python | prophet的案例实践:趋势检验突变点检验等
Posted 悟乙己
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python | prophet的案例实践:趋势检验突变点检验等相关的知识,希望对你有一定的参考价值。
5年前prophet刚出来的时候试用过R版本的prophet:
R+python︱Facebook大规模时序预测『真』神器——Prophet(遍地代码图)
现在最近的一些研究涉及时序数据,所以回来再看看python版本的。
文章目录
1 趋势检测
参考官方文档:Trend Changepoints
怎么训练出一个NB的Prophet模型
1.1 趋势检验案例
根据官方简单改编的:
import pandas as pd
from prophet import Prophet
from datetime import datetime
# 构造数据集
start = datetime(2017, 10, 1)
end = datetime(2018, 10, 1)
rng = pd.date_range(start, end, freq='W')
data = pd.Series(np.random.randn(len(rng)), index=rng)
data = data.reset_index()
data.columns = ['ds','y']
m = Prophet(changepoint_prior_scale=5,yearly_seasonality=False)
# 兼顾异常值,0.8,兼顾80%的异常值;越大兼顾的越多,波动性越大
# 越小越平滑
# Proportion of history in which trend changepoints will be estimated
m.fit(data)
forecast = m.predict(data)
# Python
from prophet.plot import add_changepoints_to_plot
fig = m.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), m, forecast)
# 找到突变时间线
threshold = 0.01
signif_changepoints = m.changepoints[
np.abs(np.nanmean(m.params['delta'], axis=0)) >= threshold
] if len(m.changepoints) > 0 else []
signif_changepoints
其中关于改变点有几个参数:
changepoints,n_changepoints,changepoint_range,changepoint_prior_scale
以上都是趋势性参数
1.2 Prophet模型的趋势参数
| 参数 | 描述 |
|---|---|
| growth | growth是指模型的趋势函数,目前取值有2种,linear和logistic |
| changepoints | Changepoint是指一个特殊的日期,在这个日期,模型的趋势将发生改变。而changepoints是指潜在changepoint的所有日期,如果不指明则模型将自动识别。 |
| n_changepoints | 最大的Changepoint的数量。如果changepoints不为None,则本参数不生效。 |
