采集项目-环境准备
Posted Tonystark_lz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了采集项目-环境准备相关的知识,希望对你有一定的参考价值。
环境准备
JDK安装
1)卸载现有JDK(3台节点)
sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
(1)rpm -qa:表示查询所有已经安装的软件包
(2)grep -i:表示过滤时不区分大小写
(3)xargs -n1:表示一次获取上次执行结果的一个值
(4)rpm -e --nodeps:表示卸载软件
2)上传文件到/opt/software
3)解压JDK到/opt/module目录下
4)配置JDK环境变量
(1)新建/etc/profile.d/my_env.sh文件
[atguigu@hadoop102 module]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容,然后保存(:wq)退出
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk
export PATH=$PATH:$JAVA_HOME/bin
(2)让环境变量生效
[atguigu@hadoop102 software]$ source /etc/profile.d/my_env.sh
5)测试JDK是否安装成功
[atguigu@hadoop102 module]# java -version
如果能看到以下结果、则Java正常安装
java version "1.8.0_212"
6)分发JDK
[atguigu@hadoop102 module]$ xsync /opt/module/jdk
7)分发环境变量配置文件
[atguigu@hadoop102 module]$ sudo /home/atguigu/bin/xsync /etc/profile.d/my_env.sh
8)分别在hadoop103、hadoop104上执行source
[atguigu@hadoop103 module]$ source /etc/profile.d/my_env.sh
[atguigu@hadoop104 module]$ source /etc/profile.d/my_env.sh
hadoop安装
1)将软件拖拽至/opt/software
2)解压至/opt/module
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
# 修改名字
cd /opt/module
mv hadoop-3.1.3/ hadoop
3)修改环境变量
sudo vim /etc/profile.d/my_env.sh
增加下面的内容
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
分发环境变量文件并使之生效:
sudo xsync /etc/profile.d/my_env.sh
xcall source /etc/profile
4)修改配置文件
(1)核心配置文件core-site.xml
[atguigu@hadoop102 ~]$ cd $HADOOP_HOME/etc/hadoop
[atguigu@hadoop102 hadoop]$ vim core-site.xml
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.atguigu.hosts</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.atguigu.users</name>
<value>*</value>
</property>
</configuration>
(2)HDFS配置文件hdfs-site.xml
[atguigu@hadoop102 hadoop]$ vim hdfs-site.xml
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
<!-- 测试环境指定HDFS副本的数量1 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
(3)YARN配置文件yarn-site.xml
