Kubernetes in Action 4 副本机制和其他控制器:部署托管的pod
Posted 沛沛老爹
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kubernetes in Action 4 副本机制和其他控制器:部署托管的pod相关的知识,希望对你有一定的参考价值。

目录
(1)Kubernetes In Action 1:Kubernetes介绍
(2)Kubernetes In Action 2:开始使用Kubernetes和Docker
(3)Kubernetes in Action 3 pod:运行于Kubernetes中的容器(1)
4 副本机制和其他控制器:部署托管的pod
本章内容涵盖
- 保持pod的健康
- 运行同—个pod的多个实例
- 在节点异常之后自动重新调度pod
- 水平缩放pod
- 在集群节点上运行系统级的pod
- 运行批量任务
- 调度任务定时执行或者在未来执行—次
正如你前面所学到的,pod代表了Kubernetes中的基本部署单元,而且你已知道如何手动创建、监督和管理它们。但是在实际的用例里,你希望你的部署能自动保持运行,并且保持健康,无须任何手动干预。要做到这一点,你几乎不会直接创建pod,而是创建ReplicationController或Deployment这样的资源,接着由它们来创建并管理实际的pod。
当你创建未托管的pod(就像你在前一章中创建的那些)时,会选择一个集群节点来运行pod,然后在该节点上运行容器。在本章中你将了解到,Kubernetes接下来会监控这些容器,并且在它们失败的时候自动重新启动它们。但是如果整个节点失败,那么节点上的pod会丢失,并且不会被新节点替换,除非这些pod由前面提到的ReplicationController或类似资源来管理。在本章中,你将了解Kubernetes如何检查容器是否仍然存在,如果不存在则重新启动容器。你还将学到如何运行托管的pod —— 既可以无限期运行,也可以执行单个任务,然后终止运行。
4.1 保持pod健康
使用Kubernetes的一个主要好处是,可以给Kubernetes一个容器列表来由其保持容器在集群中的运行。可以通过让Kubernetes创建pod资源,为其选择一个工作节点并在该节点上运行该pod的容器来完成此操作。但是,如果其中一个容器终止,或一个pod的所有容器都终止,怎么办?
只要将pod调度到某个节点,该节点上的Kubelet就会运行pod的容器,从此只要该pod存在,就会保持运行。如果容器的主进程崩溃,Kubelet将重启容器。如果应用程序中有一个导致它每隔一段时间就会崩溃的bug,Kubernetes会自动重启应用程序,所以即使应用程序本身没有做任何特殊的事,在Kubernetes中运行也能自动获得自我修复的能力。
即使进程没有崩溃,有时应用程序也会停止正常工作。例如,具有内存泄漏的Java应用程序将开始抛出OutOfMemoryErrors,但JVM进程会一直运行。如果有一种方法,能让应用程序向Kubernetes发出信号,告诉Kubernetes它运行异常并让Kubernetes重新启动,那就很棒了。
我们已经说过,一个崩溃的容器会自动重启,所以也许你会想到,可以在应用中捕获这类错误,并在错误发生时退出该进程。当然可以这样做,但这仍然不能解决所有的问题。
例如,你的应用因为无限循环或死锁而停止响应。为确保应用程序在这种情况下可以重新启动,必须从外部检查应用程序的运行状况,而不是依赖于应用的内部检测。
4.1.1 介绍存活探针
Kubernetes可以通过存活探针(liveness probe)检查容器是否还在运行。可以为pod中的每个容器单独指定存活探针。如果探测失败,Kubernetes将定期执行探针并重新启动容器。
注意 我们将在下一章中学习到Kubernetes还支持就绪探针(readiness probe),一定不要混淆两者。它们适用于两种不同的场景。
Kubernetes有以下三种探测容器的机制:
- HTTP GET探针对容器的IP地址(你指定的端口和路径)执行HTTP GET请求。如果探测器收到响应,并且响应状态码不代表错误(换句话说,如果HTTP响应状态码是2xx或3xx),则认为探测成功。如果服务器返回错误响应状态码或者根本没有响应,那么探测就被认为是失败的,容器将被重新启动。
- TCP套接字探针尝试与容器指定端口建立TCP连接。如果连接成功建立,则探测成功。否则,容器重新启动。
- Exec探针在容器内执行任意命令,并检查命令的退出状态码。如果状态码是0,则探测成功。所有其他状态码都被认为失败。
4.1.2 创建基于HTTP的存活探针
我们来看看如何为你的Node.js应用添加一个存活探针。因为它是一个Web应用程序,所以添加一个存活探针来检查其Web服务器是否提供请求是有意义的。但是因为这个Node.js应用程序太简单了,所以不得不人为地让它失败。
要正确演示存活探针,需要你稍微修改应用程序。在第五个请求之后,给每个请求返回HTTP状态码500(Internal Server Error)—— 你的应用程序将正确处理前五个客户端请求,之后每个请求都会返回错误。多亏了存活探针,应用在这个时候会重启,使其能够再次正确处理客户端请求。
可以在本书的代码档案中找到新应用程序的代码(在 Chapter04/kubia-unhealthy 文件夹中)。笔者已经将容器镜像推送到Docker Hub,因此你不需要自己构建它了。
你将创建一个包含HTTP GET存活探针的新pod,下面的代码清单显示了pod的yaml。
代码清单4.1 将存活探针添加到pod:kubia-liveness-probe.yaml
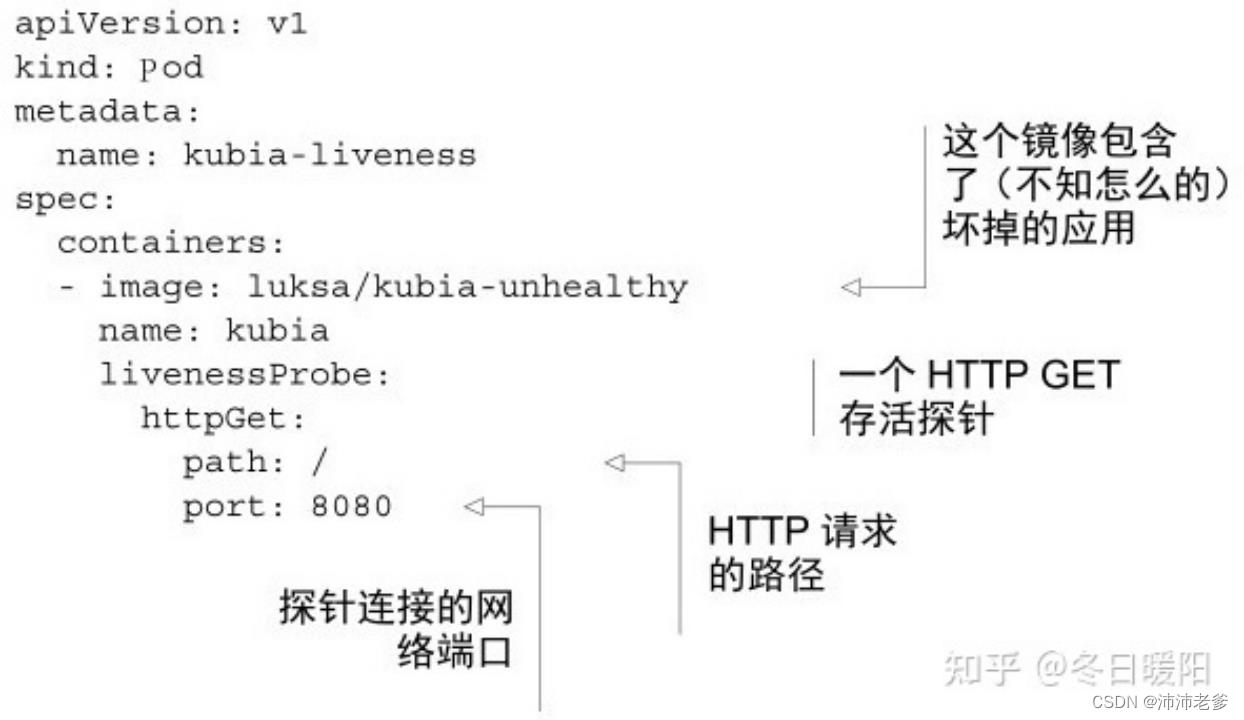
该pod的描述文件定义了一个httpGet存活探针,该探针告诉Kubernetes定期在端口8080路径上执行HTTP GET请求,以确定该容器是否健康。这些请求在容器运行后立即开始。
经过五次这样的请求(或实际的客户端请求)后,你的应用程序开始返回HTTP状态码500, Kubernetes会认为探测失败并重启容器。