| changepoint_range | 是指changepoint在历史数据中出现的时间范围,与n_changeponits配合使用,changepoint_range决定了changepoint能出现在离当前时间最近的时间点,changepont_range越大,changepoint可以出现的距离现在越近。当指定changepoints时,本参数不生效 |
| changepoint_prior_scale | 设定自动突变点选择的灵活性,值越大越容易出现changepoint |
1.2.1 growth
growth是指模型的趋势函数,目前取值有2种,linear和logistic,分别如图1-1及图1-2所示。趋势会在changepoint处出现突变点。
此图为图1-1 linear趋势:

此图为图1-2 logistic趋势:
可不可能出现同一个模型既有linear趋势,又有logistic趋势,就像下面这样:
Prophet的趋势模型要么是linear要么是logistic。而上图之所以像是两种的叠加,是因为prophet的设计师为了让趋势函数可微(连续,就理解成连续吧)做了平滑处理,

上面就是论文中做平滑处理的公式。
1.2.2 Changepoints
hangeponits形状如[‘2013-01-01’,’2013-09-01’,’2017-02-5’],是changepoint的列表。
Changepoints是一个非常重要的参数,但用户在决定设置此值时必须要注意,这个参数设置之后模型将不会自动寻找changepoints(同时n_changepoints和changepoint_range均不会生效),这就意味着手动设置的changeponits必须准确且完整,否则福布湿不建议大家设置此项。
1.2.3 n_changeponits、changepoint_range
这2个参数是模型自动识别changepoint时需要的,n_changepoints限制了changepoint的最大数量,changepoint_range限制了changepoint在历史数据中出现的时间范围。
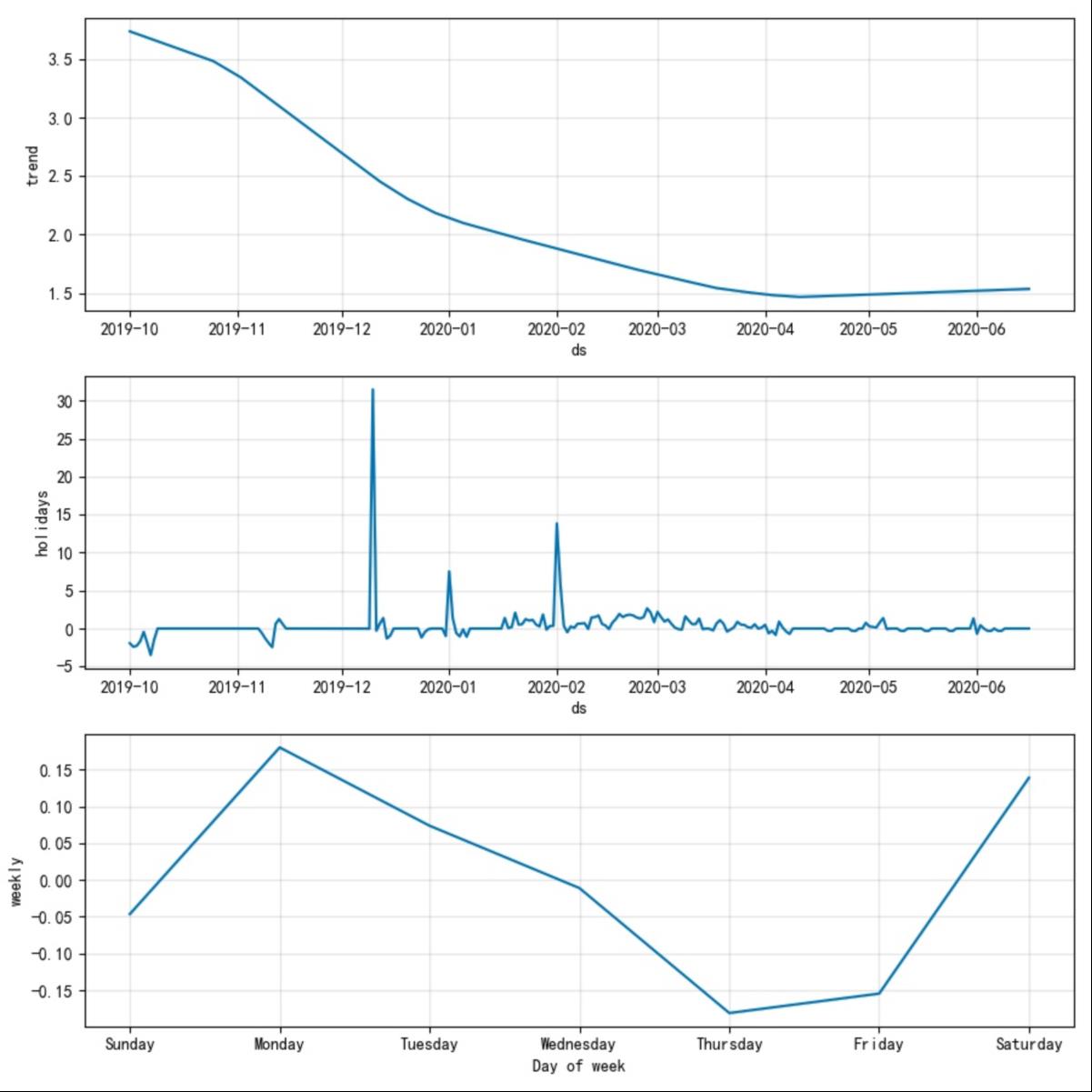
例如图1-1中changepoint_range福布湿设置的是0.5,而图1-3中设置的是0.8,如果把图1-3中的changepoint_range设置为0.2,那么所有的changpoint均只能出现在2020-01-01至2020-02-01的范围内。
1.3 Prophet模型的周期性参数
| 参数 | 描述 |
|---|---|
| yearly_seasonality | 年周期性,True为启用,false为关闭,如果设置为自然数n,则n代表傅里叶级数的项数,项数越多,模型将拟合的越好,但是也越容易过拟合,因此论文中推荐年周期性的项数取10,而周的(weekly_seasonality)取3。 一般来讲当历史数据大于1年时模型默认为True(项数默认为10),否则默认为False |
| weekly_seasonality | 周周期性,True为启用,false为关闭,如果设置为自然数n,则n代表傅里叶级数的项数,项数越多,模型将拟合的越好,但是也越容易过拟合,因此论文中推荐取3。 一般来讲当历史数据大于1周时模型默认为True(项数默认为3),否则默认为False |
| daily_seasonality | 天周期性,当时间序列为小时级别序列时才会开启。 |
| seasonality_mode | 季节模型方式,‘additive’(加法模型) (默认) 或者 ‘multiplicative’(乘法模型) |