[atguigu@hadoop102 hadoop]$ vim yarn-site.xml
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!--yarn单个容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
(4)mapreduce配置文件mapred-site.xml
[atguigu@hadoop102 hadoop]$ vim mapred-site.xml
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
</configuration>
(5)配置workers
[atguigu@hadoop102 hadoop]$ vim workers
在该文件中增加如下内容:
hadoop102
hadoop103
hadoop104
5)群起集群
(1)如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[atguigu@hadoop102 hadoop]$ bin/hdfs namenode -format
(2)在hadoop102启动HDFS和历史服务器
[atguigu@hadoop102 hadoop]$ sbin/start-dfs.sh
[atguigu@hadoop102 hadoop]$ mapred --daemon start historyserver
(3)在配置了ResourceManager的节点(hadoop103)启动YARN
[atguigu@hadoop103 hadoop]$ sbin/start-yarn.sh
(4)web端验证
HDFS : http://hadoop102:9870/
SecondaryNameNode:http://hadoop104:9868/status.html
Yarn:http://hadoop103:8088/cluster
历史服务器:http://hadoop102:19888/jobhistory
(5)编写群起群停脚本
myhadoop
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
拓展:
HDFS性能测试
参考网站:https://help.aliyun.com/document_detail/134127.html
顺序写性能测试:
[atguigu@hadoop102 hadoop]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -write -nrFiles 5 -size 4GB
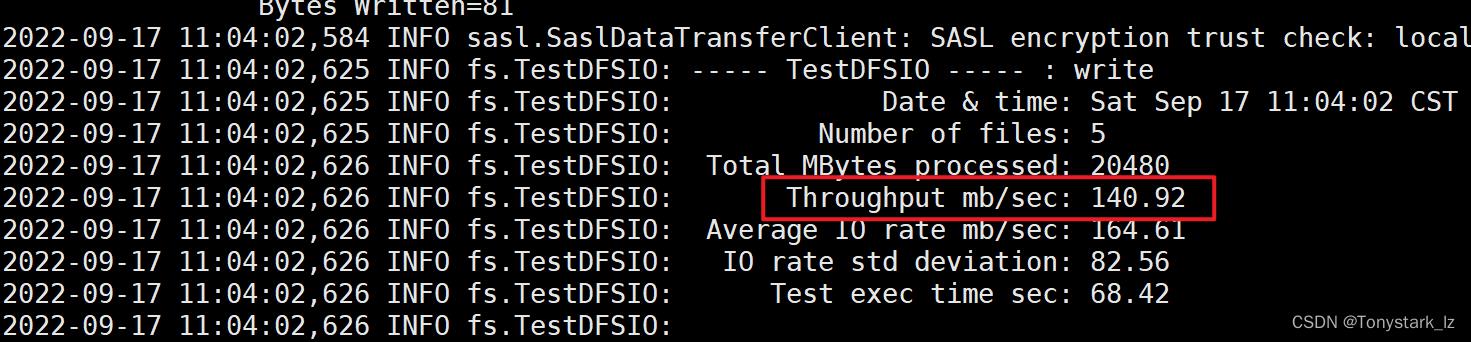
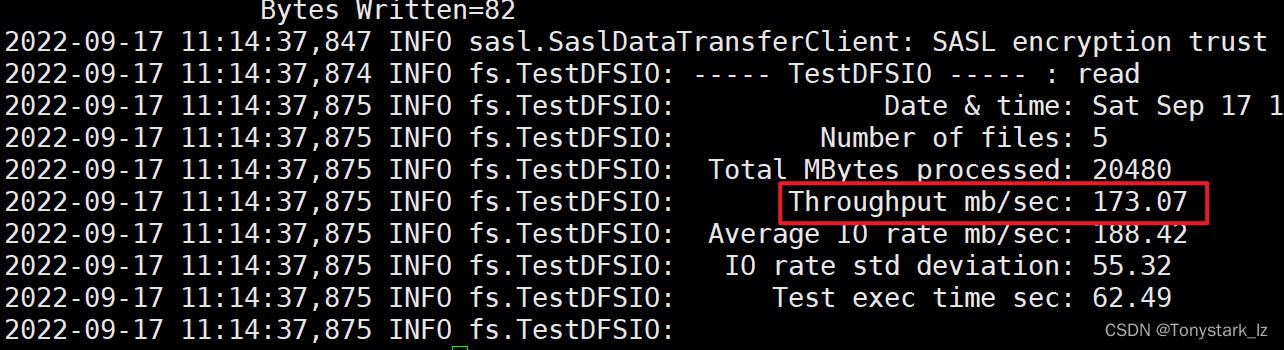
顺序读性能测试
[atguigu@hadoop102 hadoop]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -read -nrFiles 5 -size 4GB
项目经验之HDFS存储多目录
挂载新磁盘
[atguigu@hadoop102 ~]$ sudo fdisk /dev/sdb
欢迎使用 fdisk (util-linux 2.23.2)。
更改将停留在内存中,直到您决定将更改写入磁盘。
使用写入命令前请三思。
Device does not contain a recognized partition table
使用磁盘标识符 0x68b3ca31 创建新的 DOS 磁盘标签。
命令(输入 m 获取帮助):n
Partition type:
p primary (0 primary, 0 extended, 4 free)
e extended
Select (default p):
Using default response p
分区号 (1-4,默认 1):
起始 扇区 (2048-41943039,默认为 2048):
将使用默认值 2048
Last 扇区, +扇区 or +sizeK,M,G (2048-41943039,默认为 41943039):
将使用默认值 41943039
分区 1 已设置为 Linux 类型,大小设为 20 GiB
命令(输入 m 获取帮助):w
The partition table has been altered!