4.1.3 使用存活探针
要查看存活探针是如何工作的,请尝试立即创建该pod。大约一分半钟后,容器将重启。可以通过运行 kubectl get 看到:
$ kubectl get po kubia-livenessRESTARTS列显示pod的容器已被重启一次(如果你再等一分半钟,它会再次重启,然后无限循环下去)。
获取崩溃容器的应用日志
在前一章中,你学习了如何使用 kubectl logs 打印应用程序的日志。如果你的容器重启,kubectl logs 命令将显示当前容器的日志。当你想知道为什么前一个容器终止时,你想看到的是前一个容器的日志,而不是当前容器的。可以通过添加--previous选项来完成:
$ kubectl logs mypod --previous可以通过查看kubectl describe的内容来了解 为什么必须重启容器,如下面的代码清单所示。
代码清单4.2 重启容器后的pod描述

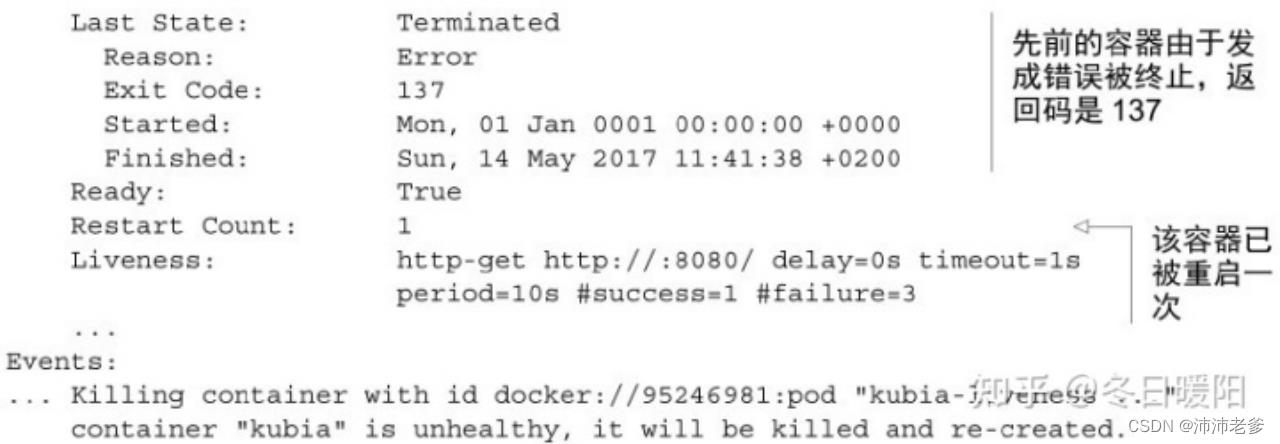
可以看到容器现在正在运行,但之前由于错误而终止。退出代码为137,这有特殊的含义 —— 表示该进程由外部信号终止。数字137是两个数字的总和:128+x,其中x是终止进程的信号编号。在这个例子中,x等于9,这是SIGKILL的信号编号,意味着这个进程被强行终止。
在底部列出的事件显示了容器为什么终止 ——Kubernetes发现容器不健康,所以终止并重新创建。
注意 当容器被强行终止时,会创建一个全新的容器——而不是重启原来的容器。
4.1.4 配置存活探针的附加属性
你可能已经注意到,kubectl describe 还显示关于存活探针的附加信息:
Liveness: http-get http://:8080/ delay=0s timeout=1s period=10s #success=1 #failure=3除了明确指定的存活探针选项,还可以看到其他属性,例如delay(延迟)、timeout(超时)、period(周期)等。delay=0s部分显示在容器启动后立即开始探测。timeout仅设置为1秒,因此容器必须在1秒内进行响应,不然这次探测记作失败。每10秒探测一次容器(period=10s),并在探测连续三次失败(#failure=3)后重启容器。
定义探针时可以自定义这些附加参数。例如,要设置初始延迟,请将initialDelaySeconds属性添加到存活探针的配置中,如下面的代码清单所示。
代码清单4.3 具有初始延迟的存活探针:
kubia-liveness-probe-initial-delay.yaml
livenessProbe:
httpGet:
path: /
port: 8080
initialDelaySeconds: 15如果没有设置初始延迟,探针将在启动时立即开始探测容器,这通常会导致探测失败,因为应用程序还没准备好开始接收请求。如果失败次数超过阈值,在应用程序能正确响应请求之前,容器就会重启。
提示 务必记得设置一个初始延迟来说明应用程序的启动时间。
很多场合都会看到这种情况,用户很困惑为什么他们的容器正在重启。但是如果使用 kubectl describe ,他们会看到容器以退出码137或143结束,并告诉他们该pod是被迫终止的。此外,pod事件的列表将显示容器因liveness探测失败而被终止。如果你在pod启动时看到这种情况,那是因为未能适当设置initialDelaySeconds。
注意 退出代码137表示进程被外部信号终止,退出代码为128+9(SIGKILL)。同样,退出代码143对应于128+15(SIGTERM)。
4.1.5 创建有效的存活探针
对于在生产中运行的pod,一定要定义一个存活探针。没有探针的话,Kubernetes无法知道你的应用是否还活着。只要进程还在运行,Kubernetes会认为容器是健康的。
存活探针应该检查什么
简易的存活探针仅仅检查了服务器是否响应。虽然这看起来可能过于简单,但即使是这样的存活探针也可以创造奇迹,因为如果容器内运行的web服务器停止响应HTTP请求,它将重启容器。与没有存活探针相比,这是一项重大改进,而且在大多数情况下可能已足够。
但为了更好地进行存活检查,需要将探针配置为请求特定的URL路径(例如/health),并让应用从内部对内部运行的所有重要组件执行状态检查,以确保它们都没有终止或停止响应。
提示 请确保/health HTTP端点不需要认证,否则探测会一直失败,导致你的容器无限重启。
一定要检查应用程序的内部,而没有任何外部因素的影响。例如,当服务器无法连接到后端数据库时,前端Web服务器的存活探针不应该返回失败。如果问题的底层原因在数据库中,重启Web服务器容器不会解决问题。由于存活探测将再次失败,你将反复重启容器直到数据库恢复。
保持探针轻量
存活探针不应消耗太多的计算资源,并且运行不应该花太长时间。默认情况下,探测器执行的频率相对较高,必须在一秒之内执行完毕。一个过重的探针会大大减慢你的容器运行。在本书的后面,还将学习如何限制容器可用的CPU时间。探针的CPU时间计入容器的CPU时间配额,因此使用重量级的存活探针将减少主应用程序进程可用的CPU时间。
提示 如果你在容器中运行Java应用程序,请确保使用HTTP GET存活探针,而不是启动全新JVM以获取存活信息的Exec探针。任何基于JVM或类似的应用程序也是如此,它们的启动过程需要大量的计算资源。
无须在探针中实现重试循环
你已经看到,探针的失败阈值是可配置的,并且通常在容器被终止之前探针必须失败多次。但即使你将失败阈值设置为1,Kubernetes为了确认一次探测的失败,会尝试若干次。因此在探针中自己实现重试循环是浪费精力。
存活探针小结
你现在知道Kubernetes会在你的容器崩溃或其存活探针失败时,通过重启容器来保持运行。这项任务由承载pod的节点上的Kubelet执行 —— 在主服务器上运行的Kubernetes Control Plane组件不会参与此过程。
但如果节点本身崩溃,那么Control Plane必须为所有随节点停止运行的pod创建替代品。它不会为你直接创建的pod执行此操作。这些pod只被Kubelet管理,但由于Kubelet本身运行在节点上,所以如果节点异常终止,它将无法执行任何操作。
