基于 GRU-Attention 的中文文本分类学习记录
Posted 彭祥.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于 GRU-Attention 的中文文本分类学习记录相关的知识,希望对你有一定的参考价值。
摘 要:
传统的 GRU 分类模型是一种基于 LSTM 的模型变体,它在 LSTM 的基础上将遗忘门和输入门合并成更新门,使得最终的模型比标准的 LSTM 模型更简单。可是 LSTM 和 GRU 均没有体现每个隐层输出的重要程度。为了得到每个输出的重要程度,本文在 GRU 的基础上加入了注意力(Attention)机制,设计了 GRU-Attention 分类模型,并通过对比实验的方式说明了增加了 Attention 的 GRU 模型在分类效果上有了一定程度的提升。
相关研究工作
GRU(Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network,RNN)的一种。与 LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆依赖和反向传播中的梯度消失等问题而提出来的。相比 LSTM,使用GRU 能够达到相当的效果,并且更容易进行训练,能够很
大程度上提高训练效率,因此,很多时候研究人员会更倾向于使用 GRU。
GRU 的整体结构
GRU 的输入输出结构与普通的 RNN 是一样的。有一个当前的输入 xt
,和上一个节点传递下来的隐状态(hidden state),ht-1 这个状态包含了之前节点的相关信息。结合 xt和 ht-1,GRU 会得到当前隐藏节点的输出和传递给下一个节点的隐状态 ht。GRU 的结构如图 1 所示。

GRU 的内部结构
首先,通过上一个传输下来的状态 ht-1 和当前节点的输入xt 来获取两个门控状态。如下计算公式所示,其中 rt 为控制重置的门控(reset gate),zt 为控制更新的门控(update gate)。
rt=σ(Wr·[ ht-1, xt ])
zt=σ(wz·[ ht-1, xt ])
得到门控信号之后,首先使用重置门控来得到重置之后的数据ht-1 * rt ,再将 ht-1* rt 与输入 xt 进行拼接,通过一个tanh 激活函数将数据放缩到 -1 ~ 1 的范围内。即得到如下
公式所示的 ht:
ht=tanh(Wh·[ ht-1*rt,xt ])
这里的 ht 主要包含当前输入的 xt 数据。有针对性地将 ht 添加到当前的隐藏状态,相当于记忆了当前的状态。在这个阶段,同时进行了遗忘和记忆两个步骤。我们使用了先前得到的更新门控 zt(update gate)。
更新计算公式:
ht=(1-zt) * ht-1 + zt * ht
门控信号(zt)的范围为 0 ~ 1。门控信号越接近 1,代表记忆下来的数据越多;而越接近 0 则代表遗忘的越多。GRU 的优点在于可以使用同一个门控 zt 同时进行遗忘和选择记忆(LSTM 要使用多个门控)。结合上述,这一步的操作就是忘记 ht-1 中的某些维度信息,并且加入当前输入的某些维度信息。可以看到,这里的遗忘 zt 和选择 1-zt 是联动的,也就是说,对于传递进来的维度信息,会进行选择性遗忘,则遗忘所占的权重 zt,就会使用包含当前输入的 ht 中所对应的权重进行弥补(1-zt),以维持一种恒定状态。
GRU-Attention 模型
注意力机制(Attention)最早是在视觉图像领域提出来的,能够使深度学习模型在处理视觉图像领域问题时更好地提取重要特征,从而提升模型效果。近些年来,注意力机制逐渐被应用到自然语言处理领域,并且能够有效提高自然语言处理任务的效果,比如机器翻译、情感分析等任务。注意力机制是一种类似人脑的注意力分配机制,通过计算不同时刻词向量的概率权重,能够使一些词得到更多的关注,从而提高隐藏层特征提取的质量。
在 GRU 模型中,由于输入的词向量是文本分词预处理后的结果,所以词向量之间会具有一些联系,基于注意力机
制的深度学习模型能够通过训练词向量识别文本中词语的重要程度来提取文本中的重要特征。在 GRU-Attention 模型中,通过注意力机制所起的作用,可以找出文本中的关键词,这些词语往往是分类的重要信息。GRU-Attention 模型的结构如图 2 所示:

