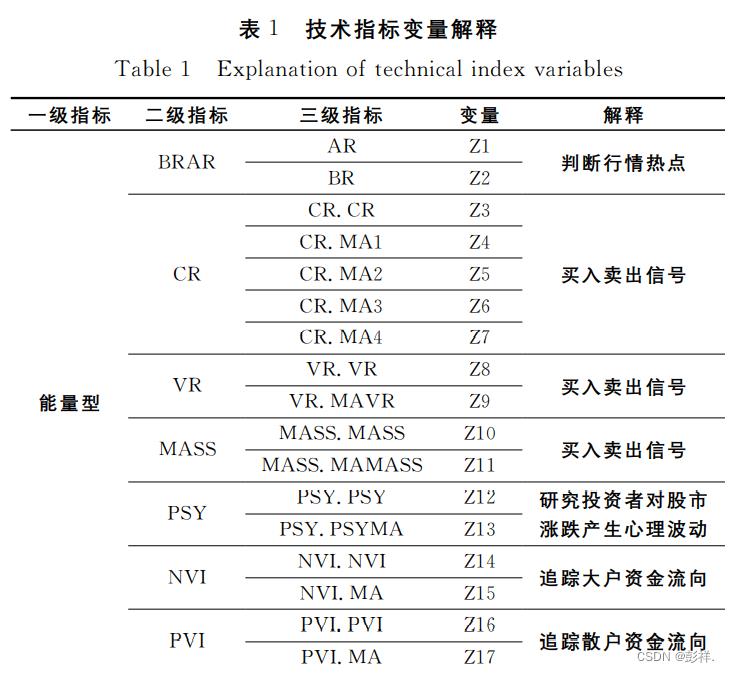
数据的筛选
表1所列5个一 级 指 标、28个 二 级 指 标 和 57个 三 级 指标描述了股价的波动影响因素。由于指标个数较多,为 了 不给网络运行带 来 负 担,提 高 LSTM 神经网络的预测能力,本文分别采用主成分分析法和 LASSO 回 归 法 对 57个 指 标 进行筛选。
主成分分析法
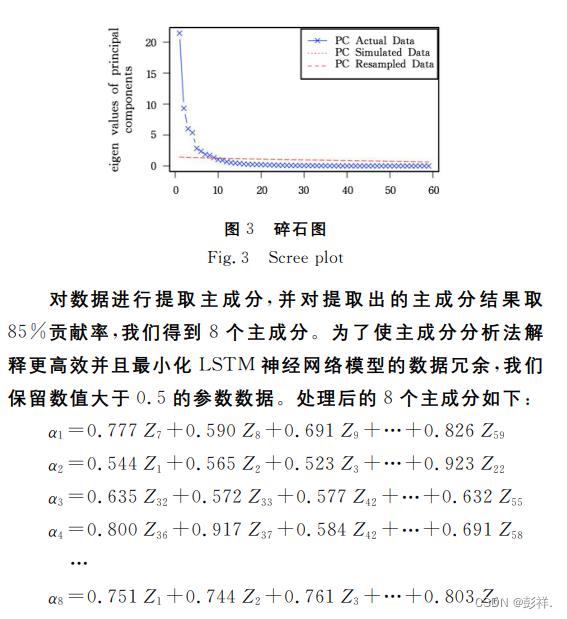
通过 RStudio软件对 平 安 银 行57个指标数据进行标准化处理,然后画出碎石图。由图3可知,特征值大于1的主成
分个数有9个。
预测方法及思路
为客观比 较 LASSO-LSTM 和 PCA-LSTM 之 间 的 预 测
效率,我们加入单纯 LSTM 模型的预测结果,进行三者对比。
LSTM 神经网络方法及预测思路
LSTM 神经网络用历史1240个交易日的数据信息对股票价格走势进 行 预 测。输入数据为未做数据筛选的所有57个参数变量,输出数据为历史股价下一日的收盘价预测值。
LASSO-LSTM 模型方法及预测思路
通过 LASSO 回归法构造惩罚函数,将历史1240个交易
日内的57个参数变量进行去共线性筛选,留 下 的50个 参 数
变量具有低共线性、高相关度等特征,再将其当作输入变量输
入 LSTM 神经网络模型中,输出变量是当日历史数据的下 一
日收盘价预测值。
PCA-LSTM 模型方法及预测思路
通过 PCA 分析法,从57个原始数据提取出8个 主 成 分用于 LSTM 模型输入,这8个主成分因子分别以不同的参数系数囊括了57个历史数据的信息,显著地精简了神经网络模型输入端,同时又不丢失重要数据信息。输 出 变 量 是 当 日 历史数据的下一日收盘价预测值。
实证结果对比
现有运用神经网络进行股票预测的研究实验较多是将历史数据全部放入训练集中进行模型训练,将最新一天的股价作为预测数 据。以该方式预测可以得出非常拟合的预测结果图,是因为神经网络模型独特的多次校正权重原理能够让神经网络模型最大程度地拟合出与历史股价重合的预测股价,但这在实际炒股应用中的失真率非常大,毫无实际应用价值。因此,本文采用历史股价80%的 数 据 即 前960日 的 历史股价作为训练集,剩 余20%的 数 据 即 第960日 至1240日的历史股价作为预测集。不 同 的 LSTM 模 型 超 参 数,对LSTM 模型的预测能力有着显著的影响,例 如 神 经 元 层 数 及每层神经元中的神经元个数的改变会使模型运算繁琐度指数增长且影响最后的预测精度,学习率的千分位改变会显著影响模型在梯度下降时的效率与准确率。
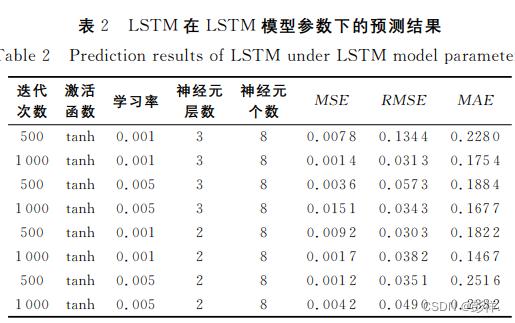
从表2单纯使用 LSTM 模型对股票的预测结果来看,在LSTM 模型设置迭代次数为500次、激活函数为tanh、学习率为0.005、神经层为3层、神经元为8个时,MSE 结果最小,为0.0012;在 设 置 迭 代 次 数 500 次、激 活 函 数 tanh、学 习 率0.001、神 经 层 2 层、神 经 元 8 个 时,RMSE 结 果 最 小,为0.0303;在 LSTM 模型设置迭代次数 1000 次、激 活 函 数tanh、学习率0.001、神经层3层、神经元8个时,MAE 结果最小,为0.1467。图4-图6分别为单纯 LSTM 模型下,3个误差值最小条件时的预测图。
以上是关于基于优化LSTM 模型的股票预测的主要内容,如果未能解决你的问题,请参考以下文章