为了确保你的应用程序在另一个节点上重新启动,需要使用ReplicationController或类似机制管理pod,我们将在本章其余部分讨论该机制。
4.2 了解ReplicationController
ReplicationController是一种Kubernetes资源,可确保它的pod始终保持运行状态。如果pod因任何原因消失(例如节点从集群中消失或由于该pod已从节点中逐出),则ReplicationController会注意到缺少了pod并创建替代pod。
图4.1 显示了当一个节点下线且带有两个pod时会发生什么。pod A是被直接创建的,因此是非托管的pod,而pod B由ReplicationController管理。节点异常退出后,ReplicationController会创建一个新的pod(pod B2)来替换缺少的pod B,而pod A完全丢失 —— 没有东西负责重建它。
图中的ReplicationController只管理一个pod,但一般而言,ReplicationController旨在创建和管理一个pod的多个副本(replicas)。这就是ReplicationController名字的由来。
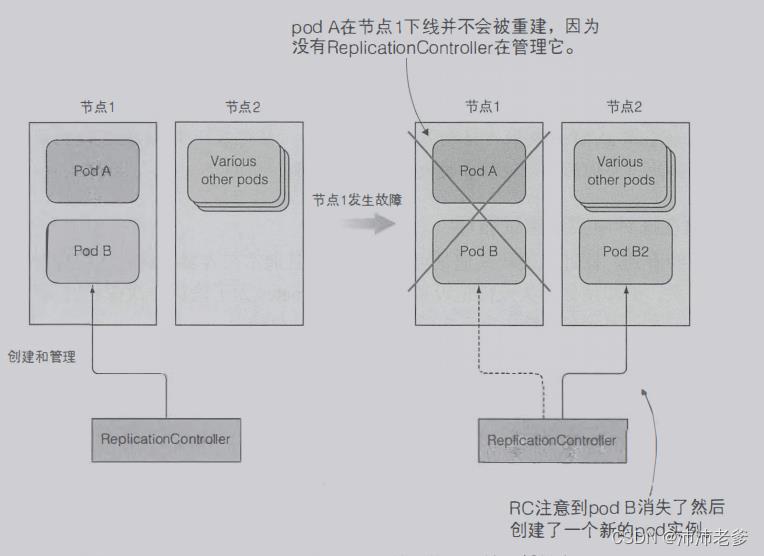 图4.1 节点故障时,只有ReplicationController管理的pod被重新创建
图4.1 节点故障时,只有ReplicationController管理的pod被重新创建
4.2.1 ReplicationController的操作
ReplicationController会持续监控正在运行的pod列表,并保证相应“类型”的pod的数目与期望相符。如正在运行的pod太少,它会根据pod模板创建新的副本。如正在运行的pod太多,它将删除多余的副本。你可能会对有多余的副本感到奇怪。这可能有几个原因:
- 有人会手动创建相同类型的pod。
- 有人更改现有的pod的“类型”。
- 有人减少了所需的pod的数量,等等。
笔者已经使用过几次pod“类型”这种说法,但这是不存在的。ReplicationController不是根据pod类型来执行操作的,而是根据pod是否匹配某个标签选择器(前一章中了解了它们)。
介绍控制器的协调流程
ReplicationController的工作是确保pod的数量始终与其标签选择器匹配。如果不匹配,则ReplicationController将根据所需,采取适当的操作来协调pod的数量。图4.2 显示了ReplicationController的操作。
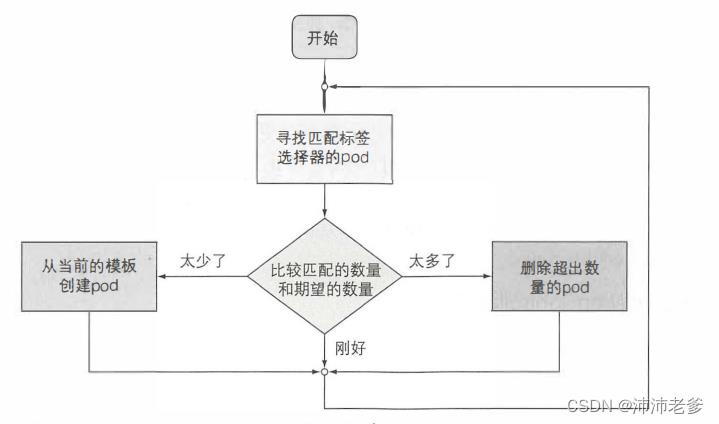
图4.2 一个ReplicationController的协调流程
了解ReplicationController的三部分
一个ReplicationController有三个主要部分(如图4.3所示):
- label selector(标签选择器),用于确定ReplicationController作用域中有哪些pod
- replica count(副本个数),指定应运行的pod数量
- pod template(pod模板),用于创建新的pod副本
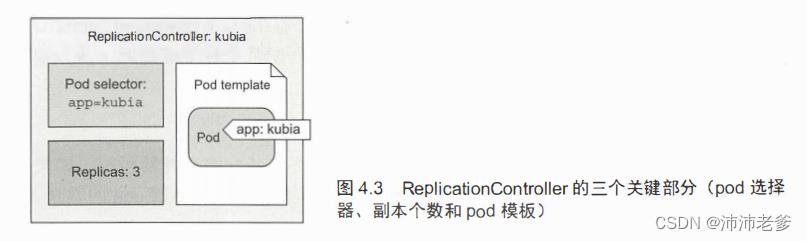
ReplicationController的副本个数、标签选择器,甚至是pod模板都可以随时修改,但只有副本数目的变更会影响现有的pod。
更改控制器的标签选择器或pod模板的效果
更改标签选择器和pod模板对现有pod没有影响。更改标签选择器会使现有的pod脱离ReplicationController的范围,因此控制器会停止关注它们。在创建pod后,ReplicationController也不关心其pod的实际“内容”(容器镜像、环境变量及其他)。因此,该模板仅影响由此ReplicationController创建的新pod。可以将其视为创建新pod的曲奇切模(cookie cutter)。
使用ReplicationController的好处
像Kubernetes中的许多事物一样,ReplicationController尽管是一个令人难以置信的简单概念,却提供或启用了以下强大功能:
- 确保一个pod(或多个pod副本)持续运行,方法是在现有pod丢失时启动一个新pod。
- 集群节点发生故障时,它将为故障节点上运行的所有pod(即受ReplicationController控制的节点上的那些pod)创建替代副本。
- 它能轻松实现pod的水平伸缩 —— 手动和自动都可以(参见第15章中的pod的水平自动伸缩)。
注意 pod实例永远不会重新安置到另一个节点。相反,ReplicationController会创建一个全新的pod实例,它与正在替换的实例无关。
4.2.2 创建一个ReplicationController
让我们了解一下如何创建一个ReplicationController,然后看看它如何让你的pod运行。就像pod和其他Kubernetes资源,可以通过上传JSON或YAML描述文件到Kubernetes API服务器来创建ReplicationController。
你将为你的ReplicationController创建名为kubia-rc.yaml的YAML文件,如下面的代码清单所示。
代码清单4.4 ReplicationController的YAML定义:kubia-rc.yaml
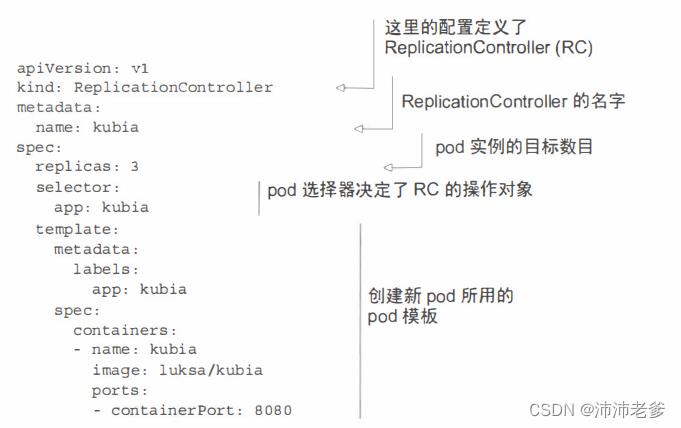
上传文件到API服务器时,Kubernetes会创建一个名为kubia的新ReplicationController,它确保符合标签选择器app=kubia的pod实例始终是三个。当没有足够的pod时,根据提供的pod模板创建新的pod。模板的内容与前一章中创建的pod定义几乎相同。
