OpenCV 例程200篇236. 特征提取之主成分分析(OpenCV)
Posted YouCans
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenCV 例程200篇236. 特征提取之主成分分析(OpenCV)相关的知识,希望对你有一定的参考价值。
『youcans 的 OpenCV 例程200篇 - 总目录』
【youcans 的 OpenCV 例程200篇】236. 特征提取之主成分分析(OpenCV)
文章目录
特征提取是指从原始特征中通过数学变换得到一组新的特征,以降低特征维数,消除相关性,减少无用信息。
特征提取分为线性映射方法和非线性映射方法。
5.2 主成分分析的数学方法
主成分分析(Principal Components Analysis,PCA)是一种基于统计的数据降维方法,又称主元素分析、主分量分析。主成分分析只需要特征值分解,就可以对数据进行压缩、去噪,应用非常广泛。
众多原始变量之间往往具有一定的相关关系。这意味着相关变量所反映的信息有一定程度的重叠,因此可以用较少的综合指标聚合、反映众多原始变量所包含的全部信息或主要信息。主成分分析方法研究特征变量之间的相关性、相似性,将一组相关性高的高维变量转换为一组彼此独立、互不相关的低维变量,从而降低数据的维数。
主成分分析方法的思想是,将高维特征(p维)映射到低维空间(k维)上,新的低维特征是在原有的高维特征基础上通过线性组合而重构的,并具有相互正交的特性,称为主成分特性。
通过正交变换构造彼此正交的新的特征向量,这些特征向量组成了新的特征空间。将特征向量按特征值排序后,样本数据集中所包含的全部方差,大部分就包含在前几个特征向量中,其后的特征向量所含的方差很小。因此,可以只保留前 k个特征向量,而忽略其它的特征向量,实现对数据特征的降维处理。
主成分分析的基本步骤是:对原始数据归一化处理后求协方差矩阵,再对协方差矩阵求特征向量和特征值;对特征向量按特征值大小排序后,依次选取特征向量,直到选择的特征向量的方差占比满足要求为止。
主成分分析方法得到的主成分变量具有几个特点:(1)每个主成分变量都是原始变量的线性组合;(2)主成分的数目大大少于原始变量的数目;(3)主成分保留了原始变量的绝大多数信息;(4)各主成分变量之间彼此相互独立。
算法的基本流程如下:
(1)归一化处理,数据减去平均值;
(2)通过特征值分解,计算协方差矩阵;
(3)计算协方差矩阵的特征值和特征向量;
(4)将特征值从大到小排序;
(5)依次选取特征值最大的 k个特征向量作为主成分,直到其累计方差贡献率达到要求;
(6)将原始数据映射到选取的主成分空间,得到降维后的数据。
在图像处理中,把每幅二维图像拉伸为一维向量,即展平为一维数组。一组 m 幅图像就构造为一个 m 维向量,使用 Karhunen-Loève transform(KLT) 变换得到变换矩阵,选取特征值最大的 k个特征向量作为主成分,从而实现特征降维。
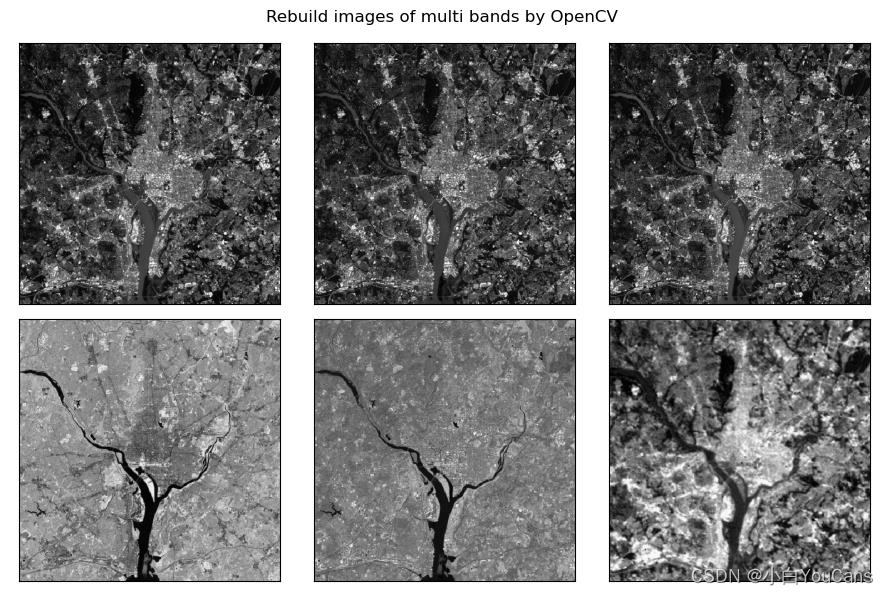
图像压缩过程是把一组原始图像变换成低维向量的过程,图像重建就是由低维向量变换重建图像组的过程。使用主成分分析进行图像压缩和重建会有少量信息损失,但可以把损失控制到很小。
5.4 OpenCV 的主成分分析方法
OpenCV 中提供了主成分分析(Principal Components Analysis,PCA)方法的实现,即 cv::PCA 类。类的声明在 include/opencv2/core.hpp 文件中,类的实现在 modules/core/src/pca.cpp 文件中。
- 成员函数:
- PCA::PCA:默认构造并初始化一个空的 PCA 结构
- PCA::backproject:将数据从 PCA 空间投影回原始空间,重建原始数据
- PCA::operator():对提供的数据执行主成分分析操作
- PCA::project:将输入数据投影到 PCA 特征空间;
- PCA::read:从指定文件读入特征值、特征向量和均值;
- PCA::write:向指定文件写入特征值、特征向量和均值;
- 属性:
- PCA::eigenvalues:协方差矩阵的特征值
- PCA::eigenvectors:协方差矩阵的特征向量
- PCA::mean:均值,投影前减去均值,投影后加上均值
PCA 类使用 Karhunen-Loeve 变换,由协方差矩阵的特征向量计算得到一组向量的正交基。
在 Python 语言中,OpenCV 提供了 PCA 类的接口函数 cv.PCACompute(),cv.PCAProject() 和 cv.PCABackProject()。
函数说明:
cv.PCACompute(data, mean[, eigenvectors=None, maxComponents=0]) → mean, eigenvectors
cv.PCACompute(data, mean, retainedVariance[, eigenvectors=None]) → mean, eigenvectors
cv.PCACompute2(data, mean[, eigenvectors=None, eigenvalues=None, maxComponents=0]) → mean, eigenvectors, eigenvalues
