Discrete VS Continuous Control
Posted Harris-H
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Discrete VS Continuous Control相关的知识,希望对你有一定的参考价值。
Discrete VS Continuous Control
1.连续动作离散化
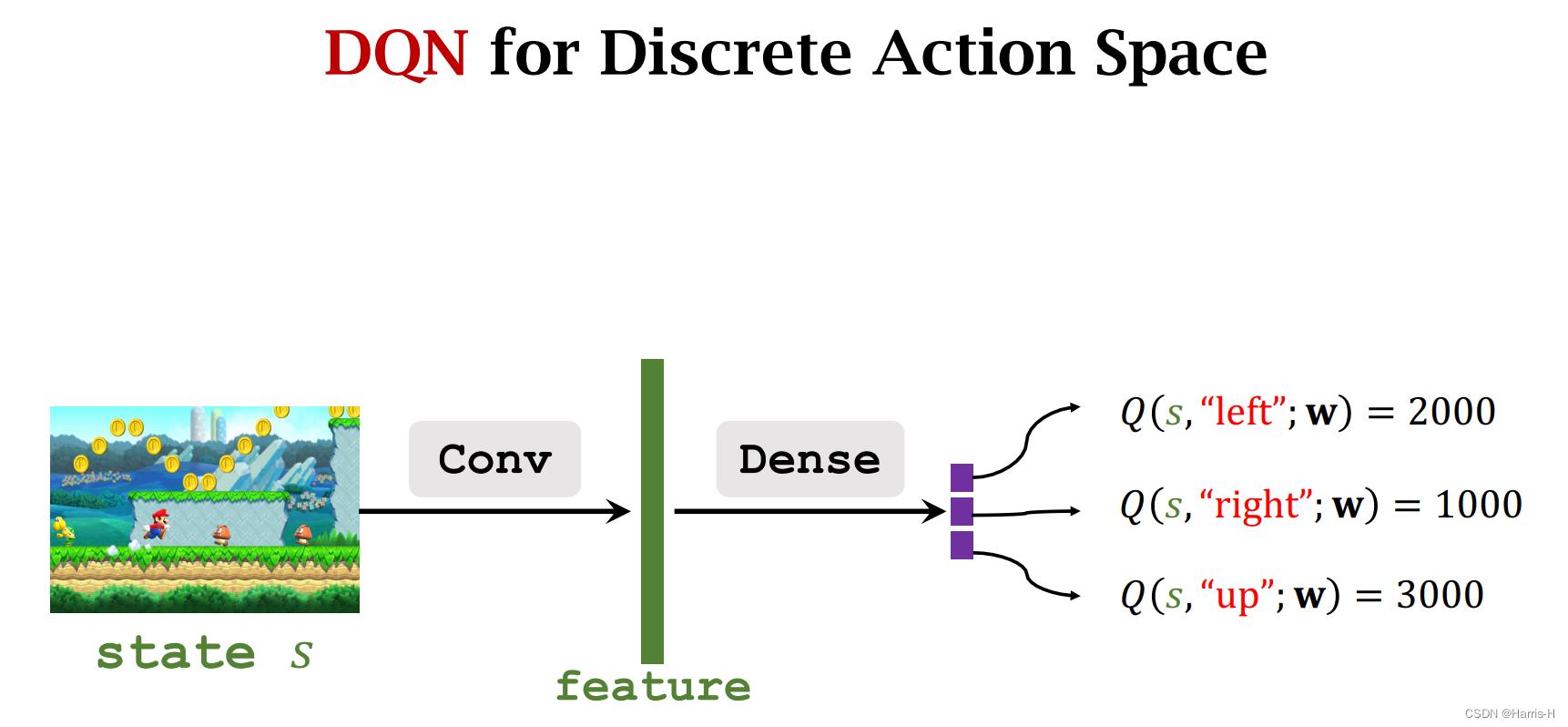
离散动作空间DQN,使用DQN近似 Q π Q_\\pi Qπ,输出每个动作对应的价值。