模板中的pod标签显然必须和ReplicationController的标签选择器匹配,否则控制器将无休止地创建新的容器。因为启动新pod不会使实际的副本数量接近期望的副本数量。为了防止出现这种情况,API服务会校验ReplicationController的定义,不会接收错误配置。
根本不指定选择器也是一种选择。在这种情况下,它会自动根据pod模板中的标签自动配置。
提示 定义ReplicationController时不要指定pod选择器,让Kubernetes从pod模板中提取它。这样YAML更简短。
要创建ReplicationController,请使用已知的kubectl create命令:
$ kubectl create -f kubia-rc.yaml一旦创建了ReplicationController,它就开始工作。让我们看看它都会做什么。
4.2.3 使用ReplicationController
由于没有任何pod有app=kubia标签,ReplicationController会根据pod模板启动三个新的pod。列出pod以查看ReplicationController是否完成了它应该做的事情:
$ kubectl get pods它确实创建了三个pod。现在ReplicationController正在管理这三个pod。接下来,你将通过稍稍破坏它们来观察ReplicationController如何响应。
查看ReplicationController对已删除的pod的响应
首先,你将手动删除其中一个pod,以查看ReplicationController如何立即启动新容器,从而将匹配容器的数量恢复为三:
$ kubectl delete pod kubia-53thy重新列出pod会显示四个,因为你删除的pod已终止,并且已创建一个新的pod:
$ kubectl get podsReplicationController再次完成了它的工作。这是非常有用的。
获取有关ReplicationController的信息
通过kubectl get命令显示的关于ReplicationController的信息:
$ kubectl get rc注意 使用rc作为replicationcontroller的简写。
你会看到三列显示了所需的pod数量,实际的pod数量,以及其中有多少pod已准备就绪(当我们在下一章谈论准备就绪探针时,你将了解这些含义)。可以通过kubectl describe命令看到ReplicationController的附加信息。
代码清单4.5 显示使用kubectl describe的ReplicationController的详细信息
$ kubectl describe rc kubia-rc
Name: kubia-rc
Namespace: test
Selector: app=kubia
Labels: app=kubia
Annotations: <none>
Replicas: 3 current / 3 desired
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=kubia
Containers:
kubia:
Image: luksa/kubia
Port: 8080/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 6m24s replication-controller Created pod: kubia-rc-hvx2m
Normal SuccessfulCreate 6m24s replication-controller Created pod: kubia-rc-6zkpd
Normal SuccessfulCreate 6m24s replication-controller Created pod: kubia-rc-x97fm
Normal SuccessfulCreate 3m56s replication-controller Created pod: kubia-rc-kkpzv当前的副本数与所需的数量相符,因为控制器已经创建了一个新的pod。它显示了四个正在运行的pod,因为被终止的pod仍在运行中,尽管它并未计入当前的副本个数中。底部的事件列表显示了ReplicationController的行为—— 它到目前为止创建了四个pod。
控制器如何创建新的pod
控制器通过创建一个新的替代pod来响应pod的删除操作(见图4.4)。从技术上讲,它并没有对删除本身做出反应,而是针对由此产生的状态 —— pod数量不足。
虽然ReplicationController会立即收到删除pod的通知(API服务器允许客户端监听资源和资源列表的更改),但这不是它创建替代pod的原因。该通知会触发控制器检查实际的pod数量并采取适当的措施。
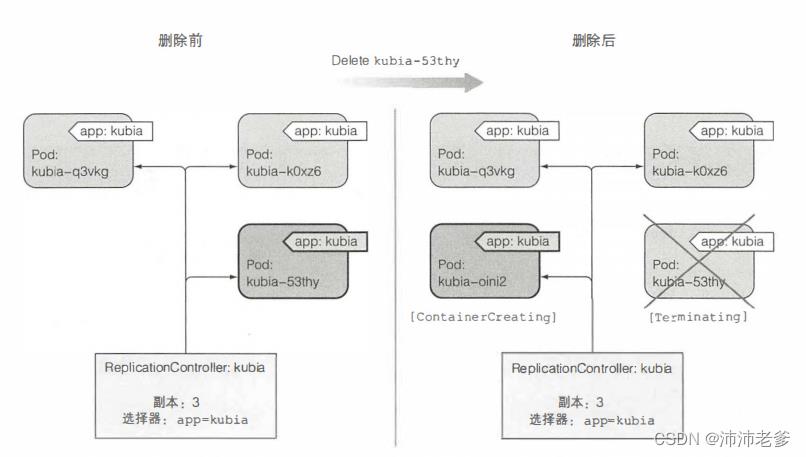
图4.4 如果一个pod消失,ReplicationController将发现pod数目更少并创建一个新的替代pod
应对节点故障
看着ReplicationController对手动删除pod做出响应没什么意思,所以我们来看一个更好的示例。如果使用Google Kubernetes Engine来运行这些示例,那么已经有一个三节点Kubernetes集群。你将从网络中断开其中一个节点来模拟节点故障。
注意 如果使用Minikube,则无法做这个练习,因为只有一个节点同时充当主节点和工作节点。
如果节点在没有Kubernetes的场景中发生故障,运维人员需要手动将节点上运行的应用程序迁移到其他机器。而现在,Kubernetes会自动执行此操作。在ReplicationController检测到它的pod已关闭后不久,它将启动新的pod以替换它们。
让我们在实践中看看这个行为。需要使用gcloud compute ssh命令ssh进入其中一个节点,然后使用sudo ifconfig eth0 down关闭其网络接口,如下面的代码清单所示。
注意 通过使用-o wide选项列出pod,选择至少运行一个pod的节点。
代码清单4.6 通过关闭网络接口来模拟节点故障