cv.PCACompute2(data, mean, retainedVariance[, eigenvectors=None, eigenvalues=None]) → mean, eigenvectors, eigenvalues
cv.PCAProject(data, mean, eigenvectors[, result=None]) → result
cv.PCABackProject(data, mean, eigenvectors[, result=None]) → result
函数 cv.PCACompute 是 PCA::operator 的接口,用于对提供的数据执行主成分分析操作,返回均值、特征向量和特征值。
函数 **cv.PCAProject ** 是 PCA::project 的接口,用于将输入数据按选择的特征向量投影到 PCA 特征空间。
函数 cv.PCABackProject 是 PCA::backproject 的接口,用于将输入数据按选择的特征向量投影从 PCA 空间投影回原始空间,重建原始数据。
参数说明:
-
data:输入数据矩阵,对于 cv.PCACompute 和 PCAProject 是 m×P 原始数据矩阵,对于 PCABackProject 是 m×K 降维数据矩阵 ( K ≤ P ) (K \\le P) (K≤P)
-
mean:均值,形状为 (1,P),如果该参数的输入为空,则通过输入数据计算均值
-
maxComponents:保留主成分的个数,默认为保留全部主成份
-
retainedVariance:保留的累计方差的百分比,据此确定保留主成分的个数(至少保留 2个主成分)
-
eigenvectors:特征向量,全部特征向量的形状为 (P,P),前 K 个特征向量的形状为 (K,P)
-
eigenvalues:特征值,全部特征向量的形状为 (P,1),前 K 个特征向量的形状为 (K,1)
注意事项:
注意事项:
- 输入参数中的 mean 如果为空,其格式为 np.empty((0)) 或 np.array([])。
- OpenCV-Python-PCA 是 C 语言版本 PCA 类的接口,有些变量/参数的格式有些不方便。网络上关于 OpenCV-Python-PCA 的很多博文(可能)也有问题(错误),请读者务必注意。
例程 14.17:特征描述之主成分分析 (OpenCV)
本例程的图像来自 R.C.Gonzalez 《数字图像处理(第四版)》P622 例11.16。本例的目的是说明如何使用主分量作为图像特征。
# 14.17 特征描述之主成分分析 (OpenCV)
# 读取光谱图像组
img = cv2.imread("../images/Fig1138a.tif", flags=0)
height, width = img.shape[:2] # (564, 564)
nBands = 6 # 光谱波段种类
snBands = ['a','b','c','d','e','f'] # Fig1138a~f
imgMulti = np.zeros((height, width, nBands)) # (564, 564, 6)
Xmat = np.zeros((img.size, nBands)) # (318096, 6)
print(imgMulti.shape, Xmat.shape)
# 显示光谱图像组
# fig1 = plt.figure(figsize=(9, 6)) # 原始图像,6 个不同波段
# fig1.suptitle("Spectral image of multi bands by NASA")
for i in range(nBands):
path = "../images/Fig1138.tif".format(snBands[i])
imgMulti[:,:,i] = cv2.imread(path, flags=0) # 灰度图像
# ax1 = fig1.add_subplot(2,3,i+1)
# ax1.set_xticks([]), ax1.set_yticks([])
# ax1.imshow(imgMulti[:,:,i], 'gray') # 绘制光谱图像 snBands[i]
# plt.tight_layout()
# 主成分分析 (principal component analysis)
m, p = Xmat.shape # m:训练集样本数量,p:特征维度数
Xmat = np.reshape(imgMulti, (-1, nBands)) # (564,564,6) -> (318096,6)
mean, eigenvectors, eigenvalues = cv2.PCACompute2(Xmat, np.empty((0)), retainedVariance=0.98) # retainedVariance=0.95
# mean, eigenvectors, eigenvalues = cv2.PCACompute2(Xmat, np.empty((0)), maxComponents=3) maxComponents=3
print(mean.shape, eigenvectors.shape, eigenvalues.shape) # (1, 6) (3, 6) (3, 1)
eigenvalues = np.squeeze(eigenvalues) # 删除维度为1的数组维度,(3,1)->(3,)
