北京上海开车遇加塞,像个人行不行?!
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了北京上海开车遇加塞,像个人行不行?!相关的知识,希望对你有一定的参考价值。
贾浩楠 发自 凹非寺
量子位 | 公众号 QbitAI
全国最复杂的环路在哪里?上海内环。
全年车流量最大的时间是何时?开学日。
赶着送孩子上学,然后再赶去公司上班,一路拥堵,一把心酸,面对频繁加塞,脚累手累心累。
难道,一天要这样开始吗?
9月1日全国最堵开学日,上海内环路上,面对不友好的突然加塞,这辆车没有重刹,没有侵占侧边车道,没有争抢冒险,当然也没有碰撞。
全程完美应对。

△ 开学日上海内环加塞实测录像来自AutoLab,下同
平缓减速避让后,及时恢复巡航速度,保证通行效率。
要是不说,没人知道这是智己L7搭载的IM AD智能驾驶系统的操作。
这样与老司机毫无二致的加塞场景处理,在上海9月1日开学季早高峰的实测中出现44次,无一接管。
这段实测视频在自动驾驶领域引发关注的核心,是因为这样“像人”的表现——对复杂场景感知、预测的细腻程度在行业内非常亮眼,也只有真正实现“数据驱动”的AI系统,才能有这样的能力。
都说在自动驾驶领域,得城市者得天下,后来又有人说,得中国城市路况者得天下,但现在看来,得加塞者才能得天下。
爆堵开学日44次加塞0接管,你不说我以为这是老司机在操作
中国实际道路驾驶中,用户最高频的痛点是加塞。
全球拥堵前30名的城市中,中国占33%,是美国的5倍。拥堵情况下,在上海内环外圈杨高中路出口,平均每小时发生16次加塞。
66%驾驶者因为频繁遭遇恶意加塞,产生过路怒行为。
这种地狱模式难度下,又叠加了开学日这样的Debuff。
44次加塞是9月1号开学季,跑完上海内环47.7公里全程的情况,大部分“被加塞”,其实是在进出匝道时的合理避让。
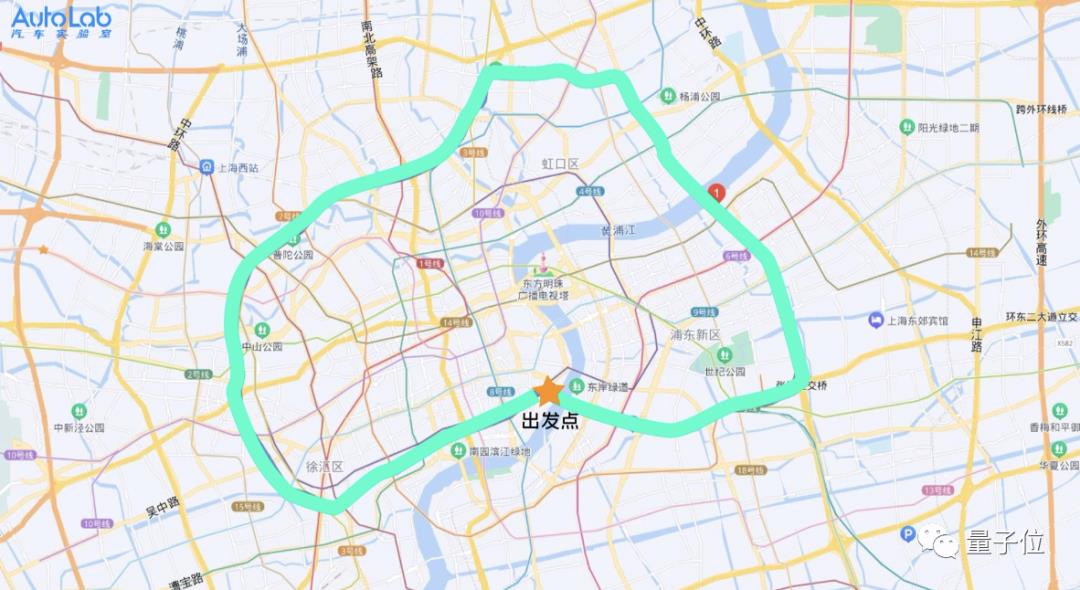
而从实际表现来看,甚至可以说IM AD的表现相当老司机,被加塞的频率并不高,能够长时间跟住一辆车平稳行驶。
 △开学日上海内环加塞实测录像来自AutoLab,仪表盘放大处理
△开学日上海内环加塞实测录像来自AutoLab,仪表盘放大处理
不至于过分迫近前车,同时大部分理智的司机也不会选择这样的空挡强行插队。这样的策略妙处,老司机肯定心领神会。
当然,路上也免不了有执意加塞的。