$ gcloud compu七e ssh gke-kubia-default-pool-b4638lfl-zwko
Enter passphrase for key '/home/luksa/.ssh/google_compu七e_engine':
Welcome to Kubernetes vl.6.4!
...
luksa@gke-kubia-default-pool-b4638lfl-zwko - $ sudo ifconfig ethO down当你关闭网络接口时,ssh会话将停止响应,所以需要打开另一个终端或强行退出ssh会话。在新终端中,可以列出节点以查看Kubernetes是否检测到节点下线。这需要一分钟左右的时间。然后,该节点的状态显示为NotReady:
$ kubectl get node如果你现在列出pod,那么你仍然会看到三个与之前相同的pod,因为Kubernetes在重新调度pod之前会等待一段时间(如果节点因临时网络故障或Kubelet重新启动而无法访问)。如果节点在几分钟内无法访问,则调度到该节点的pod的状态将变为Unknown。此时,ReplicationController将立即启动一个新的pod。可以通过再次列出pod来看到这一点:
$ kubectl get pods
注意pod的存活时间,你会发现kubia-dmdck pod是新的。你再次拥有三个运行的pod实例,这意味着ReplicationController再次开始它的工作,将系统的实际状态置于所需状态。
如果一个节点不可用(发生故障或无法访问),会发生同样的情况。立即进行人为干预就没有必要了。系统会自我修复。要恢复节点,需要使用以下命令重置它:
$ gcloud compute instances reset gke-kubia-default-pool-b46381f1-xwko当节点再次启动时,其状态应该返回到Ready,并且状态为Unknown的pod将被删除。
4.2.4 将pod移入或移出ReplicationController的作用域
由ReplicationController创建的pod并不是绑定到ReplicationController。在任何时刻,ReplicationController管理与标签选择器匹配的pod。通过更改pod的标签,可以将它从ReplicationController的作用域中添加或删除。它甚至可以从一个ReplicationController移动到另一个。
提示 尽管一个pod没有绑定到一个ReplicationController,但该pod在metadata.ownerReferences字段中引用它,可以轻松使用它来找到一个pod属于哪个ReplicationController。
如果你更改了一个pod的标签,使它不再与ReplicationController的标签选择器相匹配,那么该pod就变得和其他手动创建的pod一样了。它不再被任何东西管理。如果运行该节点的pod异常终止,它显然不会被重新调度。但请记住,当你更改pod的标签时,ReplicationController发现一个pod丢失了,并启动一个新的pod替换它。
让我们通过你的pod试试看。由于你的ReplicationController管理具有app=kubia标签的pod,因此需要删除这个标签或修改其值以将该pod移出ReplicationController的管理范围。添加另一个标签并没有用,因为ReplicationController不关心该pod是否有任何附加标签,它只关心该pod是否具有标签选择器中引用的所有标签。
给ReplicationController管理的pod加标签
需要确认的是,如果你向ReplicationController管理的pod添加其他标签,它并不关心:
$ kubectl label pod kubia-dmdck type=special
pod "kubia-dmdck" labeled
$ kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
kubia 0/1 ImagePullBackOff 0 9h run=kubia
kubia-4gkbs 1/1 Running 0 9h app=kubia
kubia-8sb89 1/1 Running 0 9h app=kubia
kubia-kt72n 1/1 Running 1 (10h ago) 4d21h app=kubia
给其中一个pod添加了type=special标签,再次列出所有pod会显示和以前一样的三个pod。因为从ReplicationController角度而言,没发生任何更改。
更改已托管的pod的标签
现在,更改app=kubia标签。这将使该pod不再与ReplicationController的标签选择器相匹配,只剩下两个匹配的pod。因此,ReplicationController会启动一个新的pod,将数目恢复为三:
$ kubectl label pod kubia-dmdck app=foo --overwrite--overwrite参数是必要的,否则kubectl将只打印出警告,并不会更改标签。这样是为了防止你想要添加新标签时无意中更改现有标签的值。再次列出所有pod时会显示四个pod:
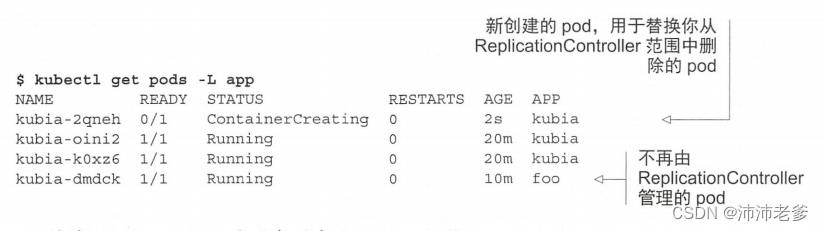
注意 使用-L app选项在列中显示app标签。
你现在有四个pod:一个不是由你的ReplicationController管理的,其他三个是。其中包括新建的pod。
图4.5 说明了当你更改pod的标签,使得它们不再与ReplicationController的pod选择器匹配时,发生的事情。可以看到三个pod和ReplicationController。在将pod的标签从app=kubia更改为app=foo之后,ReplicationController就不管这个pod了。由于控制器的副本个数设置为3,并且只有两个pod与标签选择器匹配,所以ReplicationController启动kubia-2qneh pod,使总数回到了三。kubiadmdck pod现在是完全独立的,并且会一直运行直到你手动删除它(现在可以这样做,因为你不再需要它)。