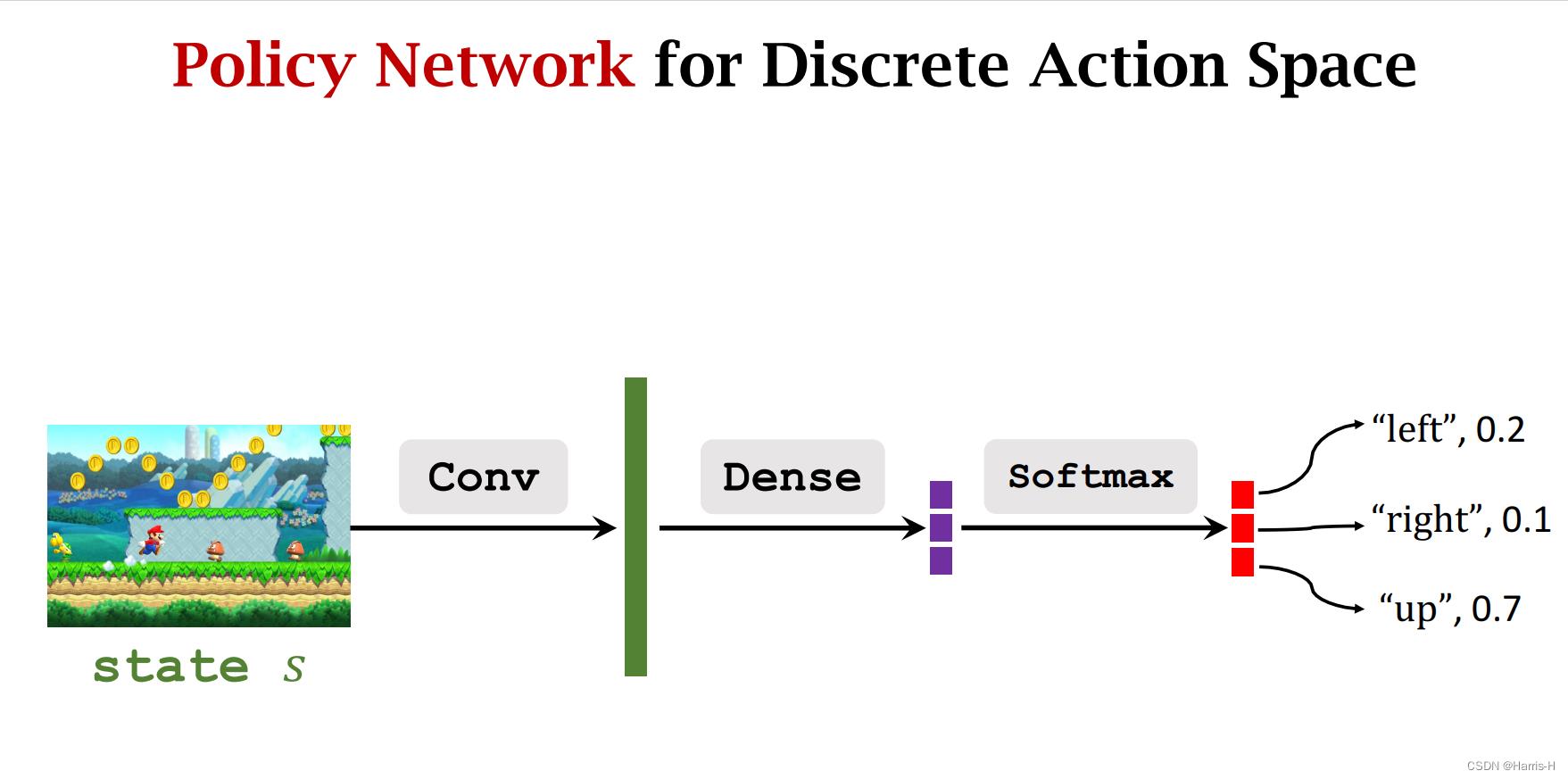
策略网络则输出动作的概率分布。
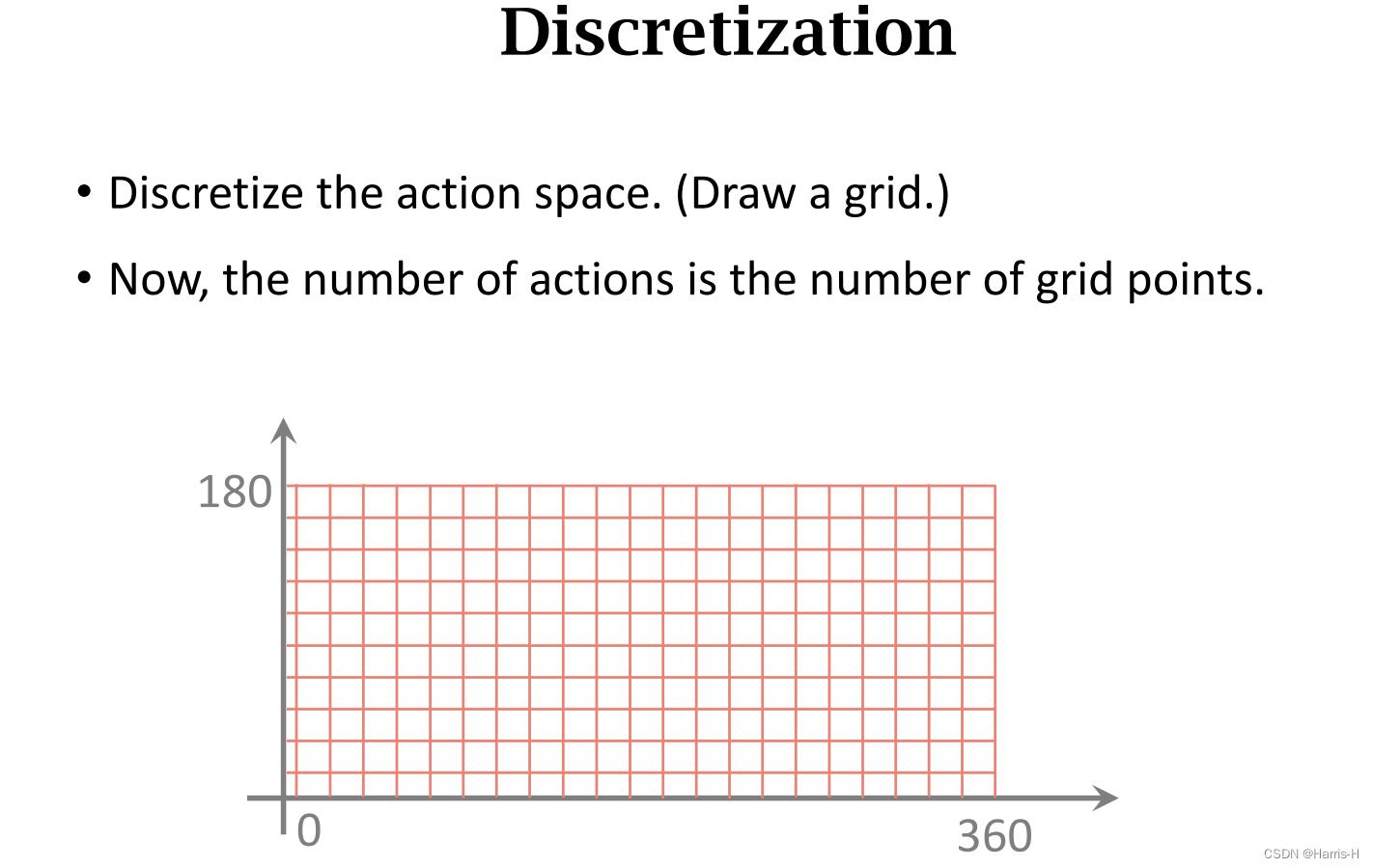
当连续动作维度较小时,可以使用离散化。

