这些好看的皮肤,这不嗖的一下,统统都到电脑里了~
Posted Just Python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了这些好看的皮肤,这不嗖的一下,统统都到电脑里了~相关的知识,希望对你有一定的参考价值。
文章目录
前言
🔍若以下有说不准确的地方,希望大家可以在评论区评论哈!
📢这几天整理了以前写的代码,后续会一一发出来,希望大家能持续关注哦!
🚀在整理这次的代码时,我发现以前写的都是个啥🤡?只是纯纯的进行图片的获取,没有想过如何提高获取图片的速度,我真的是……

💡不过,经历了这么长的(其实也不长)在代码之中摸爬滚打与Bug斗智斗勇的时间,我敲代码的手速得到了极大的提升,思维方式发生的极大的转变,头发的发量也由茂密变成了稀疏,最强的男人他要回来了……

📣 咱们言归正传!
这次整理了获取“农药”皮肤图片的代码,我在其中使用了threading模块,使用多线程高并发的方式提高获取图片的速度💥
代码实现
- 使用requests模块获取网页信息
- 使用re模块从获取的网页信息中提取英雄的名字和代号
- 使用os模块来创建图片存放的文件夹
- 使用threading模块的高并发方式来提升下载图片的速度
👉以下就是代码,感兴趣的朋友可以 点赞、收藏+关注,也可以潇洒的直接带走哦😜
import requests
import re
import os
import threading
# 获取英雄的名字和代号
def get_info():
url = 'https://pvp.qq.com/web201605/herolist.shtml'
headers =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36',
'Cookie': 'RK=haW9RXwFfJ; ptcz=a035781fb61847ef94953e1b146882c9559dacd5e4565b34e5b26ac2ab509e8b; pgv_pvid=6828704400; Qs_lvt_323937=1644561471; Qs_pv_323937=4461630154064148000; LW_sid=o1g684G4v5a6j144Y9z2f1h107; LW_uid=Y1T6a4X4Q5X6N174Q9n2U1m1G9; eas_sid=v1S6v4r4k5E6F114u9D2W1a6K9; eas_entry=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DTQtpAbrZy7X7jDr_5Frt-0VFzlvBjsJbcpmngMRDstm%26wd%3D%26eqid%3Dce276840000371ab0000000662060418; isHostDate=19034; PTTuserFirstTime=1644537600000; isOsSysDate=19034; PTTosSysFirstTime=1644537600000; isOsDate=19034; PTTosFirstTime=1644537600000; pgv_info=ssid=s5441967021; ts_refer=www.baidu.com/link; ts_uid=2316846848; weekloop=0-0-0-7; ieg_ingame_userid=FpFPb6fUFi0TR3WP5mcyE7o4BHeIvYpa; gpmtips_cfg=%7B%22iSendApi%22%3A0%2C%22iShowCount%22%3A0%2C%22iOnlineCount%22%3A0%2C%22iSendOneCount%22%3A0%2C%22iShowAllCount%22%3A0%2C%22iHomeCount%22%3A0%7D; ts_last=pvp.qq.com/web201605/herodetail/540.shtml; pvpqqcomrouteLine=index_herolist_wallpaper_herolist_herodetail_herodetail_herodetail; PTTDate=1644561800140',
'Referer': 'https://pvp.qq.com/'
res = requests.get(url,headers=headers)
text = res.content.decode('gbk')
# 获取英雄代号
hero_nums = re.findall('//game.gtimg.cn/images/yxzj/img201606/heroimg(.*).jpg', text)
# 获取英雄名字
hero_names = re.findall('height="91" alt="(.*)">.*</a></li>', text)
hero_names.pop()
return hero_nums, hero_names
def download_hero(hero_name, hero_num):
# 创建对应英雄的文件
file_path = f'./王者皮肤/hero_name'
if not os.path.exists(file_path):
os.makedirs(file_path)
n = 1
while True:
# 链接拼接
href = f'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-infohero_num-bigskin-n.jpg'
headers_1 =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36'
res_1 = requests.get(href, headers=headers_1)
if res_1.status_code == 200:
with open(f'file_path/hero_name-n.jpg', 'wb') as f:
f.write(res_1.content)
else:
break
n += 1
print(f'hero_name 皮肤下载完成!')
if __name__ == '__main__':
# 创建一个总文件夹
if not os.path.exists('./王者皮肤'):
os.makedirs('./王者皮肤')
hero_nums, hero_names = get_info()
threads = []
for i in range(len(hero_names)):
t = threading.Thread(target=download_hero(hero_names[i], hero_nums[i]))
threads.append(t)
for t in threads:
t.start()
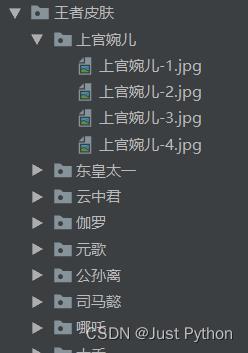
- 运行过程

- 运行结果

以上是关于这些好看的皮肤,这不嗖的一下,统统都到电脑里了~的主要内容,如果未能解决你的问题,请参考以下文章