图中的输入为文本预处理后的各个词的向量表示 x1,x2,x3,…,x i,这些输入会进入 GRU 模型中,经过 GRU模型计算之后会得到对应输出 h1,h2,h3,…,h i,然后在隐藏层引入 Attention,计算各个输入的注意力概率分布值a1,a2,a3,…,a i,进一步提取文本特征,突出文本的关键词语。其中,Attention 机制的计算公式如下:
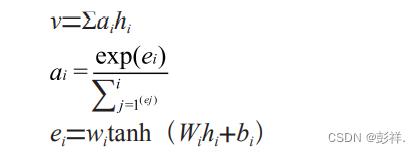
其中,ei 是由 Babdanau 等人提出的一种校验模型,ei 表示第 i 时刻隐层状态向量 hi 所决定的注意力概率分布值,wi 和 Wi 表示第 i 时刻的权重系数矩阵,bi 表示第 i 时刻相应的偏移量。通过上面的公式可以计算出最后包含文本信息的特征向量 v。输出层的输入为上一层 Attention 层的输出。最后利用 softmax 函数对输出层的输入进行相应计算,从而进行文本分类,其计算公式如下:
y=softmax(wi v + bi)
其中:wi 表示 Attention 机制层到输出层待训练的权重系数矩阵,bi 表示待训练相对应的偏置量,y 为输出的预测标签。
实验过程
实验环境
本实验采用 Windows10 操作系统,i5 四核处理器,运行内存为 16GB 的运行环境。编程语言为 Python3.6,并在Jupyter Notebook 平台上配合 Tensorflow1.6 版本深度学习框架进行开发。
实验数据
为验证本文提出的文本分类方法,本文采用 Python 爬虫从腾讯新闻爬取的中文新闻文本数据进行实验。实验数据一共包括科技、汽车、娱乐、军事和运动五大类别。数据量一共为 87595 条,并将数据集的 75% 作为训练集,25% 作为验证集来验证算法的效果。所有数据均采用 Jieba 分词工具进行分词,去停用词的操作之后,再将文本使用 word2vec转化成词向量作为算法的输入。
实验设计
本文采用对比实验(消融实验)的方式分别对 GRU-Attention 和GRU 深度学习模型进行中文新闻文本分类实验,用来说明注意力机制对文本分类结果的影响,然后在同样的数据集上使用传统的机器学习方法,包括支持向量机(SVM)、朴素贝叶斯(NB),并与前面的深度学习模型的分类效果做对比,来说明采用 GRU 深度学习模型的优势。本文的文本分类效果的评价指标采用准确率(Precision)、召回率(Recall)和 F1 值作为综合评价指标。各个评价指标的计算公式如下:

实验结果分析
实验结果如表 1 所示,从中可以看出,在相同的数据集中,GRU-Attention 模型的表现性能优于经典的 GRU 模型。另外,GRU 模型以及 GRU-Attention 模型的性能效果要比传统机器学习分类模型好,是因为注意力机制计算了文本中每个词的注意力概率值,这样可以更好地提取文本特征,从
而提高文本分类的准确率。这说明 Attention 对 GRU 文本分类模型性能的提升起到了一定的作用。

结 论
本文提出了一种新颖的混合模型 GRU-Attention,将其在文本分类任务上进行实验,并与当前主流的深度学习模型以及经典的机器学习模型进行对比,表明基于 GRU-Attention 模型可以体现文本中每个输入词的重要程度,从
而可以更加精确地提取文本特征。不仅如此,加入注意力机制后,模型既可以计算每个输入词的注意力概率分布值,也减少了特征提取过程中的信息丢失问题,缺点是在引入Attention 机制后,需要消耗一定的计算成本,如果文本输入长度增加,随之而来的计算量也会呈倍增长。在下一步的工作中,需要继续探究优化 Attention 的计算方法,减少计算量,进一步提高文本分类的效率和准确率。
个人见解
本文主要接受了GRU模型在结合了Attention后对中文文本分类的性能提升,论文内容简洁,易于理解,有一定借鉴意义。
以上是关于基于 GRU-Attention 的中文文本分类学习记录的主要内容,如果未能解决你的问题,请参考以下文章