基于深度学习的环路滤波的消融实验
Posted Dillon2015
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于深度学习的环路滤波的消融实验相关的知识,希望对你有一定的参考价值。
本文来自提案JVET-Z0106,在上一篇文章《基于深度学习的环路滤波和残差缩放》中介绍了JVET-Y0143提案使用深度学习模型来做环路滤波带来了性能提升,但是整个模型还是一个“黑盒”,无法确定究竟是模型的哪个部分起了关键作用。本文通过消融实验对模型的输入和结构进行研究,从而确定不同模块对于最终的效果的影响。
简介
提案设计了多个消融实验,每次控制单一变量,从而确定该变量对模型的影响。研究针对帧内亮度模型(intra luma model),帧内色度模型和帧间模型保持不变。JVET-Y0143提案的帧内亮度模型的输入包括重建像素(rec)、预测像素(pred)、划分信息(part)、边界强度(BS)和QP。模型有8个残差单元,每个都使用了attention。针对这些输入和模型结构设计了以下消融实验:
-
增加训练时间:训练时间由60小时增至146小时。
-
移除输入:
-
-
移除划分信息part
-
移除BS信息
-
同时移除划分信息part和BS信息
-
移除预测信息pred
-
-
减少网络层数(残差单元由8个变为4个)
-
增加网络层数(残差单元由8个变为16个)
-
去掉残差单元的attention(最后一个残差单元除外)
-
去掉所有残差单元的attention
整个消融实验的结果如表1,使用all intra配置,复杂度使用kMACs/sample度量,整体复杂度包括了帧内色度模型和帧间模型尽管它们没改动。

消融实验
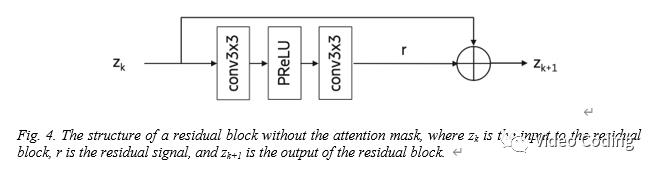
首先对JVET-Y0143提案中的模型进行了重新训练并取得了相似的BD-Rate,网络结构和JVET-Y0143提案中的一样,如图Fig.1-3,Fig.1将输入进行整合产生输出y。y再传入到8个残差单元,Fig.2是残差单元。最后一个残差的单元的输出传递到网络的最后一部分Fig.3。
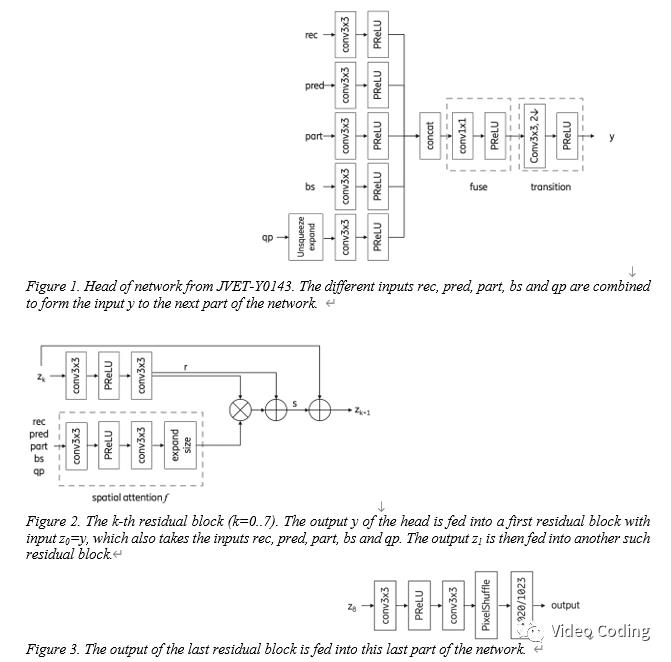
重新训练取得了和JVET-Y0143提案类似的效果(BD-Rate -7.39%),经过155轮次(60小时)训练BD-Rate为-7.38%,如表1的第1、2行。
增加训练时间
第一个消融实验是增加训练时间看对模型效果的影响,训练由155轮次(60小时)增加到378轮次(146小时),BD-Rate由-7.38%变为-7.57%,提升了0.19%,这表明增加训练时间能提升模型效果。本文使用此模型作为基准,后续的实验都训练378轮次。表1第3行。
移除输入
这部分实验通过移除不同输入验证它们对模型的影响。
移除划分信息
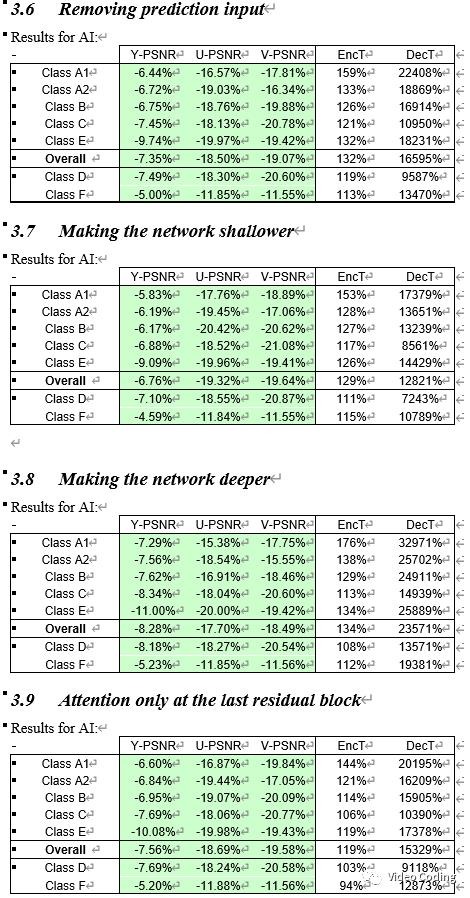
将输入中的划分信息移除,只保留rec、pred、BS和QP,经过378轮次的训练BD-Rate为-7.57%,表1第4行。移除前的BD-Rate也为-7.57%(表1第3行),这表明去掉划分信息对帧内亮度模型的效果没有影响。而且移除划分信息后复杂度也由429kMACs/sample降为418kMACs/sample。