IM AD做出了避让,和所有智能驾驶系统一样。
但不一样的是,系统不是在整个车道被侵入以后突然急刹,而是预判了加塞行为,提前进行避让。

这样的做法当然在体感上更舒适,给乘客的心理感受也更安全。
横向来看,加塞场景不是业内竞争的焦点,似乎只要是智能车,都能应对。
但实际上真的有这么简单吗?业内已经量产的系统,又在加塞场景中有啥表现?
特斯拉的Autopilot和IM AD一样,都是适用城市路况的L2智能驾驶系统。
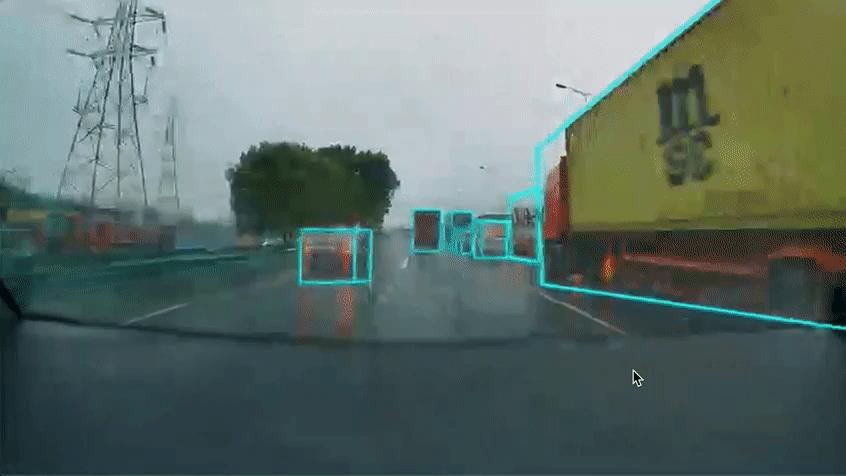
特斯拉应对突然加塞的情况,策略比较激进,Autopilot常常在遇到加塞时继续保持高速行驶,无法及时对车主进行减速反馈,这导致车主不得不在恐慌中匆忙接管。

△面对加塞Autopilot未提前减速,来自Wham Baam Teslacam
特斯拉激进的应对策略或许有时也能相安无事,但总有应对失败的情况,而一旦出现碰撞风险,对车主的安全就会产生很大的威胁。
没有任何一个智能驾驶系统能保证完全0事故,但面对加塞若系统的处理过于激进,客观上会给用户造成不信任、不敢用的障碍。用户一旦对产品的信任度下降,便会减少使用的频率,产品的价值也就相应地流失了。
应对突发情况的另一个极端,是系统策略太过保守。这其实也是现在大部分量产辅助驾驶系统的共同特征。
初衷是避免事故,但如果在驾驶逻辑的设置上过于保守,就会出现面对他车的“加塞”意图,系统过于频繁和大幅度地反馈,导致自车误制动过多,非常影响舒适度,也沦为路上的“受气包”。

△特斯拉“幽灵刹车”
这样的误制动轻则让车上的人头晕眼花,重则就像特斯拉的“幽灵刹车”一样,突然的误制动容易引发后方车辆的追尾,威胁到路面行车安全。
这样的系统,同样是在信任度和舒适性上降低了实际使用价值。
智能驾驶的初衷是减轻人类负担,研发的意义就是要让车主真正用起来。
所以,真正能处理好加塞场景,赢得车主用户信任,体验上就得在避免碰撞风险的基础上降低误制动的频率,平衡好安全性和舒适性之间的关系。要更像人,像人类老司机。
这其实就是各种安驾培训常讲的防御性驾驶。
所谓“防御性驾驶”,就是指驾驶行为的主体,无论是人还是AI司机,所要关注的都不仅仅是自车本身,还要“眼观六路”,留意自车周围所有的车、人、障碍物等目标。
预判其他目标未来的行动轨迹,并提前予以应对。
当然,还要把车开得平稳舒适。
这样的“防御性驾驶”对应到自动驾驶领域,感知、预测等底层技术的能力。
IM AD更像人,怎么做到的?
IM AD更像人,我们试了,的确如此。
同样是早高峰,地点是北京北四环,路面比上海内环更窄,车道更少。
开启IM AD后,坐在后排的乘客不看交互屏甚至难以分辨是人在驾驶还系统在驾驶。