| seasonality_prior_scale | 改变周期性影响因素的强度,值越大,周期性因素在预测值中占比越大 |
周期性参数设置相对较为固化,除了seasonality_mode和seasonality_prior_scale可能需要手动调整外其余各项一般情况下保持为默认值即可(当然具体问题具体分析,傅里叶项数在某些特殊情况下也可能需要调整)。
傅里叶级数跟泰勒展开式一样,都是用特定的级数形式拟合某个函数,傅里叶级数是专门为周期性函数设计的,也就是说只要某个函数是周期函数就能使用傅里叶级数拟合。有兴趣的同学可以看下知乎上的这个文章:
傅里叶系列(一)傅里叶级数的推导
seasonality_mode的季节模型类型如果大家不深究按字面意思理解即可。
1.4 Prophet模型节假日参数
| 参数 | 描述 |
|---|---|
| holidays | 节假日或特殊日期,商业活动中活动日期是这类日期的典型代表 |
| holiday_prior_scale | 改变假日模型的强度 |
Holidays参数是一个pd.DataFrame:
| holiday | ds |
|---|---|
| 元旦 | 2019/1/1 |
| 元旦 | 2018/1/1 |
holiday是特殊日期的时间,ds是时间(pd.Timestamp类型),upper_window和lower_window分别指特殊日期的影响上下限。
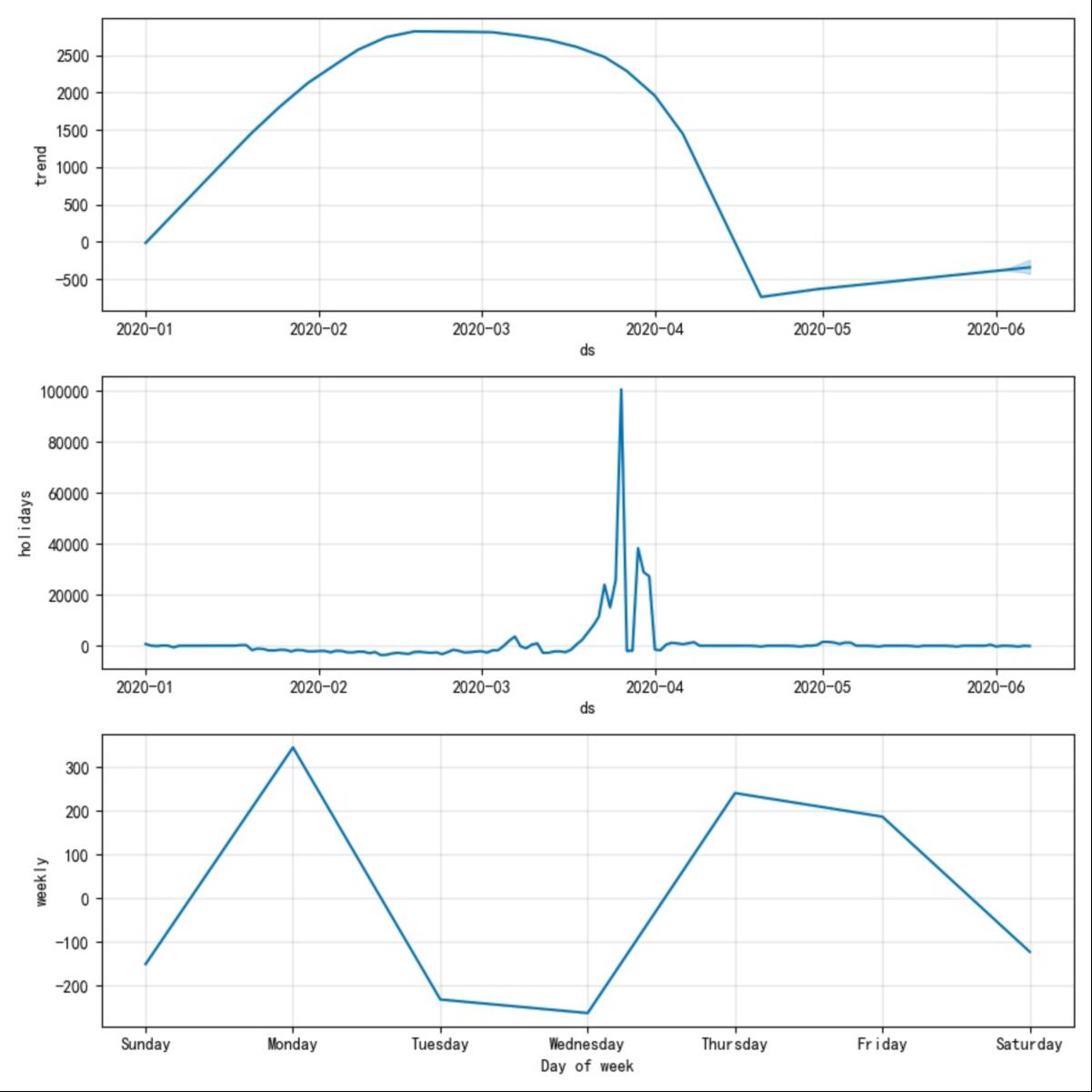
在Prophet中,认为holiday服从正态分布,正态分布的轴为ds。因此,prophet在预测节假日时会以正态分布作为来估计预测值,但这个过程只是一个先验估计的过程,如果模型后面发现这个holiday期间内不服从正态分布,那么模型将生硬的拟合该节假日。如图1-4中所示,大家可以自行体会。

holidays这个参数非常重要,对整个模型的影响极大,因此大家在构建这个参数时一定要给予相当的重视。
holidays在模型中是一个广义的概念,不仅指节假日,也指活动日期,特殊事件日期等,因此大家在设置holidays时一定要确保完整,同时对于upper_window和lower_window的设置也应符合实际情况。
值得注意的是holidays的数量应尽量少,过多的holidays会对模型的过拟合现象加重,如果holidays的数量超过了整体数据的30%,工程师就应该考虑是否去掉一些影响较小的节假日。
1.5 Prophet模型其他参数
| 参数 | 描述 |
|---|---|
| mcmc_samples | 概率估计方式。如果为0将会采用最大后验概率估计(MAP),如果为n(n>0)将会以n个马尔科夫采样样本做全贝叶斯推断。 估计有同学有疑问,这些个概率估计的东西跟本模型有毛关系?大家仔细看下图1-4中的蓝色曲线和淡蓝色区域,这其实就是预测结果,而采样估计就是用来给出淡蓝色区域的(uncertainty intervals),大家可以理解为置信区间或者是预测结果的上下限(虽然外国佬叫它‘不确定区间’)。 当mcmc_samples=0的时候,只有趋势因素会存在这种估计,当mcmc_samples>0时,周期性因素才会存在这种估计。 |
| interval_width | uncertainty intervals 的宽度,是一个浮点数,越大允许的uncertainty intervals范围越大 |