# 保留的主成分数量
K = eigenvectors.shape[0] # 主成分方差贡献率 95% 时的特征维数 K=3
print("number of samples: m=", m) # 样本集的样本数量 m=318096
print("number of features: p=", p) # 样本集的特征维数 p=6
print("number of PCA features: k=", K) # 降维后的特征维数,主成分个数 k=3
print("mean:", mean.round(4)) # 均值
print("topK eigenvalues:\\n", eigenvalues.round(4)) # 特征值,从大到小
print("topK eigenvectors:\\n", eigenvectors.round(4)) # (3, 6)
# 压缩图像特征,将输入数据按主成分特征向量投影到 PCA 特征空间
mbMatPCA = cv2.PCAProject(Xmat, mean, eigenvectors) # (318096, 6)->(318096, K=3)
# 显示主成分变换图像
fig2 = plt.figure(figsize=(9, 6)) # 主元素图像
fig2.suptitle("Principal component images")
for i in range(K):
pca = mbMatPCA[:, i].reshape(-1, img.shape[1]) # 主元素图像 (564, 564)
imgPCA = cv2.normalize(pca, (height, width), 0, 255, cv2.NORM_MINMAX)
ax2 = fig2.add_subplot(2,3,i+1)
ax2.set_xticks([]), ax2.set_yticks([])
ax2.imshow(imgPCA, 'gray') # 绘制主成分图像
plt.tight_layout()
# # 由主成分分析重建图像
reconMat = cv2.PCABackProject(mbMatPCA, mean, eigenvectors) # (318096, K=3)->(318096, 6)
fig3 = plt.figure(figsize=(9, 6)) # 重建图像,6 个不同波段
fig3.suptitle("Rebuild images of multi bands by OpenCV")
rebuild = np.zeros((height, width, nBands)) # (564, 564, 6)
for i in range(nBands):
rebuild = reconMat[:, i].reshape(-1, img.shape[1]) # 主元素图像 (564, 564)
# rebuild = np.uint8(cv2.normalize(rebuild, (height, width), 0, 255, cv2.NORM_MINMAX))
ax3 = fig3.add_subplot(2,3,i+1)
ax3.set_xticks([]), ax3.set_yticks([])
ax3.imshow(rebuild, 'gray') # 绘制光谱图像 snBands[i]
plt.tight_layout()
plt.show()
运行结果:
(564, 564, 6) (318096, 6)
(1, 6) (3, 6) (3, 1)
number of samples: m= 318096
number of features: p= 6
number of PCA features: k= 3
mean: [[ 61.9724 67.5084 62.1467 146.1866 134.4214 111.4343]]
topK eigenvalues:
[10344.2723 2965.8884 1400.6306]
topK eigenvectors:
[[ 0.489 0.4777 0.4899 -0.1375 0.2188 0.4753]
[-0.0124 0.0394 -0.022 0.7986 0.5981 -0.0486]
[-0.2301 -0.3012 -0.315 0.0431 0.0165 0.8689]]

【本节完】
版权声明:
本例程的图像来自 R.C.Gonzalez 《数字图像处理(第四版)》P622 例11.16。
youcans@xupt 原创作品,转载必须标注原文链接:(https://blog.csdn.net/youcans/article/details/125782192)
Copyright 2022 youcans, XUPT
Crated:2022-7-15
234. 特征提取之主成分分析(PCA)
235. 特征提取之主成分分析(sklearn)
236. 特征提取之主成分分析(OpenCV)
以上是关于OpenCV 例程200篇236. 特征提取之主成分分析(OpenCV)的主要内容,如果未能解决你的问题,请参考以下文章
OpenCV 例程200篇235. 特征提取之主成分分析(sklearn)
OpenCV 例程200篇235. 特征提取之主成分分析(sklearn)
OpenCV 例程300篇234. 特征提取之主成分分析(PCA)