Calling ioctl() to re-read partition table.
正在同步磁盘。
[atguigu@hadoop102 ~]$ sudo mkfs.ext4 /dev/sdb1
mke2fs 1.42.9 (28-Dec-2013)
文件系统标签=
OS type: Linux
块大小=4096 (log=2)
分块大小=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
1310720 inodes, 5242624 blocks
262131 blocks (5.00%) reserved for the super user
第一个数据块=0
Maximum filesystem blocks=2153775104
160 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000
Allocating group tables: 完成
正在写入inode表: 完成
Creating journal (32768 blocks): 完成
Writing superblocks and filesystem accounting information: 完成
[atguigu@hadoop102 ~]$ cd /mnt
[atguigu@hadoop102 mnt]$ sudo mkdir data1
[atguigu@hadoop102 mnt]$ sudo mkdir data2
[atguigu@hadoop102 mnt]$ ll
总用量 0
drwxr-xr-x. 2 root root 6 9月 17 11:32 data1
drwxr-xr-x. 2 root root 6 9月 17 11:32 data2
[atguigu@hadoop102 mnt]$ sudo mount /dev/sdb1 /mnt/data2
data2就是我新挂载的硬盘
①生产环境服务器磁盘情况
②在hdfs-site.xml文件中配置多目录,注意新挂载磁盘的访问权限问题。
HDFS的DataNode节点保存数据的路径由dfs.datanode.data.dir参数决定,其默认值为file://$hadoop.tmp.dir/dfs/data,若服务器有多个磁盘,必须对该参数进行修改。如服务器磁盘如上图所示,则该参数应修改为如下的值。
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///dfs/data1,file:///hd2/dfs/data2,file:///hd3/dfs/data3,file:///hd4/dfs/data4</value>
</property>
注意:每台服务器挂载的磁盘不一样,所以每个节点的多目录配置可以不一致。单独配置即可。
(2)项目经验之集群数据均衡
①节点间数据均衡
开启数据均衡命令:
start-balancer.sh -threshold 10
对于参数10,代表的是集群中各个节点的磁盘空间利用率相差不超过10%,可根据实际情况进行调整。
停止数据均衡命令:
stop-balancer.sh
②磁盘间数据均衡
生成均衡计划(我们只有一块磁盘,不会生成计划)
hdfs diskbalancer -plan hadoop103
执行均衡计划
hdfs diskbalancer -execute hadoop103.plan.json
查看当前均衡任务的执行情况
hdfs diskbalancer -query hadoop103
取消均衡任务
hdfs diskbalancer -cancel hadoop103.plan.json
项目经验之Hadoop参数调优
①HDFS参数调优hdfs-site.xml
The number of Namenode RPC server threads that listen to requests from clients. If dfs.namenode.servicerpc-address is not configured then Namenode RPC server threads listen to requests from all nodes.