△北京早高峰北四环加塞实测
为什么IM AD的乘坐体感更像老司机?
搭载Momenta技术方案的智己IM AD,基于数据驱动的AI飞轮能力,可以以“更像人”的智能驾驶体验,轻松应对各种复杂路况。
面对加塞这个用户“痛点”,当然也包括其他行车场景,智能驾驶的第一个技术环节就是感知。
基于数据驱动的感知能力:看得清,懂得多
最大的挑战,是要让机器快速建立自我进化和学习的能力,以保证在全天候、各种路况下,智能驾驶系统都能够“看得清,懂得多”。
Momenta在感知算法的训练中采用了Data-driven 3D的方式。
在传统的Rule-based方案中,若想通过Camera采集的物体二维信息,以此来估算物体的3D距离信息,需要依赖于大量的先验假设,且需要针对每一种不同车型设计不同的2D至3D的转换规则,无法处理真实路面上庞大数量级的复杂场景。
而数据驱动的感知系统则可以基于AI自动化深度学习的方式,从真实行车场景中采集了海量数据,作为视觉感知的原始训练数据。

同时以激光雷达输出的3D距离信息作为真值,使算法自主学习目标的具体位置信息,再依靠算法模型自由泛化的能力,实现对感知目标检测的准确度提升。
Momenta的视觉感知可以准确判断出车辆所在位置以及其与车道线之间的相对位置关系,帮助自车准确应对各种复杂的加塞场景。
也只有基于数据驱动的感知算法,才有这样的准确率和迭代效率。
基于数据驱动的预测能力:更早、更准、更及时
“像人”的核心,是搭载了Momenta技术方案的IM AD能更早、更准、更及时地判断其他车辆的加塞意图,这就是基于数据驱动的预测能力。
预测最本质的难度是不确定性。同一场景下,感知目标存在多种合理的行为决策,并且都是由目标本身主观决定。
预测功能要做的,是合理地预测出车和人的多条不同轨迹,及其对应的概率,进而反馈给下游规划模块做出安全的决策。
但真实的交通场景中,可能有近百个交通参与者,每分每秒存在上千个轨迹。

在过去,预测主要以规则驱动为主。即人工制定规则,对于极端案例的覆盖来说,这种方案有明显的局限:许多corner case无法被归类,而且人工制定规则难以穷尽长尾问题。
Momenta的思路是通过100%数据驱动(Data-driven)的方式构建出准确的预测算法,并通过海量真实路面场景的数据回流,自动化地提高预测算法的性能。
这其中藏着两个关键词:多任务学习、集体智慧。
“多任务学习”是指从车和人的位置信息、角度信息、轨迹信息及速度四个维度对预测算法模型进行联合训练。
比如在速度估计的任务学习中,当算法判断一辆车的行驶速度很快,那么它5秒后的行驶轨迹自然应该也较长,也就是跑得比较远,那么如果此时算法预测它未来5秒的所在位置却很近,这样的预测则显然是不准确的。
如此数据驱动的预测模型就可以在算法内部进行自我矫正,不断地进行自主迭代,相应地预测准确性也就越来越高。
目前Momenta在各类道路交通参与者的轨迹预测上,误差值为分米级别。
“集体智慧”则是数据驱动的算法非常形象的表达方式。通过融合海量数据中成熟人类司机的驾驶行为,来理解周围环境,理解不同车之间的交互以及车和路之间的交互,从而更准确地预测目标的未来行驶轨迹,让算法更可靠地处理复杂路况。
也就是汇聚海量人类司机的“集体智慧”,打造“更像人”并最终可能“超越人”的智能驾驶。
基于上亿数量级的庞大数据库,通过3周数据驱动的AI自主迭代,这样训练的结果是,IM AD能够更早、更准、更及时地预判其他车辆的加塞意图,使自车的减速时机提前了800毫秒。
在测试中,面对同样的极近距离加塞场景,IM AD可以及时减速,制动都比头部玩家至少提早一个车轮的距离。
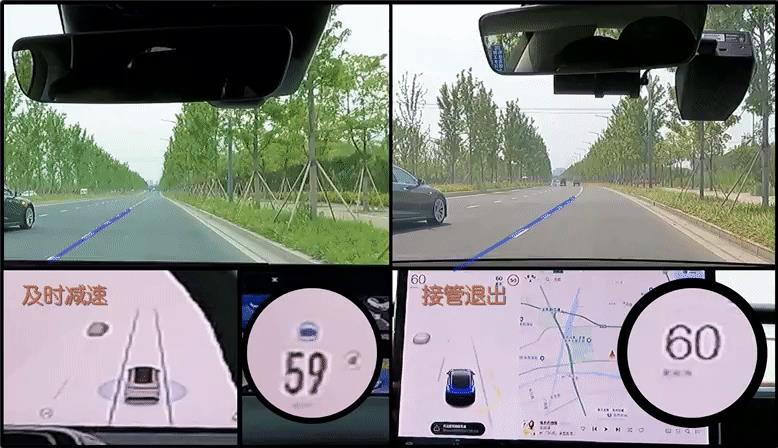