动作的个数随纬度指数增长。
2.Deterministic Policy Gradient (DPG)
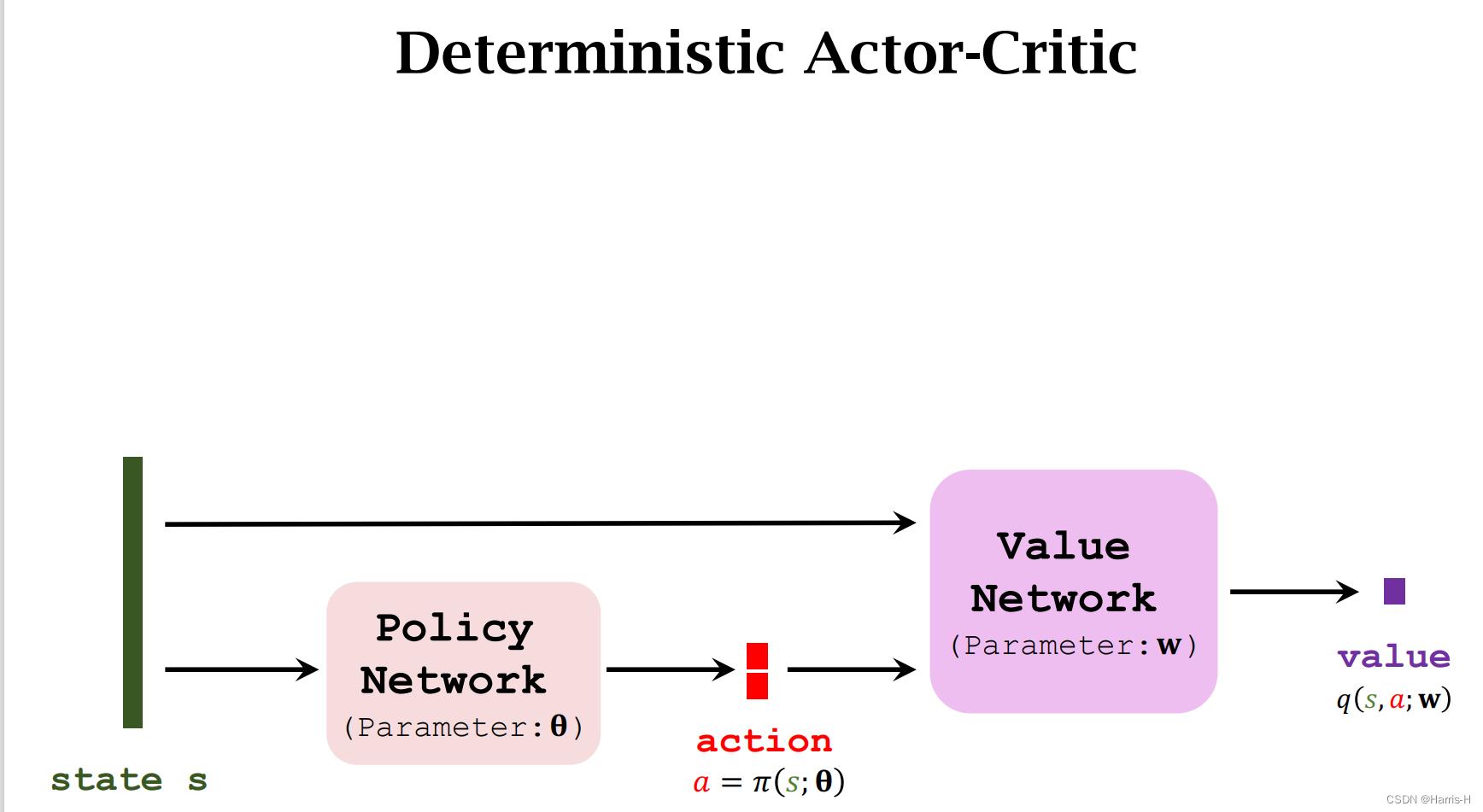