移除BS信息
将输入中的BS信息移除,只保留rec、pred、part和QP,经过378轮次的训练BD-Rate为-7.56%,表1第5行。移除前的BD-Rate为-7.57%(表1第3行),这表明去掉BS信息对帧内亮度模型的效果几乎没有影响。而且移除BS信息后复杂度也由429kMACs/sample降为418kMACs/sample。
移除划分信息和BS信息
将输入中的划分信息和BS信息都移除,只保留rec、pred和QP,经过378轮次的训练BD-Rate为-7.42%,表1第6行。移除前的BD-Rate为-7.57%(表1第3行),这表明同时去掉划分信息和BS信息对帧内亮度模型有影响,可以判断划分信息和BS信息在模型中可能起到相似的作用,模型中至少保留两者之一。移除划分信息和BS信息后复杂度由429kMACs/sample降为407kMACs/sample。
移除预测信息
将输入中的预测信息移除,只保留rec、part、BS和QP,经过378轮次的训练BD-Rate为-7.35%,表1第7行。移除前的BD-Rate为-7.57%(表1第3行),这表明去掉预测信息对帧内亮度模型的效果影响很大。
减少网络层数
本实验将残差单元数量由8个减少为4个,经过378轮次的训练BD-Rate为-6.76%,表1第8行。移除前的BD-Rate为-7.57%(表1第3行),这表明减少网络层数对帧内亮度模型的效果影响很大。由于残差单元数量的减半,复杂度由429kMACs/sample降为261kMACs/sample。
增加网络层数
本实验将残差单元数量由8个增加为16个,经过378轮次的训练BD-Rate为-8.28%,表1第9行,由于网络层数加深训练时间也由146小时增加为235小时。移除前的BD-Rate为-7.57%(表1第3行),这表明增加网络层数可以提升帧内亮度模型的效果。由于残差单元数量的加倍,复杂度由429kMACs/sample降为765kMACs/sample。
去掉残差单元的attention(最后一个残差单元除外)
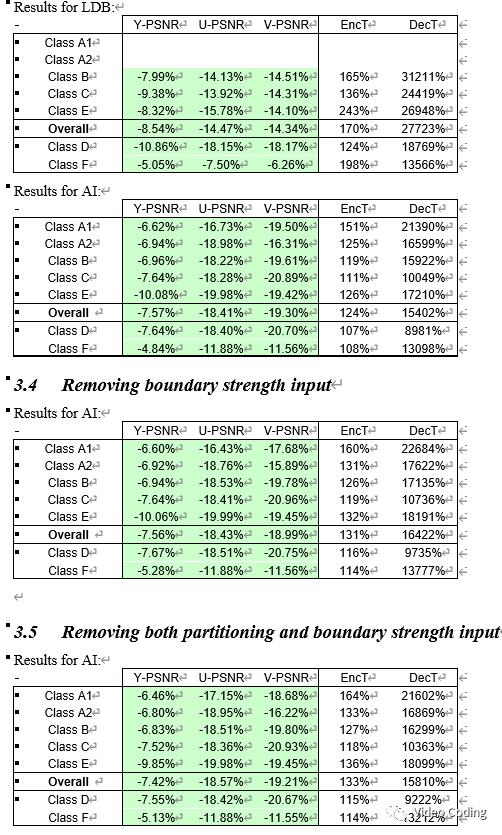
去掉前7个残差单元中的attention计算,不带attention的残差单元结构如下图,第8个残差单元保持不变,经过378轮次的训练BD-Rate为-7.56%,表1第10行,对帧内亮度模型的效果几乎没有影响。由于减少了attention的计算,,复杂度由429kMACs/sample降为426kMACs/sample。
去掉所有残差单元的attention
去掉所有残差单元中的attention计算,经过378轮次的训练BD-Rate为-7.58%,这表明attention对模型效果没有影响。由于减少了attention的计算,,复杂度由429kMACs/sample降为426kMACs/sample。
实验结果
下面是各实验的具体结果,由于研究的是帧内亮度模型所以大部分实验都是用all intra配置,其中移除划分信息的实验还有RA和LDB配置。


感兴趣的请关注微信公众号Video Coding
以上是关于基于深度学习的环路滤波的消融实验的主要内容,如果未能解决你的问题,请参考以下文章