| uncertainty_samples | 用来估计uncertainty intervals的采样次数,如果设置为0或者False,就不会进行uncertainty intervals的估计,从而加快模型的训练速度。 |
| stan_backend | CMDSTANPY或者PYSTAN。一般PYSTAN在linux上使用,cmdstanpy在微软操作系统上使用。提示下在微软操作系统上使用的同学,最好不要开启马尔科夫采样(就是不要把mcmc_samples设成大于0),因为微软操作系统上马尔科夫采样非常慢。 |
2 prophet 与 LSTM的对比案例
目前成熟的时间序列预测算法很多,但商业领域性能优越的却不多,经过多种尝试,给大家推荐2种时间序列算法:facebook开源的Prophet算法和LSTM深度学习算法。
现将个人理解的2种算法特性予以简要说明:
(1)、在训练时间上,prophet几十秒就能出结果,而lstm往往需要1个半小时,更是随着网络层数和特征数量的增加而增加。
(2)、Prophet是一个为商业预测而生的时间序列预测模型,因此在很多方便都有针对性的优化,而lstm的初衷是nlp。
(3)、Prophet无需特征处理即可使用,参数调优也明确简单。而lstm则需要先进行必要的特征处理,其次要进行正确的网络结构设计,因此lstm相对prophet更为复杂。
(4)、Lstm需要更多的数据进行学习,否则无法消除欠拟合的情形。而prophet不同,prophet基于统计学,有完整的数学理论支撑,因此更容易从少量的数据中完成学习。
(5)、传统的时间序列预测算法只支持单纬度,但LSTM能支持多纬度,也就是说LSTM能考虑促销活动,目标用户特性,产品特性等
Prophet的核心是调参,步骤如下:
- 1、首先我们去除数据中的异常点(outlier),直接赋值为none就可以,因为Prophet的设计中可以通过插值处理缺失值,但是对异常值比较敏感。
- 2、选择趋势模型,默认使用分段线性的趋势,但是如果认为模型的趋势是按照log函数方式增长的,可设置growth='logistic’从而使用分段log的增长方式
- 3、 设置趋势转折点(changepoint),如果我们知道时间序列的趋势会在某些位置发现转变,可以进行人工设置,比如某一天有新产品上线会影响我们的走势,我们可以将这个时刻设置为转折点。如果自己不设置,算法会自己总结changepoint。
- 4、 设置周期性,模型默认是带有年和星期以及天的周期性,其他月、小时的周期性需要自己根据数据的特征进行设置,或者设置将年和星期等周期关闭。
设置节假日特征,如果我们的数据存在节假日的突增或者突降,我们可以设置holiday参数来进行调节,可以设置不同的holiday,例如五一一种,国庆一种,影响大小不一样,时间段也不一样。 - 5、 此时可以简单的进行作图观察,然后可以根据经验继续调节上述模型参数,同时根据模型是否过拟合以及对什么成分过拟合,我们可以对应调节seasonality_prior_scale、holidays_prior_scale、changepoint_prior_scale参数。
9 参考文献
- Prophet官方文档:https://facebook.github.io/prophet/
- Prophet论文:https://peerj.com/preprints/3190/
- Prophet-github:https://github.com/facebook/prophet
以上是关于python | prophet的案例实践:趋势检验突变点检验等的主要内容,如果未能解决你的问题,请参考以下文章