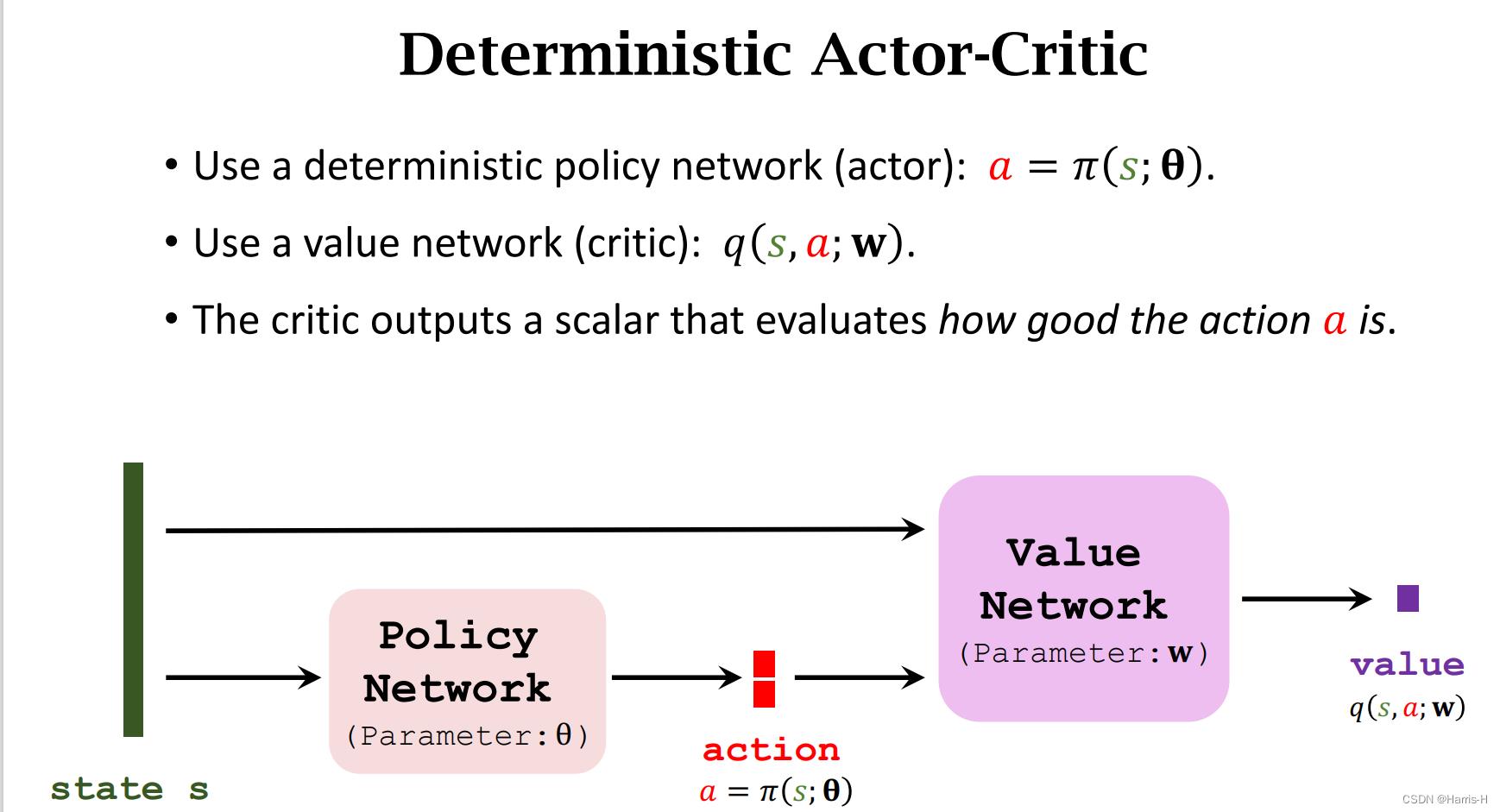
使用确定性策略网络近似 π \\pi π ,这里 π \\pi π 输出的是一个确定的动作,而不是概率分布。
价值网络的更新采用TD 算法。



