Redis_11_Redis集群实现主从复制应对高并发
Posted 毛奇志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis_11_Redis集群实现主从复制应对高并发相关的知识,希望对你有一定的参考价值。
文章目录
一、前言
Redis搭建的集群有三个作用:
1、Redis集群实现主从复制应对高并发
2、Redis集群实现Sentinel哨兵应对高可用
3、Redis集群实现RedisCluster应对大数据量
二、主从复制搭建
实现方式包括三种:
方案1:在每一个从节点的redis.conf配置文件中增加一行,然后重启从节点
replicaof 主节点ip 6379
方案2:在每一个从节点启动命令后面增加一点东西,修改为
./src/redis-server redis.conf --slaveof 主节点ip 6379
方案3:在每一个从节点redis-cli中执行命令,无需重启从节点
slaveof 主节点ip 6379
加入集群的方法有上面桑,但是如果某个节点想要退出集群,方法有一个,redis-cli 执行 slaveof no one 即可。
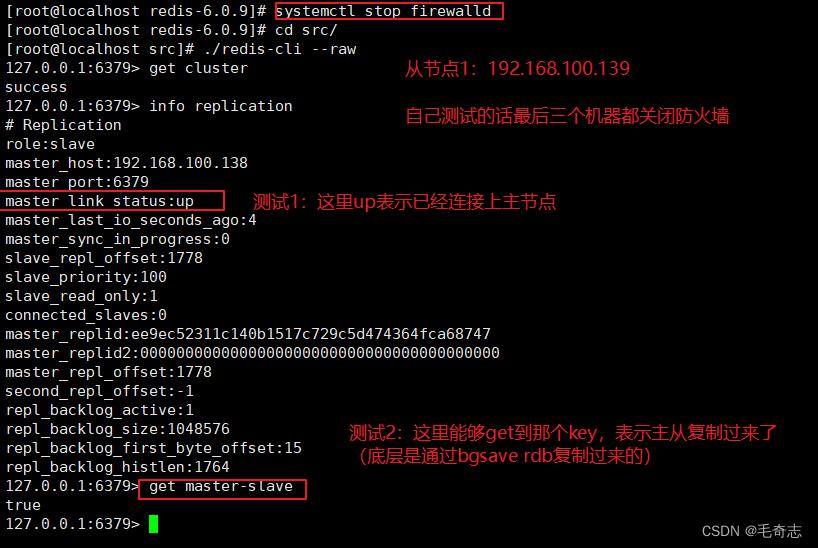
测试方法1:info命令 redis集群的任何一个节点,都可以在redis-cli中执行 info replication
测试方法2:在主节点set,然后在两个从节点可以get得到
对于测试方法1,使用
info replication在主节点可以看下面有几个slave,在从节点可以看主节点是不是up,如果有 N 个slave,主节点上显示 connected slaves : N-1 ,那么就可以到 N个从节点上,用info replication看哪个从节点上,主节点不是 up,就可以排查到了。


三、主从复制原理
Redis的主从复制分为两类:
1、全量复制:就是一个节点第一次连接到master接单,需要全部的数据。
2、增量复制:之前连接到master的节点,但是中间网络断开了,或者slave主机宕机了,缺少了一部分数据。
3.1 连接阶段
第一步,从节点启动的时候,或者 slaveof 命令执行的时候,会在自己本地保存 master 节点的信息,包括 master node 和 master ip。
第二步,从节点内部有一个定时任务 replicationCron ,每隔一秒钟检查是否有新的 master node 要连接和复制。如果发现有新的master节点,就和master节点建立连接。如果连接成功,从节点就为连接建立一个专门处理复制工作的文件事件处理器负责后续的复制工作。为了让主节点感知到slave节点的存活,slave节点定期会给主节点发送ping请求,类似心跳。
连接建立好之后,就可以同步数据了,这里也分为两个阶段。
3.2 数据同步阶段
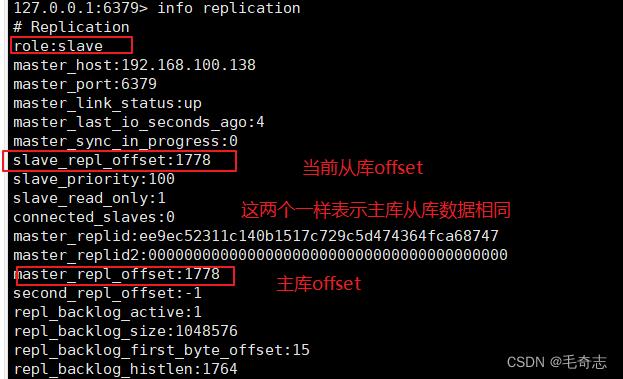
offset偏移量:如果是新加入的从节点,需要从主节点全量复制数据。master通过bgsave命令在本地生成一个rdb快照,将rdb快照文件发给从节点。然后,第一次全量同步完了,主从已经保持一致,后面就是持续把接收到的命令增量发送给从节点就好了。如果是增量复制,怎么知道上次复制到哪里?答案是从节点通过 master_repl_offset 记录的偏移量。
无盘复制:另外,Redis 6.0 引入了一个新特性,主从复制的无盘复制 repl-diskless-sync=no ,为了降低主节点磁盘开销,Redis支持无盘复制,master生成的RDB文件不保存到磁盘,而是直接通过网络发送给从节点。无盘复制适用于主节点所在机器磁盘性能较差但网络带宽宽裕的场景。
问题:如果从节点自己本来就有数据怎么办?