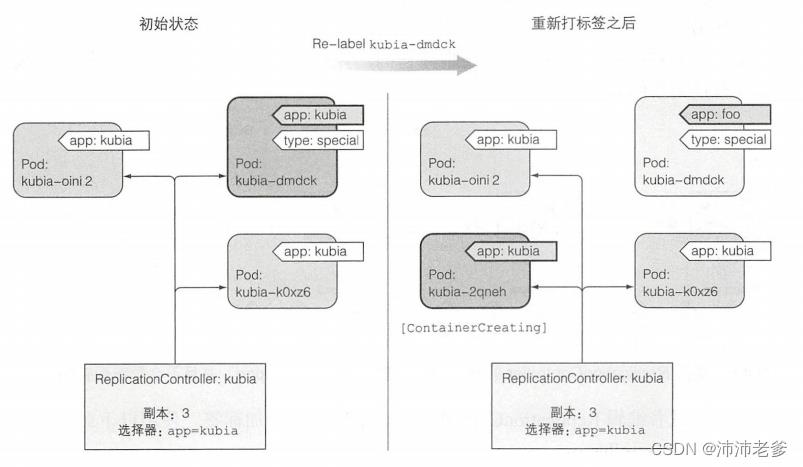
图4.5 通过更改标签从ReplicationController的作用域中删除一个pod
从控制器删除pod
当你想操作特定的pod时,从ReplicationController管理范围中移除pod的操作很管用。例如,你可能有一个bug导致你的pod在特定时间或特定事件后开始出问题。如果你知道某个pod发生了故障,就可以将它从Replication-Controller的管理范围中移除,让控制器将它替换为新pod,接着这个pod就任你处置了。完成后删除该pod即可。
更改ReplicationController的标签选择器
这里有个练习,看看你是否完全理解了ReplicationController:如果不是更改某个pod的标签而是修改了ReplicationController的标签选择器,你认为会发生什么?
如果你的答案是“它会让所有的pod脱离ReplicationController的管理,导致它创建三个新的pod”,那么恭喜你,答对了。这表明你了解了ReplicationController的工作方式。Kubernetes确实允许你更改ReplicationController的标签选择器,但这不适用于本章后半部分中介绍的其他资源(也是用来管理pod的)。
你永远不会修改控制器的标签选择器,但你会时不时会更改它的pod模板。就让我们来了解一下吧。
4.2.5 修改pod模板
ReplicationController的pod模板可以随时修改。更改pod模板就像用一个曲奇刀替换另一个。它只会影响你之后切出的曲奇,并且不会影响你已经剪切的曲奇(见图4.6)。要修改旧的pod,你需要删除它们,并让ReplicationController根据新模板将其替换为新的pod。
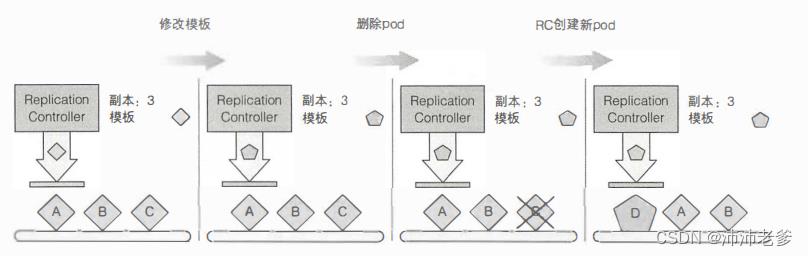
图4.6 更改ReplicationController的pod模板只影响之后创建的pod,并且不会影响现有的pod
可以试着编辑ReplicationController并向pod模板添加标签。使用以下命令编辑ReplicationController:
$ kubectl edit rc kubia这将在你的默认文本编辑器中打开ReplicationController的YAML配置。找到pod模板部分并向元数据添加一个新的标签。保存更改并退出编辑器后,kubectl将更新ReplicationController并打印以下消息:
replicationcontroller "kubia" edited现在可以再次列出pod及其标签,并确认它们未发生变化。但是如果你删除了这个pod并等待其替代pod创建,你会看到新的标签。
像这样编辑一个ReplicationController,来更改容器模板中的容器图像,删除现有的容器,并让它们替换为新模板中的新容器,可以用于升级pod,但你将在第9章学到更好的方法。
配置kubectl edit使用不同的文本编辑器
可以通过设置KUBE_EDITOR环境变量来告诉kubectl使用你期望的文本编辑器。例如,如果你想使用nano编辑Kubernetes资源,请执行以下命令(或将其放入~/.bashrc或等效文件中):
export KUBE_EDITOR="/usr/bin/nano"
如果未设置KUBE_EDITOR环境变量,则kubectl edit会回退到使用默认编辑器(通常通过EDITOR环境变量进行配置)。
4.2.6 水平缩放pod
你已经看到了ReplicationController如何确保持续运行的pod实例数量保持不变。因为改变副本的所需数量非常简单,所以这也意味着水平缩放pod很简单。
放大或者缩小pod的数量规模就和在ReplicationController资源中更改Replicas字段的值一样简单。更改之后,ReplicationController将会看到存在太多的pod并删除其中的一部分(缩容时),或者看到它们数目太少并创建pod(扩容时)。
ReplicationController扩容
ReplicationController一直保持三个pod实例在运行的状态。现在要把这个数字提高到10。你可能还记得,已经在第2章中扩容了ReplicationController。可以使用和之前相同的命令:
$ kubectl scale rc kubia --replicas=10但这次你的做法会不一样。
通过编辑定义来缩放ReplicationController
不使用kubectl scale命令,而是通过以声明的形式编辑ReplicationController的定义对其进行缩放:
$ kubectl edit rc kubia
当文本编辑器打开时,找到spec.replicas字段并将其值更改为10,如下面的代码清单所示。
代码清单4.7 运行kubectl edit在文本编辑器中编辑RC

保存该文件并关闭编辑器,ReplicationController会更新并立即将pod的数量增加到10:
$ kubectl get rc
NAME DESIRED CURRENT READY AGE
kubia 3 3 3 4d22h就是这样。如果 kubectl scale 命令看起来好像是你在告诉Kubernetes要做什么,现在就更清晰了,你是在声明对ReplicationController的目标状态的更改,而不是告诉Kubernetes它要做的事情。
用kubectl scale命令缩容
现在将副本数目减小到3。可以使用 kubectl scale 命令:
$ kubectl scale rc kubia --replicas=3所有这些命令都会修改ReplicationController定义的spec.replicas字段,就像通过 kubectl edit 进行更改一样。
伸缩集群的声明式方法
在Kubernetes中水平伸缩pod是陈述式的:“我想要运行x个实例。”你不是告诉Kubernetes做什么或如何去做,只是指定了期望的状态。