改进 θ \\theta θ 可以让critic 对action评分更高,因此可以对 q q q的 θ \\theta θ 求梯度。


价值网络在使用TD target时会出现bootstrapping,导致高估问题。

因此可以采用target network来计算 y t y_t yt,分别用target value network表示 q t + 1 q_t+1 qt+1 ,target policy network 表示 a t + 1 ′ a_t+1^' at+1′


target network 的参数更新可以采用加权平均。
一些tricks

2.1 随机策略梯度和确定策略梯度两者比较

3.Stochastic Policy for Continuous Control

将每一维的动作的概率分布使用正态分布近似。

这样动作的概率分布就是对应正态分布的乘积。

这里我们采用两个neural network 近似 u u u和 ln σ 2 \\ln \\sigma^2 lnσ2


这里我们就可以得到每维度的动作概率分布 a i a_i ai
3.1 Training Policy Network

取对数进行变形。

我们同时构造一个辅助网络表示上面的式子。

辅助网络输出的是一个标量,输入是 u u u和 ρ \\rho ρ 还有动作。
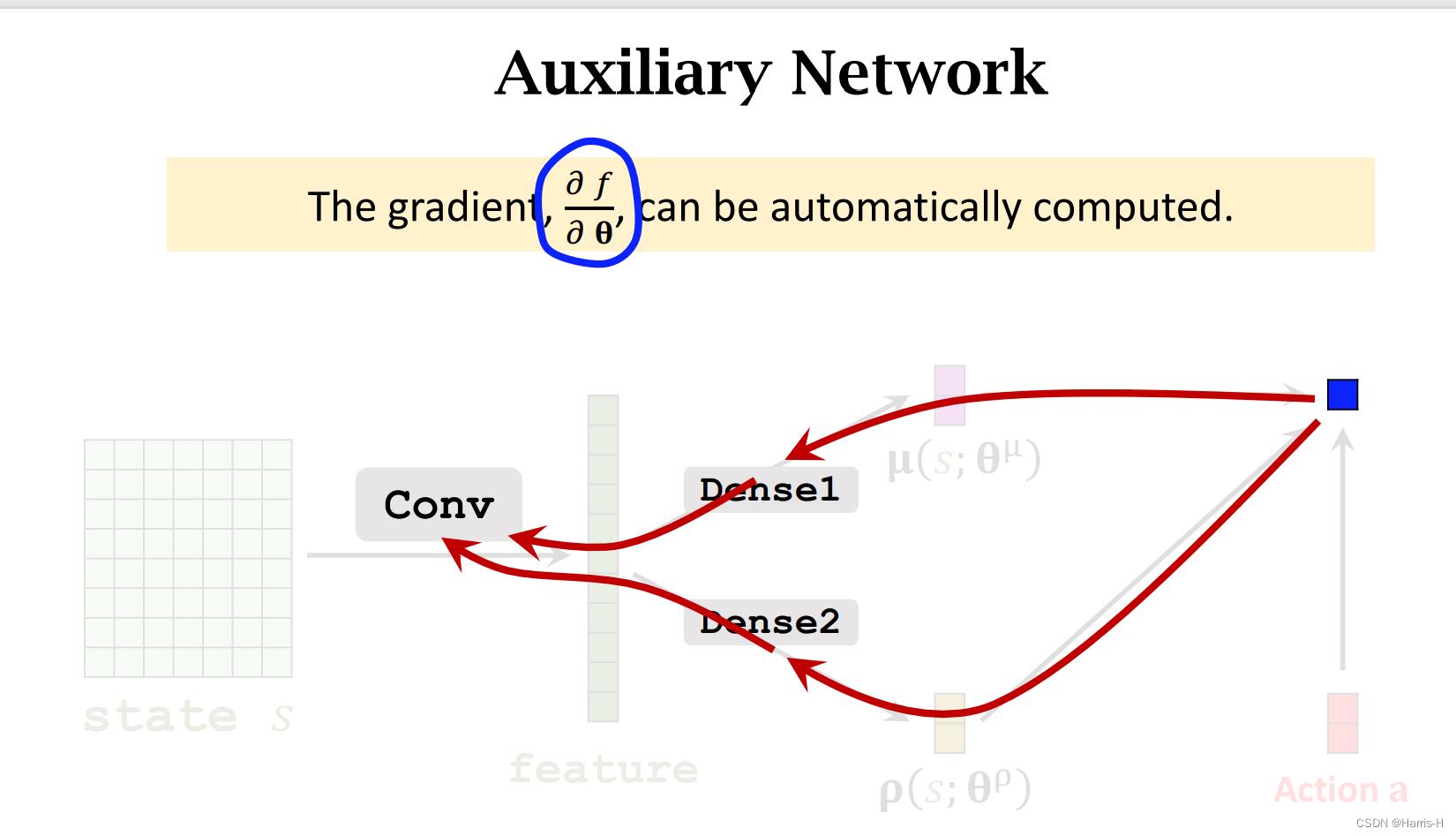
通过反向传播,我们可以计算 f f f对于 θ \\theta θ的梯度。

因为 f f f 是 l n ln ln 加上一个常数,那么显然 ln \\ln ln 对于 θ \\theta θ的偏导等于 f f f对其的偏导。


如果采用AC网络的话。
采用Mente Carlo 近似便可以更新策略网络 θ \\theta θ。
然后用TD 算法更新value network。

如果采用REINFORCE的话,怎么通过一次轨迹计算 u t u_t ut,然后Mente Carlo 近似 Q π Q_\\pi Qπ
3.2 Summary


以上是关于Discrete VS Continuous Control的主要内容,如果未能解决你的问题,请参考以下文章