回答:应该先自宫,从节点应该先清除自己的旧数据,然后再用rdb文件加载数据。这个清除数据是自动,一个节点执行了 slaveof 命令,就成为了从节点,就会自动失去数据。
问题:主节点在生成rdb文件期间,接收到redis-cli客户端发送过来的写命令,如何处理?
回答:在开始生成rdb文件时,主节点会把所有新的写命令缓存到内存。在从节点保存了rdb文件之后,再次将新的命令复制给从节点。(和 aof rewrite 重写期间接收到客户端新命令一样,都是先放到内存中,处理完之后在持久化新命令)
3.3 命令传播阶段
主节点持续的写命令,异步复制给从节点 (底层bgsava生成rdb文件传递过去,所以说是异步复制)。
3.4 小结
主从复制:主节点使用bgsave命令,生成rdb文件,发送给从节点,就完成了主从复制。
注意:一般情况下,我们不会用到redis做读写分离,因为redis的吞吐量已经足够高了。如果做了主从复制,主从之间的延迟是不可避免的问题,只能通过优化网络改善。
另外,主从结构可以包含联级结构,即一个从节点可以成为其他节点的主节点,即在 redis-cli 客户端中使用 info replication 查看,一个 role: slave 的节点,也会有 connected-slaves 属性。
四、主从复制不足
Redis主从复制解决了数据备份和高并发的性能问题,但是没有解决高可用问题,没有解决大数据量水平扩容的问题。
没有解决高可用问题:如果主节点宕机,整个redis就无法使用了。
没有解决大数据量水平扩容:如果数据量太多,内存无法支持,redis存放不下,只能淘汰。
Redis主从复制解决了高并发的性能问题;
Sentinel哨兵解决高并发、高可用问题(N个Sentinel节点是同级的,N个Redis是主从的);
Redis Cluster解决高并发、高可用、大数据量问题(RedisCluster每个节点都是平级的)。
五、尾声
本文介绍了Redis集群实现主从复制应对高并发,包括如下:
问题1:为什么需要Redis集群主从架构、读写分离?
回答1:因为单机QPS是有上限的,而且Redis的特性就是必须支撑读高并发的,那你一台机器又读又写,无法承受住,但是你让这个master机器去写,数据同步给别的slave机器,他们都拿去读,分发掉大量的请求那是不是好很多,而且扩容的时候还可以轻松实现水平扩容。
问题2:主从复制怎样进行?
回答2:先全量再增量
(1) 新的slaver进来的时候用RDB冷备份做全量复制
你启动一台 slave 的时候,他会发送一个psync命令给master ,如果是这个slave第一次连接到master,他会触发一个全量复制。master就会启动一个线程,生成RDB快照,还会把新的写请求都缓存在内存中,RDB文件生成后,master会将这个RDB发送给slave的,slave拿到之后做的第一件事情就是写进本地的磁盘,然后加载进内存,然后master会把内存里面缓存的那些新命名都发给slave。
(2) 新数据使用AOF做增量复制
之后,一旦有新的数据进入,master就会同步到slaver,使用AOF热备份做增量复制,这个AOF持久化增量复制就像mysql的Binlog一样,把日志增量同步给从服务就好了。
问题3:数据传输的时候断网了或者服务器挂了怎么办啊?
回答3:传输过程中有什么网络问题啥的,会自动重连的,并且连接之后会把缺少的数据补上的。
Redis集群实现主从复制应对高并发,完成了。
以上是关于Redis_11_Redis集群实现主从复制应对高并发的主要内容,如果未能解决你的问题,请参考以下文章
Redis_12_Redis集群实现Sentinel哨兵应对高可用
redis11_Redis的主从复制先了解待重新看教程redis的集群redis 集群的优缺点