这种声明式的方法使得与Kubernetes集群的交互变得容易。设想一下,如果你必须手动确定当前运行的实例数量,然后明确告诉Kubernetes需要再多运行多少个实例的话,工作更多且更容易出错,改变一个简单的数字要容易得多。在第15章中,你会发现如果启用pod水平自动缩放,那么即使是Kubernetes本身也可以完成。
4.2.7 删除一个ReplicationController
当你通过 kubectl delete 删除ReplicationController时,pod也会被删除。但是由于由ReplicationController创建的pod不是ReplicationController的组成部分,只是由其进行管理,因此可以只删除ReplicationController并保持pod运行,如图4.7所示。
当你最初拥有一组由ReplicationController管理的pod,然后决定用ReplicaSet( 你接下来会知道)替换ReplicationController时,这就很有用。可以在不影响pod的情况下执行此操作,并在替换管理它们的ReplicationController时保持pod不中断运行。
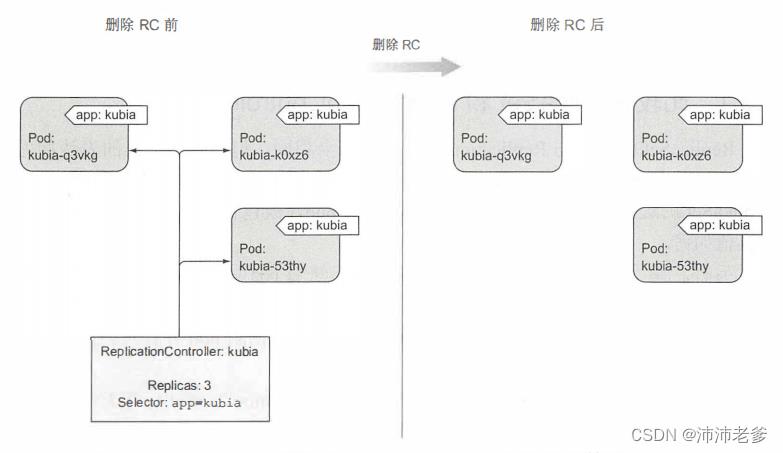
图4.7 使用--cascade=false删除ReplicationController使托架不受管理
当使用kubectl delete删除ReplicationController时,可以通过给命令增加--cascade=false选项来保持pod的运行。马上试试看:
$ kubectl delete re kubia --cascade=false
replicationcontroller "kubia" deleted你已经删除了ReplicationController,所以这些pod独立了,它们不再被管理。但是你始终可以使用适当的标签选择器创建新的ReplicationController,并再次将它们管理起来。
4.3 使用ReplicaSet而不是ReplicationController
最初,ReplicationController是用于复制和在异常时重新调度节点的唯一Kubernetes组件,后来又引入了一个名为ReplicaSet的类似资源。它是新一代的ReplicationController,并且将其完全替换掉(ReplicationController最终将被弃用)。
你本可以通过创建一个ReplicaSet而不是一个ReplicationController来开始本章,但是笔者觉得从Kubernetes最初提供的组件开始是个好主意。另外,你仍然可以看到使用中的ReplicationController,所以你最好知道它们。也就是说从现在起,你应该始终创建ReplicaSet而不是ReplicationController。它们几乎完全相同,所以你不会碰到任何麻烦。
你通常不会直接创建它们,而是在创建更高层级的Deployment资源时(在第9章中会学到)自动创建它们。无论如何,你应该了解ReplicaSet,所以让我们看看它们与ReplicationController的区别。
4.3.1 比较ReplicaSet和ReplicationController
ReplicaSet的行为与ReplicationController完全相同,但pod选择器的表达能力更强。虽然ReplicationController的标签选择器只允许包含某个标签的匹配pod,但ReplicaSet的选择器还允许匹配缺少某个标签的pod,或包含特定标签名的pod,不管其值如何。
另外,举个例子,单个ReplicationController无法将pod与标签env=production和env=devel同时匹配。它只能匹配带有env=devel标签的pod或带有env=devel标签的pod。但是一个ReplicaSet可以匹配两组pod并将它们视为一个大组。
同样,无论ReplicationController的值如何,ReplicationController都无法仅基于标签名的存在来匹配pod,而ReplicaSet则可以。例如,ReplicaSet可匹配所有包含名为env的标签的pod,无论ReplicaSet的实际值是什么(可以理解为env=*)。
4.3.2 定义ReplicaSet
现在要创建一个ReplicaSet,并看看先前由ReplicationController创建稍后又被抛弃的无主pod,现在如何被ReplicaSet管理。首先,创建一个名为kubia-replicaset.yaml的新文件将你的ReplicationController改写为ReplicaSet,其中包含以下代码清单中的内容。
代码清单4.8 ReplicaSet的YAML定义:kubia-replicaset.yaml
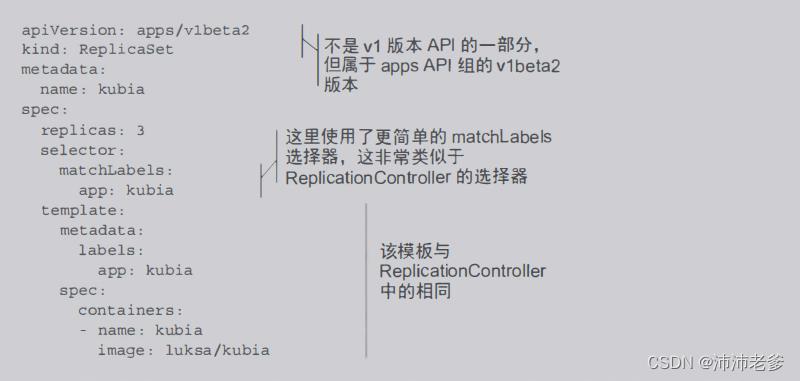
首先要注意的是ReplicaSet不是v1 API的一部分,因此你需要确保在创建资源时指定正确的apiVersion。你正在创建一个类型为ReplicaSet的资源,它的内容与你之前创建的ReplicationController的内容大致相同。
唯一的区别在选择器中。不必在selector属性中直接列出pod需要的标签,而是在selector.matchLabels下指定它们。这是在ReplicaSet中定义标签选择器的更简单(也更不具表达力)的方式。之后,你会看到表达力更强的选项。
关于API版本的属性
这是你第一次有机会看到apiVersion属性指定的两件事情:
- API组(在这种情况下是apps)
- 实际的API版本(v1beta2)
你将在整本书中看到某些Kubernetes资源位于所谓的核心API组中,该组并不需要在apiVersion字段中指定(只需指定版本——例如,你已经在定义pod资源时使用过apiVersion:v1)。在后续的Kubernetes版本中引入其他资源,被分为几个API组。
冬日暖阳的笔记
目前已经支持正式版本了!!!