△ 遭遇恶意加塞对比,来自智己发布会,左侧为IM AD,右侧为头部玩家
数据驱动的感知、预测在底层技术上其实是属于L4及以上自动驾驶系统的先天优势。
将这套“高阶版”算法适配到量产车型上,其实是Momenta L4完全无人驾驶算法赋能到L2+智能驾驶产品的实例。
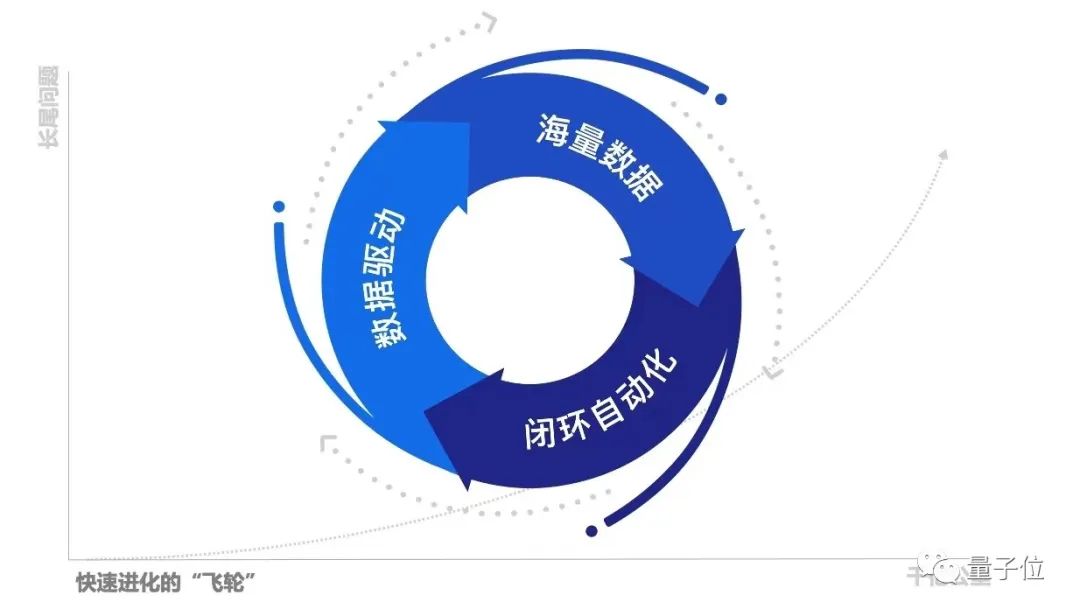
背后支撑的核心是Momenta数据驱动的飞轮战略。
飞轮一共有三个关键因子:数据驱动、海量数据和闭环自动化。
数据驱动的算法是指Momenta投入大量精力打造的统一框架,可以自动解决数据中存在的各种的问题,实现低成本、高效率的迭代。
在这个技术框架下,随着海量量产数据的流入,算法会变得越来越「聪明」,系统不断迭代,自动化解决问题的比例也会越高。
这里的海量数据,既可以来自于商业运营的Robotaxi,也可以来自搭载了Momenta量产自动驾驶系统的乘用车。
在Momenta的技术架构中,量产自动驾驶产品Mpilot和L4完全无人驾驶产品MSD采用的是统一的传感器方案和软件架构。
这也就意味着,量产车辆的数据,可以有效助力L4完全无人驾驶产品的提升。与此同时,Momenta的完全无人驾驶算法也能反馈最新的技术给到量产自动驾驶产品,从而不断提升量产自动驾驶的能力。