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。
对于大集群或者有大量客户端的集群来说,通常需要增大参数dfs.namenode.handler.count的默认值10。
<property>
<name>dfs.namenode.handler.count</name>
<value>10</value>
</property>
dfs.namenode.handler.count=20×〖log〗_e^(Cluster Size),比如集群规模为8台时,此参数设置为41。可通过简单的python代码计算该值,代码如下。
[atguigu@hadoop102 ~]$ python
Python 2.7.5 (default, Apr 11 2018, 07:36:10)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import math
>>> print int(20*math.log(8))
>>> quit()
>
②YARN参数调优yarn-site.xml
情景描述:总共7台机器,每天几亿条数据,数据源->Flume->Kafka->HDFS->Hive
面临问题:数据统计主要用HiveSQL,没有数据倾斜,小文件已经做了合并处理,开启的JVM重用,而且IO没有阻塞,内存用了不到50%。但是还是跑的非常慢,而且数据量洪峰过来时,整个集群都会宕掉。基于这种情况有没有优化方案。
解决办法:
内存利用率不够。这个一般是Yarn的2个配置造成的,单个任务可以申请的最大内存大小,和Hadoop单个节点可用内存大小。调节这两个参数能提高系统内存的利用率。
(a)yarn.nodemanager.resource.memory-mb
表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。
(b)yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是8192(MB)。
Zookeeper安装
1)集群规划
在hadoop102、hadoop103和hadoop104三个节点上部署Zookeeper。
| 服务器hadoop102 | 服务器hadoop103 | 服务器hadoop104 | |
|---|---|---|---|
| Zookeeper | Zookeeper | Zookeeper | Zookeeper |
2)解压安装
(1)解压Zookeeper安装包到/opt/module/目录下
[atguigu@hadoop102 software]$ tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
(2)修改/opt/module/apache-zookeeper-3.5.7-bin名称为zookeeper-3.5.7
[atguigu@hadoop102 module]$ mv apache-zookeeper-3.5.7-bin/ zookeeper
3)配置服务器编号
(1)在/opt/module/zookeeper-3.5.7/这个目录下创建zkData
[atguigu@hadoop102 zookeeper]$ mkdir zkData
(2)在/opt/module/zookeeper-3.5.7/zkData目录下创建一个myid的文件
[atguigu@hadoop102 zkData]$ vim myid
添加myid文件,注意一定要在linux里面创建,在notepad++里面很可能乱码
在文件中添加与server对应的编号:
2
4)配置zoo.cfg文件
(1)重命名/opt/module/zookeeper-3.5.7/conf这个目录下的zoo_sample.cfg为zoo.cfg
[atguigu@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg
(2)打开zoo.cfg文件
[atguigu@hadoop102 conf]$ vim zoo.cfg
修改数据存储路径配置
dataDir=/opt/module/zookeeper/zkData
增加如下配置
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
(3)同步/opt/module/zookeeper-3.5.7目录内容到hadoop103、hadoop104
[atguigu@hadoop102 module]$ xsync zookeeper/
(4)分别修改hadoop103、hadoop104上的myid文件中内容为3、4
(5)zoo.cfg配置参数解读
server.A=B:C:D。
A是一个数字,表示这个是第几号服务器;
集群模式下配置一个文件myid,这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
B是这个服务器的地址;
C是这个服务器Follower与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
5)集群操作
(1)分别启动Zookeeper
[atguigu@hadoop102 zookeeper]$ bin/zkServer.sh start
[atguigu@hadoop103 zookeeper]$ bin/zkServer.sh start
[atguigu@hadoop104 zookeeper]$ bin/zkServer.sh start
(2)查看状态
[atguigu@hadoop102 zookeeper]$ bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[atguigu@hadoop103 zookeeper]$ bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper/bin/../conf/zoo.cfg
Mode: leader
[atguigu@hadoop104 zookeeper]$ bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper/bin/../conf/zoo.cfg
Mode: follower
6)ZK集群 群起群听脚本
(1)在hadoop102的/home/atguigu/bin目录下创建脚本
[atguigu@hadoop102 bin]$ vim zk.sh
在脚本中编写如下内容
#!/bin/bash
case $1 in
"start")
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/opt/module/zookeeper/bin/zkServer.sh start"
done
;;
"stop")
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/opt/module/zookeeper/bin/zkServer.sh stop"
done
;;
"status")
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/opt/module/zookeeper/bin/zkServer.sh status"
done
;;
esac
(2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 zk.sh
(3)Zookeeper集群启动脚本
[atguigu@hadoop102 module]$ zk.sh start
(4)Zookeeper集群停止脚本
<以上是关于采集项目-环境准备的主要内容,如果未能解决你的问题,请参考以下文章