apiVersion: apps/v1kind: ReplicaSet
metadata:
name: kubia
spec:
replicas: 3
selector:
matchLabels:
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
因为你仍然有三个pod匹配从最初运行的 app=kubia 选择器,所以创建此ReplicaSet不会触发创建任何新的pod。ReplicaSet将把它现有的三个pod归为自己的管辖范围。
4.3.3 创建和检查ReplicaSet
使用kubectl create命令根据YAML文件创建ReplicaSet。之后,可以使用 kubectl get 和 kubectl describe 来检查ReplicaSet:
$ kubectl get rs提示 rs是replicaset的简写。
$ kubectl describe rs
Name: kubia
Namespace: default
Selector: app=kubia
Labels: <none>
Annotations: <none>
Replicas: 3 current / 3 desired
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=kubia
Containers:
kubia:
Image: luksa/kubia
Port: <none>
Host Port: <none>
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 36s replicaset-controller Created pod: kubia-thmbn
Normal SuccessfulCreate 36s replicaset-controller Created pod: kubia-lp7nt
Normal SuccessfulCreate 36s replicaset-controller Created pod: kubia-f4j4l
如你所见,ReplicaSet与ReplicationController没有任何区别。显示有三个与选择器匹配的副本。如果列出所有pod,你会发现它们仍然是你以前的三个pod。ReplicaSet没有创建任何新的pod。
4.3.4 使用ReplicaSet的更富表达力的标签选择器
ReplicaSet相对于ReplicationController的主要改进是它更具表达力的标签选择器。之前我们故意在第一个ReplicaSet示例中,用较简单的matchLabels选择器来确认ReplicaSet与ReplicationController没有区别。现在,你将用更强大的matchExpressions属性来重写选择器,如下面的代码清单所示。
代码清单4.9 一个matchExpressions选择器:kubia-replicasetmatchexpressions.yaml

注意 仅显示了选择器。你会在本书的代码档案中找到整个ReplicaSet定义。
可以给选择器添加额外的表达式。如示例,每个表达式都必须包含一个key、一个operator(运算符),并且可能还有一个values的列表(取决于运算符)。你会看到四个有效的运算符:
- In:Label的值必须与其中一个指定的values匹配。
- NotIn:Label的值与任何指定的values不匹配。
- Exists:pod必须包含一个指定名称的标签(值不重要)。使用此运算符时,不应指定values字段。
- DoesNotExist:pod不得包含有指定名称的标签。values属性不得指定。
如果你指定了多个表达式,则所有这些表达式都必须为true才能使选择器与pod匹配。如果同时指定matchLabels和matchExpressions,则所有标签都必须匹配,并且所有表达式必须计算为true以使该pod与选择器匹配。
4.3.5 ReplicaSet小结
这是对ReplicaSet的快速介绍,将其作为ReplicationController的替代。请记住,始终使用它而不是ReplicationController,但你仍可以在其他人的部署中找到ReplicationController。
现在,删除ReplicaSet以清理你的集群。可以像删除ReplicationController一样删除ReplicaSet:
$ kubectl delete rs kubia删除ReplicaSet会删除所有的pod。这种情况下是需要列出pod来确认的。
4.4 使用DaemonSet在每个节点上运行一个pod
Replicationcontroller和ReplicaSet都用于在Kubernetes集群上运行部署特定数量的pod。但是,当你希望pod在集群中的每个节点上运行时(并且每个节点都需要正好一个运行的pod实例,如图4.8所示),就会出现某些情况。
这些情况包括pod执行系统级别的与基础结构相关的操作。例如,希望在每个节点上运行日志收集器和资源监控器。另一个典型的例子是Kubernetes自己的kube-proxy进程,它需要运行在所有节点上才能使服务工作。
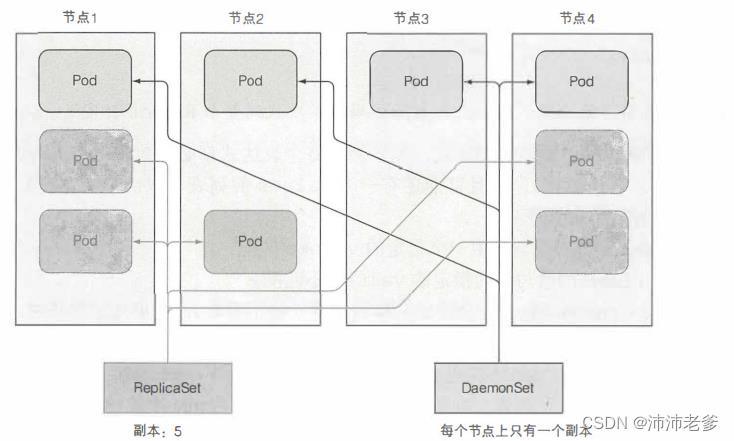 图4.8 DaemonSet在每个节点上只运行一个pod副本,而副本则将它们随机地分布在整个集群中
图4.8 DaemonSet在每个节点上只运行一个pod副本,而副本则将它们随机地分布在整个集群中
在Kubernetes之外,此类进程通常在节点启动期间通过系统初始化脚本或systemd守护进程启动。在Kubernetes节点上,仍然可以使用systemd运行系统进程,但这样就不能利用所有的Kubernetes特性了。
4.4.1 使用DaemonSet在每个节点上运行一个pod
要在所有集群节点上运行一个pod,需要创建一个DaemonSet对象,这很像一个ReplicationController或ReplicaSet,除了由DaemonSet创建的pod,已经有一个指定的目标节点并跳过Kubernetes调度程序。它们不是随机分布在集群上的。
DaemonSet确保创建足够的pod,并在自己的节点上部署每个pod,如图4.8所示。
尽管ReplicaSet(或ReplicationController)确保集群中存在期望数量的pod副本,但DaemonSet并
以上是关于Kubernetes in Action 4 副本机制和其他控制器:部署托管的pod的主要内容,如果未能解决你的问题,请参考以下文章