获取海量数据之后,闭环自动化工具链则包含数据采集、回流、分析、标注、模型训练及验证环节,用来帮助数据和算法之间形成快速迭代的反馈闭环,这个工具链可以自动筛选出海量黄金数据,驱动算法自动迭代,让“飞轮”越转越快。
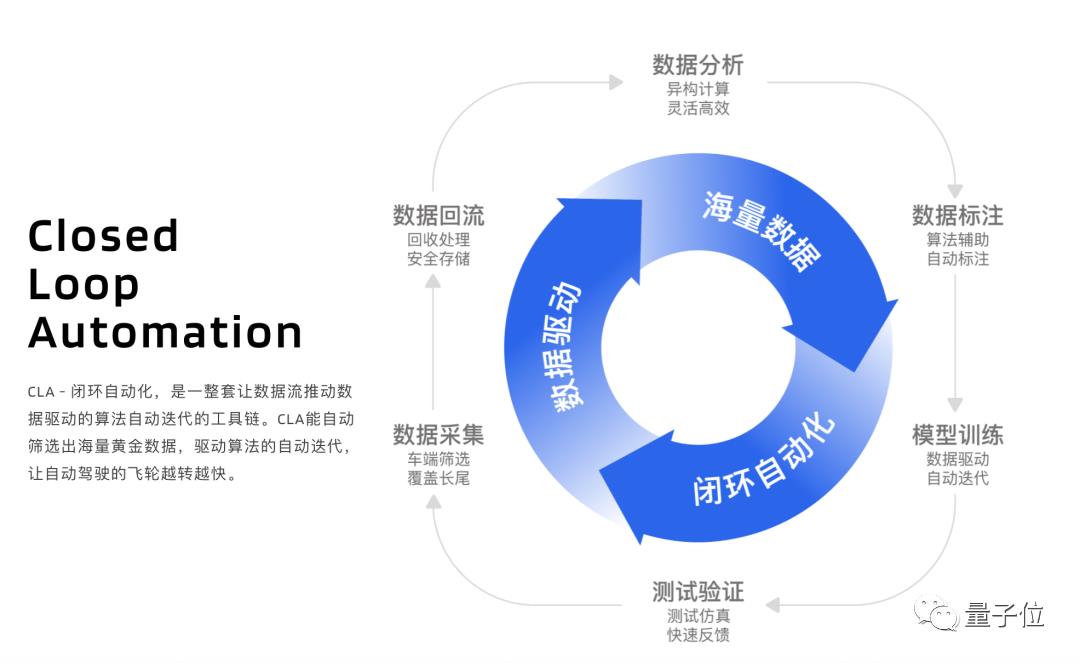
这个过程不断循环,自动「消化」海量长尾问题,从而低成本、高效率地打通整个链路,而不是依靠「传统」的人工驱动,耗时耗力地调参来解决问题。
举例来说,通过闭环自动化工具链,自交付以来,IM AD功能迭代迅速,10天内预测能力提升42%。海量真实场景数据驱动的自我迭代,可以高效解决复杂交通场景,快速覆盖规则驱动无法处理的长尾问题。
所以,智己 IM AD 展现出来超越行业普遍水平的能力,仅凭基于规则的ADAS系统,很难做到。
核心是基于AI本质的方法:数据驱动。
这套方案,应对加塞是拿下了最难场景下的一个展示。而在其他方面也有独到的表现。
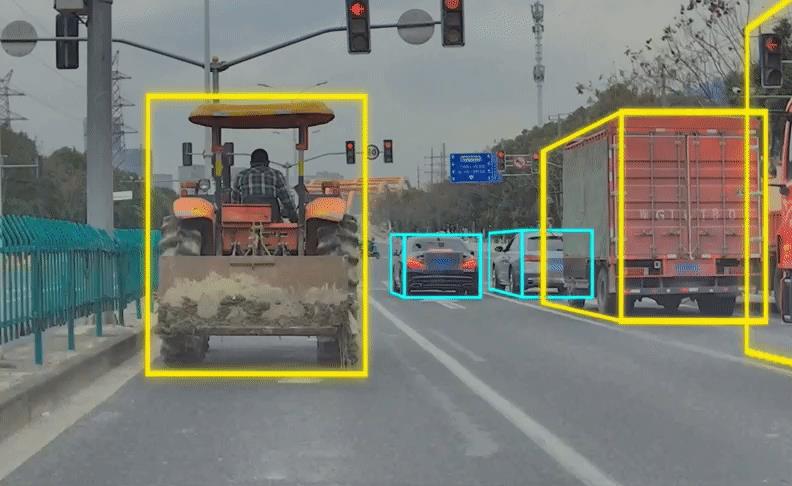
比如大车避让:

IM AD可以精准地识别出旁车道大车/异型车是否压线或即将压线行驶。
在与压线或即将压线的大车/异型车并行时,IM AD的行驶轨迹将略微向另一侧偏移,与大车之间拉开30cm的“安全距离”,安全通过后再回归车道中线,这样的设计在保障安全的同时,也可以让车主在行驶过程中感到更加安心。
这背后依然是基于数据驱动的算法,通过日产量400万的海量数据和100%的自动化标注,IM AD目前积累了累计生产一亿量级的大车数据,其中有近2500万为异型大车,覆盖全量中国典型大车、异型车场景。
一个真实研发例子是:通过3周的算法快速进化,IM AD成功开发出大车的压线属性。
这是建立用户信任与产品舒适性的一个重要功能,也是区分诸如特斯拉这样立足海外,和上汽、Momenta这样立足国内路况的自动驾驶玩家的一个重要标志。
另外,IM AD 的泊车成功率可达到95%以上,可实现极限条件下的自主泊车,在超级狭小空间下,车位空间和通道宽度仅为自车的外延的30cm:

得加塞者得L2天下
为什么这么说?
首先,从技术角度来讲,加塞场景复杂度最高、技术要求最高。一个典型的加塞避让过程,不但全面考验感知、预测等能力,还对系统的反应时间、操控细腻程度提出更高的要求。
可以熟练应对加塞的智能驾驶产品,在车道保持、定速巡航等功能上自然更加得心应手。

从用户角度来看,通勤场景内拥堵路况下的频繁加塞,是日常用车中最令人疲惫、恼火,也是最需要由智能驾驶系统代劳的场景。
这项能力其实才是L2一系列功能中用户价值最高的。
L2的人机共驾,必须要迈出的一步就是:建立人对系统的信任。
加塞场景做得让人心惊肉跳,让车主不信任不敢用,其他的功能做再好,也很难体现出智能驾驶的本来价值。
但这项能力一直被主流自动驾驶玩家忽略,直至智己IM AD。
拿下加塞场景,意味着什么?
IM AD,以及背后的Momenta,开始真正亲力亲为践行自动驾驶第一性原理。

所谓数据驱动,意义不止于表面上获取海量数据喂给AI,然后等待结果是否符合需求。这只能算“刀耕火种”的自动驾驶系统。
数据驱动的真实含义,不是执行设定好的规则,而是让AI自己从浩如烟海的数据中总结规律自我成长,在各个方面与人类驾驶行为无限接近。
这还代表着Momenta在有效数据的处理、训练、部署等等闭环环节上,已经十分成熟,为日后超大规模数据处理和更短的迭代周期奠定基础。
对于用户来说,数据驱动的算法自动迭代,能带来更安全、安心的驾驶体验。
比如上文提及的,在典型加塞场景中,IM AD可以将制动时机提前800毫秒。
这意味着如果车主的时速为80km,IM AD可以提前17.8m制动,如果车主的时速为60km,IM AD则可以提前13.3m制动。
10余米的空间距离对于紧急情况来说意味着什么,没人比各位老司机更清楚了。
在中国落地智能驾驶,要“更像人”,才能让用户敢用、愿意用,这才是系统有实用意义、能规模上量并形成数据闭环的前提。

所以,在智能驾驶领域,得加塞者得天下,IM AD和Momenta已经快人一步了。
最后再做个互动调查。在日常生活中,还有没有别的用车场景,让你觉得比加塞更烦人、体验感更差,而智能驾驶又解决得不好的?
以上是关于北京上海开车遇加塞,像个人行不行?!的主要内容,如果未能解决你的问题,请参考以下文章